Eformer是进行低剂量CT图像重建的工作,它第一次将Transformer用在医学图像去噪上,值得一读。
知乎同名账号同步发布。
一、架构和贡献
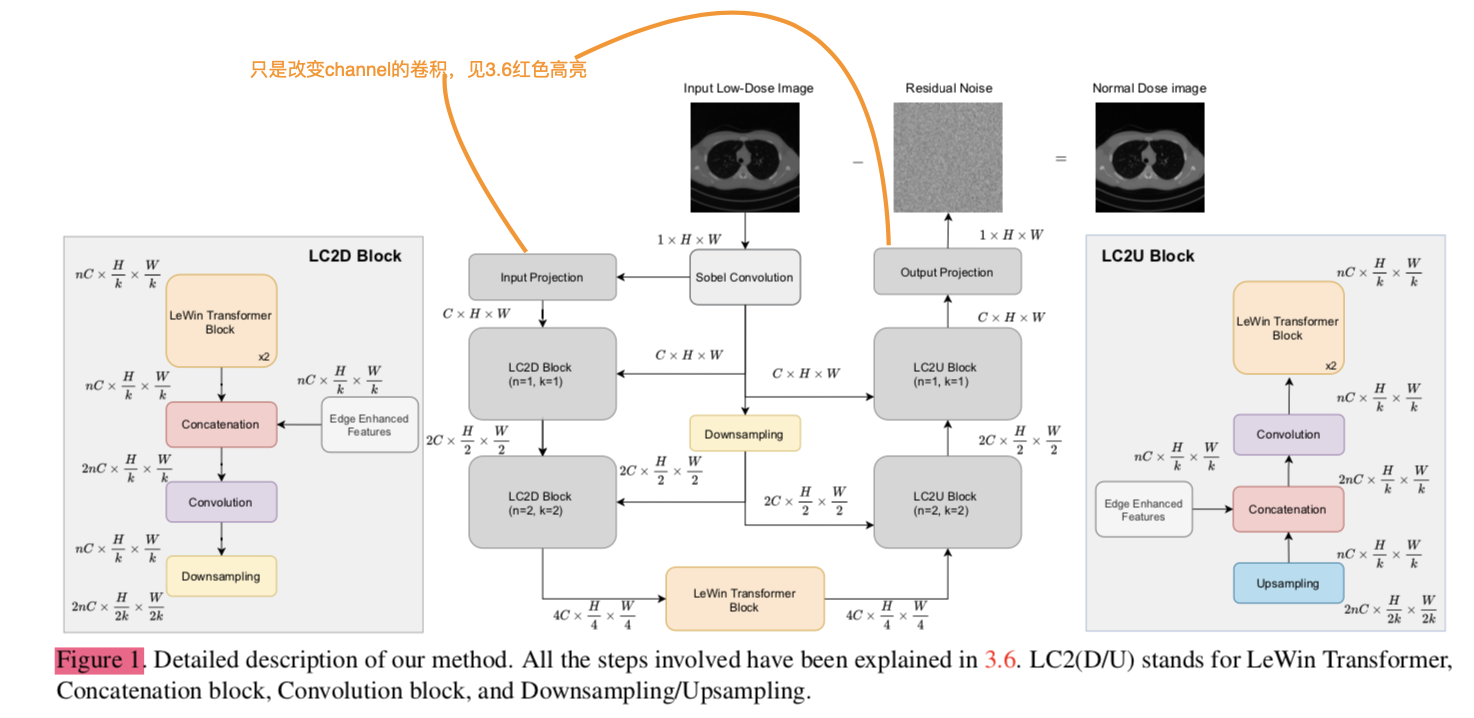
和Uformer一样,将LeWin Transformer加入了UNet中,不一样的是将经过Sobel Convolution处理的图片concat到UNet中不同阶段的encode和decode过程中。采用了残差学习,原图减残差为预测去噪结果。注意下采样和上采样是用卷积和反卷积(注意避免棋盘效应,后文会讲)。
二、主要细节
需要了解的主要就是Sobel Convolution和LeWin Transformer,后者我在Uformer笔记中已经记录,简单放上公式:
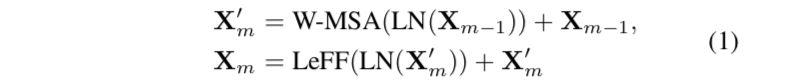
2.1,Sobel Convolution
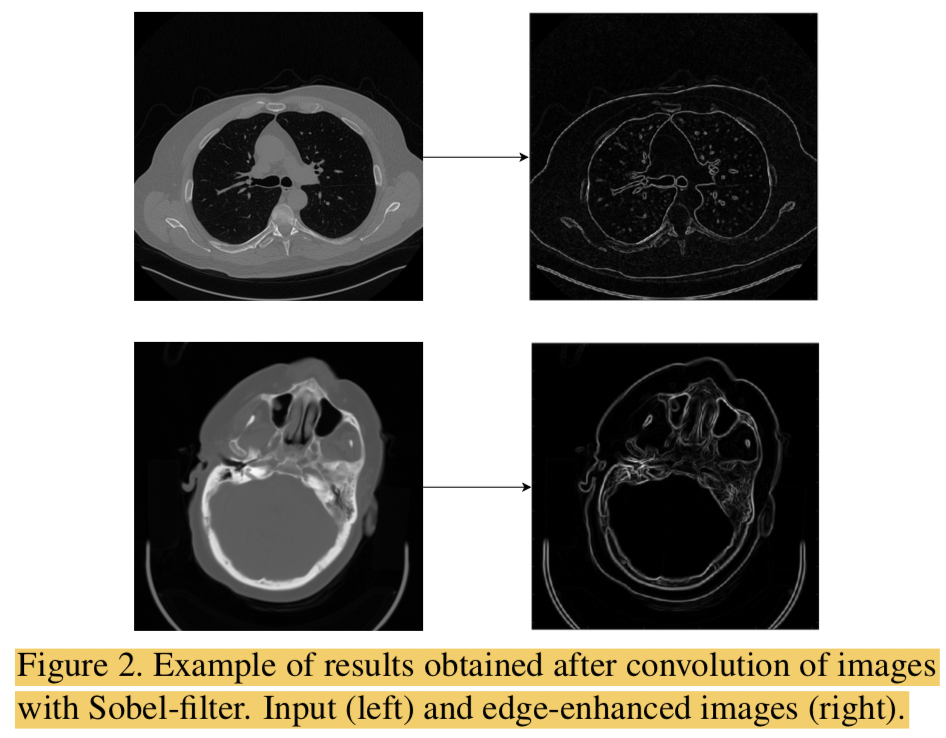
Sobel Convolution的功能是获得edge-enhanced images,效果如下图所示:
细节没看,文章中对其的引用放下面:
[19] Tengfei Liang, Yi Jin, Yidong Li, and Tao Wang. Edcnn: Edge enhancement-based densely connected network with compound loss for low-dose ct denoising. 2020 15th IEEE International Conference on Signal Processing (ICSP), Dec 2020.
[24] Irwin Sobel. An isotropic 3x3 image gradient operator. Presentation at Stanford A.I. Project 1968, 02 2014.
Sobel Convolution之后跟的激活函数是GeLU。
2.2, 下采样和上采样
采用3×3的卷积进行下采样,stride为2,padding为1.作者说不用pooling的原因是可能会丢失细节,所以采用strided conv来下采样。
采用反卷积进行上采样,作者提到了棋盘效应:
棋盘效应,源头就是反卷积过程中,当卷积核大小不能被步长整除时,反卷积就会出现重叠问题,插零的时候,输出结果会出现一些数值效应,就像棋盘一样。
所以卷积核大小应当能被步长整除,作者采用4×4的卷积核,stride为2.
2.3,损失函数
采用两个损失函数,一个是MSE,一个是感知损失。
MSE:
MSE损失会造成过度平滑和图像模糊,所以作者没有只用它。
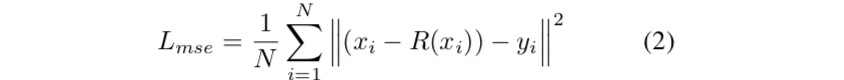
ResNet based MSP(Multi-scale Perceptual):
x
i
−
R
(
x
i
)
x_i-R(x_i)
xi−R(xi)是网络的预测结果,
y
i
y_i
yi是ground-truth,
ϕ
s
\phi_s
ϕs表示ResNet,不同的s表示不同尺度的ResNet,一共有C种s,所以是multi-scale。
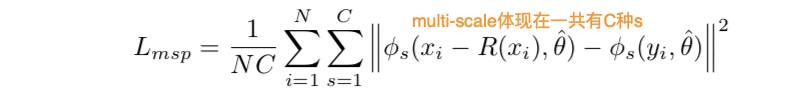
最终损失函数如下所示:
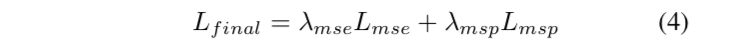
作者也对比了不同方法采用的不同损失:

三、实验
在Mayo上做的,先用Pydicom将像素从Dicom文件提取到Numpy array中,然后将像素数值scale到0-1之间。其他数据集和训练细节在paper第7页。
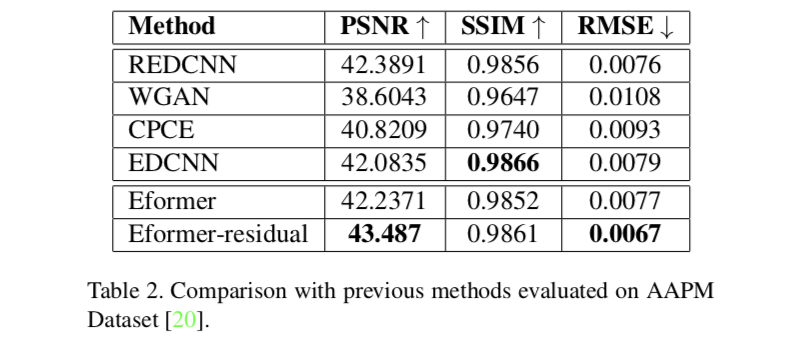
和其他方法的对比:
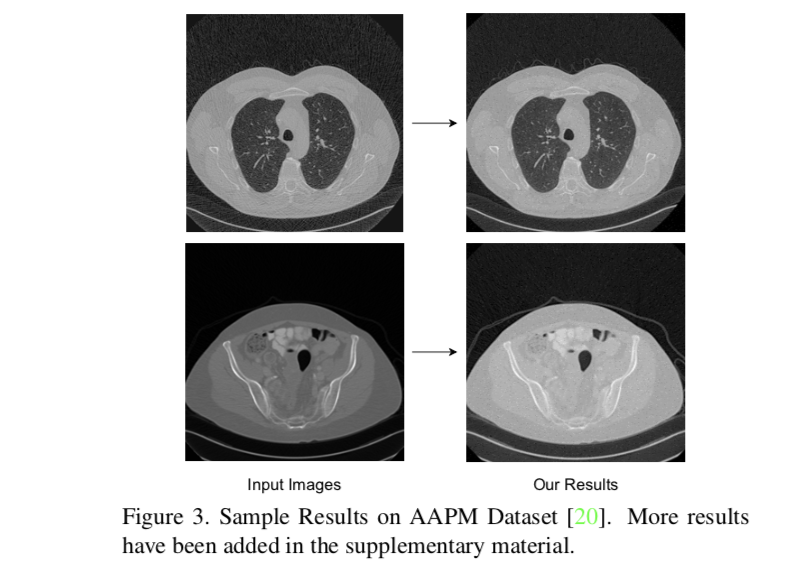
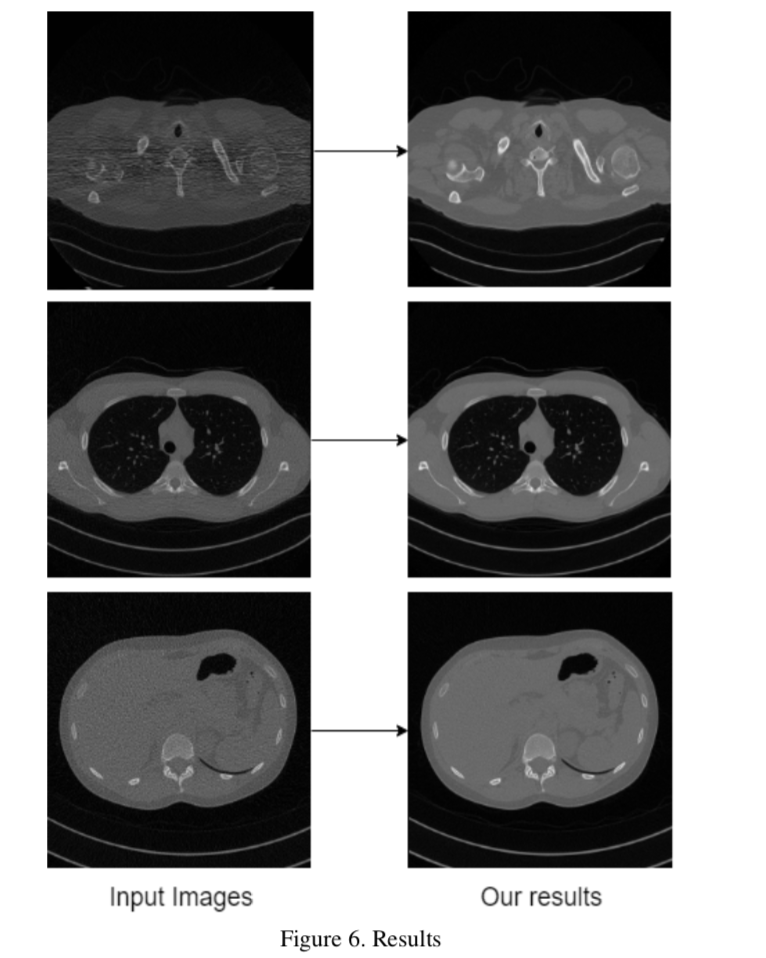
作者放的效果图: