点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(正在更新)
背景介绍
这里是三台公网云服务器,每台 2C4G,搭建一个Hadoop的学习环境,供我学习。
之前已经在 VM 虚拟机上搭建过一次,但是没留下笔记,这次趁着前几天薅羊毛的3台机器,赶紧尝试在公网上搭建体验一下。
注意,如果你和我一样,打算用公网部署,那一定要做好防火墙策略,避免不必要的麻烦!!!
注意,如果你和我一样,打算用公网部署,那一定要做好防火墙策略,避免不必要的麻烦!!!
注意,如果你和我一样,打算用公网部署,那一定要做好防火墙策略,避免不必要的麻烦!!!
请大家都以学习为目的,也请不要对我的服务进行嗅探或者攻击!!!
请大家都以学习为目的,也请不要对我的服务进行嗅探或者攻击!!!
请大家都以学习为目的,也请不要对我的服务进行嗅探或者攻击!!!
但是有一台公网服务器我还运行着别的服务,比如前几天发的:autodl-keeper 自己写的小工具,防止AutoDL机器过期的。还跑着别的Web服务,所以只能挤出一台 2C2G 的机器。那我的配置如下了:
- 2C4G 编号 h121
- 2C4G 编号 h122
- 2C2G 编号 h123 (后续如果服务器多出来,我还有好几台别的,到时候换一下)
Hadoop
Hadoop 是一个开源的分布式计算框架,由 Apache 软件基金会维护,主要用于处理大规模数据集。Hadoop 的核心组件包括:
HDFS(Hadoop Distributed File System)
Hadoop 分布式文件系统,是 Hadoop 中的存储系统,能够以分布式的方式存储大规模数据集。HDFS 将数据分成块,并将这些块分散存储在集群中的不同节点上,从而提供高容错性和可靠性。
MapReduce
这是 Hadoop 的数据处理模型,适合处理大规模的、需要并行计算的任务。MapReduce 将任务分为两个阶段:
- Map 阶段:将输入数据拆分为一系列键值对。
- Reduce 阶段:根据键对数据进行聚合或处理。
通过分布式计算,MapReduce 能够处理数百甚至上千台服务器上的数据,并有效利用硬件资源。
YARN(Yet Another Resource Negotiator)
YARN 是 Hadoop 集群中的资源管理器。YARN 负责调度和分配集群中的计算资源,使得 Hadoop 体系结构更灵活,可以支持 MapReduce 之外的其他处理框架。
Hadoop Common
这一组件为 Hadoop 各个模块提供了通用的工具和库,如文件系统抽象、序列化机制和 RPC(远程过程调用)框架。
优点
- 可扩展性:Hadoop 可以通过增加节点来扩展计算和存储能力,适用于从单台服务器到上千节点的大规模集群。
- 容错性:HDFS 会将数据复制到不同的节点中,即使部分节点出现故障,数据仍然可以恢复。
- 成本效益:Hadoop 是开源的,能够运行在廉价的商用硬件上,适合处理 PB 级别的数据。
- 灵活性:Hadoop 能够处理各种格式的数据,包括结构化、半结构化和非结构化数据。
应用场景
Hadoop 常用于大数据分析、数据仓库、日志处理、推荐系统、机器学习和金融风险分析等场景。例如:
- 数据存储和处理:企业可以使用 Hadoop 来存储并处理大量的历史数据,并在这些数据上运行分析程序。
- 机器学习:Hadoop 可以作为机器学习模型训练的基础架构,帮助处理大量的数据集。
- 日志处理:Hadoop 常用于分析和处理来自不同服务器和应用程序的日志数据,以便监控性能或进行故障排除。
Hadoop 已经成为大数据生态系统的基础,围绕它形成了丰富的技术栈,例如 Apache Hive、Apache HBase、Apache Pig 和 Apache Spark 等,进一步拓展了其能力。
Java 环境
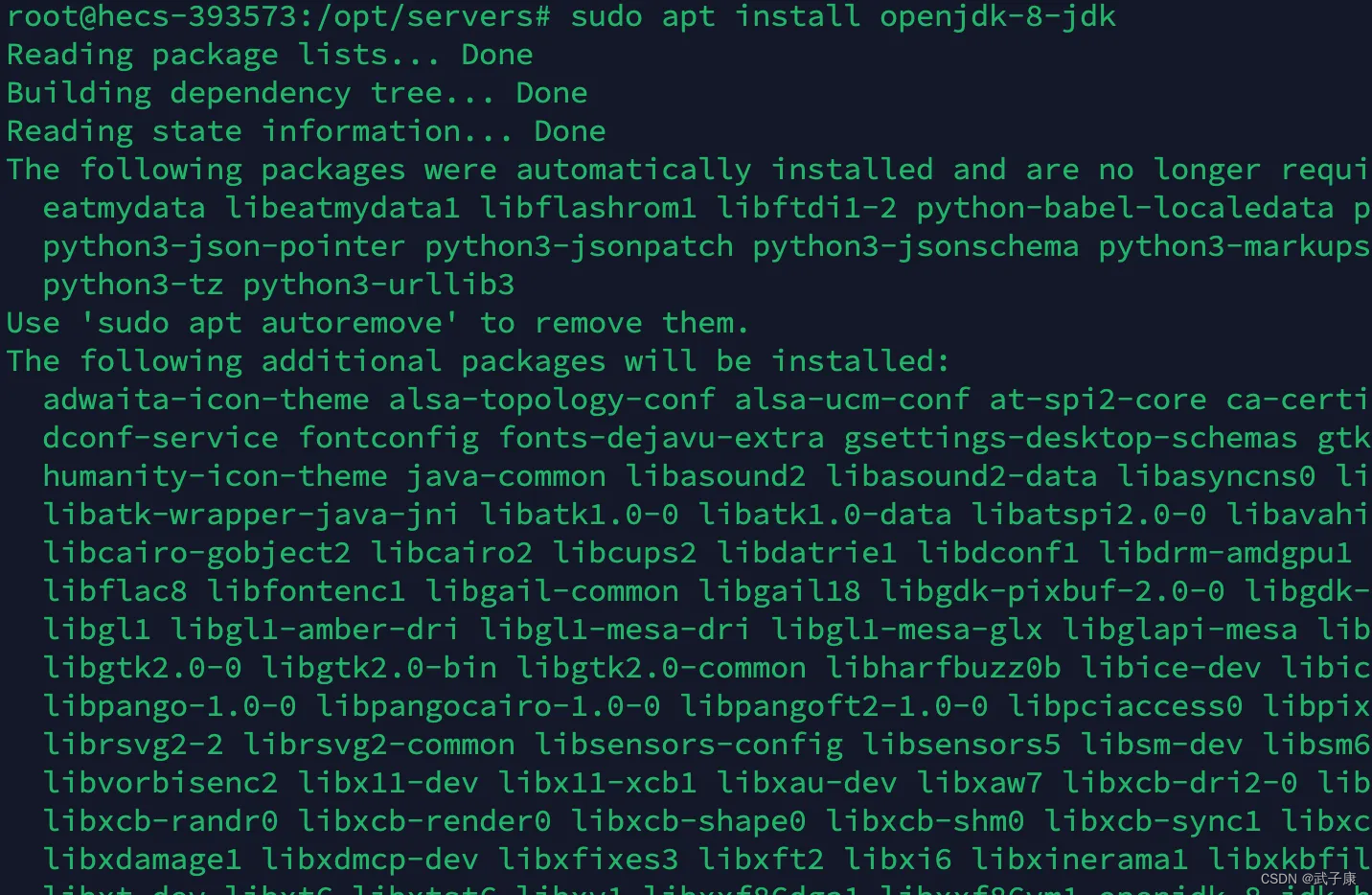
apt 安装
sudo apt install openjdk-8-jdk
下载安装
这种就是大家常用的方式安装,我选择的是 apt 的方式
# JDK8:https://www.oracle.com/cn/java/technologies/downloads/#java8-linux
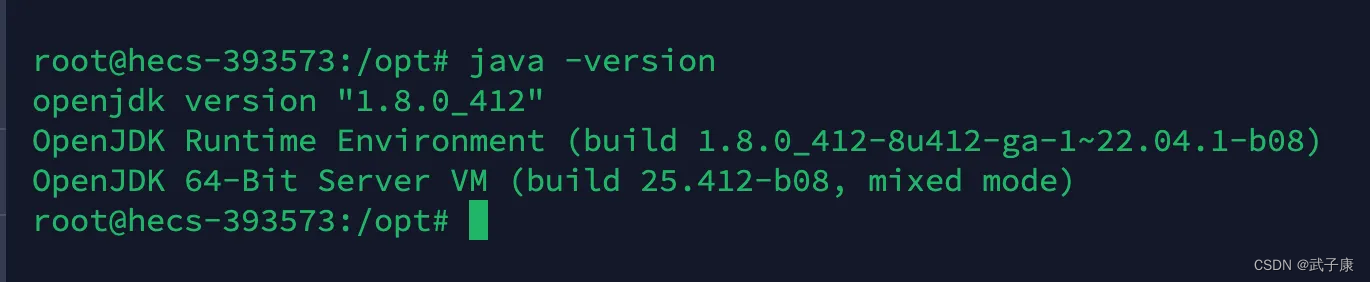
验证环境
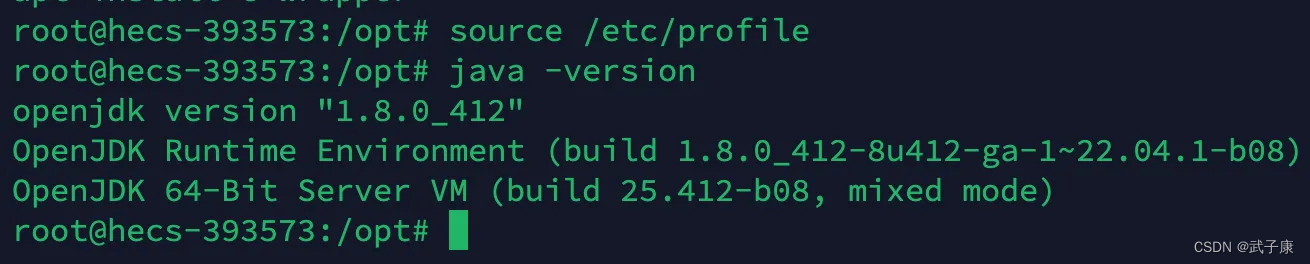
java -version
环境变量
虽然 apt 安装完之后,是有了环境变量,但是为了后续 Hadoop 能够正常的工作,我们还需要手动去配置一下。
找到你目前的Java目录
readlink -f $(which java)

修改配置文件
sudo vim /etc/profile
**写入如下内容: **
# java
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
退出保存,并刷新环境变量
source /etc/profile
此时,重新测试环境,如果没有问题,恭喜你一切顺利!
Hadoop环境
创建目录
现在根目录下创建
sudo mkdir /opt/software
sudo mkdir /opt/servers
创建完毕后,进入 软件的目录。
cd /opt/software
下载文件
我们直接使用 wget 工具来帮助我们下载:
sudo wget -O hadoop-2.9.2.tar.gz https://archive.apache.org/dist/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
解压文件
将文件解压到 servers 目录下
sudo tar -zxvf hadoop-2.9.2.tar.gz -C /opt/servers
我们查看当前的目录:

环境变量
打开环境配置
sudo vim /etc/profile
在最底部加入如下的内容:
# HADOOP_HOME
export HADOOP_HOME=/opt/servers/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
刷新环境变量
source /etc/profile
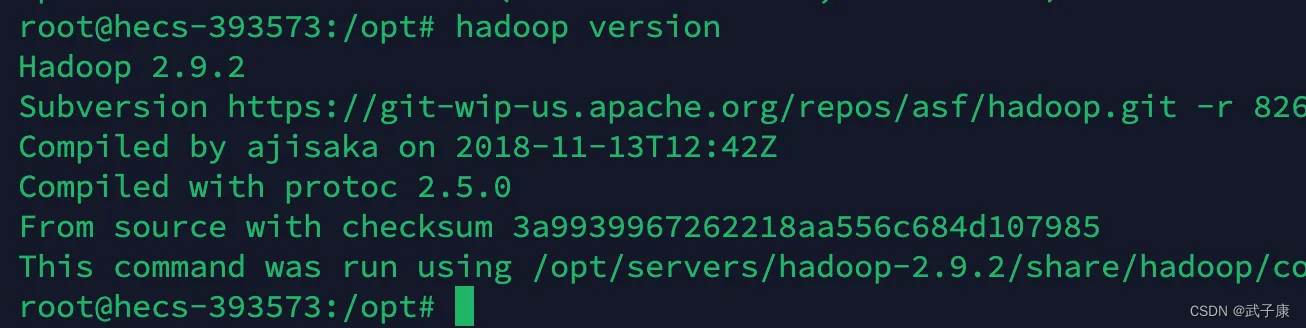
验证环境
hadoop version
如果出现如图的内容,那么恭喜你!已经完成了初步的Java和Hadoop的环境配置!