官方文档:MMDetection–》点击进入
**
第一步 安装相关环境
**
1、MMDetection提供了GPU与CPU两个版本,但是cpu版本可用的算法会少很多。
2、参考我的前一篇博文安装好cuda等等环境
3、MMDetection所支持的最低依赖
Linux 和 macOS (Windows 理论上支持)
Python 3.6+
PyTorch 1.3+
CUDA 9.2+ (如果基于 PyTorch 源码安装,也能够支持 CUDA 9.0)
GCC 5+
MMCV
4、开始安装MMDetection
- 使用 conda 新建虚拟环境,并进入该虚拟环境;
conda create -n open-mmlab python=3.7 -y
conda activate open-mmlab
2.基于 PyTorch 官网安装 PyTorch 和 torchvision,例如:
conda install pytorch torchvision -c pytorch
3.我们建议使用 MIM 来安装 MMDetection:
pip install openmim
mim install mmdet
MIM 能够自动地安装 OpenMMLab 的项目以及对应的依赖包。
或者,可以手动安装 MMDetection:
安装 mmcv-full,我们建议使用预构建包来安装:
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/{cu_version}/{torch_version}/index.html
需要把命令行中的 {cu_version} 和 {torch_version} 替换成对应的版本。例如:在 CUDA 11 和 PyTorch 1.7.0 的环境下,可以使用下面命令安装最新版本的 MMCV:
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu110/torch1.7.0/index.html
请参考 MMCV 获取不同版本的 MMCV 所兼容的的不同的 PyTorch 和 CUDA 版本。同时,也可以通过以下命令行从源码编译 MMCV:
git clone https://github.com/open-mmlab/mmcv.git
cd mmcv
MMCV_WITH_OPS=1 pip install -e . # 安装好 mmcv-full
cd ..
或者,可以直接使用命令行安装:
pip install mmcv-full
4.安装 MMDetection:
你可以直接通过如下命令从 pip 安装使用 mmdetection:
pip install mmdet
或者从 git 仓库编译源码
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
pip install -r requirements/build.txt
pip install -v -e . # or "python setup.py develop"
5.安装额外的依赖以使用 Instaboost, 全景分割, 或者 LVIS 数据集
# 安装 instaboost 依赖
pip install instaboostfast
# 安装全景分割依赖
pip install git+https://github.com/cocodataset/panopticapi.git
# 安装 LVIS 数据集依赖
pip install git+https://github.com/lvis-dataset/lvis-api.git
# 安装 albumentations 依赖
pip install albumentations>=0.3.2 --no-binary imgaug,albumentations
验证
为了验证是否正确安装了 MMDetection 和所需的环境,我们可以运行示例的 Python 代码来初始化检测器并推理一个演示图像:
from mmdet.apis import init_detector, inference_detector
config_file = 'configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
# 从 model zoo 下载 checkpoint 并放在 `checkpoints/` 文件下
# 网址为: http://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
checkpoint_file = 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
device = 'cuda:0'
# 初始化检测器
model = init_detector(config_file, checkpoint_file, device=device)
# 推理演示图像
inference_detector(model, 'demo/demo.jpg')
如果成功安装 MMDetection,则上面的代码可以完整地运行。
具体的内容可以点击传送门MODEL_ZOO库
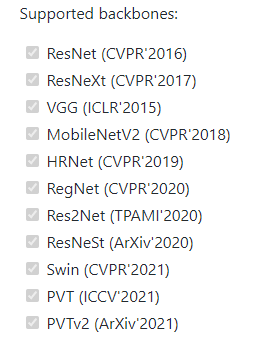
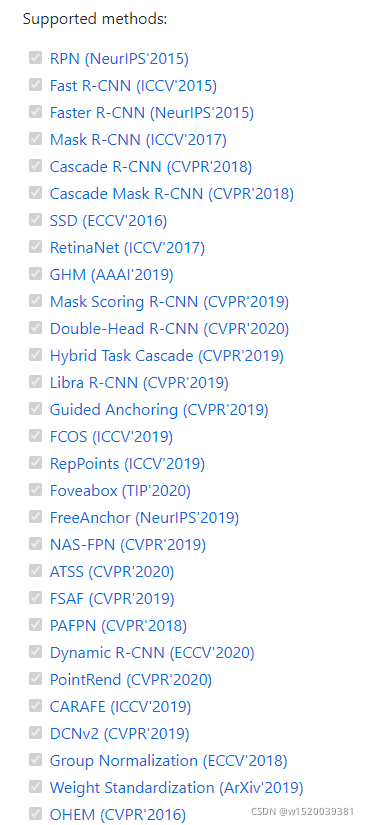

第二步 正式进入学习
1、在已有的数据集上进行推理
MMDetection 在 Model Zoo 中提供了数以百计的检测模型,并支持多种标准数据集,包括 Pascal VOC,COCO,Cityscapes,LVIS 等。这份文档将会讲述如何使用这些模型和标准数据集来运行一些常见的任务,包括:
- 使用现有模型在给定图片上进行推理
- 在标准数据集上测试现有模型
- 在标准数据集上训练预定义的模
2、使用现有模型进行推理
推理是指使用训练好的模型来检测图像上的目标。在 MMDetection 中,一个模型被定义为一个配置文件和对应的存储在 checkpoint 文件内的模型参数的集合。
首先,我们建议从 Faster RCNN 开始,其 配置 文件和 checkpoint 文件在此。 我们建议将 checkpoint 文件下载到 checkpoints 文件夹内。
3、推理的高层编程接口
MMDetection 为在图片上推理提供了 Python 的高层编程接口。下面是建立模型和在图像或视频上进行推理的例子。
from mmdet.apis import init_detector, inference_detector
import mmcv
# 指定模型的配置文件和 checkpoint 文件路径
config_file = 'configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
checkpoint_file = 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
# 根据配置文件和 checkpoint 文件构建模型
model = init_detector(config_file, checkpoint_file, device='cuda:0')
# 测试单张图片并展示结果
img = 'test.jpg' # 或者 img = mmcv.imread(img),这样图片仅会被读一次
result = inference_detector(model, img)
# 在一个新的窗口中将结果可视化
model.show_result(img, result)
# 或者将可视化结果保存为图片
model.show_result(img, result, out_file='result.jpg')
# 测试视频并展示结果
video = mmcv.VideoReader('video.mp4')
for frame in video:
result = inference_detector(model, frame)
model.show_result(frame, result, wait_time=1)
异步接口-支持 Python 3.7+
对于 Python 3.7+,MMDetection 也有异步接口。利用 CUDA 流,绑定 GPU 的推理代码不会阻塞 CPU,从而使得 CPU/GPU 在单线程应用中能达到更高的利用率。在推理流程中,不同数据样本的推理和不同模型的推理都能并发地运行。
您可以参考 tests/async_benchmark.py 来对比同步接口和异步接口的运行速度。
import asyncio
import torch
from mmdet.apis import init_detector, async_inference_detector
from mmdet.utils.contextmanagers import concurrent
async def main():
config_file = 'configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
checkpoint_file = 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
device = 'cuda:0'
model = init_detector(config_file, checkpoint=checkpoint_file, device=device)
# 此队列用于并行推理多张图像
streamqueue = asyncio.Queue()
# 队列大小定义了并行的数量
streamqueue_size = 3
for _ in range(streamqueue_size):
streamqueue.put_nowait(torch.cuda.Stream(device=device))
# 测试单张图片并展示结果
img = 'test.jpg' # or 或者 img = mmcv.imread(img),这样图片仅会被读一次
async with concurrent(streamqueue):
result = await async_inference_detector(model, img)
# 在一个新的窗口中将结果可视化
model.show_result(img, result)
# 或者将可视化结果保存为图片
model.show_result(img, result, out_file='result.jpg')
asyncio.run(main())
演示样例
我们还提供了三个演示脚本,它们是使用高层编程接口实现的。
图片样例
这是在单张图片上进行推理的脚本,可以开启 --async-test 来进行异步推理。
python demo/image_demo.py \
${IMAGE_FILE} \
${CONFIG_FILE} \
${CHECKPOINT_FILE} \
[--device ${GPU_ID}] \
[--score-thr ${SCORE_THR}] \
[--async-test]
运行样例:
python demo/image_demo.py demo/demo.jpg \
configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
--device cpu
摄像头样例
这是使用摄像头实时图片的推理脚本。
python demo/webcam_demo.py \
${CONFIG_FILE} \
${CHECKPOINT_FILE} \
[--device ${GPU_ID}] \
[--camera-id ${CAMERA-ID}] \
[--score-thr ${SCORE_THR}]
运行样例:
python demo/webcam_demo.py \
configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
视频样例
这是在视频样例上进行推理的脚本。
python demo/video_demo.py \
${VIDEO_FILE} \
${CONFIG_FILE} \
${CHECKPOINT_FILE} \
[--device ${GPU_ID}] \
[--score-thr ${SCORE_THR}] \
[--out ${OUT_FILE}] \
[--show] \
[--wait-time ${WAIT_TIME}]
运行样例:
python demo/video_demo.py demo/demo.mp4 \
configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
--out result.mp4
在标准数据集上测试现有模型
为了测试一个模型的精度,我们通常会在标准数据集上对其进行测试。MMDetection 支持多个公共数据集,包括 COCO , Pascal VOC ,Cityscapes 等等。 这一部分将会介绍如何在支持的数据集上测试现有模型。
数据集准备
一些公共数据集,比如 Pascal VOC 及其镜像数据集,或者 COCO 等数据集都可以从官方网站或者镜像网站获取。 注意:在检测任务中,Pascal VOC 2012 是 Pascal VOC 2007 的无交集扩展,我们通常将两者一起使用。 我们建议将数据集下载,然后解压到项目外部的某个文件夹内,然后通过符号链接的方式,将数据集根目录链接到 $MMDETECTION/data 文件夹下,格式如下所示。 如果你的文件夹结构和下方不同的话,你需要在配置文件中改变对应的路径。
mmdetection
├── mmdet
├── tools
├── configs
├── data
│ ├── coco
│ │ ├── annotations
│ │ ├── train2017
│ │ ├── val2017
│ │ ├── test2017
│ ├── cityscapes
│ │ ├── annotations
│ │ ├── leftImg8bit
│ │ │ ├── train
│ │ │ ├── val
│ │ ├── gtFine
│ │ │ ├── train
│ │ │ ├── val
│ ├── VOCdevkit
│ │ ├── VOC2007
│ │ ├── VOC2012
有些模型需要额外的 COCO-stuff 数据集,比如 HTC,DetectoRS 和 SCNet,你可以下载并解压它们到 coco 文件夹下。文件夹会是如下结构:
mmdetection
├── data
│ ├── coco
│ │ ├── annotations
│ │ ├── train2017
│ │ ├── val2017
│ │ ├── test2017
│ │ ├── stuffthingmaps
PanopticFPN 等全景分割模型需要额外的 COCO Panoptic 数据集,你可以下载并解压它们到 coco/annotations 文件夹下。文件夹会是如下结构:
mmdetection
├── data
│ ├── coco
│ │ ├── annotations
│ │ │ ├── panoptic_train2017.json
│ │ │ ├── panoptic_train2017
│ │ │ ├── panoptic_val2017.json
│ │ │ ├── panoptic_val2017
│ │ ├── train2017
│ │ ├── val2017
│ │ ├── test2017
Cityscape 数据集的标注格式需要转换,以与 COCO 数据集标注格式保持一致,使用 tools/dataset_converters/cityscapes.py 来完成转换:
pip install cityscapesscripts
python tools/dataset_converters/cityscapes.py \
./data/cityscapes \
--nproc 8 \
--out-dir ./data/cityscapes/annotations
测试现有模型
我们提供了测试脚本,能够测试一个现有模型在所有数据集(COCO,Pascal VOC,Cityscapes 等)上的性能。我们支持在如下环境下测试:
-
单 GPU 测试
-
单节点多 GPU 测试
-
多节点测试
根据以上测试环境,选择合适的脚本来执行测试过程。
# 单 GPU 测试
python tools/test.py \
${CONFIG_FILE} \
${CHECKPOINT_FILE} \
[--out ${RESULT_FILE}] \
[--eval ${EVAL_METRICS}] \
[--show]
# 单节点多 GPU 测试
bash tools/dist_test.sh \
${CONFIG_FILE} \
${CHECKPOINT_FILE} \
${GPU_NUM} \
[--out ${RESULT_FILE}] \
[--eval ${EVAL_METRICS}]
可选参数:
RESULT_FILE: 结果文件名称,需以 .pkl 形式存储。如果没有声明,则不将结果存储到文件。
EVAL_METRICS: 需要测试的度量指标。可选值是取决于数据集的,比如 proposal_fast,proposal,bbox,segm 是 COCO 数据集的可选值,mAP,recall 是 Pascal VOC 数据集的可选值。Cityscapes 数据集可以测试 cityscapes 和所有 COCO 数据集支持的度量指标。
show: 如果开启,检测结果将被绘制在图像上,以一个新窗口的形式展示。它只适用于单 GPU 的测试,是用于调试和可视化的。请确保使用此功能时,你的 GUI 可以在环境中打开。否则,你可能会遇到这么一个错误 cannot connect to X server。
--show-dir: 如果指明,检测结果将会被绘制在图像上并保存到指定目录。它只适用于单 GPU 的测试,是用于调试和可视化的。即使你的环境中没有 GUI,这个选项也可使用。
--show-score-thr: 如果指明,得分低于此阈值的检测结果将会被移除。
--cfg-options: 如果指明,这里的键值对将会被合并到配置文件中。
--eval-options: 如果指明,这里的键值对将会作为字典参数被传入 dataset.evaluation() 函数中,仅在测试阶段使用。