文章目录
5.1 LangChain 框架
LangChain 是专用于开发 LLM 驱动型应用程序的框架。该框架还提供了许多额外的功能。
使用以下命令可以快速、简便地安装 LangChain
pip install langchain
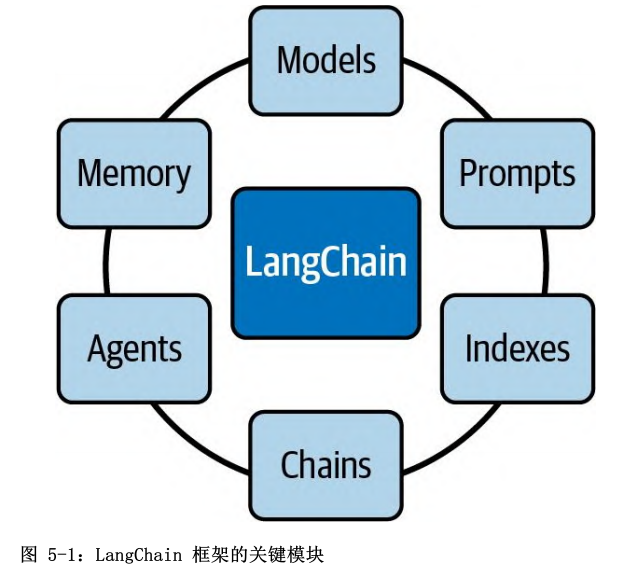
这些关键模块的作用如下:
- Models(模型):该模块是由 LangChain 提供的标准接口,可以通过它与各种 LLM进行交互。LangChain 支持集成 OpenAI、Hugging Face、Cohere、GPT4All 等提供商提供的不同类型的模型;
- Prompts(提示词):该模块包含许多用于管理提示词的工具;
- Indexes(索引): Retrieval 模块,能够将 LLM 与你的数据结合使用 ;
- Chains(链):可以使用该接口创建一个调用序列,将多个模型或提示词组合在一起;
- Agents(智能体):该模块引入了 Agent 接口。可以处理用户输入、做出决策并选择适当工具来完成任务的组件。它以迭代方式工作,采取一系列行动,直到解决问题;
- Memory(记忆):该模块让你能够在链调用或智能体调用之间维持状态。默认情况下,链和智能体是无状态的。这意味着它们独立地处理每个传入的请求,就像LLM 一样。
5.1.1 动态提示词
用 OpenAI 模型和 LangChain 来完成一个简单的文本补全任务:
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
template = """
Question: {question}
Let's think step by step.
Answer:
"""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm = ChatOpenAI(model_name="gpt-4")
llm_chain = LLMChain(prompt=prompt, llm=llm)
question = """ What is the population of the capital of the country where the Olympic Games were held in 2016? """
llm_chain.run(question)
输出如下:
Step 1: Identify the country where the Olympic Games were held in 2016.
Answer: The 2016 Olympic Games were held in Brazil.
Step 2: Identify the capital of Brazil.
Answer: The capital of Brazil is Brasília.
Step 3: Find the population of Brasília.
Answer: As of 2021, the estimated population of Brasília is around 3.1 million. So, the population of the capital of the country where the Olympic Games were held in 2016 is around 3.1 million. Note that this is an estimate and may vary slightly.'
PromptTemplate 负责构建模型的输入,能以可复制的方式生成提示词。它包含一个名为 template 的输入文本字符串,其中的值可以通过 input_variables 进行指定。
提示词和模型由 LLMChain 函数组合在一起,形成包含这两个元素的一条链。最后需要调用 run 函数来请求补全输入问题。当运行 run 函数时,LLMChain 使用提供的输入键值格式化提示词模板,随后将经过格式化的字符串传递给 LLM,并返回 LLM 输出。模型运用“逐步思考”的技巧自动回答问题,对于复杂的应用程序来说,动态提示词是简单而又颇具价值的功能。
5.1.2 智能体及工具
智能体及工具是 LangChain 框架提供的关键功能:它们可以使应用程序变得非常强大,让 LLM 能够执行各种操作并与各种功能集成,从而解决复杂的问题。这里所指的“工具”是围绕函数的特定抽象,使语言模型更容易与之交互
工具的接口有一个文本输入和一个文本输出。LangChain 中有许多预定义的工具,包括谷歌搜索、维基百科搜索、Python REPL、计算器、世界天气预报 API 等。除了使用预定义的工具,你还可以构建自定义工具并将其加载到智能体中,这使得智能体非常灵活和强大。
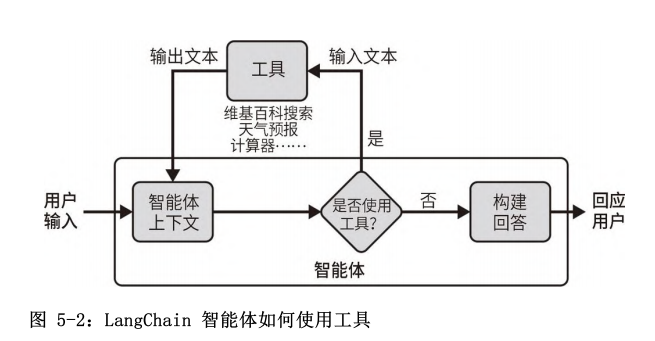
智能体安排的步骤如下所述。
-
智能体收到来自用户的输入。
-
智能体决定要使用的工具(如果有的话)和要输入的文本。
-
使用该输入文本调用相应的工具,并从工具中接收输出文本。
-
将输出文本输入到智能体的上下文中。
-
重复执行步骤 2 ~步骤 4,直到智能体决定不再需要使用工具。此时,它将直接回应用户。
假如问以下问题:2016 年奥运会举办国首都的人口的平方根是多少?这个问题并没有特殊的含义,但它很好地展示了LangChain 智能体及工具如何提高 LLM 的推理能力。如果将问题原封不动地抛给 GPT-3.5 Turbo,得到以下回答
The capital of the country where the Olympic Games were held in 2016 is Rio de Janeiro, Brazil. The population of Rio de Janeiro is approximately 6.32 million people as of 2021. Taking the square root of this population, we get approximately 2,513.29. Therefore, the square root of the population of the capital of the country where the Olympic Games were held in 2016 is approximately 2,513.29.
上述回答至少有两处错误:
- 巴西的首都是巴西利亚,而不是里约热内卢;
-
- 6 320 000 的平方根约等于 2513.96,而不是 2513.29。
可以通过运用“逐步思考”或其他提示工程技巧来获得更好的结果,但由于模型在推理和数学运算方面存在困难,因此很难相信结果是准确的。使用LangChain 可以给我们更好的准确性保证。
LangChain 智能体可以使用两个工具:维基百科搜索和计算器。
在通过 load_tools 函数创建工具之后,使用initialize_agent 函数创建智能体。智能体的推理功能需要用到一个LLM,本例使用的是 gpt-3.5-turbo。参数ZERO_SHOT_REACT_DESCRIPTION 定义了智能体如何在每一步中选择工具。通过将 verbose 的值设置为 True,可以查看智能体的推理过程,并理解它是如何做出最终决策的。
from langchain.agents import load_tools, initialize_agent, AgentType
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
tools = load_tools(["wikipedia", "llm-math"], llm=llm)
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
question = """
What is the square root of the population of the capital
of the Country where the Olympic Games were held in 2016?"""
agent.run(question)
在使用维基百科搜索工具之前,可以使用 pip install wikipedia 来安装这个包。
> Entering new chain...
I need to find the country where the Olympic Games were held in 2016
and then find the population of its capital city. Then I can take the
square root of that population.
Action: Wikipedia
Action Input: "2016 Summer Olympics"
Observation: Page: 2016 Summer Olympics
[...]
输出的下一行包含维基百科关于奥运会的摘录。智能体使用维基百科搜索工具又进行了两次额外的操作
Thought:I need to search for the capital city of Brazil.
Action: Wikipedia
Action Input: "Capital of Brazil"
Observation: Page: Capitals of Brazil
Summary: The current capital of Brazil, since its construction in
1960, is Brasilia. [...]
Thought: I have found the capital city of Brazil, which is Brasilia. Now I need to find the population of Brasilia.
Action: Wikipedia
Action Input: "Population of Brasilia"
Observation: Page: Brasilia
[...]
下一步,智能体使用计算器工具:
Thought: I have found the population of Brasilia, but I need to
calculate the square root of that population.
Action: Calculator
Action Input: Square root of the population of Brasilia (population: found in previous observation)
Observation: Answer: 1587.051038876822
得出最终答案:
Thought: I now know the final answer
Final Answer: The square root of the population of the capital of the country where the Olympic Games were held in 2016 is approximately 1587.
> Finished chain.
正如你所见,该智能体展示了较强的推理能力:在得出最终答案之前,它完成了 4 个步骤。LangChain 框架使开发人员能够仅用几行代码就实现这种推理能力。
5.1.3 记忆
在某些应用程序中,记住之前的交互是至关重要的,无论是短期记忆还是长期记忆。使用 LangChain,可以轻松地为链和智能体添加状态以管理记忆。构建聊天机器人是这种能力最常见的用例。在 LangChain 中,可以使用 ConversationChain 很快地完成这个过程,只需几行代码即可将语言模型转换为聊天工具。
以下代码使用 text-ada-001 模型创建一个聊天机器人。这是一个只能执行基本任务的小模型。只需几行LangChain 代码,即可使用这个简单的文本补全模型开始聊天:
from langchain import OpenAI, ConversationChain
chatbot_llm = OpenAI(model_name='text-ada-001')
chatbot = ConversationChain(llm=chatbot_llm , verbose=True)
chatbot.predict(input='Hello')
最后一行执行了 predict(input='Hello')。这要求聊天机器人回复我们的 ‘Hello’ 消息。模型的回答如下所示:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an
AI. The AI is talkative and provides lots of specific details from
its context. If the AI does not know the answer to a question, it
truthfully says it does not know.
Current conversation:
Human: Hello
AI:
> Finished chain.
' Hello! How can I help you?'
由于将 ConversationChain 中的 verbose 设置为 True,因此可以查看 LangChain 使用的完整提示词。当执行predict(input='Hello') 时,text-ada-001 模型收到的不仅仅是’Hello’ 消息,而是完整的提示词。该提示词位于标签> Entering new ConversationChain chain...和> Finished chain之间。
如果继续对话,会发现该函数在提示词中保留了对话的历史记录。如果接着问模型是不是 AI,那么这个问题也将被包含在提示词中:
> Entering new ConversationChain chain...
Prompt after formatting:
The following [...] does not know.
Current conversation:
Human: Hello
AI: Hello! How can I help you?
Human: Can I ask you a question? Are you an AI?
AI:
> Finished chain.
'\n\nYes, I am an AI.'
ConversationChain 对象使用提示工程技巧和记忆技巧,将进行文本补全的 LLM 转换为聊天工具。
5.1.4 嵌入
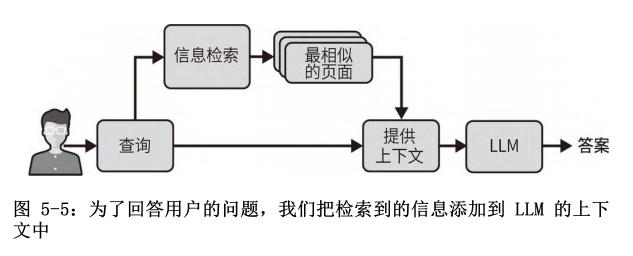
将语言模型与你自己的文本数据相结合,这样做有助于将应用程序所用的模型知识个性化。首先检索信息,即获取用户的查询并返回最相关的文档;然后将这些文档发送到模型的输入上下文中,以便它响应查询。
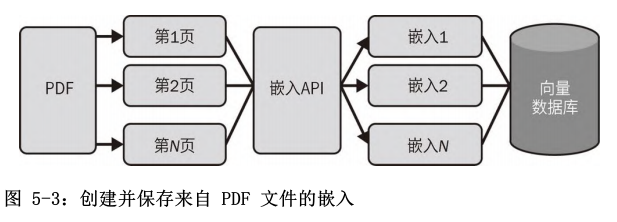
document_loaders 是 LangChain 中的一个重要模块。通过这个模块可以快速地将文本数据从不同的来源加载到应用程序中。比如,应用程序可以加载 CSV 文件、电子邮件、PowerPoint 文档、Evernote 笔记、Facebook 聊天记录、HTML 页面、PDF 文件和许多其他格式。
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("ExplorersGuide.pdf")
pages = loader.load_and_split()
在使用 PDF 加载器之前,需要安装 pypdf 包。这可以通过 pip install pypdf 来完成。
进行信息检索时,需要嵌入每个加载的页面。在信息检索中,嵌入是用于将非数值概念(如单词、标记和句子)转换为数值向量的一种技术。这些嵌入使得模型能够高效地处理这些概念之间的关系。借助 OpenAI 的嵌入端点,开发人员可以获取输入文本的数值向量表示。此外,LangChain 提供了一个包装器来调用这些嵌入,如下所示。
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
要使用 OpenAIEmbeddings,先使用 pip install tiktoken 安装 tiktoken 包
LangChain 以向量数据库为中心。有许多向量数据库可供选择,详见 LangChain 文档。以下代码片段使用Faiss 向量数据库,这是一个主要由 Facebook AI 团队开发的相似性搜索库:
from langchain.vectorstores import FAISS
db = FAISS.from_documents(pages, embeddings)
使用 Faiss 向量数据库之前,需要使用 pip install faiss-cpu 命令安装 faiss-cpu 包。
搜索相似内容:
q = "What is Link's traditional outfit color?"
db.similarity_search(q)[0]
得到以下内容:
Document(
page_content='While Link’s traditional green tunic is certainly an iconic look, his wardrobe has expanded [...] Dress for Success',
metadata={'source': 'ExplorersGuide.pdf', 'page': 35})
这个问题的答案是Link 的服装颜色是绿色。可以看到,答案就在选定的内容中。输出显示,答案在 ExplorersGuide.pdf 的第 35 页。Python 从 0 开始计数。因此,如果查看原始 PDF 文件,会发现答案在第 36 页,而非第 35 页。

使用 RetrievalQA,它接受 LLM 和向量数据库作为输入。然后,像往常一样向所获得的对象提问
from langchain.chains import RetrievalQA
from langchain import OpenAI
llm = OpenAI()
chain = RetrievalQA.from_llm(llm=llm, retriever=db.as_retriever())
q = "What is Link's traditional outfit color?"
chain(q, return_only_outputs=True)
得到以下答案:
{'result': " Link's traditional outfit color is green."}
“提供上下文”将信息检索系统找到的页面和用户最初的查询进行分组。然后,上下文被发送给 LLM。LLM 可以利用上下文中的附加信息正确回答用户的问题
5.2 GPT-4 插件
在 AI 的发展过程中,插件已经成为一种新型的革命性工具,它重新定义了我们与 LLM 的互动方式。插件的目标是为 LLM 提供更广泛的功能,使 LLM 能够访问实时信息,进行复杂的数学运算,并利用第三方服务。
比如当需要进行计算时,模型会自动调用计算器,从而得到正确的结果。

通过迭代部署方法,OpenAI 逐步向 GPT-4 添加插件,这使得 OpenAI 能够考虑插件的实际用途及可能引入的安全问题和定制化挑战。OpenAI 的目标是创建一个生态系统,插件可以帮助塑造 AI 与人类互动的未来。每家企业都需要有自己的插件。事实上,Expedia、FiscalNote、Instacart、KAYAK、Klarna、Milo、OpenTable、Shopify 和 Zapier 等公司已经率先推出了几款插件。
比如,插件可以使 LLM 检索体育比分和股票价格等实时信息,从企业文档等知识库中提取数据,并根据用户的需求执行任务,如预订航班或订餐。两者都旨在帮助AI 获取最新信息并进行计算。然而,GPT-4 中的插件更专注于第三方服务,而不是 LangChain 工具。
5.2.1 概述
当你开始与 GPT-4 进行交互时,OpenAI 会向 GPT-4 发送一条隐藏消息,以检查你的插件是否已安装。这条消息会简要介绍你的插件,包括其描述信息、端点和示例。
模型就成了智能的 API 调用者。当用户询问关于插件的问题时,模型可以调用你的插件 API。是否调用插件是基于 OpenAPI 规范和关于应该使用 API 的情况的自然语言描述所做出的决策。一旦模型决定调用你的插件,它就会将 API 的结果合并到上下文中,以向用户提供响应。因此,插件的 API 响应必须返回原始数据而不是自然语言响应。这使得GPT-4 可以根据返回的数据生成自己的自然语言响应。
如果用户问模型“我在北京可以住哪里”,那么模型可以使用酒店预订插件,然后将插件的 API 响应与其文本生成能力结合起来,提供既含有丰富信息又对用户友好的回答。
5.2.2 API
OpenAI 在 GitHub 上提供的待办事项列表定义插件的简化版本:
import quart
import quart_cors
from quart import request
app = quart_cors.cors(
quart.Quart(__name__), allow_origin="https://chat.openai.com"
)
# 跟踪待办事项
_TODOS = {}
@app.post("/todos/<string:username>")
async def add_todo(username):
request = await quart.request.get_json(force=True)
if username not in _TODOS:
_TODOS[username] = []
_TODOS[username].append(request["todo"])
return quart.Response(response="OK", status=200)
@app.get("/todos/<string:username>")
async def get_todos(username):
return quart.Response(
response=json.dumps(_TODOS.get(username, [])), status=200
)
@app.get("/.well-known/ai-plugin.json")
async def plugin_manifest():
host = request.headers["Host"]
with open("./.well-known/ai-plugin.json") as f:
text = f.read()
return quart.Response(text, mimetype="text/json")
@app.get("/openapi.yaml")
async def openapi_spec():
host = request.headers["Host"]
with open("openapi.yaml") as f:
text = f.read()
return quart.Response(text, mimetype="text/yaml")
def main():
app.run(debug=True, host="0.0.0.0", port=5003)
if __name__ == "__main__":
main()
这段 Python 代码是一个简单的插件示例,用于管理待办事项列表。首先,变量 app 被初始化为 quart_cors.cors()。这行代码创建了一个新的 Quart 应用程序,并配置它允许来自 https://chat.openai.com 的跨源资源共享(cross-origin resource sharing,CORS)。Quart 是一个Python Web 微框架,Quart-CORS 则是一个扩展,可以控制 CORS。这个设置允许插件与指定 URL 上托管的 ChatGPT 应用程序进行交互。然后,代码定义了几个 HTTP 路由,分别对应待办事项列表定义插件的不同功能:
add_todo函数与 POST 请求相关联get_todos函数与 GET请求相关联
接着,代码定义了两个额外的端点:plugin_manifest 和openapi_spec。这两个端点分别用于提供插件清单文件和 OpenAPI 规范,这对于 GPT-4 和插件之间的交互至关重要。这些文件包含有关插件及其 API 的详细信息,GPT-4 使用这些信息来了解何时及如何使用插件。
5.2.3 插件清单
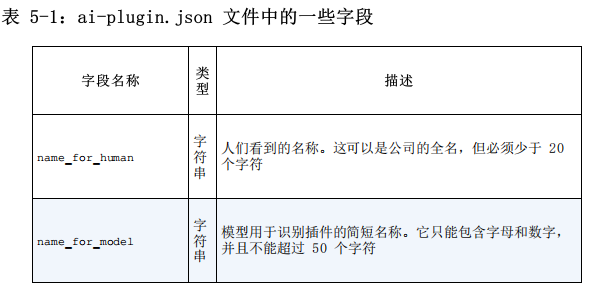
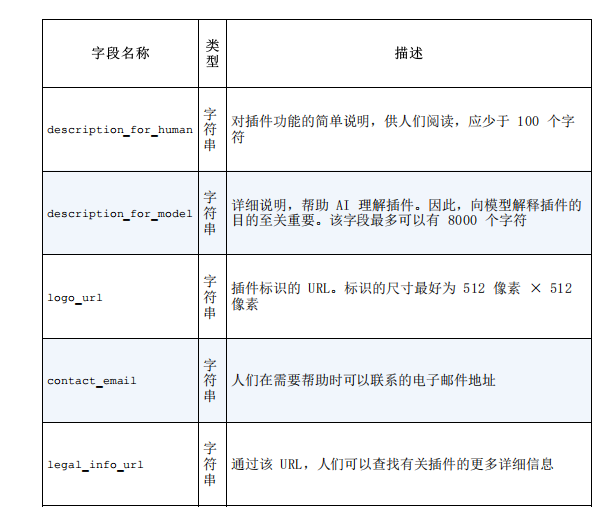
每个插件都需要在 API 域上有一个 ai-plugin.json 文件。举例来说,如果你的公司在 iTuring.cn 上提供服务,那么必须将此文件放在iTuring.cn/.well-known/ 下。在安装插件时,OpenAI 将按照路径/.well-known/ai-plugin.json 查找此文件。如果没有该文件,则无法安装插件。
以下是 ai-plugin.json 文件的极简定义:
{
"schema_version": "v1",
"name_for_human": "TODO Plugin",
"name_for_model": "todo",
"description_for_human": "Plugin for managing a TODO list. You can add, remove and view your TODOs.",
"description_for_model": "Plugin for managing a TODO list. You can add, remove and view your TODOs.",
"auth": {
"type": "none"
},
"api": {
"type": "openapi",
"url": "http://localhost:3333/openapi.yaml",
"is_user_authenticated": false
},
"logo_url": "http://localhost:3333/logo.png",
"contact_email": "[email protected]",
"legal_info_url": "http://thecompany-url/legal"
}
5.2.4 OpenAPI 规范
创建插件的下一步是创建 openapi.yaml 文件。该文件必须遵循 OpenAPI标准。GPT 模型只通过此文件和插件清单文件中的详细信息来了解你的 API。
以下是一个示例,包含待办事项列表定义插件的 openapi.yaml 文件的第一行
openapi: 3.0.1
info:
title: TODO Plugin
description: A plugin that allows the user to create and manage a TODO list using ChatGPT. If you do not know the user s username, ask them first before making queries to the plugin. Otherwise, use the username "global".
version: 'v1'
servers:
- url: http://localhost:5003
paths:
/todos/{username}:
get:
operationId: getTodos
summary: Get the list of todos
parameters:
- in: path
name: username
schema:
type: string
required: true
description: The name of the user.
responses:
"200":
description: OK
content:
application/json:
schema:
$ref: '#/components/schemas/getTodosResponse'
[...]
可以将 OpenAPI 规范视为描述性文档,它足以理解和使用 API。在 GPT-4中进行搜索时,使用 info 部分中的描述来确定插件与搜索内容的相关性。OpenAPI 规范的其余内容遵循标准的 OpenAPI 格式。许多工具可以根据现有的 API 代码自动生成 OpenAPI 规范。
5.2.5 描述
当插件有助于响应用户请求时,模型会扫描 OpenAPI 规范中的端点描述及插件清单文件中的description_for_model 字段。目标是创建最合适的响应,这通常涉及测试不同的请求和描述。OpenAPI 文档应该提供关于 API 的各种细节,比如可用的函数及其参数。它还应包含特定于属性的描述字段,提供有价值的解释,说明每个函数的作用及查询字段期望的信息类型。**关键要素是 description_for_model 字段,强烈建议为该字段创建简明、清晰和描述性强的说明。**在撰写描述时,必须遵循以下最佳实践:
- 不要试图影响 GPT 的“情绪”、个性或确切回应
- 避免指示 GPT 使用特定的插件,除非用户明确要求使用该类别的服务
- 不要为 GPT 指定特定的触发器来使用插件,因为它旨在自主确定何时使用插件
5.3 小结
LangChain 框架和 GPT-4 插件有助于大幅提升 LLM 的潜力。凭借其强大的工具和模块套件,LangChain 已成为 LLM 领域的核心框架。它在集成不同模型、管理提示词、组合数据、为链排序、处理智能体和管理记忆等方面的多功能性为开发人员和 AI 爱好者开辟了新的道路。使用 GPT-4 和 ChatGPT 从头开始编写复杂指令存在局限性。**LangChain 的真正潜力在于创造性地利用各种功能来解决复杂问题,并将通用语言模型转化为功能强大且具体的应用程序。**GPT-4 插件是语言模型和实时可用的上下文信息之间的桥梁。
5.4 总结
可以在 AI 领域中进一步开拓,开发利用这些先进语言模型的应用程序。但请记住,AI 领域的发展是动态的,要时刻关注进展并相应地进行调整。进入 LLM 世界只是开始,探索不应止步于此。鼓励利用新知识探索 AI 技术的未来。