随着监控系统监控的指标越来越多,你会发现你的监控很杂乱,并且一个server去那么多机器上抽取数据或者被推送,想着都很累。又或者你是个老板,你不关心那些闲杂项,只想要个聚合结果。那么prometheus提供了分布式部署方案。相对来说,zabbix提供了proxy的方案解决这个问题。
环境说明
你需要准备两个PrometheUS的server,一个上面已经有数据了,而另一个上面什么配置都没有
配置
- 编辑目标端的配置文件,添加
- job_name: 'federate'
scrape_interval: 15s
metrics_path: '/federate'
params:
'match[]':
- '{job="test_server", __name__="up"}'
static_configs:
- targets: ['192.168.0.1:9091'] #这里写源端的地址
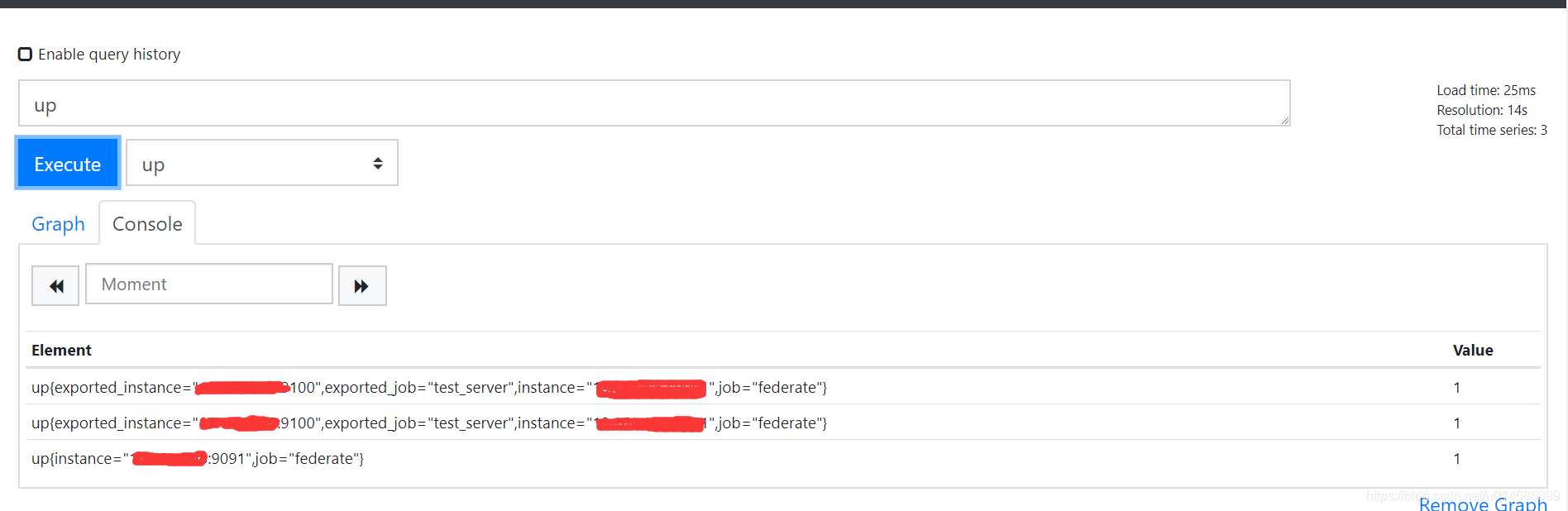
上面的例子是说,只同步源端的test_server这一类job的up指标
match[] 是必须有的至少写一个
label是支持正则匹配的,比如 name~=“up.*”,这是匹配所有已up开头的指标
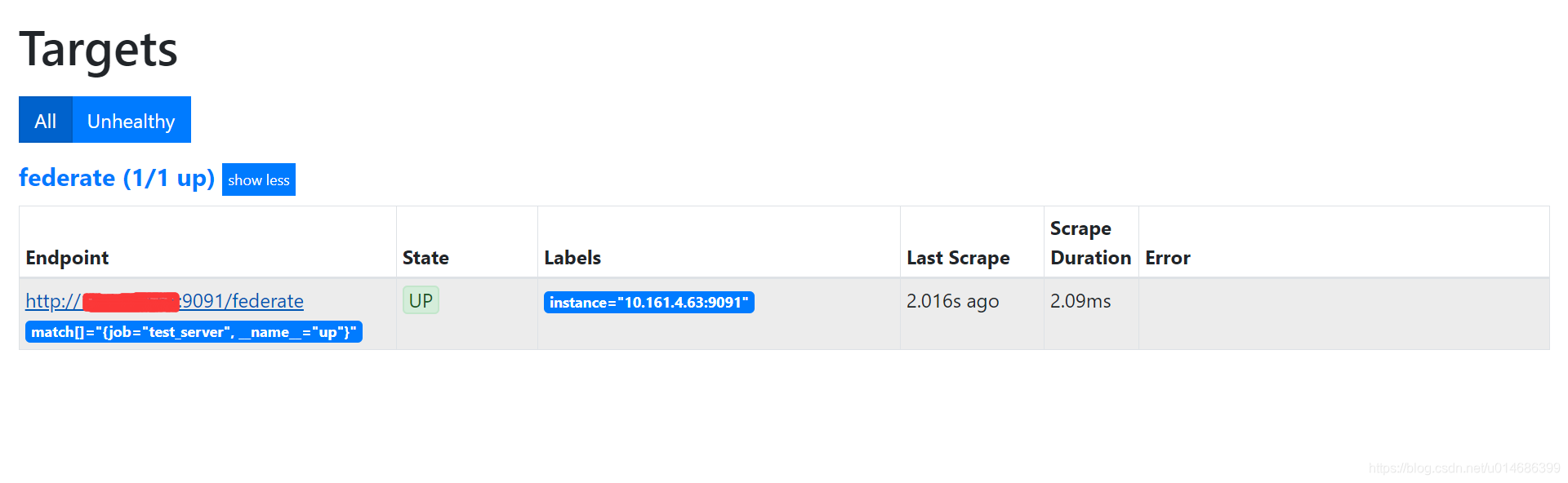
- 启动prometheus
- 查看页面
配置完毕
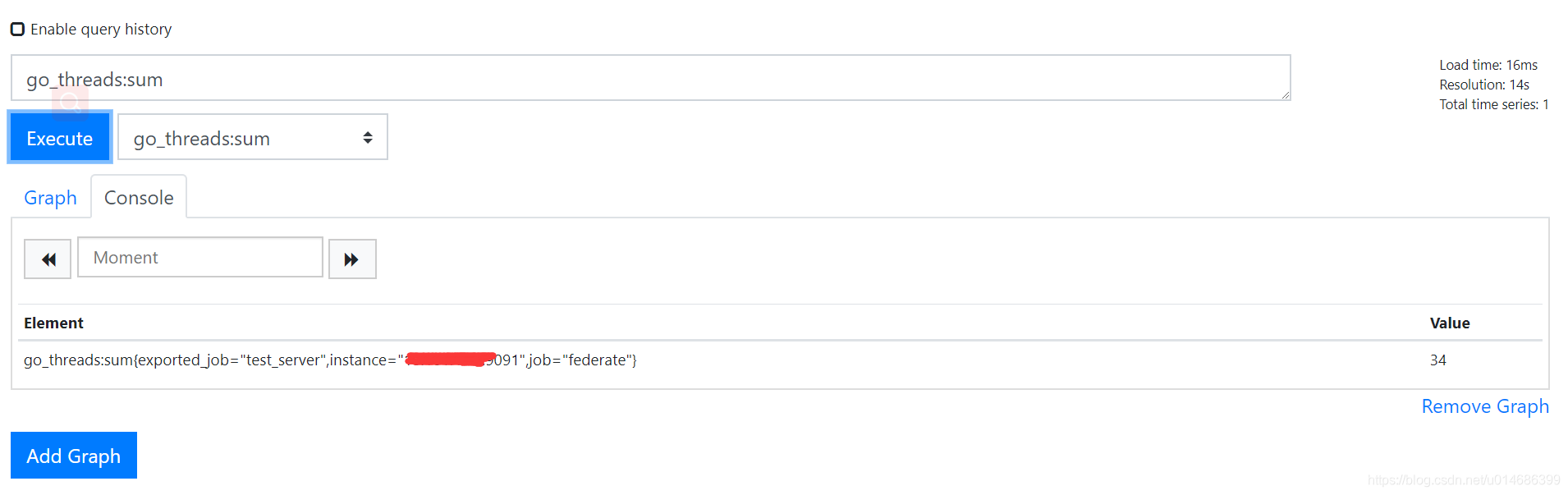
只同步聚合后的结果
- 编辑或者新建源端的配置文件prometheus.rules.yml,添加一个rule规则
groups:
- name: test_rule
interval: 60s
rules:
- record: go_threads:sum
expr: sum(go_threads)
labels:
testname: test
- 编辑源端的prometheus.yml配置文件
rule_files:
- "prometheus.rules.yml"
- 重新加载源端的配置
- 编辑目的端的配置文件,prometheus.yml
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'federate'
scrape_interval: 15s
metrics_path: '/federate'
params:
'match[]':
- '{job="test_server", __name__="go_threads:sum"}'
static_configs:
- targets: ['192.168.0.1:9091']
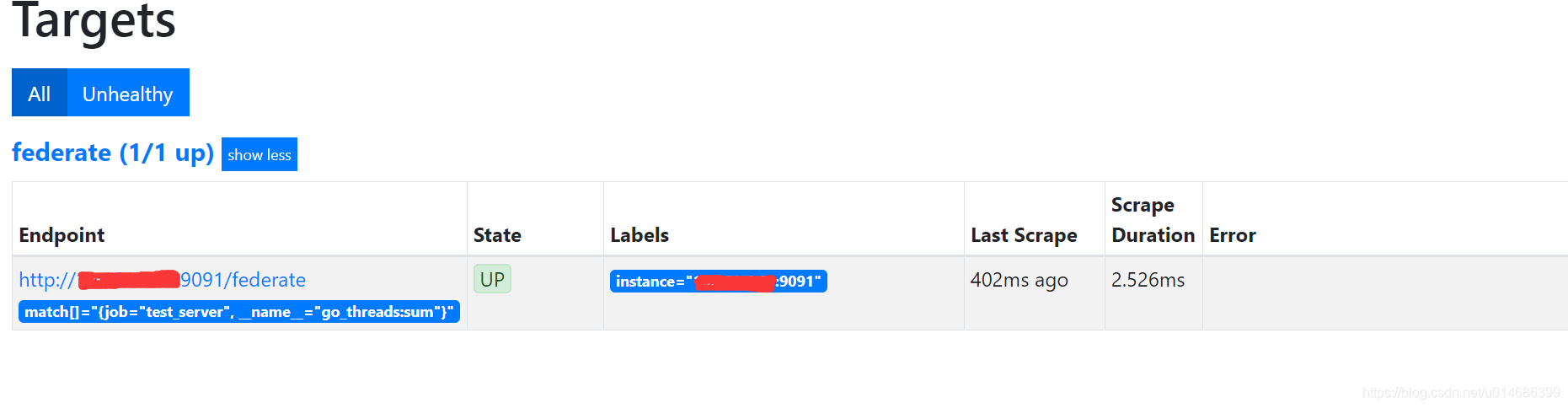
- 重新加载目的端的配置
- 查看web页面
先写到这里了,有问题进QQ群630300475聊一聊,大家一起进步