
核心:用 transfrom 架构整合特征提取和特征融合
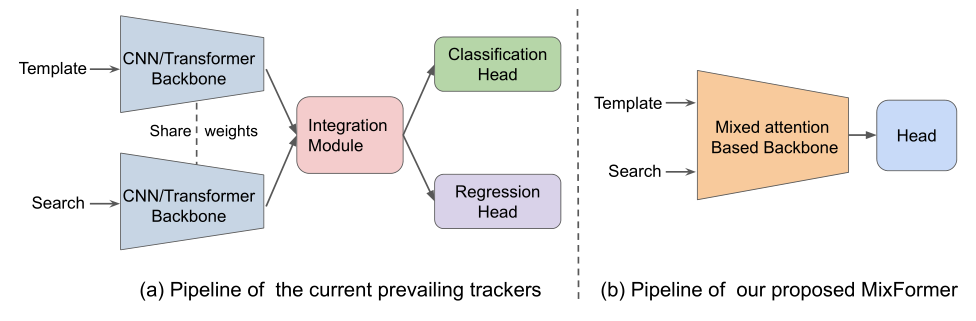
主流的跟踪框架分三步:特征提取、特征融合、预测头分类回归
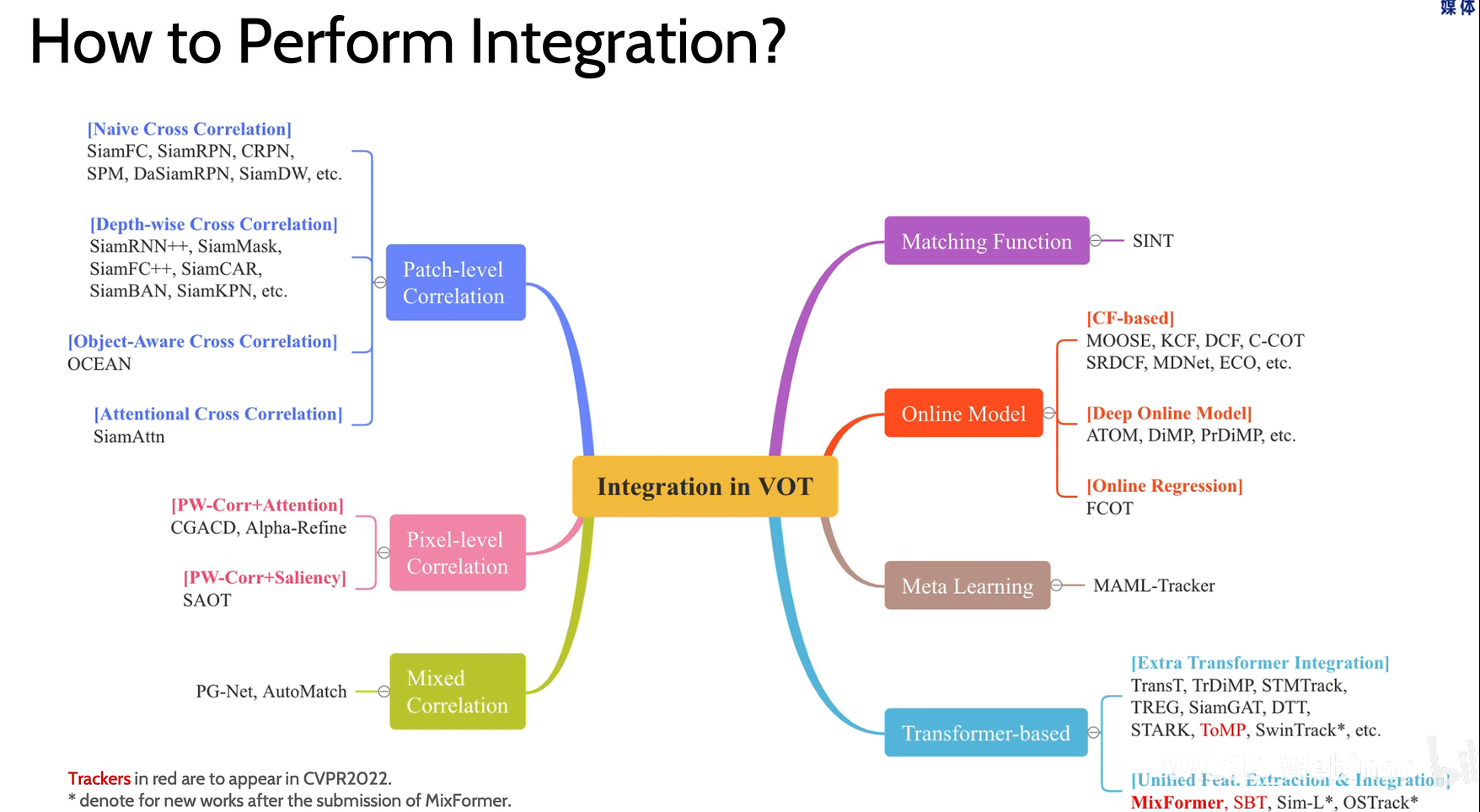
其中特征融合是关键,下图展示了不同的融合方法。(摘自 【VALSE 论文速览 - 68 期】MixFormer: 更加简洁的端到端单目标跟踪器)
最近的研究使用 transformer 进行融合,但仍然依赖 CNN 提取特征,这其中存在一些局限:
- attention 只作用在高层抽象的特征表示空间,忽略了浅层特征;
- CNN 对通用对象识别进行预训练,可能会忽略用于跟踪的更精细的结构信息;
- CNN 的表征能力是局部的,缺乏长距离建模的能力
解决方案:
提出一个通用的 transformer 结构同时进行特征提取和特征融合。
具有如下好处:
- 使特征提取更具体到相应的跟踪目标,并捕获更多目标特定的判别特征;
- 让目标信息更 extensive 的融合进搜索区域;
- 结构更加紧凑简洁。
主要创新点:
- 提出了 MAM 模块,应用 attnetion 机制同时进行特征提取与信息交互
- 提出 SPM 模块进行模板更新
Method
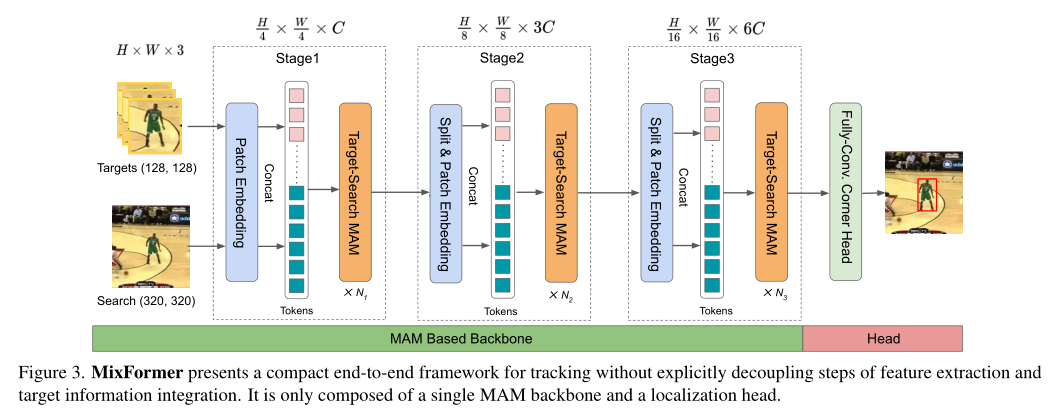
网络整体框架如图 3 所示,包括两部分:模板和搜索图像经过基于 mixed attention module (MAM) 的 backbone 进行特征提取和融合,再通过预测头输出结果。backbone 部分包含 3 个 stage,每个 stage 输入特征首先经过 patch embedding 变成一系列 token,然后送入 MAM 模块提取并融合特征。预测头部分直接将融合后的搜索区域的 token 输入进行预测。
Mixed Attention Module (MAM)
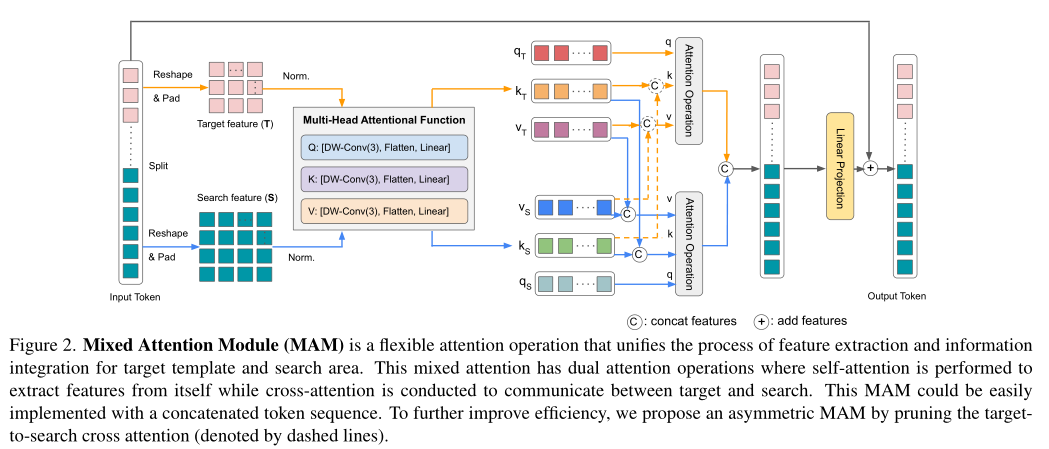
本文的核心模块 MAM,目的是同时提取并融合模板和搜索图像的特征,因此设计了 dual attention 分别用于二者。具体来说,MAM 输入模板和搜索特征拼接成的 token 序列,首先会将输入分开并 reshape 成二维的模板和搜索特征,经过 3×3 DW 卷积编码局部上下文和线性映射生成 q,k,v 后,同时进行 self-attention 和 cross-attention。
注意 MAM 是一个非对称的 attention,删去了 target-to-search 的 cross-attention。如图 2 所示,模板的 q 只会和模板自己的 k,v 计算 attention(黄色虚线);而搜索图的 q 会同时和模板和搜索图的 k,v 计算 attention(蓝色虚线)。用公式表达为:

这样做可以使得模板的 token 在跟踪过程中保持不变,避免被动态的搜索区域影响。为后续引入多个在线模板做铺垫,无需每帧重新计算模板 token。
Localization Head
采用类似 stark 的角点预测模式。作者也额外尝试了类似 detr 的采用一个 query 进行预测的方式。均无需后处理。
Template Online Update
在线更新模板能够很好的利用时序信息处理一些形变和外观变化,然而低质量的更新模板可能使得结果变差。本文设计了一个 score prediction module (SPM),根据预测置信度得分来选择可靠的在线模板,如图 4 所示。
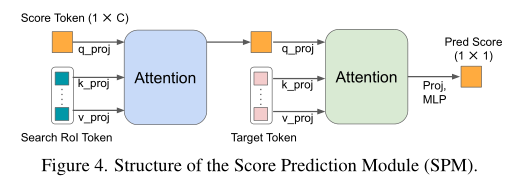
SPM 由两个 attention 和一个三层的 MLP 组成,该模块接在 backbone 最后一个 stage 后,和预测头是并行的。首先输入一个可学习的 score token,与 search ROI token 计算 attention,对搜索图中挖掘的目标信息进行编码。然后将 score token 与第一帧的模板 token 做 attention,隐式地将挖掘的目标与初始目标进行比较。最后过一个 MLP 预测出置信度得分,小于 0.5 判断为不可靠。
Training and Inference
作者设计了两种网络架构 MixFormer 和 MixFormer-L ,分别基于 CVT-21 和 CVT24-W,也就是说可以使用 CVT 在 Imagenet 上预训练的权重来初始化 backbone(虽然原始的 CVT 并没有两个输入,计算 attention 的方式也不一样,但是每个 block 的参数是一样的)。
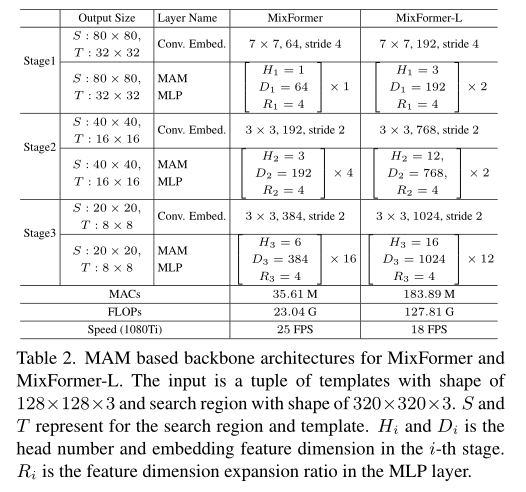
训练过程分为两步,首先用 500 个 epoch 训练 backbone 和 head;最后用 40 个 epoch 单独训练 SPM,冻结其他部分参数。这个训练流程和 stark 类似。
推理阶段每隔 200 帧更新一次模板,选择区间中得分最高的模板替换先前的模板。本文的框架允许输入任意张数的模板,代码实现中只包含两张模板,一张初始模板,一张在线更新模板。
Experiments
SOTA 比较

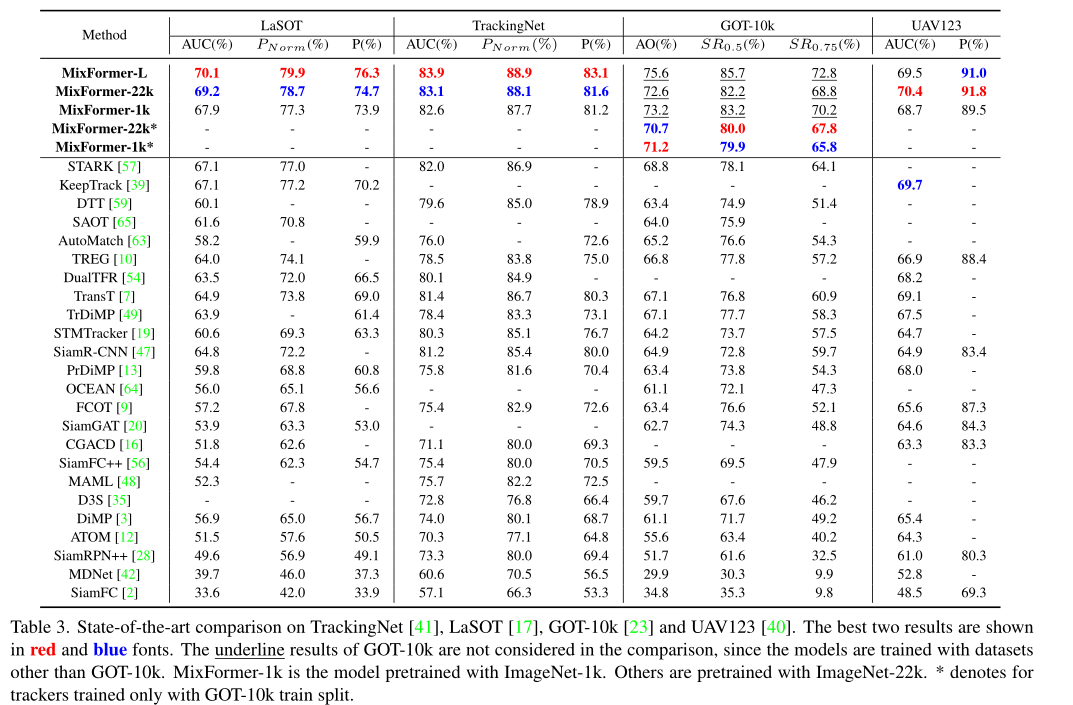
SOTA 性能就一个字:恐怖!
探究实验

- 1 2 3 8 统一特征提取和融合的 MAM 比先提特征 SAM 再融合 CAM 要好,因为耦合的方式可以互相促进。
- 4 5 6 7 8 MAM 的数量越多越好,因为这样可以获得更 extensive 的目标感知特征提取和分层融合。
- 8 9 corner head 比 query head 效果更好
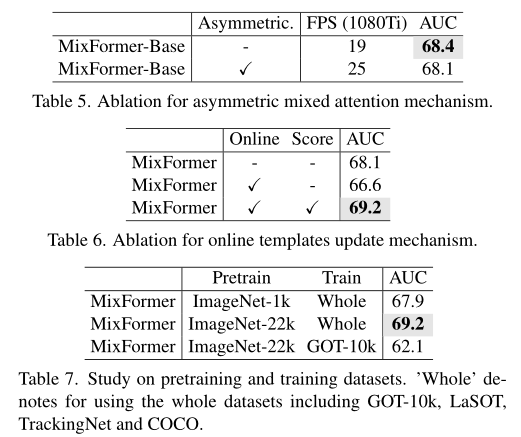
- 使用非对称结构效果略有下降,但是速度提升了
- 从固定间隔中随机采样更新模板效果变差了,加上预测得分后才能提升效果
- pretrain 的规模越大,对效果也是有提升的。

Attention 可视化
- 背景中的干扰物逐层受到抑制
- 在线模板更适应外观变化并有助于区分目标
- 多个模板的前景可以通过交叉注意力来增强
- 某个位置倾向于与周围的局部块相互作用。