安装环境
安装pgvector,先设置docker镜像源:
vim /etc/docker/daemon.json
{
"registry-mirrors": [
"https://05f073ad3c0010ea0f4bc00b7105ec20.mirror.swr.myhuaweicloud.com",
"https://mirror.ccs.tencentyun.com",
"https://0dj0t5fb.mirror.aliyuncs.com",
"https://docker.mirrors.ustc.edu.cn",
"https://6kx4zyno.mirror.aliyuncs.com",
"https://registry.docker-cn.com",
"https://akchsmlh.mirror.aliyuncs.com",
"https://registry.docker-cn.com",
"https://docker.mirrors.ustc.edu.cn",
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com"
]
}编写docker-compose.yml:
services:
pgvector:
image: ankane/pgvector:latest
container_name: pgvector
ports:
- "5432:5432"
restart: always
environment:
- POSTGRES_DB=langchat
- POSTGRES_USER=root
- POSTGRES_PASSWORD=root
volumes:
- ./pgdata:/var/lib/postgresql/data
networks:
- app_network
pgadmin:
image: dpage/pgadmin4:latest
container_name: pgadmin
ports:
- "5050:80"
environment:
PGADMIN_DEFAULT_EMAIL: "[email protected]"
PGADMIN_DEFAULT_PASSWORD: "admin"
volumes:
- pgadmin-data:/var/lib/pgadmin
networks:
- app_network
networks:
app_network:
driver: bridge
volumes:
pgadmin-data:
pgdata:
执行docker compose up -d(老版本的docker是docker-compose up -d)。如下则安装成功:
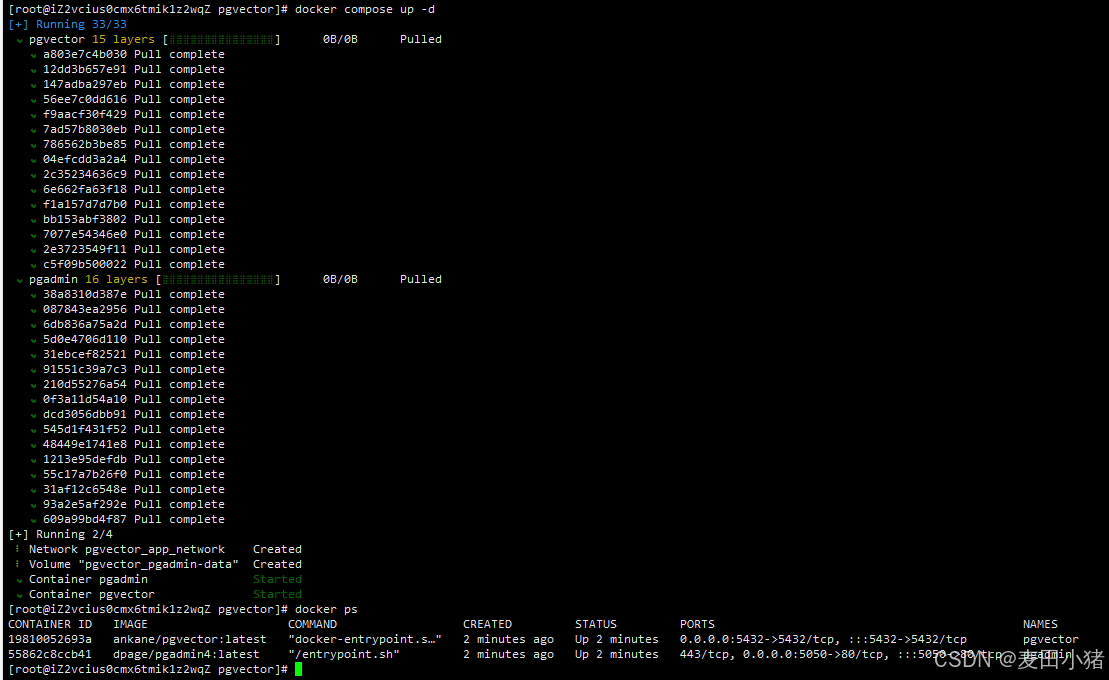
访问http://128.0.0.1:5050/ 登录pgadmin,账号密码在docker-compose中
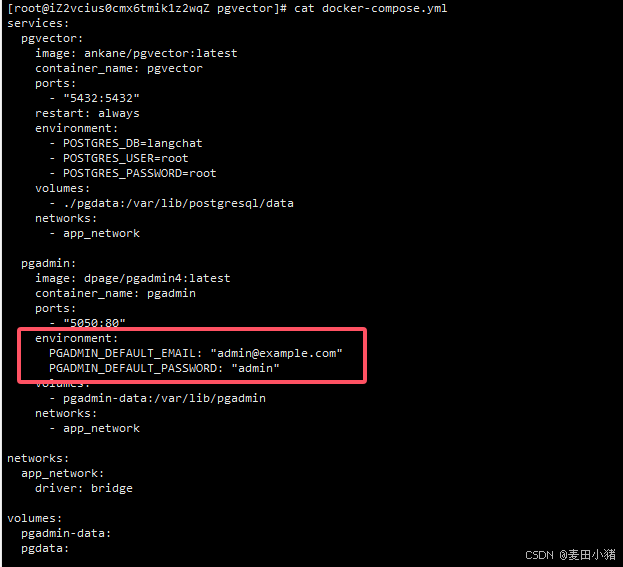
登陆完新增一个server
ollama中安装embedding,在ollama官网中搜索nomic-embed-text ,这里的embedding.length表示向量长度,需要记住

存储向量数据
首先在pom中添加对应依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-core</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pgvector</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.5.8</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embedding-store-filter-parser-sql</artifactId>
<version>${langchain4j.version}</version>
<exclusions>
<exclusion>
<groupId>com.github.jsqlparser</groupId>
<artifactId>jsqlparser</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-tika</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pgvector</artifactId>
<version>${langchain4j.version}</version>
</dependency>编写代码:新增EmbeddingController,首先构建一个EmbbedingStore
private EmbeddingStore buildEmbeddingStore() {
PgVectorEmbeddingStore store = PgVectorEmbeddingStore.builder()
.host("127.0.0.1")
.port(5432)
.database("langchat")
.dimension(768) //需要跟llm embedding模型的向量长度统一
.user("root")
.password("root")
.table("testEmb") //可以自定义新增,无需提前创建
.indexListSize(1)
.useIndex(true)
.createTable(true)
.dropTableFirst(false)
.build();
return store;
}随后构建一个EmbeddingModel,用于将文档解析成向量数据
public EmbeddingModel buildEmbedding() {
return OllamaEmbeddingModel
.builder()
.baseUrl("http://127.0.0.1:11434")
.modelName("nomic-embed-text")
.logRequests(true)
.logResponses(true)
.build();
}随后准备一份简单的文本内容存放于E盘中(自己喜欢):
Redis是一个基于内存的key-value结构数据库。Redis 是互联网技术领域使用最为广泛的存储中间件。
Redis服务默认端口号为 6379 ,通过快捷键Ctrl + C 即可停止Redis服务
重启Redis后,再次连接Redis时,需加上密码,否则连接失败。
Redis存储的是key-value结构的数据,其中key是字符串类型,value有5种常用的数据类型:
在MySQL中,可以使用create database语句来创建数据库。以下是创建一个名为my_database的数据库的示例:新增embed方法,用于解析文档并存储到pgvector中
@GetMapping(value="/embed")
public String embed() {
Document document;
document = FileSystemDocumentLoader.loadDocument("E:\\新建文本文档.txt", new ApacheTikaDocumentParser());
document.metadata().put("fileName", "c.md");
DocumentSplitter splitter = new DocumentByLineSplitter(100,0);
List<TextSegment> segments = splitter.split(document);
EmbeddingModel embeddingModel = buildEmbedding();
EmbeddingStore<TextSegment> embeddingStore = buildEmbeddingStore();
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
List<String> ids = embeddingStore.addAll(embeddings, segments);
// 正则表达式匹配换行符
return JSONUtil.toJsonStr(ids);
}其中FileSystemDocumentLoader表示系统文件读取器,可以读取本地文件并转化为document。同时还有UrlDocumentLoader用于读取网络上的文档内容
DocumentSplitter作为文档切割器,可以将文档切割成小份的TextSegment。DocumentSplitter有多种实现,可根据自己需求选择:
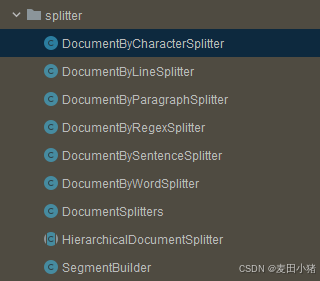
其中常用的有DocumentByLineSplitter,用于根据行切割(需要注意的点是他需要定义maxSegmentSizeInChars,当他设置为1000,文档每行大小为300时,会将每三行合并成一个segment,会根据分隔符最大程度的填充)
DocumentByParagraphSplitter表示根据段落切割
DocumentByRegexSplitter表示根据正则表达式切割
具体可以点到方法中查看
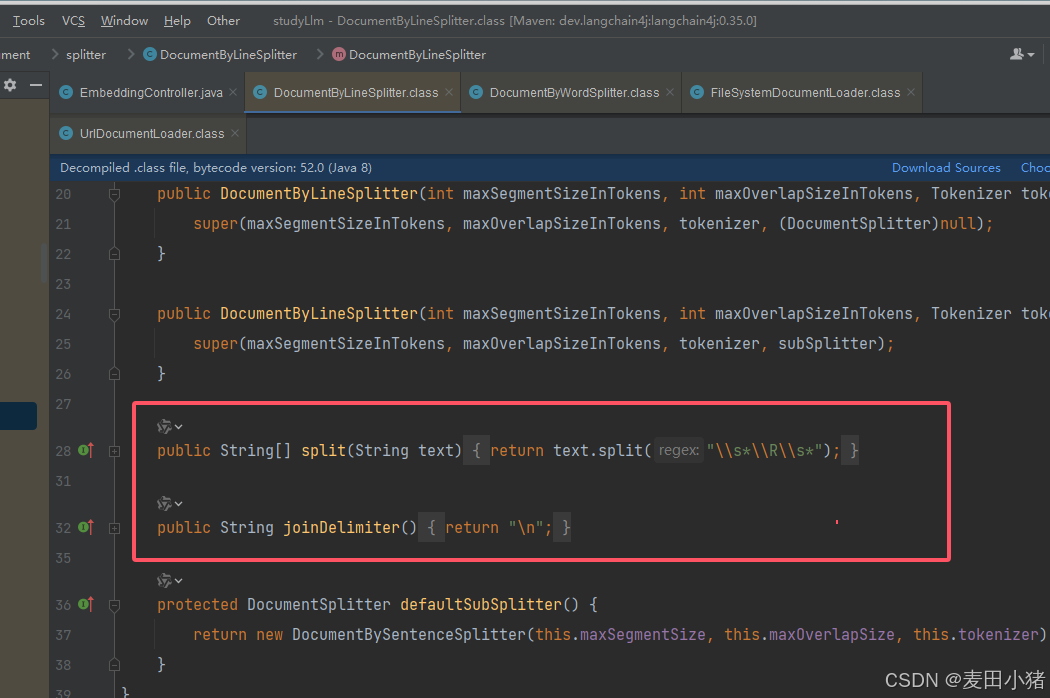
metadata则表示元数据,可以存储如用户名,文档名之类的检索信息,在后续检索中可以作为条件进行查询
至此文档已成功解析并存储到向量数据库中
查询向量数据
@GetMapping(value="/search")
public String search() {
EmbeddingModel embeddingModel = buildEmbedding();
EmbeddingStore<TextSegment> embeddingStore = buildEmbeddingStore();
Embedding queryEmbedding = embeddingModel.embed("MySQL创建语句").content();
Filter filter = metadataKey("fileName").isEqualTo("c.md");
EmbeddingSearchResult<TextSegment> list = embeddingStore.search(EmbeddingSearchRequest
.builder()
.queryEmbedding(queryEmbedding)
.maxResults(5)
.filter(filter)
.build());
List<Map<String, Object>> result = new ArrayList<>();
list.matches().forEach(i -> {
TextSegment embedded = i.embedded();
Map<String, Object> map = embedded.metadata().toMap();
map.put("text", embedded.text());
result.add(map);
});
String promot = """
查询MySQL创建语句,
以下是文本内容,请根据内容提取问题的结果:
""" + JSONUtil.toJsonStr(result);
ChatLanguageModel model = buildModel();
return model.generate(promot);
}
private ChatLanguageModel buildModel(){
return OllamaChatModel.builder()
.baseUrl("http://127.0.0.1:11434")
.modelName("qwen2:7b")
.temperature(0.1)
.build();
}其中Embedding填充的是需要通过向量数据查询的内容
Filter表示需要过滤的元数据内容。它是一个链式结构,可以通过or,and等关联条件进行搜索
search方法中maxResult表示返回最高匹配的文档数(可能查询的内容不存在于向量中,但是根据向量查询算法查询他有一定相似度也会查询出来)
promot表示将pgvector中搜索出来的内容,根据描述将问题跟结果拼接丢给大模型去整合并返回最终的结果(这里的提示词很粗糙,可以根据自己的需求不断完善提示词)
最终输出结果如下:
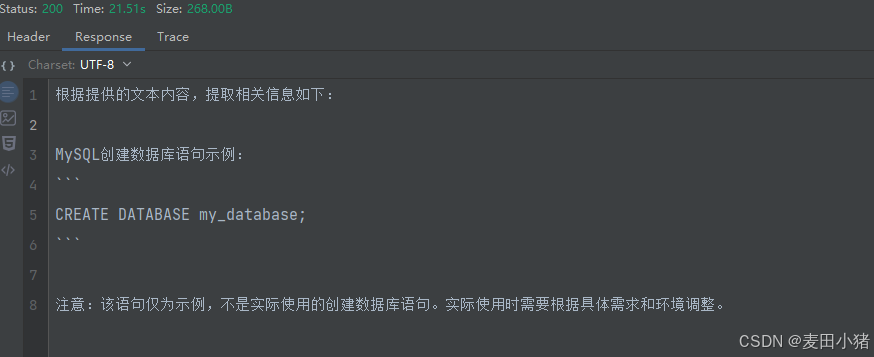
至此,一个简单的rag增强搜索就完成了。其中有很多需要微调的地方,还有很多需要整合的地方需要后续再一步步优化迭代