前言
当对机器人动作策略的预测越来越成熟稳定之后(比如ACT、比如扩散策略diffusion policy),为了让机器人可以拥有更好的泛化能力,比较典型的途径之一便是基于预训练过的大语言模型中的广泛知识,然后加一个policy head(当然,一开始背后的模型比较简单,比如有用LSTM或MLP——RoboFlamingo)
再之后,便出来了越来越多成熟稳定的专门的VLA模型,比如OpenVLA,再比如近期介绍过过的π0——用于通用机器人控制的VLA模型:一套框架控制7种机械臂(基于PaliGemma和流匹配的3B模型)
- π0的意义在于,首次用同一套策略/算法操作不同机器人/机械臂,这种基于机器人大模型的「预训练-微调」模式,很快会越来越多(犹如此前大模型革命NLP 其次CV等各模态,目前到了robot领域),算是代表了通用机器人的核心发展方向
- 且π0 比英伟达的HOVER早一点,当然,同时期的RDT GR2也有这个潜力的,期待这两 后续的更新
一个多月前,有朋友曾说,一个月内,π0 会开源来着,当时虽然觉得不太可能,但还是抱着期待,可还是没开..
没开源必然是有点遗憾,故这两天我一直在考虑、对比,看目前哪个vla最逼近π0,然后借鉴π0的思路,去改造该vla
前两天又重点看了下openvla,和cogact,发现
- 目前cogACT把openvla的动作预测换成了dit,在模型架构层面上,逼近了π0
- 那为了进一步逼近,感觉可能会有人把cogACT中的VLM模块(dinov2+sigclip+llama2)换成paligemma
总之,各种vlm + 各种动作预测头/方法,会出来很多vla
而本来OpenVLA、cogACT是另外一篇文章中的内容,但考虑这两模型的重要性,故皆分别独立成文——前者即成本文,后者则另行成文
第一部分 OpenVLA:相当于RT-2的开源版
1.1 OpenVLA:第一个开源的通用VLA模型,类似RT-2
2.1.1 通过Open X-Embodiment中97万机器人数据微调的7B VLA模型
如本文前言所说,24年6月,来自1Stanford University、2UC Berkeley、3Toyota Research Institute、4Google DeepMind、5Physical Intelligence(即推出VLA模型π0的机构)、6MIT推出了OpenVLA
- 其对应的论文为《OpenVLA: An Open-Source Vision-Language-Action Model》
- 其项目地址为:openvla.github.io
其GitHub地址为:github.com/openvla/openvla
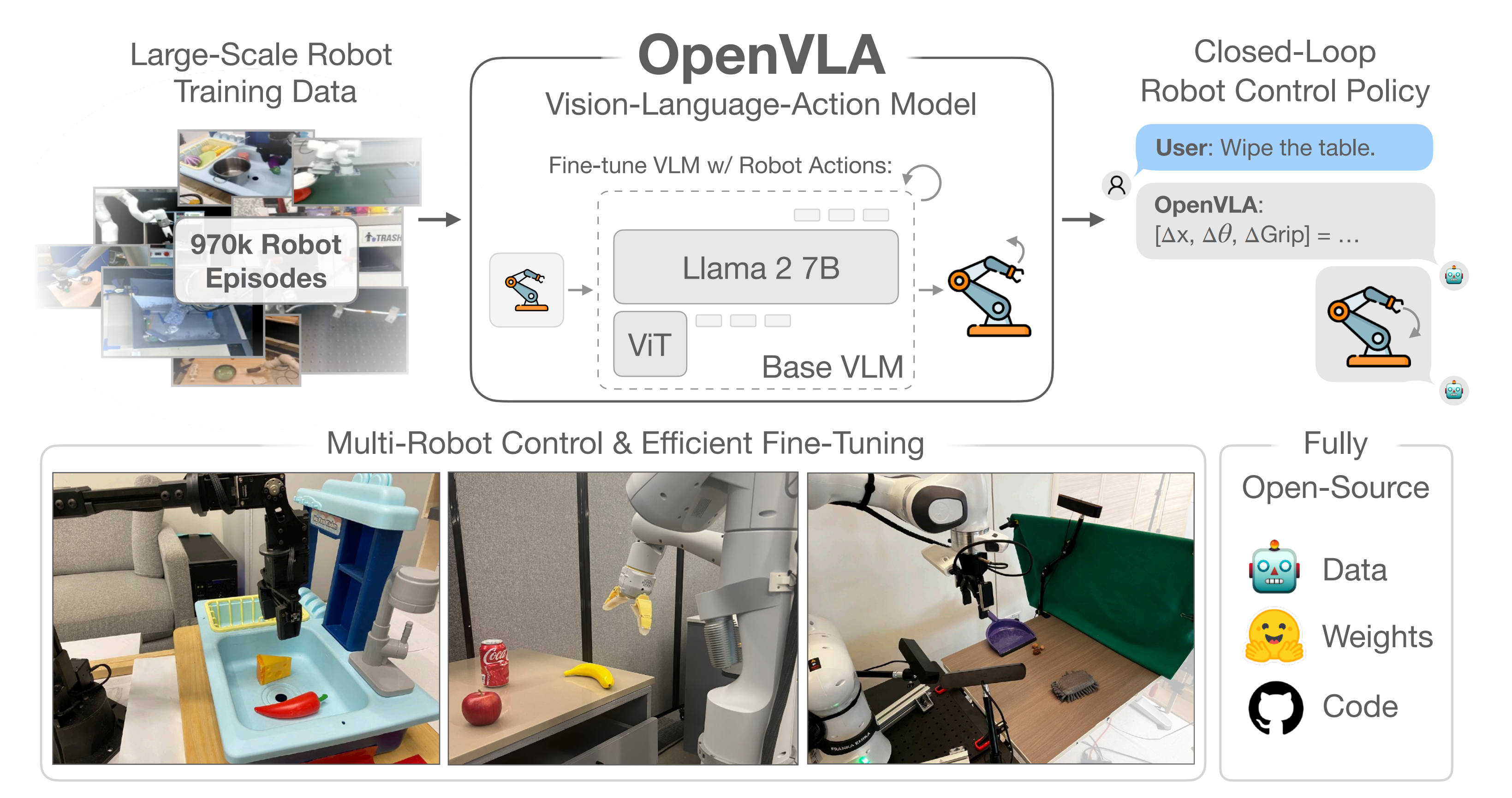
这是一种具有70亿参数的开源视觉-语言-动作模型VLA,由一个预训练的视觉条件语言模型骨干组成,该模型在Open-X Embodiment [1] 数据集中的970k机器人操作轨迹的大型多样数据集上进行了微调
它支持开箱即用地控制多个机器人,并且可以通过参数高效微调快速适应新的机器人领域
1.1.2 背景
可学习或可训练的机器人操作策略的一个关键弱点是它们无法超出其训练数据进行泛化:虽然现有的针对单个技能或语言指令训练的策略能够将行为外推到新的初始条件,如物体位置或光照条件[2,3],但它们缺乏对场景干扰物或新颖物体的鲁棒性[4,5],并且难以执行未见过的任务指令[6,7]
- 然而,在机器人技术之外,现有的视觉和语言基础模型,如CLIP[8]、SigLIP[9]和Llama 2[10],具备这种类型的泛化能力及更多,源于其通过互联网规模的预训练数据集捕获的先验知识
说白了,就是这类视觉或语言模型有比较好的泛化能力 - 尽管在机器人领域复制这种规模的预训练仍然是一个未解决的挑战——即使是最大规模的机器人操作数据集[1,11]也只有10万到100万的例子——这种不平衡表明了一个机会:使用现有的视觉和语言基础模型作为核心构建模块来训练能够泛化到超出其训练数据的物体、场景和任务的机器人策略
说白了,就是把视觉或语言模型的丰富知识(背后对应着丰富数据训练出来的)拿过来用——即其作为基础模块
为实现这一目标,现有工作探索了将预训练的语言和视觉-语言模型整合用于机器人表示学习[12–R3m,14-Cliport],并作为模块化系统中任务规划和执行的组件[15,16-Palm-e,全称Pathways Language Model-Embodied(PaLM-E),是谷歌发布的一个多模态预训练大模型,它从PaLM模型演化而来]
- 最近,这些模型被用于直接学习视觉-语言-动作模型(VLAs;1-Open X-Embodiment Collaboration,7- Rt-2,17,18-Lingo-2)以进行控制
VLAs提供了一种直接使用预训练的视觉和语言基础模型用于机器人的实例化,直接微调视觉条件的语言模型(VLMs),如PaLI [19,20],以生成机器人控制动作
通过利用在互联网规模数据上训练的强大基础模型,诸如RT-2[7]的VLAs展示了令人印象深刻的鲁棒性结果,以及泛化到新对象和任务的能力,设立了通用机器人策略的新标准 - 然而,有两个关键原因阻碍了现有VLAs的广泛使用:
1)当前模型[1,7-Rt-2,17,18]是封闭的,对模型架构、训练过程和数据组合的可见性有限;
2)现有工作未提供将VLAs部署和适应于新机器人、环境和任务的最佳实践,尤其是在商品硬件(例如消费级GPU)上
作者认为,为了为未来的研究和开发奠定丰富的基础,机器人需要开源、通用的VLAs,以支持有效的微调和适应,类似于现有的围绕开源语言模型的生态系统[21–24,比如llama、Mistral等等]
为此,作者推出了OpenVLA
- 由于数据多样性增加和新模型组件的产物,OpenVLA在29个评估任务中相对于WidowX和Google Robot体现的55B参数RT-2-X模型[1,7],即之前的最先进VLA,绝对成功率提高了16.5%
- 还调查了VLAs的高效微调策略,这是一项以前的工作中未探索的新贡献,涉及从物体拾放到清理桌子的7个不同操作任务。他们发现微调后的OpenVLA策略明显优于微调的预训练策略,例如Octo [5]
具体而言,Octo[5]训练了一种通用策略,可以直接控制多种机器人,并允许灵活地微调以适应新的机器人设置。与这些方法和OpenVLA的一个关键区别在于模型架构
像Octo这样的先前工作通常由预训练的组件组成,例如语言嵌入或视觉编码器,并与从头初始化的附加模型组件结合[2,5,6],在策略训练过程中学习将它们“拼接”在一起
与这些工作不同,OpenVLA采用了一种更端到端的方法,直接微调VLM以通过将机器人动作视为语言模型词汇中的token来生成机器人动作。实验评估表明,这种简单但可扩展的流程大大提升了性能和泛化能力,超过了之前的通用策略 - 与从零开始使用扩散策略的模仿学习[3]相比,微调后的OpenVLA在涉及将语言落地到行为的任务上显示出显著的改进
1.2 OpenVLA的模型架构、训练过程、训练数据
1.2.1 模型架构(基于Prismatic-7B VLM):SigLIP、DinoV2、Llama 2
最近的VLM架构[20,42–44,其中的44即指Prismatic vlms:Investigating the design space of visually-conditioned language models,详见下文的第三部分]一般由三部分组成(见图2):
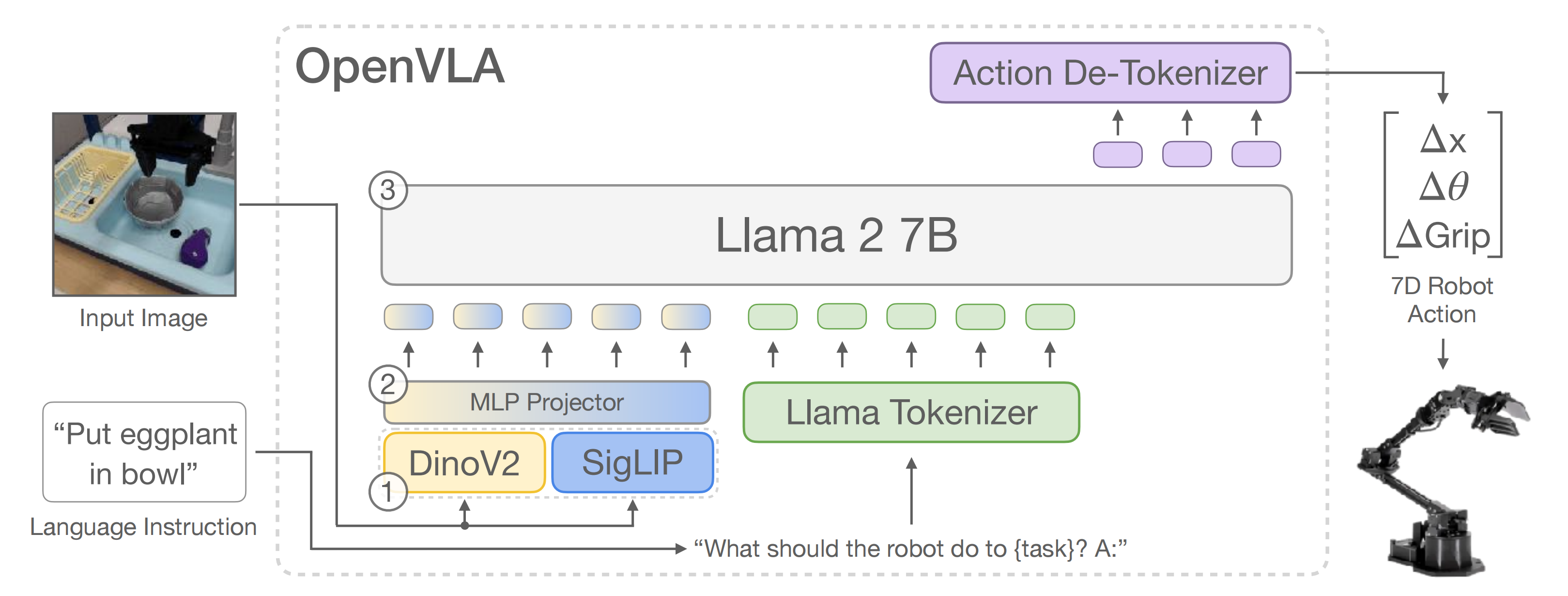
- 一个视觉编码器,将图像输入映射为多个“图像块嵌入”
- 一个投影器,将视觉编码器的输出嵌入映射到语言模型的输入空间
- 一个大型语言模型LLM骨干
最终,基于Prismatic-7B VLM [44-Prismatic vlms:Investigating the design space of visually-conditioned language models,详见下文的第三部分]的标准进行构建,其具有
- 一个600M参数的视觉编码器:SigLIP 和DinoV2
值得注意的是,Prismatic使用了一个两部分的视觉编码器,由预训练的SigLIP [79,在400亿图文对上进行训练]和DinoV2 [25,在12亿张图片上训练]模型组成。输入图像块分别通过两个编码器传递,结果特征向量在通道上连接
与更常用的视觉编码器如CLIP- [80]或SigLIP-only编码器相比,添加DinoV2特征已被证明有助于改善空间推理[44],这对机器人控制特别有帮助
说个题外话,作者还实验了一个OpenVLA模型的版本——即openvla-v01-7b:开发期间使用的早期模型,由 Prismatic siglip-224pxVLM(单一 SigLIP 视觉主干和 Vicuña v1.5 LLM)训练而成,该版本使用较小的机器人数据混合进行预训练(与Octo相同的OpenX数据集混合)
有意思的是,这种「仅使用SigLIP [79]视觉骨干而不是融合的Dino + SigLIP编码器的架构」在微调任务和“开箱即用”任务中仍能取得强劲的性能 - 一个小型2层MLP投影器
- 以及一个70亿参数的Llama 2语言模型骨干[10]
至于为何基于Prismatic-7B构建OpenVLA呢
- 起初,作者尝试了多种 VLM 主干
除了 Prismatic [44],他们还测试了微调 IDEFICS-1 [84] 和 LLaVA [85] 以预测机器人动作- 他们发现LLaVA 和 IDEFICS-1 在只有一个物体的场景任务中表现相当,但在涉及多个物体并要求策略操控正确物体(即语言指令中指定的物体)的任务中,LLaVA 展示了更强的语言基础
具体而言,LLaVA 在 BridgeData V2 水槽环境的五个语言基础任务中平均绝对成功率比 IDEFICS-1 提高了 35%- 微调的 Prismatic VLM 策略实现了进一步的改进,在简单的单物体任务和多物体语言基础任务中,绝对成功率比 LLaVA 策略高出约 10%
- 作者将这种性能差异归因于融合的 SigLIP-DinoV2 主干提供的改进的空间推理能力
- 除了性能增强外,Prismatic 还提供了模块化且易于使用的代码库,因此最终选择它作为 OpenVLA 模型的主干
至于对于图像分辨率、训练轮次、学习率的问题
- 对于输入图像的分辨率
对 VLA 训练的计算要求有显著影响,因为更高分辨率的图像会产生更多的图像patch token,从而导致训练计算量呈二次增长。作者比较了224×224 像素和 384×384 像素输入的 VLA,但在评估中未发现性能差异,而后者训练时间是前者的三倍。因此,最终选择 224×224 像素分辨率- 对于训练轮次
典型的 LLM 或 VLM 训练最多只通过其训练数据集一到两次。相比之下,发现对于 VLA 训练来说,通过训练数据集的次数要显著增加,实际机器人性能会不断提高,直到训练动作token准确率超过 95%
最终训练运行通过其训练数据集完成了 27 个轮次- 对于学习率
作者在多个数量级上对 VLA 训练的学习率进行了全面搜索,使用固定学习率 2e-5(与 VLM 预训练期间使用的学习率相同 [44])取得了最佳结果。且他们没有发现学习率预热带来任何好处
SigLIP、DinoV2和Llama 2没有公布其训练数据的详细信息,训练数据可能分别由数万亿个来自互联网的图像-文本、仅图像和仅文本数据组成
Prismatic VLM在这些组件的基础上使用LLaVA 1.5数据混合[43]进行微调,数据混合包含来自开源数据集[29,42,81–83]的大约100万图像-文本和仅文本数据样本
1.2.2 微调Prismatic-7B VLM,使其输出机器人动作
为了训练 OpenVLA ,作者对预训练的 Prismatic-7B VLM 骨干网络进行微调,以进行机器人动作预测
作者将动作预测问题表述为一个“视觉-语言” 任务,其中输入观察图像和自然语言任务指令被映射为一串预测的机器人动作
- 为了使 VLM 的语言模型骨干能够预测机器人动作,作者通过将连续的机器人动作映射到语言模型的分词器使用的离散token来表示 LLM 的输出空间中的动作
To enable the VLM’s language model backbone to predict robot actions, we represent the actions in the output space of the LLM by mapping continuous robot actions to discrete tokens used by the language model’s tokenizer.
类似 Brohan 等人的方法[7-Rt-2]——基于下一个token预测技术预测动作token,作者将机器人的每个动作维度分别离散化为 256 个箱子中的一个
Following Brohan et al. [7], we discretize each dimension of the robot actions separately into one of 256 bins. - 对于每个动作维度,作者设置箱子的宽度以均匀划分训练数据中动作的
和
分位数之间的区间
For each action dimension, we set the bin width to uniformly divide the interval between the 1st and 99th quantile of the actions in the training data.
使用分位数而不是 Brohan等人[7] 使用的最小-最大边界,使得能够忽略数据中的异常动作,否则这些异常动作可能会极大地扩展离散化区间并降低动作离散化的有效粒度
Using quantiles instead of the min-max bounds Brohan et al. [7] used allows us to ignore outlieractions in the data that could otherwise drastically expand the discretization interval and reduce the effective granularity of our action discretization. - 使用这种离散化方法,作者为一个N维的机器人动作获得了N个离散整数∈[0...255]。不幸的是,OpenVLA的语言骨干使用的分词器Llama分词器[10]仅为微调期间新引入的词保留了100个“特殊词”,这对于作者动作离散化的256个词来说太少了
因此,作者再次选择简单的方法,遵循Brohan等人[7]的方法,简单地用动作词覆盖Llama分词器词汇中使用最少的256个词(对应于最后的256个词)「Instead, we again opt for simplicity and follow Brohan et al. [7]’s approach by simply overwriting the 256 least used tokens in the Llama tokenizer’svocabulary (which corresponds to the last 256 tokens) with our action tokens」
一旦这些动作被处理成一个词序列,OpenVLA就会使用标准的「下一个词预测目标」进行训练,仅对预测的动作词计算交叉熵损失
1.2.3 训练数据
一方面,OpenVLA用Open X-Embodiment数据集[1](OpenX)作为基础来策划训练数据集。在撰写本文时,完整的OpenX数据集由超过70个单独的机器人数据集组成,包含超过200万条机器人轨迹
为了使在这些数据上进行训练变得可行,作者对原始数据集应用了多个步骤的数据整理
- 所有训练数据集之间的输入、输出空间一致
为了实现这个目的,可以遵循[1,5]并限制训练数据集仅包含至少有一个第三人称摄像机的操作数据集,并使用单臂末端执行器控制 - 在最终训练组合中具有平衡的embodiments
位了达到这个目的,利用Octo[5]的数据混合权重来处理所有通过第一轮筛选的数据集,Octo启发式的降低或移除多样性较低的数据集,并增大任务和场景多样性比较大的数据集的权重
此外,作者还尝试将自Octo发布以来添加到OpenX数据集中的一些额外数据集整合到OpenVLA的训练混合中,包括DROID数据集[11],虽然其混合权重保守设定为10%
- 不过考虑到在实践中,发现DROID上的动作token准确率在整个训练过程中保持较低,表明未来可能需要更大的混合权重或模型来适应其多样性
- 故为了不影响最终模型的质量,作者在最后三分之一的训练中将DROID从数据混合中移除
最终,在附录A中提供了所用数据集和混合权重的完整概述
1.2.4 训练和推理的基础设施
最终的 OpenVLA 模型在一个由 64 个 A100 GPU 组成的集群上训练了 14 天,总计 21,500 A100 小时,使用的批量大小为 2048
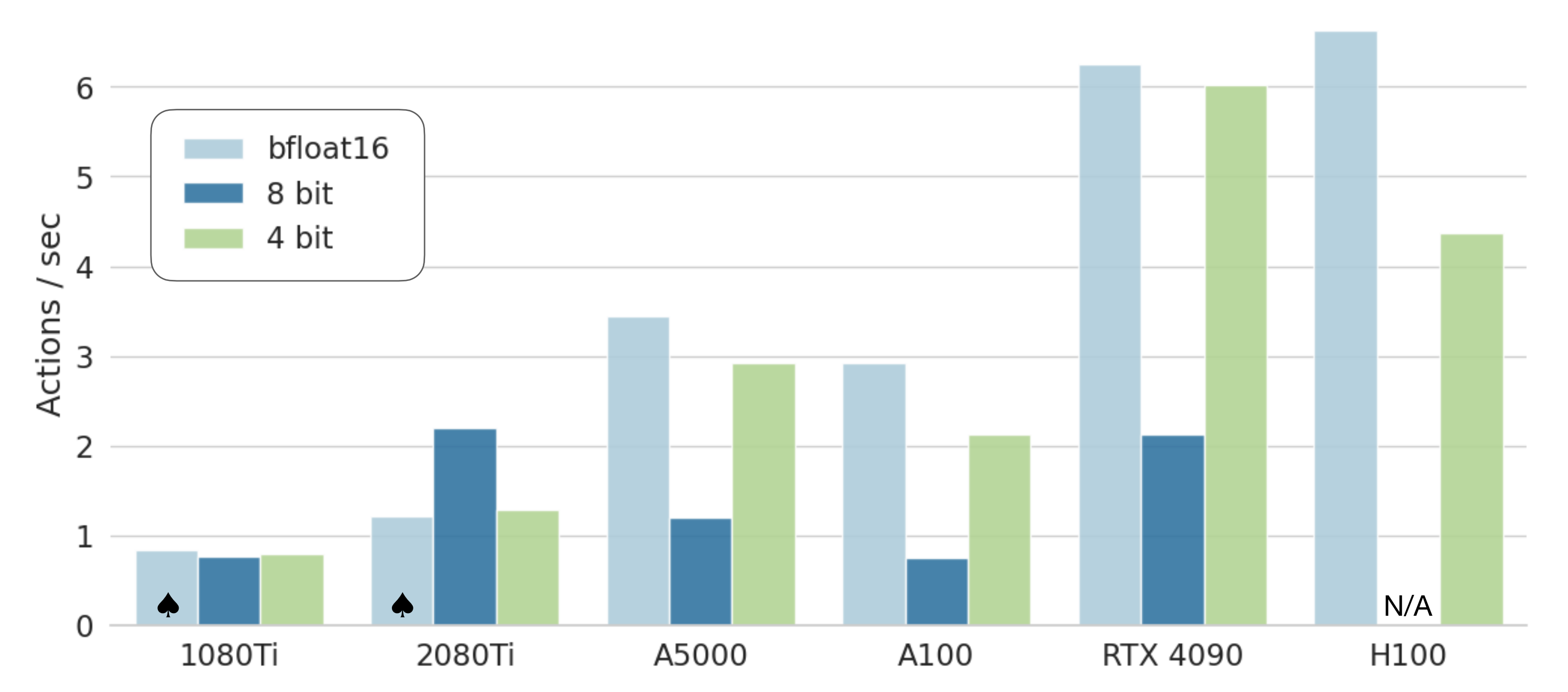
- 在推理过程中,OpenVLA 在加载为 bfloat16 精度(即未量化)的情况下需要 15GB 的 GPU 内存,并在一块NVIDIA RTX 4090 GPU 上以大约 6Hz 的速度运行(未进行编译、推测解码或其他推理加速技巧)
且如原论文第 5.4 节所示,他们可以通过量化进一步减少 OpenVLA 在推理过程中的内存占用,而不会影响在实际机器人任务中的性能
在下图图 6 中报告了各种消费级和服务器级 GPU 上的推理速度 - 且为了方便起见,我们实现了一个远程 VLA 推理服务器,以允许将动作预测实时远程流式传输到机器人上——消除了需要访问强大本地计算设备来控制机器人的要求。我们将此远程推理解决方案作为我们开源代码发布的一部分
值得一提的是,作者除了提供模型之外,还发布了OpenVLA代码库,这是一个用于训练VLA模型的模块化PyTorch代码库:openvla.github.io
- 该代码库可以从在单个GPU上微调VLA扩展到在多节点GPU集群上训练具有十亿参数的VLA,并支持现代大型Transformer模型训练的技术包括自动混合精度(AMP,PyTorch [75])、FlashAttention [76] 和完全分片数据并行(FSDP,Zhao等[77])
- 而且还可以做到开箱即用,OpenVLA代码库完全支持在Open X数据集上进行训练,与HuggingFace的[21]AutoModel类集成,并支持LoRA微调[26]和量化模型推理[27,88]
1.3 实验:与RT-2、Octo、Diffusion Policy的对比,以及LoRA微调
1.3.1 与RT-2的横向对比:除了语义泛化外,均强于RT-2
为了进一步评估OpenVLA 的” 开箱即用” 性能:作者把OpenVLA放到以下两个平台测试

- 一个是来自BridgeData V2 评估的WidowX 机器人[6](见上图图1,左)
- 一个是来自RT-1 和RT-2 评估的移动操作机器人[2, 7](”Google 机器人”;见上图图1,中)
这两个平台在之前的工作中已被广泛用于评估通用机器人策略[1, 2, 5, 7]
- 作者在每个环境中定义了一套全面的评估任务,涵盖各种泛化轴
如视觉(未见过的背景、干扰物体、物体的颜色/外观);
运动(未见过的物体位置/方向);
物理(未见过的物体大小/形状);
以及语义(未见过的目标物体、指令和来自互联网的概念)泛化 - 还评估了在具有多个物体的场景中语言调节能力,测试策略是否可以根据用户的提示操控正确的目标物体
总体而言
- 他们在BridgeData V2 实验中对每种方法进行了170 次展开评估(17 个任务,每个任务10 次试验)
结果显示,OpenVLA在大多数任务中表现最强,并且在通用策略中具有最高的总体成功率。RT-2-X也表现良好,优于RT-1-X和Octo「RT-1-X和Octo在这些泛化任务中通常遇到困难」,但不如OpenVLA
尽管OpenVLA的规模小了一个数量级(7B对55B参数)
从质量上看,发现RT-2-X和OpenVLA都表现出明显更强的行为稳定性,例如在存在干扰物体时接近正确的物体,正确调整机器人的末端执行器以与目标物体的方向对齐,甚至从抓取不牢的错误中恢复(参见https://openvla.github.io获取定性回放示例)
但RT-2-X在语义泛化任务中取得了更高的性能,如上图图3所示,这也在预料之中,因为它使用了更大规模的互联网预训练数据,并与机器人动作数据和互联网预训练数据共同微调,以更好地保留预训练知识,而不是单独微调 - 在Google 机器人实验中进行了60 次展开评估(12 个任务,每个任务5 次试验)。所有任务的详细分类及其与训练数据的差异在附录B
总体而言,发现RT-1-X和Octo在评估任务中遇到了困难;在多个任务中,它们通常无法在五次试验中取得一次成功。另一方面,RT-2-X和OpenVLA表现出强劲的性能,在五次试验中至少完成每个任务两次;这两个VLA策略在这个特定的评估套件中表现相当
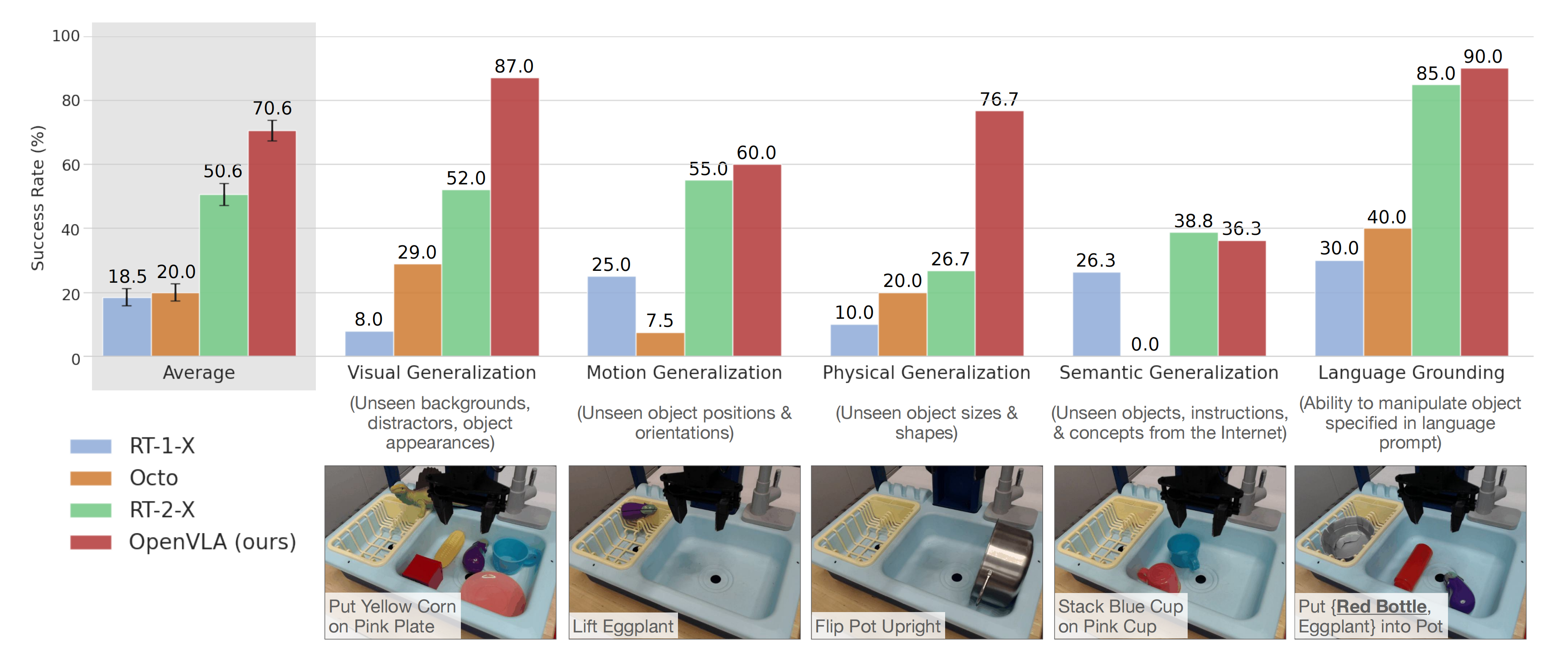
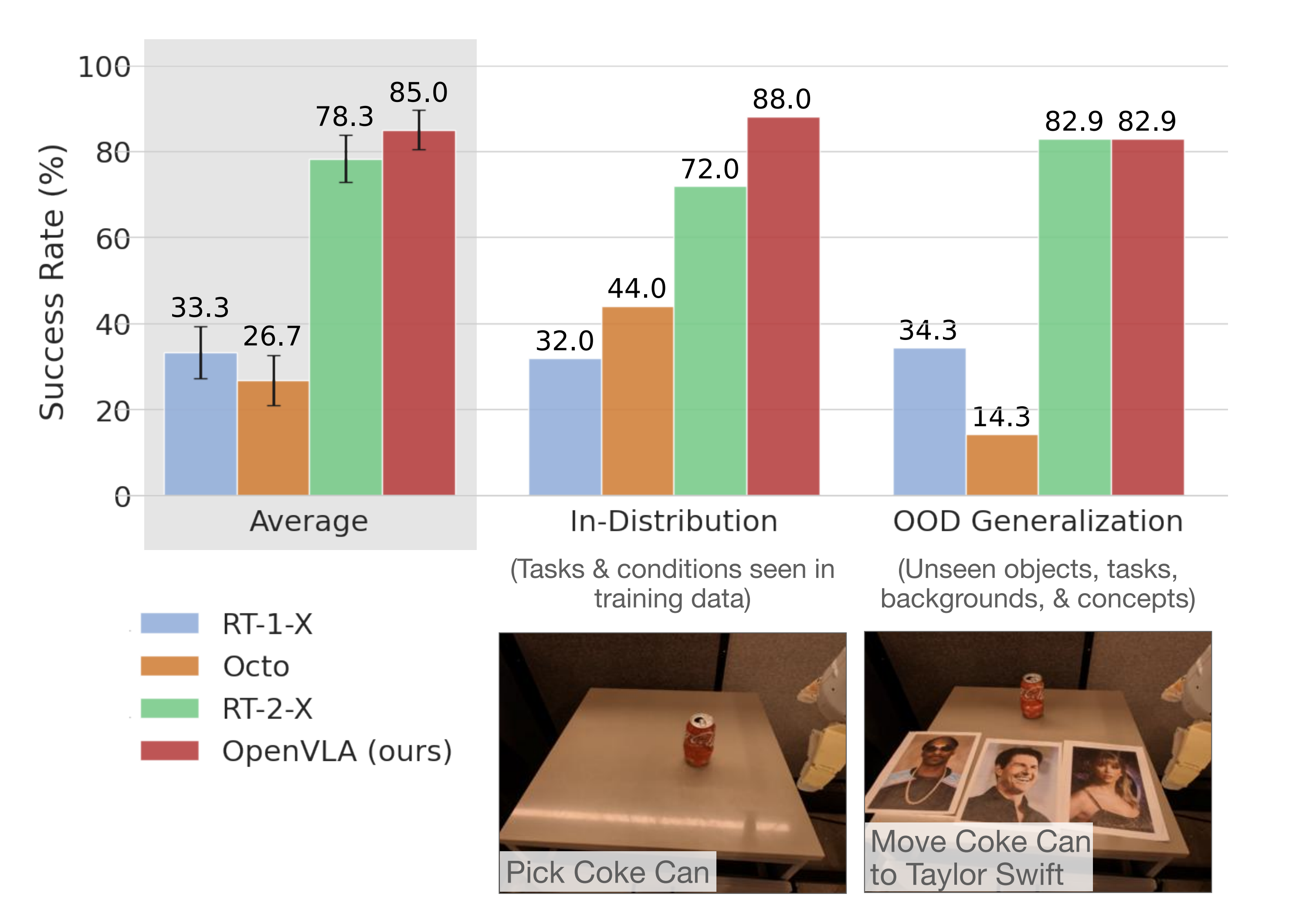
尽管在Google机器人评估中,在一些任务上,OpenVLA的表现与RT-2-X相当,然而,在BridgeData V2和Google机器人评估的全部任务里,OpenVLA的整体表现略胜一筹。这种性能差异可归因于多种因素的结合:
- 为OpenVLA策划了一个更大的训练数据集,包含970k个轨迹(相比之下,RT-2-X为350k);
- OpenVLA使用了融合的视觉编码器——SigLIP-DinoV2,该编码器结合了预训练的语义和空间特征
- OpenVLA对训练数据集进行了更仔细的清理,例如,过滤掉了Bridge数据集中全零的动作
因为原始版本的BridgeData V2 数据集包含许多全零(无操作)动作的转换。例如,在每个演示中,全零动作在第一个时间步被记录为真实动作。因此,在没有任何数据预处理的情况下,在原始数据集上训练一个高度表达的VLA 模型导致了一个频繁预测全零动作并在评估中卡住的策略
因此,在训练OpenVLA 模型时简单地过滤掉了每个演示中的第一个转换,这在大多数情况下足以缓解冻结行为
考虑到由于这是一个我们无法重新训练的专有模型(例如,使用预处理过的 BridgeDataV2 数据集版本),只好通过简单地查询模型的第二最可能动作来缓解这一问题,因为第一最可能动作通常全为零,而第二最可能动作不是——而这也是 RT-2-X 模型的开发者在 Open X-Embodiment 实验中报告的 BridgeData V2 评估中应用的相同变通方法,即始终查询第二可能动作
1.3.2 与Diffusion Policy的对比实验
作者还将OpenVLA与Diffusion Policy[3]、Diffusion Policy(matched)进行比较,后者是一种与OpenVLA输入和输出规格匹配的Diffusion Policy版本
- 此外,作者评估在目标数据集上微调的Octo[5],因为它目前是支持微调的最佳通用策略(通过其推理API不支持RT-2-X的微调)
- 且还在相同的目标数据集上微调OpenVLA,得到的策略称为OpenVLA
- 最后,作为消融实验,作者与OpenVLA(从头开始)——即OpenVLA(scratch)进行比较,在该实验中,作者直接在目标机器人设置上微调基础Prismatic VLM,而不是微调OpenX预训练的OpenVLA模型,以评估大规模机器人预训练的好处
作者在原论文的图5中展示了结果(每项任务的详细信息见附录,表7)
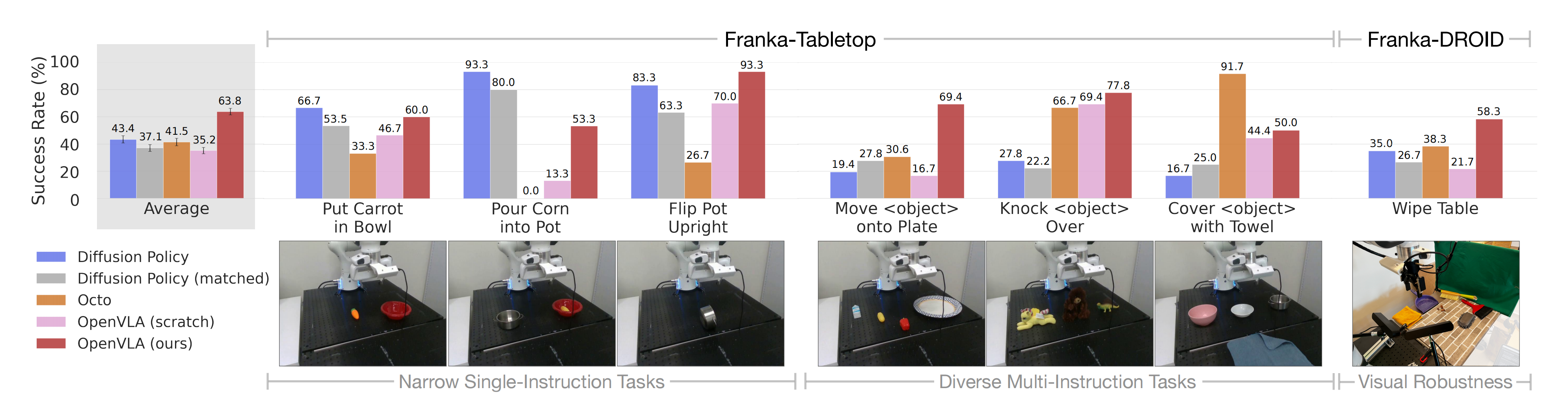
作者发现,在针对上图的这7个任务中(这7个任务分别是:将胡萝卜放入碗中、将玉米倒入锅中、将锅翻转为直立,将物体移动到盘子上、将物体击倒、用毛巾覆盖物体,擦拭表面)
- Diffusion Policy的两个版本在诸如“将胡萝卜放入碗中”和“将玉米倒入锅中”这样的单一指令任务中(single instruction tasks,见上图左侧的前三个任务),与或超过了通用策略Octo和OpenVLA的竞争力
如此说明,对于较狭窄但高度灵活的任务,Diffusion Policy仍显示出更平滑和精确的轨迹;在Diffusion Policy中实施的动作分块和时间平滑—— action chunking and temporal smoothing,可能有助于OpenVLA达到同样的灵活性水平,并可能成为OpenVLA未来改进的一个有前途的方向 - 但在涉及场景中多个对象并需要语言调节的更为多样化的微调任务中(见上图右侧的multi instruction tasks),预训练的通用策略表现更佳
比如Octo和OpenVLA的OpenX预训练使得模型能够更好地适应这些 “语言基础至关重要的更为多样化” 的任务;这点从OpenVLA(scratch)较低的性能中便可以看出来
1.3.3 参数高效微调:LoRA微调效果逼近全量微调
一般的VLM训练方法包括
- 全量微调
在微调过程中更新所有权重 - 仅微调网络的最后一层last layer only
仅微调OpenVLA的transformer骨干的最后一层和token嵌入矩阵 - 冻结视觉
冻结视觉编码器,但微调所有其他权重 - sandwich fine-tuning
解冻视觉编码器、token嵌入矩阵和最后一层「unfreezes thevision encoder, token embedding matrix, and last laye」 - LoRA微调
使用Hu等人[26]提出的流行的low-rank adaptation「详见此文《LLM高效参数微调方法:从Prefix Tuning、Prompt Tuning、P-Tuning V1/V2到LoRA、QLoRA(含对模型量化的解释)》的第4部分」,应用于模型的所有线性层
最终发现
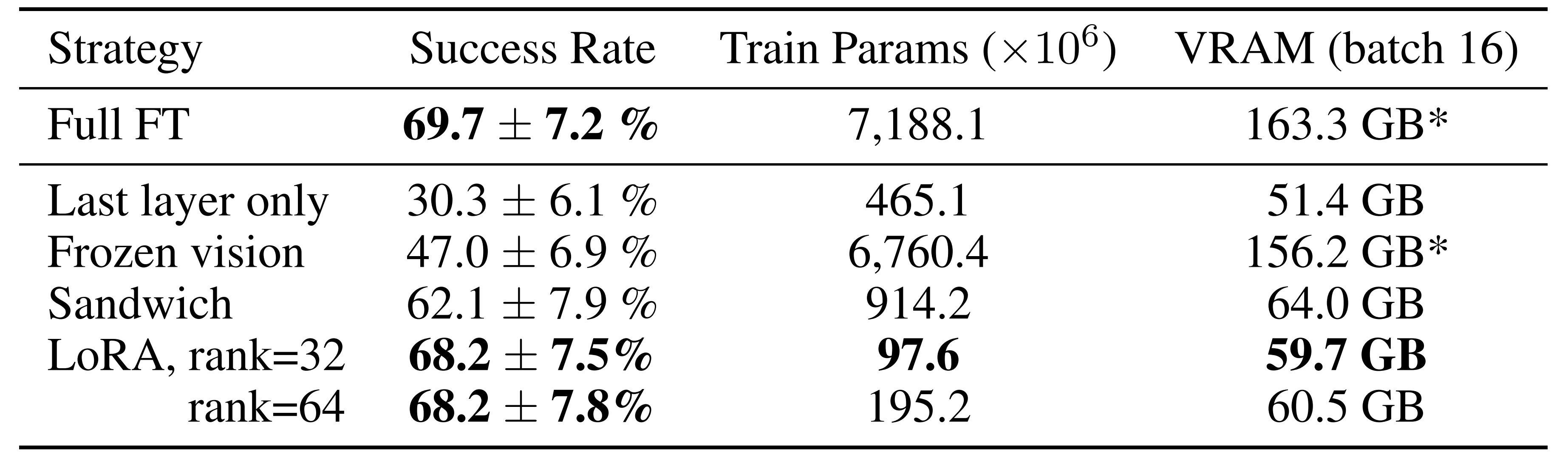
- 发现仅微调网络的最后一层或冻结视觉编码器导致性能不佳,这表明视觉特征对目标场景的进一步适应是至关重要的
- 相比之下,”sandwich fine-tuning” 通过微调视觉编码器实现了更好的性能,并且由于不需要微调完整的LLM 主干,它消耗更少的GPU 内存
- 最后,LoRA 在性能和训练内存消耗之间实现了最佳平衡,优于”sandwichfine-tuning” 并且在仅微调1.4 % 参数的情况下匹配了完整微调的性能
且发现LoRA 的rank 对策略性能的影响可以忽略不计,因此建议使用默认rank r = 32
总之,使用LoRA,可以在单个A100 GPU 上在10-15 小时内微调OpenVLA 到新任务上——与完整微调相比,计算减少了8x
最终,OpenVLA以bfloat16精度保存和加载用于推理(默认方法),这将内存占用减少了一半,使能够在只有16GB的GPU上提供OpenVLA服务
第二部分(选读) Prismatic VLM
2.1 Prismatic VLM
2.1.1 Prismatic VLM
在先前的工作(Tan & Bansal,2019;Li etal.,2022;2023b)中,新的VLMs采用了一种简单的方法,将预训练视觉骨干(例如CLIP;Radford etal.,2021)的patch特征视为可以投射到语言模型(LM)输入空间的token「new VLMs adopt a simple approach, treating patch features from pretrained visual backbones (e.g., CLIP; Radford et al.,2021) as tokens that can be projected into the input space of a language model (LM)」
- 这种“patch-as-token”的方法使得训练可以采用一个简单的目标——下一个token预测——并允许利用强大LMs的生态系统,例如Llama-2和Mistral(Touvron etal.,2023;Jiang et al.,2023),以及有效训练它们的工具(例如,FSDP;Zhao et al.,2023)
- 这种组合推动了模型的快速发展和发布,例如LLaVa v1.5和PALI-3,这些模型采用相同的基本配方,同时在预训练组件、数据或优化程序的选择等个别成分上有所不同
不过,VLM到底该怎么设计性能更优,换言之,哪些关键设计决策会影响VLM的能力和下游使用?为了回答这个问题
24年2月,来自1Department of Computer Science, Stanford University, Stanford, CA, USA、2Toyota Research Institute, Los Altos, CA, USA的研究者发布了一个工作《Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models》
这项工作探索了开发VLM的四个关键设计轴:1)优化过程,2)图像处理和预训练视觉表示,3)语言模型,以及4)围绕训练时间和数据的扩展属性(左)。为了实现这一探索,发布了一个用于高效训练VLM的开源、灵活代码库(右)
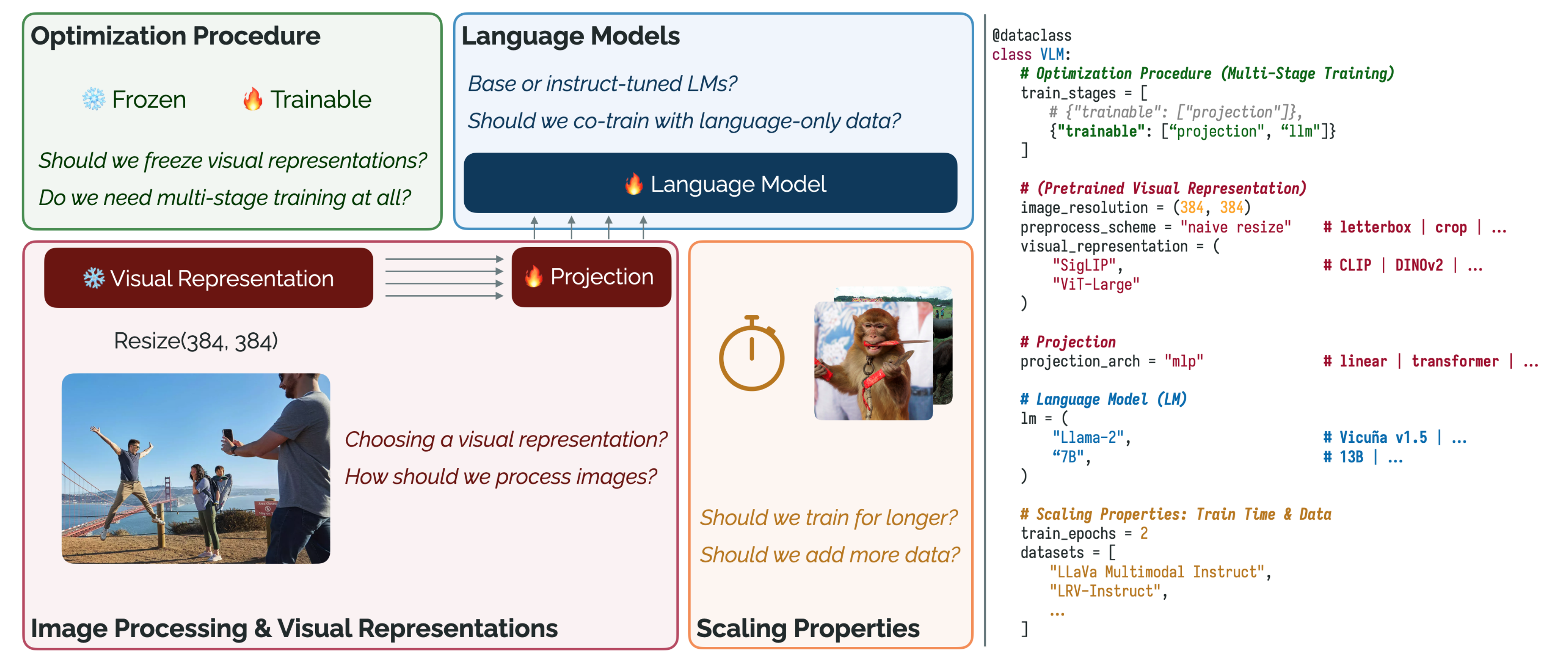
具体而言
- 首先,为了提供对VLM 能力的细粒度洞察,他们编制了一个标准化的评估套件,包括来自视觉与语言文献的十二个基准,包括
四个涉及视觉问答的任务(Bigham et al., 2010; Goyal et al., 2017; Hudson &Manning, 2019; Singh et al., 2019),
四个涉及目标定位的任务(Kazemzadeh et al., 2014; Yu et al., 2016;Wang et al., 2021),
以及四个评估细粒度空间推理、幻觉和图表理解的挑战任务(Acharya et al., 2018; Liuet al., 2022; Li et al., 2023d; Kembhavi et al., 2016) - 其次,他们开发了一个优化的模块化代码库用于VLM训练,强调灵活性,使用户可以轻松替换预训练组件、优化程序、数据等(图2;右)
- 第三,他们利用这些资源贡献进行有针对性的实验,探索四个关键设计轴(图2;左):
1)优化程序,
2)图像处理和视觉表示,
3)语言模型,
4)训练时间和数据的扩展
且作者识别出了一些洞察;例如,发现现有工作采用的多阶段训练程序可以在不影响性能的情况下消除,从而减少20-25 % 的计算成本。还发现融合来自不同骨干的特征的视觉骨干,如CLIP(Radford et al., 2021)和DINOv2(Oquab et al., 2023),在各方面都能导致更高性能的VLM
最后,他们整合了他们的发现,并在7B/13B 规模上训练了一系列模型PRISMs,其严格优于最新的开放VLM,如InstructBLIP 和LLaVav1.5
// 待更
2.1.2 模型架构
在模型架构上,他们采用了许多近期VLM(如LLaVa、Qwen-VL 和PaLI-3)使用的通用架构(Liu et al.,2023c; Bai et al., 2023; Chen et al., 2023b)
这些架构使用一个(预训练的)视觉骨干网络将输入图像映射为一系列patch特征,然后将这些特征单独投影到LM 的嵌入空间中
形式上,一个VLM 接收输入图像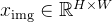
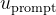
这些输入然后被送入以下组件:
- 视觉表示骨干
首先处理,通过视觉表示骨干网络
输出一系列特征
,其中
例如,可能是Vision Trans-former(ViT; Dosovitskiy 等,2021)输出的patch 特征
- 视觉-语言投影器Vision-Language Projector
接下来,通过一个学习到的投影器将
映射到一个嵌入序列
,其中
- 语言模型
最后,将序列与文本提示嵌入
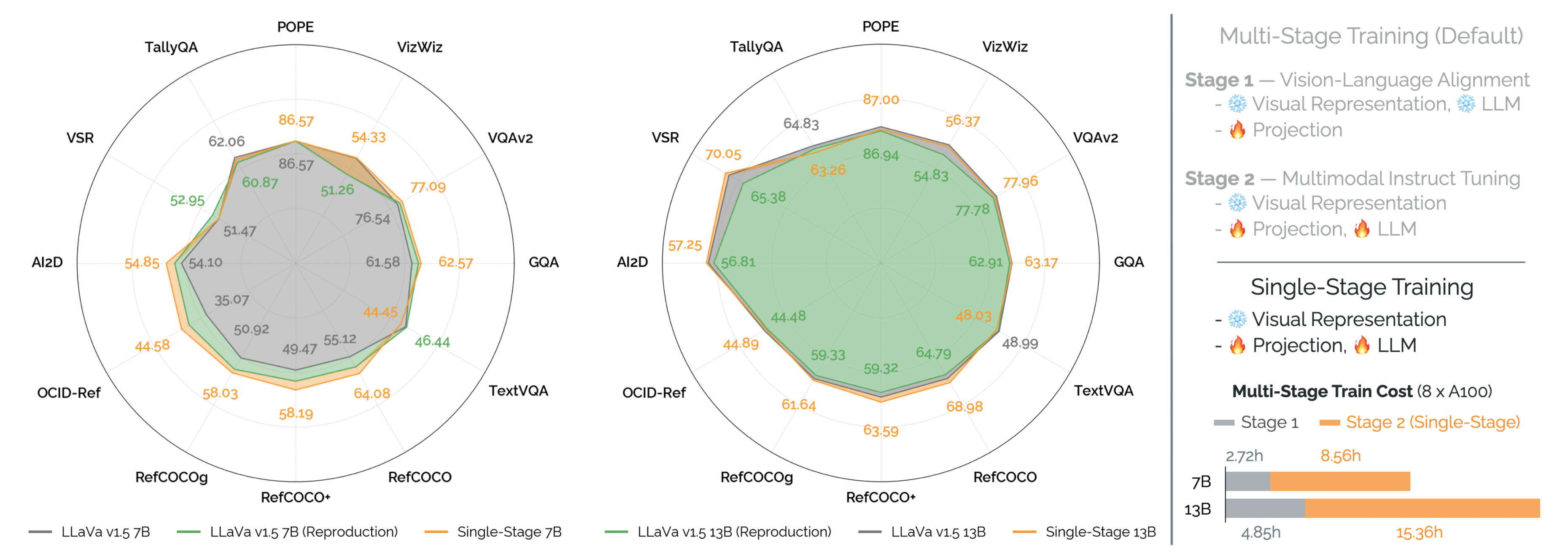
连接,将结果传递给语言模型。语言模型生成输出文本
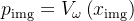
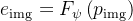
![u_{\text {gen }}=\mathrm{LM}_{\theta}\left(\left[e_{\text {img }} ; e_{\text {prompt }}\right]\right)](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT91XyU3QiU1Q3RleHQlMjAlN0JnZW4lMjAlN0QlN0QlM0QlNUNtYXRocm0lN0JMTSU3RF8lN0IlNUN0aGV0YSU3RCU1Q2xlZnQlMjglNUNsZWZ0JTVCZV8lN0IlNUN0ZXh0JTIwJTdCaW1nJTIwJTdEJTdEJTIwJTNCJTIwZV8lN0IlNUN0ZXh0JTIwJTdCcHJvbXB0JTIwJTdEJTdEJTVDcmlnaHQlNUQlNUNyaWdodCUyOQ%3D%3D)
组合![\operatorname{LM}_{\theta}\left(\left[F_{\psi}\left(V_{\omega}\left(o_{\mathrm{rgb}}\right)\right) ; \operatorname{embed}\left(u_{\text {prompt }}\right)\right]\right)](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUNvcGVyYXRvcm5hbWUlN0JMTSU3RF8lN0IlNUN0aGV0YSU3RCU1Q2xlZnQlMjglNUNsZWZ0JTVCRl8lN0IlNUNwc2klN0QlNUNsZWZ0JTI4Vl8lN0IlNUNvbWVnYSU3RCU1Q2xlZnQlMjhvXyU3QiU1Q21hdGhybSU3QnJnYiU3RCU3RCU1Q3JpZ2h0JTI5JTVDcmlnaHQlMjklMjAlM0IlMjAlNUNvcGVyYXRvcm5hbWUlN0JlbWJlZCU3RCU1Q2xlZnQlMjh1XyU3QiU1Q3RleHQlMjAlN0Jwcm9tcHQlMjAlN0QlN0QlNUNyaWdodCUyOSU1Q3JpZ2h0JTVEJTVDcmlnaHQlMjk%3D)

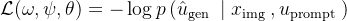
2.1.3 预训练数据集及训练实施
对于预训练数据集,具体使用LLaVa v1.5数据混合,其中包含两个用于多阶段训练管道的子集
- 第一个子集由来自各种字幕数据集(例如,Conceptual Captions,LAIONSharma等,2018; Schuhmann等,2021)的558K样本混合组成
- 而第二个子集由665K多模态指令调优示例组成,这些示例包括Liu等(2023c)生成的合成数据,以及来自现有视觉-语言训练集(例如,GQA, TextCaps; Hudson &Manning, 2019; Sidorov等,2020)的示例,特别是来自ShareGPT(ShareGPT, 2023)的语言仅数据样本
对于训练实施,为了得到高效且灵活的VLM训练代码,且能够轻松更换视觉和语言模型的骨干网络,并处理任意优化过程(例如,在训练期间冻结视觉骨干网络)
基于这些要求,作者在PyTorch中实现了Prismatic VLM的训练代码库,使用了完全分片数据并行(FSDP;Zhao等,2023)和BF16混合精度
- FSDP使我们能够为单个模型组件指定精度(例如,视觉骨干网络使用FP16,语言模型使用BF16),实现不同硬件的可移植性,并提供最小的实现开销
- 且遵循先前工作的可重复性实践(Karamcheti等,2021;Biderman等,2023),在训练期间固定初始化随机性和批次顺序
以及利用TIMM(Wightman,2019)和Hugging Face Transformers(Wolf等,2019)来提供预训练模型
为了验证Prismatic VLM的代码,作者在7B和13B参数规模上进行了一次LLaVa v1.5(Liu et al.,2023b)的同类重现
- 发现Prismatic VLM的实现比参考的LLaVav1.5训练实现效率高得多:在相同硬件上进行基准测试时(一个配备8个A100 GPU的AWSp4de.24xlargenode),观察到使用我们基于FSDP的实现步长时间快了20%,这在LLaVa利用了优化良好的DeepSpeed ZeRO库(Rasley et al.,2020)的情况下是一个显著的提升
- 且与其他开源代码库不同,提供了一个模块化且富有表现力的接口,可以轻松指定或添加模型组件、优化过程和数据,只需进行最少的代码更改(图2;右)
2.2 实验:4个关键设计的考量点
2.2.1 多阶段训练
许多VLM(Chen et al., 2023a; Ye et al.,2023)采用的一种普遍设计选择是包含一个两阶段的训练流程:
- 对齐阶段,通过单独训练随机初始化的投影器
- 微调阶段,此时只有视觉表示被冻结,同时训练投影和LM
此外,现有VLMs 中利用预训练视觉表示的另一个流行设计选择是在整个训练过程中保持视觉骨干不变(Liu et al., 2023b; Driess et al.,2023; Li et al., 2023b)。这种选择限制了在训练过程中学习改进的视觉表示以促进语言生成的潜力
那通过微调包括视觉骨干在内的完整模型,是否有可能提高VLM 性能?
最终发现情况并非如此,微调视觉骨干显著降低了性能(p = 0.00381 ),尤其是在需要细粒度空间推理的任务上,如RefCOCO和OCID-Ref
2.2.2 图像处理与视觉表示
首先,对于预训练视觉表示的选择问题上,尽管有大量在不同数据源上训练的视觉表示,CLIP (Radford et al., 2021) 已成为几乎所有VLM 的默认视觉表示选择。在这个实验中,作者
- 对CLIP、SigLIP (Zhai et al., 2023)、DINOv2(Oquab et al., 2023) 和一个标准的用于分类的预训练视觉Transformer(在ImageNet-21K 上预训练,在ImageNet-1K 上微调;
- Dosovitskiy et al., 2021; Steineret al., 2021)进行逐一比较
为了公平比较,使用ViT-Large 模型变体,作者发现(图6;左)使用视觉-语言对比目标训练的骨干网络(即CLIP, SigLIP)的性能显著优于其他选择(p = 7.11e-8)
虽然视觉-语言对比目标是解释CLIP和SigLIP优势的一个原因,另一种可能的解释是训练图像分布。CLIP和SigLIP都包含来源于互联网的图像(例如,草图、图表、动画图形等),这些图像不在ImageNet或DINOv2的预训练数据中
其次,对于跨视觉骨干网的图像处理问题上,大多数图像的分辨率和纵横比差异很大,但大多数视觉骨干网期望固定大小的方形图像;为了解决这个问题,普遍的默认做法是将图像“调整大小并裁剪”到合适的大小。虽然这对于分类等应用通常效果良好,但对于需要全场景推理的任务来说,裁剪掉图像的一部分尤其有害
在本次实验中,作者评估了三种不同的图像处理方案
- 默认的”resize & crop” 方案
- LLaVa v1.5 使用的”letterbox padding” 方案(将非正方形图像填充为正方形)
- 以及”naive resize” 方案(扭曲原始图像的纵横比,将图像压缩或拉伸为正方形)
可以发现(图6;中间)令人惊讶:
虽然裁剪显然不是最佳选择,但对于CLIP 而言,”naive resize” 方案表现最佳。对于SigLIP,”naive resize” 和”letterbox padding” 的表现相似。总体而言,实验结果更偏向于”naive resizing”而非”letterbox padding”,但不能排除这种改进在统计上具有显著性(p = 0.0176)
值得一提的是,关于在填充图像时天真地调整图像大小的两个推测性论点是最小化” 无效像素” 和分布偏移。一个16:9长宽比的图像被填充为正方形时,会引入大量无信息像素(超过40 %);改变长宽比的变形可能导致较小的偏移。结合Vision Transformer 的固有补丁维度(对于16 × 16 像素补丁,d = 1024),天真地调整图像大小可能会保留足够的信息,使下游LM(具有7B+ 参数)能够提取下游任务所需的属性
再其次,对于缩放图像分辨率的问题上,近期VLMs 的另一个趋势是增加输入图像分辨率,希望捕捉到细粒度的细节以提高下游性能(Liu et al., 2023b; Li et al., 2023a)。而作者的研究结果(图6;右)证实了这一假设
缩放到336px 或384px 带来了显著的改进(p = 6.05 e-4)——当然 代价是带来计算复杂度的显著提升「因为VLMs将单个ViT patch投影到LM的嵌入空间中。在假设固定patch粒度的情况下,将输入分辨率翻倍会导致输入补丁数量增加四倍」
最后,对于不同视觉表示的结合问题上,在视觉领域,大量的先前研究表明,不同归纳偏差训练的不同类型的视觉表示可以提高广泛应用的性能(Kobayashi et al., 2022; Karam-cheti et al., 2023)
受此启发,作者疑问这种趋势是否同样适用于VLM 训练——特别是结合DINOv2 特征与来自CLIP 和SigLIP 的视觉-语言对比特征是否能提高性能「遵循Kerr et al. (2023) 中采用的方法」
为了高效实现这一点,作者简单地将不同骨干网络的patch特征沿通道维度连接在一起,从而为每个patch生成相同数量的输入patch嵌入——只是特征维度加倍
为此调整,作者只需将投影器
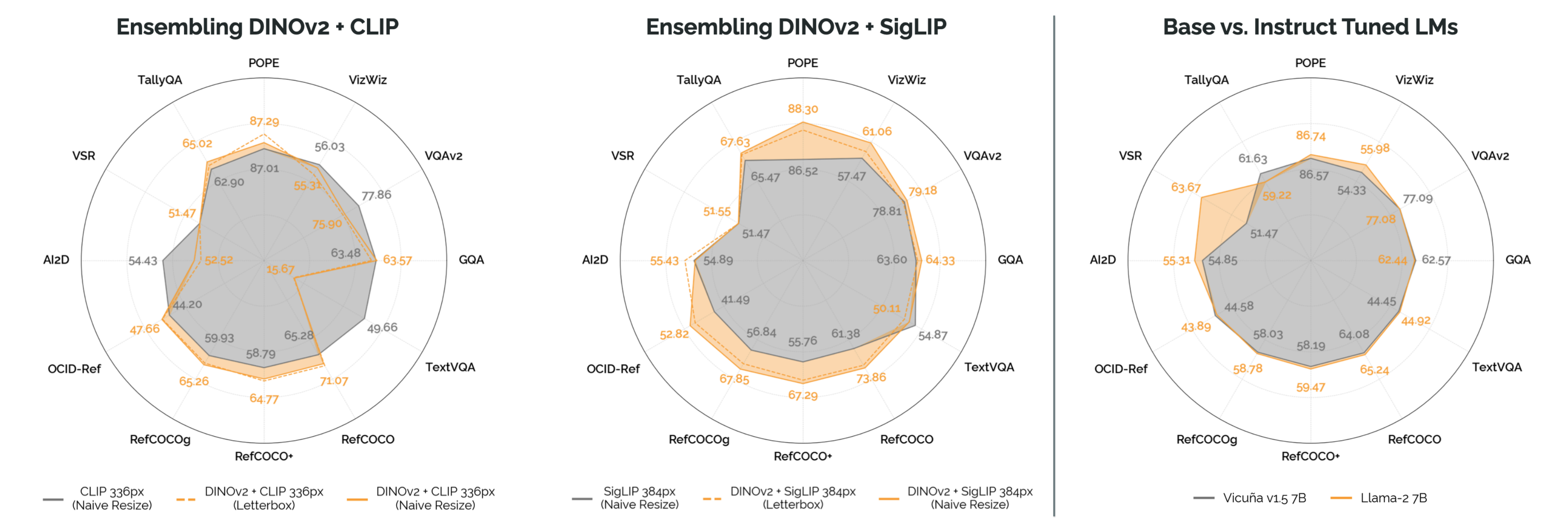
通过查看其余结果,还看到在定位和挑战任务上有5-10 % 的显著提升;总体而言,DINOv2 + SigLIP 融合表示是作者尝试过的性能最佳的视觉表示,几乎没有增加参数
根据Kerr等人(2023)和类似工作的假设,作者相信DINOv2特征提供了捕捉图像低级空间属性的特征,增强了视觉语言对比模型所捕捉的高级“语义”属性
2.2.3 整合语言模型:是整合微调过的,还是不微调过的呢
基础模型与指令微调模型。指令微调(或聊天微调;Ouyang et al., 2022; Chung et al., 2022)是一种将基础语言模型(为下一个词预测训练的)微调为对话代理的方法,为广泛的应用提供自然的输入/输出接口
因此,像Vicuña(Zheng et al., 2023)这样的指令微调模型已经成为视觉语言模型的默认骨干。不幸的是,指令微调有其缺点,会引入偏差并导致性能回退(Ouyang et al., 2022)
因此,在这个实验中,作者通过基础语言模型(Llama-2;Touvron et al., 2023)与指令微调变体(Vicuña v1.5)的正面对比,评估指令微调语言模型骨干对下游视觉语言模型性能的影响
发现(图7 - 右)指令微调语言模型在性能上并没有比基础语言模型带来统计上显著的改善(p = 0.34854),但在定性性能上有所不同
具体而言,观察到指令微调语言模型导致的视觉语言模型更加冗长,易出现幻觉,并且其响应通常不够具体(图11)
更好的语言模型是否会导致更好的视觉语言模型?
- 作者研究了语言模型在仅语言基准上的性能如何转化为下游视觉语言模型的性能,训练了从 Mistral v1 7B 和 Mistral Instruct v1 7B(Jiang 等,2023)得到的视觉语言模型,这些是最近在语言和代码基准上表现优于 Llama-2 的语言模型(Hendrycks 等,2021;Chen 等,2021)
可以发现(图 12)这些视觉语言模型并没有显著更高的性能——比起从Llama-2 训练的VLMs(p = 0.03097),这是一个更为重要的因素,故未来工作的一个令人兴奋的方向是研究语言模型预训练组合如何与VLM 性能相关联 - 仅使用语言的安全数据共同训练
比如用于训练的LLaVa v1.5 预训练数据集由40 K 个来自ShareGPT(ShareGPT, 2023)的语言数据示例组成;这些数据由用户上传的与OpenAI 的ChatGPT 的多样化对话构成;关键是,该数据集中的许多示例包含有毒、不当或其他不安全的输入,以及ChatGPT 对应的” 保护” 响应(例如,” 作为一个AI,我不能评论....”)
在此实验中,作者分析了在下游性能上共同训练这种仅语言数据的影响,目的是了解添加与视觉推理无关的仅语言数据是否会相对于仅在多模态数据上训练而损害性能
最终发现(图8;左)去除仅语言数据仅略微提高了性能(p = 0.13655)
2.2.4 扩展属性:训练时间与数据
作者还探讨了训练时间作为训练轮数的函数的影响。与现有的VLMs 如PaLI 或LLaVa 最多只进行一个轮次训练不同,作者比较了在不同轮数下训练的性能。发现(图10;中间)单轮训练存在严重欠拟合的证据,随着训练到两轮,性能稳步提升(特别是对于需要结构化输出的任务如RefCOCO),之后性能趋于平稳
从而也就发现了进行两轮训练比进行一轮训练有显著的改进(p = 0.00496)
最后总结一下一系列能够简化VLM训练并提高下游性能的独特见解
- 优化过程:单阶段训练在不影响下游性能的情况下减少计算成本
- 图像处理和视觉表示:融合了DINOv2和SigLIP主干网络,通过高分辨率图像和简单的图像调整尺寸实现了强大的性能
- 语言模型:基础语言模型(如Llama-2)的性能与指令调优语言模型相当或更好,联合训练语言数据对于安全性非常重要
- 扩展属性:增加多样化的数据和延长训练时间显著提升性能
第三部分 OpenVLA的源码剖析
整个代码仓库主要包含
- prismatic — 包源;为模型加载、训练、数据预处理等方面提供核心工具
- vla-scripts/— 训练、微调及部署视觉语言动作(VLA)的核心脚本
- LICENSE— 所有代码均依据MIT许可证发布;尽情编程
- Makefile— 主要的Makefile(默认情况下支持lint检查与自动修复);根据需求扩展
- pyproject.toml— 完整的项目配置详情(包含依赖项),以及工具配置
3.1 prismatic/models
3.1.1 models/vlms/prismatic.py
// 待更
3.1.2 models/vlas/openvla.py
// 待更
3.3 prismatic/vla:动作预测
3.3.1 prismatic/vla/action_tokenizer.py
ActionTokenizer类的主要功能是将连续的机器人动作离散化为多个维度上的 N 个区间,并将其映射到最少使用的token上
- 构造函数 __init__
接受一个基础的 LLM/VLM token器、区间数量、最小动作值和最大动作值作为参数
默认情况下,假设使用的是类似于 LlamaTokenizer 的 BPE 风格token器,其中最少使用的token出现在词汇表的末尾。构造函数中还创建了均匀分布的区间,并计算了区间中心
具体而言,__init__方法是 接受四个参数:tokenizer、bins、min_action 和max_action。其中,tokenizer 是一个基础的 LLM/VLM token器,bins是每个连续值的区间数量,min_action 和 max_action 分别是最小和最大动作值
该方法的主要功能是将连续的机器人动作离散化为多个维度上的 N 个区间,并将其映射到最少使用的token上。默认情况下,假设使用的是类似于 LlamaTokenizer 的 BPE 风格token器,其中最少使用的token出现在词汇表的末尾class ActionTokenizer: def __init__( self, tokenizer: PreTrainedTokenizerBase, bins: int = 256, min_action: int = -1, max_action: int = 1 ) -> None:
在构造函数中,首先将传入的参数赋值给实例变量
然后,使用 np.linspace方法创建均匀分布的区间,并计算区间中心self.tokenizer, self.n_bins, self.min_action, self.max_action = tokenizer, bins, min_action, max_action
最后,设置 action_token_begin_idx,它基于 self.tokenizer.vocab_size - (self.n_bins + 1) 计算,假设总是覆盖词汇表的最后 n_bins 个token# Create Uniform Bins + Compute Bin Centers self.bins = np.linspace(min_action, max_action, self.n_bins) self.bin_centers = (self.bins[:-1] + self.bins[1:]) / 2.0# [Contract] Set "action_token_begin_idx" based on `self.tokenizer.vocab_size - (self.n_bins + 1)` # =>> Assumes we're always overwriting the final `n_bins` tokens of the vocabulary! self.action_token_begin_idx: int = int(self.tokenizer.vocab_size - (self.n_bins + 1)) - __call__方法
用于将动作裁剪并离散化为词汇表中最后的 n_bins个token
该方法首先将动作值裁剪到指定的最小和最大动作值之间
然后使用 np.digitize方法将动作值离散化def __call__(self, action: np.ndarray) -> Union[str, List[str]]: """Clip & bin actions to *the last `n_bins` tokens* of the vocabulary (e.g., tokenizer.vocab[-256:]).""" action = np.clip(action, a_min=float(self.min_action), a_max=float(self.max_action))
如果输入是单个元素,则返回解码后的token字符串;如果是批量输入,则返回解码后的token字符串列表discretized_action = np.digitize(action, self.bins)# Handle single element vs. batch if len(discretized_action.shape) == 1: return self.tokenizer.decode(list(self.tokenizer.vocab_size - discretized_action)) else: return self.tokenizer.batch_decode((self.tokenizer.vocab_size - discretized_action).tolist()) - decode_token_ids_to_actions
方法的主要功能是将离散的动作token ID 转换回连续的动作值。该方法接受一个 action_token_ids的 `numpy` 数组作为输入,并返回一个 `numpy` 数组,包含对应的连续动作值
首先,方法通过从 self.tokenizer.vocab_size中减去action_token_ids来计算离散化的动作值。这一步的目的是将token ID 映射到一个新的索引范围内
接下来,使用 np.clip函数将这些离散化的动作值限制在有效的区间范围内,即 `[0, self.bin_centers.shape[0] - 1]`——具体而言,将小于最小值的元素设置为最小值,将大于最大值的元素设置为最大值,从而确保所有的索引都在有效范围内def decode_token_ids_to_actions(self, action_token_ids: np.ndarray) -> np.ndarray: discretized_actions = self.tokenizer.vocab_size - action_token_ids
最后,方法返回self.bin_centers中对应索引的值discretized_actions = np.clip(discretized_actions - 1, a_min=0, a_max=self.bin_centers.shape[0] - 1)
self.bin_centers是在初始化时计算的区间中心值数组,因此返回的数组包含了对应于输入token ID 的连续动作值。这种方法有效地将离散的记 ID 转换回了连续的动作值,便于进一步的处理和使用return self.bin_centers[discretized_actions]
// 待更