文章目录
中间件
Nginx
1:简介
Nginx 是一个异步框架的 Web 服务器,也可以用作反向代理,负载平衡器 和 HTTP 缓存
2:安装
安装配置环境
#安装gcc环境
yum install gcc-c++
#安装pcre
yum install -y pcre pcre-devel
#安装zlib
yum install -y zlib zlib-devel
#安装openssl
yum install -y openssl openssl-devel
#安装Nginx 下载源代码包:
wget http://nginx.org/download/nginx-1.21.0.tar.gz
安装nginx
tar -xzvf nginx-1.21.0.tar.gz
cd nginx-1.21.0
./configure
make
make install
修改配置文件 nginx.conf
vi /usr/local/nginx/conf/nginx.conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 9999;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
运行
#/usr/local/nginx/sbin/nginx -s reload
如果报 [error] open() "/usr/local/nginx/logs/nginx.pid" failed (2: No such file or directory) 错误,
则执行执行 命令后再次启动运行 Nginx:
#/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
查看 Nginx 启动状态
#ps -ef | grep nginx
Nginx 相关命令
#cd /usr/local/nginx/sbin/
./nginx -s reload # 重新载入配置文件
./nginx -s reopen # 重启 Nginx
./nginx -s stop # 停止 Nginx
./nginx -s quit # 关闭 Nginx
访问nginx
http://192.168.0.103:9999/
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5q6SP80L-1647763935843)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211012233227105.png)]
3:反向代理
配置
proxy_pass http://xxxxxxxxxx;
server {
listen 9999;
server_name localhost;
location / {
proxy_pass http://www.baidu.com; #请求会转发到www.baidu.com
index index.html index.htm index.jsp;
}
}
location块
location: 配置请求的路由,以及各种页面的处理情况
location 第一行是一个正则,对请求的url过滤,正则匹配,~ 为区分大小写,~* 为不区分大小写
server {
......
......
......
location ~*^.+$ {
#root html; #根目录
#index index.html index.htm; #设置默认页
proxy_pass http://xxxxxxxx; #请求转向xxxxxxxx 定义的服务器列表
deny 127.0.0.1; #拒绝的ip
allow 172.18.5.54; #允许的ip
}
}
4:负载均衡
Nginx 负载平衡主要通过配置:upstream mysvr
配置
热备:如果你有2台服务器,当一台服务器发生事故时,才启用第二台服务器给提供服务,服务器处理请求的顺序:AAAAAA突然A挂啦,BBBBBBBBBBBBBB…
upstream mysvr {
server 192.168.0.11:1111;
server 192.168.0.22:2222 backup; #备用
}
轮询
nginx默认就是轮询其权重都默认为1,服务器处理请求的顺序:ABABABABAB…
upstream mysvr {
server 192.168.0.11:1111;
server 192.168.0.33:3333;
server 192.168.0.22:2222 backup; #备用
}
加权轮询
加权轮询:跟据配置的权重的大小而分发给不同服务器不同数量的请求。如果不设置,则默认为1。下面服务器的请求顺序为:ABBABBABBABBABB…
upstream mysvr {
server 192.168.0.11:1111 weight=1;
server 192.168.0.33:3333 weight=1;
server 192.168.0.55:5555 weight=2;
server 192.168.0.22:2222 backup; #备用
}
ip_hash
ip_hash:nginx会让相同的客户端ip请求相同的服务器
upstream mysvr {
server 127.0.0.1:7878;
server 192.168.10.121:3333;
ip_hash;
}
nginx负载均衡配置
- down,表示当前的server暂时不参与负载均衡。
- backup,预留的备份机器。当其他所有的非backup机器出现故障或者忙的时候,才会请求backup机器,因此这台机器的压力最轻。
- max_fails,允许请求失败的次数,默认为1。当超过最大次数时,返回proxy_next_upstream 模块定义的错误。
- fail_timeout,在经历了max_fails次失败后,暂停服务的时间。max_fails可以和fail_timeout一起使用
upstream mysvr {
server 127.0.0.1:7878 weight=2 max_fails=2 fail_timeout=2;
server 192.168.10.121:3333 weight=1 max_fails=2 fail_timeout=1;
}
5.Nginx性能优化
Nginx运行工作进程数量
Nginx运行工作进程个数一般设置CPU的核心或者核心数x2。如果不了解cpu的核数,可以top命令之后按1看出来,也可以查看/proc/cpuinfo文件 grep ^processor /proc/cpuinfo | wc -l
[root@lx~]# vi/usr/local/nginx1.10/conf/nginx.conf
worker_processes 4;
[root@lx~]# /usr/local/nginx1.10/sbin/nginx-s reload
[root@lx~]# ps -aux | grep nginx |grep -v grep
root 9834 0.0 0.0 47556 1948 ? Ss 22:36 0:00 nginx: master processnginx
www 10135 0.0 0.0 50088 2004 ? S 22:58 0:00 nginx: worker process
www 10136 0.0 0.0 50088 2004 ? S 22:58 0:00 nginx: worker process
www 10137 0.0 0.0 50088 2004 ? S 22:58 0:00 nginx: worker process
www 10138 0.0 0.0 50088 2004 ? S 22:58 0:00 nginx: worker process
Nginx运行CPU亲和力
#比如4核配置:
worker_processes 4;
worker_cpu_affinity 0001 0010 0100 1000
#比如8核配置:
worker_processes 8;
worker_cpu_affinity 00000001 00000010 00000100 0000100000010000 00100000 01000000 10000000;
worker_processes最多开启8个,8个以上性能提升不会再提升了,而且稳定性变得更低,所以8个进程够用了。
Nginx最大打开文件数
worker_rlimit_nofile 65535;
这个指令是指当一个nginx进程打开的最多文件描述符数目,理论值应该是最多打开文件数(ulimit -n)与nginx进程数相除,但是nginx分配请求并不是那么均匀,所以最好与ulimit -n的值保持一致。
注:文件资源限制的配置可以在/etc/security/limits.conf设置,针对root/user等各个用户或者*代表所有用户来设置。
* soft nofile 65535
* hard nofile 65535
Nginx事件处理模型
events {
use epoll;
worker_connections 65535;
multi_accept on; #nginx收到一个新连接通知后接收尽可能多的连接
}
nginx采用epoll事件模型,处理效率高。
work_connections是单个worker进程允许客户端最大连接数,这个数值一般根据服务器性能和内存来制定,实际最大值就是worker进程数乘以work_connections。
实际我们填入一个65535,足够了,这些都算并发值,一个网站的并发达到这么大的数量,也算一个大站了!
multi_accept 告诉nginx收到一个新连接通知后接收尽可能多的连接,默认是on,设置为on后,多个worker按串行方式来处理连接,也就是一个连接只有一个worker被唤醒,其他的处于休眠状态,设置为off后,多个worker按并行方式来处理连接,也就是一个连接会唤醒所有的worker,直到连接分配完毕,没有取得连接的继续休眠。当你的服务器连接数不多时,开启这个参数会让负载有一定的降低,但是当服务器的吞吐量很大时,为了效率,可以关闭这个参数。
开启高效传输模式
http {
include mime.types;
default_type application/octet-stream;
……
sendfile on;
tcp_nopush on;
……
}
- Include mime.types : 媒体类型,include 只是一个在当前文件中包含另一个文件内容的指令。
- default_type application/octet-stream :默认媒体类型足够。
- sendfile on:开启高效文件传输模式,sendfile指令指定nginx是否调用sendfile函数来输出文件,对于普通应用设为 on,如果用来进行下载等应用磁盘IO重负载应用,可设置为off,以平衡磁盘与网络I/O处理速度,降低系统的负载。注意:如果图片显示不正常把这个改成off。
- tcp_nopush on:必须在sendfile开启模式才有效,防止网路阻塞,积极的减少网络报文段的数量(将响应头和正文的开始部分一起发送,而不一个接一个的发送。)
连接超时时间
主要目的是保护服务器资源,CPU,内存,控制连接数,因为建立连接也是需要消耗资源的。
keepalive_timeout 60;
tcp_nodelay on;
client_header_buffer_size 4k;
open_file_cache max=102400 inactive=20s;
open_file_cache_valid 30s;
open_file_cache_min_uses 1;
client_header_timeout 15;
client_body_timeout 15;
reset_timedout_connection on;
send_timeout 15;
server_tokens off;
client_max_body_size 10m;
- keepalived_timeout :客户端连接保持会话超时时间,超过这个时间,服务器断开这个链接。
- tcp_nodelay:也是防止网络阻塞,不过要包涵在keepalived参数才有效。
- client_header_buffer_size 4k:客户端请求头部的缓冲区大小,这个可以根据你的系统分页大小来设置,一般一个请求头的大小不会超过 1k,不过由于一般系统分页都要大于1k,所以这里设置为分页大小。分页大小可以用命令getconf PAGESIZE取得。
- open_file_cache max=102400 inactive=20s :这个将为打开文件指定缓存,默认是没有启用的,max指定缓存数量,建议和打开文件数一致,inactive 是指经过多长时间文件没被请求后删除缓存。
- open_file_cache_valid 30s:这个是指多长时间检查一次缓存的有效信息。
- open_file_cache_min_uses 1 :open_file_cache指令中的inactive 参数时间内文件的最少使用次数,如果超过这个数字,文件描述符一直是在缓存中打开的,如上例,如果有一个文件在inactive 时间内一次没被使用,它将被移除。
- client_header_timeout : 设置请求头的超时时间。我们也可以把这个设置低些,如果超过这个时间没有发送任何数据,nginx将返回request time out的错误。
- client_body_timeout设置请求体的超时时间。我们也可以把这个设置低些,超过这个时间没有发送任何数据,和上面一样的错误提示。
- reset_timeout_connection :告诉nginx关闭不响应的客户端连接。这将会释放那个客户端所占有的内存空间。
- send_timeout :响应客户端超时时间,这个超时时间仅限于两个活动之间的时间,如果超过这个时间,客户端没有任何活动,nginx关闭连接。
- server_tokens :并不会让nginx执行的速度更快,但它可以关闭在错误页面中的nginx版本数字,这样对于安全性是有好处的。
- client_max_body_size:上传文件大小限制。
fastcgi 调优
fastcgi_connect_timeout 600;
fastcgi_send_timeout 600;
fastcgi_read_timeout 600;
fastcgi_buffer_size 64k;
fastcgi_buffers 4 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 128k;
fastcgi_temp_path/usr/local/nginx1.10/nginx_tmp;
fastcgi_intercept_errors on;
fastcgi_cache_path/usr/local/nginx1.10/fastcgi_cache levels=1:2 keys_zone=cache_fastcgi:128minactive=1d max_size=10g;
- fastcgi_connect_timeout 600 :指定连接到后端FastCGI的超时时间。
- fastcgi_send_timeout 600 :向FastCGI传送请求的超时时间。
- fastcgi_read_timeout 600 :指定接收FastCGI应答的超时时间。
- fastcgi_buffer_size 64k :指定读取FastCGI应答第一部分需要用多大的缓冲区,默认的缓冲区大小为。fastcgi_buffers指令中的每块大小,可以将这个值设置更小。
- fastcgi_buffers 4 64k :指定本地需要用多少和多大的缓冲区来缓冲FastCGI的应答请求,如果一个php脚本所产生的页面大小为256KB,那么会分配4个64KB的缓冲区来缓存,如果页面大小大于256KB,那么大于256KB的部分会缓存到fastcgi_temp_path指定的路径中,但是这并不是好方法,因为内存中的数据处理速度要快于磁盘。一般这个值应该为站点中php脚本所产生的页面大小的中间值,如果站点大部分脚本所产生的页面大小为256KB,那么可以把这个值设置为“8 32K”、“4 64k”等。
- fastcgi_busy_buffers_size 128k :建议设置为fastcgi_buffers的两倍,繁忙时候的buffer。
- fastcgi_temp_file_write_size 128k :在写入fastcgi_temp_path时将用多大的数据块,默认值是fastcgi_buffers的两倍,该数值设置小时若负载上来时可能报502BadGateway。
- fastcgi_temp_path :缓存临时目录。
- fastcgi_intercept_errors on :这个指令指定是否传递4xx和5xx错误信息到客户端,或者允许nginx使用error_page处理错误信息。注:静态文件不存在会返回404页面,但是php页面则返回空白页!
- fastcgi_cache_path /usr/local/nginx1.10/fastcgi_cachelevels=1:2 keys_zone=cache_fastcgi:128minactive=1d max_size=10g :fastcgi_cache缓存目录,可以设置目录层级,比如1:2会生成16*256个子目录,cache_fastcgi是这个缓存空间的名字,cache是用多少内存(这样热门的内容nginx直接放内存,提高访问速度),inactive表示默认失效时间,如果缓存数据在失效时间内没有被访问,将被删除,max_size表示最多用多少硬盘空间。
- fastcgi_cache cache_fastcgi :#表示开启FastCGI缓存并为其指定一个名称。开启缓存非常有用,可以有效降低CPU的负载,并且防止502的错误放生。cache_fastcgi为proxy_cache_path指令创建的缓存区名称。
- fastcgi_cache_valid 200 302 1h :#用来指定应答代码的缓存时间,实例中的值表示将200和302应答缓存一小时,要和fastcgi_cache配合使用。
- fastcgi_cache_valid 301 1d :将301应答缓存一天。
- fastcgi_cache_valid any 1m :将其他应答缓存为1分钟。
- fastcgi_cache_min_uses 1 :该指令用于设置经过多少次请求的相同URL将被缓存。
- fastcgi_cache_key http:// h o s t host hostrequest_uri :该指令用来设置web缓存的Key值,nginx根据Key值md5哈希存储.一般根据 h o s t ( 域 名 ) 、 host(域名)、 host(域名)、request_uri(请求的路径)等变量组合成proxy_cache_key 。
- fastcgi_pass :指定FastCGI服务器监听端口与地址,可以是本机或者其它。
总结:
nginx的缓存功能有:proxy_cache / fastcgi_cache
- proxy_cache的作用是缓存后端服务器的内容,可能是任何内容,包括静态的和动态。
- fastcgi_cache的作用是缓存fastcgi生成的内容,很多情况是php生成的动态的内容。
- proxy_cache缓存减少了nginx与后端通信的次数,节省了传输时间和后端宽带。
- fastcgi_cache缓存减少了nginx与php的通信的次数,更减轻了php和数据库(mysql)的压力。
gzip 调优
使用gzip压缩功能,可能为我们节约带宽,加快传输速度,有更好的体验,也为我们节约成本,所以说这是一个重点。
Nginx启用压缩功能需要你来ngx_http_gzip_module模块,apache使用的是mod_deflate。
一般我们需要压缩的内容有:文本,js,html,css,对于图片,视频,flash什么的不压缩,同时也要注意,我们使用gzip的功能是需要消耗CPU的!
gzip on;
gzip_min_length 2k;
gzip_buffers 4 32k;
gzip_http_version 1.1;
gzip_comp_level 6;
gzip_typestext/plain text/css text/javascriptapplication/json application/javascript application/x-javascriptapplication/xml;
gzip_vary on;
gzip_proxied any;
gzip on; #开启压缩功能
-
gzip_min_length 1k :设置允许压缩的页面最小字节数,页面字节数从header头的Content-Length中获取,默认值是0,不管页面多大都进行压缩,建议设置成大于1K,如果小与1K可能会越压越大。
-
gzip_buffers 4 32k :压缩缓冲区大小,表示申请4个单位为32K的内存作为压缩结果流缓存,默认值是申请与原始数据大小相同的内存空间来存储gzip压缩结果。
-
gzip_http_version 1.1 :压缩版本,用于设置识别HTTP协议版本,默认是1.1,目前大部分浏览器已经支持GZIP解压,使用默认即可。
-
gzip_comp_level 6 :压缩比例,用来指定GZIP压缩比,1压缩比最小,处理速度最快,9压缩比最大,传输速度快,但是处理慢,也比较消耗CPU资源。
-
gzip_types text/css text/xml application/javascript :用来指定压缩的类型,‘text/html’类型总是会被压缩。默认值: gzip_types text/html (默认不对js/css文件进行压缩)
-
- 压缩类型,匹配MIME型进行压缩;
- 不能用通配符 text/*;
- text/html默认已经压缩 (无论是否指定);
- 设置哪压缩种文本文件可参考 conf/mime.types。
-
gzip_vary on :varyheader支持,改选项可以让前端的缓存服务器缓存经过GZIP压缩的页面,例如用Squid缓存经过nginx压缩的数据。
expires 缓存调优
缓存,主要针对于图片,css,js等元素更改机会比较少的情况下使用,特别是图片,占用带宽大,我们完全可以设置图片在浏览器本地缓存365d,css,js,html可以缓存个10来天,这样用户第一次打开加载慢一点,第二次,就非常快了!缓存的时候,我们需要将需要缓存的拓展名列出来, Expires缓存配置在server字段里面。
location ~* \.(ico|jpe?g|gif|png|bmp|swf|flv)$ {
expires 30d;
#log_not_found off;
access_log off;
}
location ~* \.(js|css)$ {
expires 7d;
log_not_found off;
access_log off;
}
注:log_not_found off;是否在error_log中记录不存在的错误。默认是。
总结:
expire功能优点:
- expires可以降低网站购买的带宽,节约成本;
- 同时提升用户访问体验;
- 减轻服务的压力,节约服务器成本,是web服务非常重要的功能。
expire功能缺点:
- 被缓存的页面或数据更新了,用户看到的可能还是旧的内容,反而影响用户体验。
解决办法:第一个缩短缓存时间,例如:1天,但不彻底,除非更新频率大于1天;第二个对缓存的对象改名。
网站不希望被缓存的内容:
- 网站流量统计工具;
- 更新频繁的文件(google的logo)。
防盗链
防止别人直接从你网站引用图片等链接,消耗了你的资源和网络流量,那么我们的解决办法由几种:
- 水印,品牌宣传,你的带宽,服务器足够;
- 防火墙,直接控制,前提是你知道IP来源;
- 防盗链策略下面的方法是直接给予404的错误提示。
location ~*^.+\.(jpg|gif|png|swf|flv|wma|wmv|asf|mp3|mmf|zip|rar)$ {
valid_referers noneblocked www.benet.com benet.com;
if($invalid_referer) {
#return 302 http://www.benet.com/img/nolink.jpg;
return 404;
break;
}
access_log off;
}
参数可以使如下形式:
- none :意思是不存在的Referer头(表示空的,也就是直接访问,比如直接在浏览器打开一个图片)。
- blocked :意为根据防火墙伪装Referer头,如:“Referer:XXXXXXX”。
- server_names :为一个或多个服务器的列表,0.5.33版本以后可以在名称中使用“*”通配符。
内核参数优化
- fs.file-max = 999999:这个参数表示进程(比如一个worker进程)可以同时打开的最大句柄数,这个参数直线限制最大并发连接数,需根据实际情况配置。
- net.ipv4.tcp_max_tw_buckets = 6000 :这个参数表示操作系统允许TIME_WAIT套接字数量的最大值,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息。该参数默认为180000,过多的TIME_WAIT套接字会使Web服务器变慢。注:主动关闭连接的服务端会产生TIME_WAIT状态的连接
- net.ipv4.ip_local_port_range = 1024 65000 :允许系统打开的端口范围。
- net.ipv4.tcp_tw_recycle = 1 :启用timewait快速回收。
- net.ipv4.tcp_tw_reuse = 1 :开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接。这对于服务器来说很有意义,因为服务器上总会有大量TIME-WAIT状态的连接。
- net.ipv4.tcp_keepalive_time = 30:这个参数表示当keepalive启用时,TCP发送keepalive消息的频度。默认是2小时,若将其设置的小一些,可以更快地清理无效的连接。
- net.ipv4.tcp_syncookies = 1 :开启SYN Cookies,当出现SYN等待队列溢出时,启用cookies来处理。
- net.core.somaxconn = 40960 :web 应用中 listen 函数的 backlog 默认会给我们内核参数的。
- net.core.somaxconn :限制到128,而nginx定义的NGX_LISTEN_BACKLOG 默认为511,所以有必要调整这个值。注:对于一个TCP连接,Server与Client需要通过三次握手来建立网络连接.当三次握手成功后,我们可以看到端口的状态由LISTEN转变为ESTABLISHED,接着这条链路上就可以开始传送数据了.每一个处于监听(Listen)状态的端口,都有自己的监听队列.监听队列的长度与如somaxconn参数和使用该端口的程序中listen()函数有关。somaxconn定义了系统中每一个端口最大的监听队列的长度,这是个全局的参数,默认值为128,对于一个经常处理新连接的高负载 web服务环境来说,默认的 128 太小了。大多数环境这个值建议增加到 1024 或者更多。大的侦听队列对防止拒绝服务 DoS 攻击也会有所帮助。
- net.core.netdev_max_backlog = 262144 :每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
- net.ipv4.tcp_max_syn_backlog = 262144 :这个参数标示TCP三次握手建立阶段接受SYN请求队列的最大长度,默认为1024,将其设置得大一些可以使出现Nginx繁忙来不及accept新连接的情况时,Linux不至于丢失客户端发起的连接请求。
- net.ipv4.tcp_rmem = 10240 87380 12582912 :这个参数定义了TCP接受缓存(用于TCP接受滑动窗口)的最小值、默认值、最大值。
- net.ipv4.tcp_wmem = 10240 87380 12582912:这个参数定义了TCP发送缓存(用于TCP发送滑动窗口)的最小值、默认值、最大值。
- net.core.rmem_default = 6291456:这个参数表示内核套接字接受缓存区默认的大小。
- net.core.wmem_default = 6291456:这个参数表示内核套接字发送缓存区默认的大小。
- net.core.rmem_max = 12582912:这个参数表示内核套接字接受缓存区的最大大小。
- net.core.wmem_max = 12582912:这个参数表示内核套接字发送缓存区的最大大小。
- net.ipv4.tcp_syncookies = 1:该参数与性能无关,用于解决TCP的SYN攻击。
下面贴一个完整的内核优化设置:
fs.file-max = 999999
net.ipv4.ip_forward = 0
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.default.accept_source_route = 0
kernel.sysrq = 0
kernel.core_uses_pid = 1
net.ipv4.tcp_syncookies = 1
kernel.msgmnb = 65536
kernel.msgmax = 65536
kernel.shmmax = 68719476736
kernel.shmall = 4294967296
net.ipv4.tcp_max_tw_buckets = 6000
net.ipv4.tcp_sack = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_rmem = 10240 87380 12582912
net.ipv4.tcp_wmem = 10240 87380 12582912
net.core.wmem_default = 8388608
net.core.rmem_default = 8388608
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.netdev_max_backlog = 262144
net.core.somaxconn = 40960
net.ipv4.tcp_max_orphans = 3276800
net.ipv4.tcp_max_syn_backlog = 262144
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_mem = 94500000 915000000 927000000
net.ipv4.tcp_fin_timeout = 1
net.ipv4.tcp_keepalive_time = 30
net.ipv4.ip_local_port_range = 1024 65000
执行sysctl -p使内核修改生效。
关于系统连接数的优化
linux 默认值 open files为1024。查看当前系统值:
# ulimit -n
1024
说明server只允许同时打开1024个文件。
使用ulimit -a 可以查看当前系统的所有限制值,使用ulimit -n 可以查看当前的最大打开文件数。
新装的linux 默认只有1024 ,当作负载较大的服务器时,很容易遇到error: too many open files。因此,需要将其改大,在/etc/security/limits.conf最后增加:
* soft nofile 65535
* hard nofile 65535
* soft noproc 65535
* hard noproc 65535
Redis
Redis 安装
Windows 下安装
**下载地址:**https://github.com/tporadowski/redis/releases
运行
redis-server.exe redis.windows.conf
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R2jPMkcK-1647763935848)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211016130219079.png)]
C:\Users\d>redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> set mykey abc
OK
127.0.0.1:6379> get mykey
"abc"
127.0.0.1:6379>
Centos 下安装
1.安装gcc依赖
由于 redis 是用 C 语言开发,安装之前必先确认是否安装 gcc 环境(gcc -v),如果没有安装,执行以下命令进行安装
[root@localhost ~]# yum install -y gcc
2.下载并解压安装
[root@localhost local]# cd /usr/local
[root@localhost local]# wget http://download.redis.io/releases/redis-5.0.3.tar.gz
[root@localhost local]# tar -zxvf redis-5.0.3.tar.gz
[root@localhost local]# cd redis-5.0.3
#1.执行编译
[root@localhost redis-5.0.3]# make
#2.安装并指定安装目录
[root@localhost redis-5.0.3]# make install PREFIX=/usr/local/redis
#3.启动服务
#3.1.前台启动
[root@localhost redis-5.0.3]# cd /usr/local/redis/bin/
[root@localhost bin]# ./redis-server redis.conf
#测试连接redis:
$ redis-cli -h host -p port -a password
$redis-cli -h 127.0.0.1 -p 6379 -a "mypass"
C:\Users\d>redis-cli -h 192.168.0.103 -p 6379
192.168.0.103:6379>
#3.2后台启动
#从 redis 的源码目录中复制 redis.conf 到 redis 的安装目录
[root@localhost bin]# cp /usr/local/redis-5.0.3/redis.conf /usr/local/redis/bin/
#修改 redis.conf 文件,把 daemonize no 改为 daemonize yes; 注释 #bind 127.0.0.1
[root@localhost bin]# ./redis-server redis.conf #后台启动
#查看redis进程
[root@localhost bin]# ps -ef |grep redis
root 13563 1 0 13:24 ? 00:00:00 ./redis-server 127.0.0.1:6379
root 13568 8949 0 13:24 pts/3 00:00:00 grep --color=auto redis
3.设置开机启动
添加开机启动服务
[root@localhost bin]# vi /etc/systemd/system/redis.service
#添加 如下内容
[Unit]
Description=redis-server
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/bin/redis.conf
PrivateTmp=true
[Install]
WantedBy=multi-user.target
#注意:ExecStart配置成自己的路径
设置开机启动
[root@localhost bin]# systemctl daemon-reload
[root@localhost bin]# systemctl start redis.service
[root@localhost bin]# systemctl enable redis.service
[root@localhost system]# systemctl status redis.service
[root@localhost system]# ps -ef |grep redis
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dPAsFihT-1647763935850)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211016133301779.png)]
创建 redis 命令软链接
[root@localhost ~]# ln -s /usr/local/redis/bin/redis-cli /usr/bin/redis
#测试redis
[root@localhost system]# redis
127.0.0.1:6379> ping
PONG
127.0.0.1:6379>
#redis服务操作命令
systemctl start redis.service #启动redis服务
systemctl stop redis.service #停止redis服务
systemctl restart redis.service #重新启动服务
systemctl status redis.service #查看服务当前状态
systemctl enable redis.service #设置开机自启动
systemctl disable redis.service #停止开机自启动
4.Redis 配置
[root@localhost bin]# redis
127.0.0.1:6379> CONFIG GET loglevel
1) "loglevel"
2) "notice"
127.0.0.1:6379> CONFIG GET *
1) "dbfilename"
2) "dump.rdb"
3) "requirepass"
127.0.0.1:6379> CONFIG GET maxclients
1) "maxclients"
2) "10000"
编辑配置
你可以通过修改 redis.conf 文件或使用 CONFIG set 命令来修改配置。
语法
CONFIG SET 命令基本语法:
redis 127.0.0.1:6379> CONFIG SET CONFIG_SETTING_NAME NEW_CONFIG_VALUE
127.0.0.1:6379> CONFIG SET loglevel "notice"
OK
127.0.0.1:6379> CONFIG GET loglevel
1) "loglevel"
2) "notice"
| 序号 | 配置项 | 说明 |
|---|---|---|
| 1 | daemonize no | Redis 默认不是以守护进程的方式运行,可以通过该配置项修改,使用 yes 启用守护进程(Windows 不支持守护线程的配置为 no ) |
| 2 | pidfile /var/run/redis.pid | 当 Redis 以守护进程方式运行时,Redis 默认会把 pid 写入 /var/run/redis.pid 文件,可以通过 pidfile 指定d |
| 3 | port 6379 | 指定 Redis 监听端口,默认端口为 6379,作者在自己的一篇博文中解释了为什么选用 6379 作为默认端口,因为 6379 在手机按键上 MERZ 对应的号码,而 MERZ 取自意大利歌女 Alessia Merz 的名字 |
| 4 | bind 127.0.0.1 | 绑定的主机地址 |
| 5 | timeout 300 | 当客户端闲置多长秒后关闭连接,如果指定为 0 ,表示关闭该功能 |
| 6 | loglevel notice | 指定日志记录级别,Redis 总共支持四个级别:debug、verbose、notice、warning,默认为 notice |
| 7 | logfile stdout | 日志记录方式,默认为标准输出,如果配置 Redis 为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给 /dev/null |
| 8 | databases 16 | 设置数据库的数量,默认数据库为0,可以使用SELECT 命令在连接上指定数据库id |
| 9 | save <seconds> <changes> | 指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合 Redis 默认配置文件中提供了三个条件:save 900 1save 300 10save 60 10000分别表示 900 秒(15 分钟)内有 1 个更改,300 秒(5 分钟)内有 10 个更改以及 60 秒内有 10000 个更改 |
| 10 | rdbcompression yes | 指定存储至本地数据库时是否压缩数据,默认为 yes,Redis 采用 LZF 压缩,如果为了节省 CPU 时间,可以关闭该选项,但会导致数据库文件变的巨大 |
| 11 | dbfilename dump.rdb | 指定本地数据库文件名,默认值为 dump.rdb |
| 12 | dir ./ | 指定本地数据库存放目录 |
| 13 | slaveof <masterip> <masterport> | 设置当本机为 slave 服务时,设置 master 服务的 IP 地址及端口,在 Redis 启动时,它会自动从 master 进行数据同步 |
| 14 | masterauth <master-password> | 当 master 服务设置了密码保护时,slave 服务连接 master 的密码 |
| 15 | requirepass foobared | 设置 Redis 连接密码,如果配置了连接密码,客户端在连接 Redis 时需要通过 AUTH 命令提供密码,默认关闭 |
| 16 | maxclients 128 | 设置同一时间最大客户端连接数,默认无限制,Redis 可以同时打开的客户端连接数为 Redis 进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis 会关闭新的连接并向客户端返回 max number of clients reached 错误信息 |
| 17 | maxmemory <bytes> | 指定 Redis 最大内存限制,Redis 在启动时会把数据加载到内存中,达到最大内存后,Redis 会先尝试清除已到期或即将到期的 Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis 新的 vm 机制,会把 Key 存放内存,Value 会存放在 swap 区 |
| 18 | appendonly no | 指定是否在每次更新操作后进行日志记录,Redis 在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis 本身同步数据文件是按上面 save 条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为 no |
| 19 | appendfilename appendonly.aof | 指定更新日志文件名,默认为 appendonly.aof |
| 20 | appendfsync everysec | 指定更新日志条件,共有 3 个可选值:no:表示等操作系统进行数据缓存同步到磁盘(快)always:表示每次更新操作后手动调用 fsync() 将数据写到磁盘(慢,安全)everysec:表示每秒同步一次(折中,默认值) |
| 21 | vm-enabled no | 指定是否启用虚拟内存机制,默认值为 no,简单的介绍一下,VM 机制将数据分页存放,由 Redis 将访问量较少的页即冷数据 swap 到磁盘上,访问多的页面由磁盘自动换出到内存中(在后面的文章我会仔细分析 Redis 的 VM 机制) |
| 22 | vm-swap-file /tmp/redis.swap | 虚拟内存文件路径,默认值为 /tmp/redis.swap,不可多个 Redis 实例共享 |
| 23 | vm-max-memory 0 | 将所有大于 vm-max-memory 的数据存入虚拟内存,无论 vm-max-memory 设置多小,所有索引数据都是内存存储的(Redis 的索引数据 就是 keys),也就是说,当 vm-max-memory 设置为 0 的时候,其实是所有 value 都存在于磁盘。默认值为 0 |
| 24 | vm-page-size 32 | Redis swap 文件分成了很多的 page,一个对象可以保存在多个 page 上面,但一个 page 上不能被多个对象共享,vm-page-size 是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page 大小最好设置为 32 或者 64bytes;如果存储很大大对象,则可以使用更大的 page,如果不确定,就使用默认值 |
| 25 | vm-pages 134217728 | 设置 swap 文件中的 page 数量,由于页表(一种表示页面空闲或使用的 bitmap)是在放在内存中的,,在磁盘上每 8 个 pages 将消耗 1byte 的内存。 |
| 26 | vm-max-threads 4 | 设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4 |
| 27 | glueoutputbuf yes | 设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启 |
| 28 | hash-max-zipmap-entries 64 hash-max-zipmap-value 512 | 指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法 |
| 29 | activerehashing yes | 指定是否激活重置哈希,默认为开启(后面在介绍 Redis 的哈希算法时具体介绍) |
| 30 | include /path/to/local.conf | 指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件 |
Redis 数据类型
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
String(字符串)
string 是 redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value。
string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象。
string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB
redis 127.0.0.1:6379> SET runoob "菜鸟教程"
redis 127.0.0.1:6379> GET runoob
"菜鸟教程"
Hash(哈希)
Redis hash 是一个键值(key=>value)对集合。
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
DEL runoob 用于删除前面测试用过的 key,不然会报错:(error) WRONGTYPE Operation against a key holding the wrong kind of value
127.0.0.1:6379> DEL runoob
127.0.0.1:6379> hmset runoob field1 "Hello" field2 "World"
127.0.0.1:6379> hget runoob field1
"Hello"
127.0.0.1:6379> hget runoob field2
"World"
HMSET 设置了两个 field=>value 对,
HGET 获取对应 field 对应的 value。
每个 hash 可以存储 232 -1 键值对(40多亿)
List(列表)
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
127.0.0.1:6379> lpush mylist redis
(integer) 1
127.0.0.1:6379> lpush mylist mongodb
(integer) 2
127.0.0.1:6379> lpush mylist rebbitmq
(integer) 3
127.0.0.1:6379> lrange mylist 0 10
1) "rebbitmq"
2) "mongodb"
3) "redis"
lpush 向 字符串列表 新增元素
lrange 从 字符串列表 中取值
Set(集合)
Redis 的 Set 是 string 类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
sadd 命令
添加一个 string 元素到 key 对应的 set 集合中,成功返回 1,如果元素已经在集合中返回 0。
127.0.0.1:6379> sadd myset redis
(integer) 1
127.0.0.1:6379> sadd myset mongodb
(integer) 1
127.0.0.1:6379> sadd myset rabbitmq
(integer) 1
127.0.0.1:6379> smembers myset
1) "mongodb"
2) "rabbitmq"
3) "redis"
127.0.0.1:6379>
sadd 向 set中 新增元素
smembers 从 set 中取值
zset(sorted set:有序集合)
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
zadd 命令
添加元素到集合,元素在集合中存在则更新对应score
zadd key score member
127.0.0.1:6379> zadd myzset 0 redis
(integer) 1
127.0.0.1:6379> zadd myzset 0 mongodb
(integer) 1
127.0.0.1:6379> zadd myzset 0 rabbitmq
(integer) 1
127.0.0.1:6379> zadd myzset 0 rabbitmq
(integer) 0
127.0.0.1:6379> ZRANGEBYSCORE myzset 0 1000
1) "mongodb"
2) "rabbitmq"
3) "redis"
zadd 向 zset中 新增元素
ZRANGEBYSCORE 从 zset 中取值
Redis Stream
Redis Stream 是 Redis 5.0 版本新增加的数据结构。
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
Redis Stream 的结构如下所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容
各个数据类型应用场景
| 类型 | 简介 | 特性 | 场景 |
|---|---|---|---|
| String(字符串) | 二进制安全 | 可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M | — |
| Hash(字典) | 键值对集合,即编程语言中的Map类型 | 适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去) | 存储、读取、修改用户属性 |
| List(列表) | 链表(双向链表) | 增删快,提供了操作某一段元素的API | 1,最新消息排行等功能(比如朋友圈的时间线) 2,消息队列 |
| Set(集合) | 哈希表实现,元素不重复 | 1、添加、删除,查找的复杂度都是O(1) 2、为集合提供了求交集、并集、差集等操作 | 1、共同好友 2、利用唯一性,统计访问网站的所有独立ip 3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐 |
| Sorted Set(有序集合) | 将Set中的元素增加一个权重参数score,元素按score有序排列 | 数据插入集合时,已经进行天然排序 | 1、排行榜 2、带权重的消息队列 |
Redis高级使用
Redis 数据备份与恢复
Redis SAVE 命令用于创建当前数据库的备份。
#该命令将在 redis 安装目录中创建dump.rdb文件。
127.0.0.1:6379> save
OK
127.0.0.1:6379>
如果需要恢复数据,只需将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可。获取 redis 目录可以使用 CONFIG 命令
127.0.0.1:6379> CONFIG GET dir
1) "dir"
2) "/"
创建 redis 备份文件也可以使用命令 BGSAVE,该命令在后台执行
Redis安全
查看是否设置了密码验证
127.0.0.1:6379> CONFIG get requirepass
1) "requirepass"
2) ""
默认情况下 requirepass 参数是空的,这就意味着无需通过密码验证就可以连接到 redis 服务
通过以下命令来修改该参数:
127.0.0.1:6379> CONFIG set requirepass "123456"
OK
127.0.0.1:6379> CONFIG get requirepass
(error) NOAUTH Authentication required.
#设置密码后,客户端连接 redis 服务就需要密码验证,否则无法执行命令。
127.0.0.1:6379> auth "123456"
OK
127.0.0.1:6379> CONFIG get requirepass
1) "requirepass"
2) "123456"
redis性能测试
cd /usr/local/redis/bin
[root@localhost bin]# ./redis-benchmark -h 127.0.0.1 -p 6379 -t set,lpush -n 10000 -q
SET: 47393.37 requests per second
LPUSH: 46511.63 requests per second
#主机为 127.0.0.1,端口号为 6379,执行的命令为 set,lpush,请求数为 10000,通过 -q 参数让结果只显示每秒执行的请求数
Redis 客户端连接
Redis 通过监听一个 TCP 端口或者 Unix socket 的方式来接收来自客户端的连接,当一个连接建立后,Redis 内部会进行以下一些操作:
1.首先,客户端 socket 会被设置为非阻塞模式,因为 Redis 在网络事件处理上采用的是非阻塞多路复用模型。
2.然后为这个 socket 设置 TCP_NODELAY 属性,禁用 Nagle 算法
3.然后创建一个可读的文件事件用于监听这个客户端 socket 的数据发送
最大连接数
127.0.0.1:6379> config get maxclients
1) "maxclients"
2) "10000"
Java 使用 Redis
pom.xml 新增仓库地址如下
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
测试redis
package redis;
import redis.clients.jedis.Jedis;
import java.util.Iterator;
import java.util.List;
import java.util.Set;
public class TestRedis {
public static void main(String[] args) {
//连接的 Redis 服务
Jedis jedis = new Jedis("192.168.0.103");
// 如果 Redis 服务设置了密码,需要下面这行,没有就不需要
jedis.auth("123456");
System.out.println("连接成功");
//查看服务是否运行
System.out.println("服务正在运行: " + jedis.ping());
//设置 redis 字符串数据
jedis.set("mystring", "mystringtest");
// 获取存储的数据并输出
System.out.println("redis 存储的字符串为: " + jedis.get("mystring"));
//存储数据到列表中
jedis.lpush("site-list", "Runoob");
jedis.lpush("site-list", "Google");
jedis.lpush("site-list", "Taobao");
// 获取存储的数据并输出
List<String> list = jedis.lrange("site-list", 0, 2);
for (int i = 0; i < list.size(); i++) {
System.out.println("列表项为: " + list.get(i));
}
// Keys 实例 获取数据并输出
Set<String> keys = jedis.keys("*");
Iterator<String> it = keys.iterator();
while (it.hasNext()) {
String key = it.next();
System.out.println(key);
}
}
}
python使用redis
C:\Users\d>pip install redis
import redis
r = redis.StrictRedis(host='192.168.0.103',port=6379,db=0,password="123456")
#redis 字符串
r.set("mystring",'mystring666666666666')
print(r.get("mystring"))
#redis hash
r.hset('hash1','k1','v1')
r.hset('hash1','k11','v11')
r.hset('hash1','k111','v111')
r.hset('hash2','k2','v2')
print(r.hkeys("hash1")) # 取hash中所有的key
print(r.hget("hash1",'k1')) # 单个取hash的key对应的值
print(r.hmget("hash1", "k1", "k11")) # 多个取hash的key对应的值
#redis list
r.lpush("list1",11,22,33)
print(r.lrange("list1",0,-1))
#redis set
r.sadd("set1",33,44,55,66)
print(r.smembers("set1"))
#输出:
b'mystring666666666666'
[b'k1', b'k11', b'k111']
b'v1'
[b'v1', b'v11']
[b'33', b'22', b'11', b'33', b'22', b'11', b'33', b'22', b'11']
{b'55', b'33', b'66', b'44'}
Redis集群
主从模式(master/slaver)
Redis主从同步的搭建
redis默认是主数据,所以master无需配置,我们只需要修改slave的配置即可。
设置需要连接的master的ip端口:
[root@localhost bin]# cd /usr/local/redis_6380/bin
#修改 redis.conf
port:6380
slaveof 192.168.0.103 6379 # 修改slave的配置slaveof 连接master 192.168.0.103 6379
masterauth 123456 #如果master设置了密码
# 启动redis slave
[root@localhost bin]# ./redis-server redis.conf
[root@localhost bin]# ps -ef |grep redis
root 15237 1 0 13:39 ? 00:00:35 /usr/local/redis/bin/redis-server *:6379
root 18397 8949 0 17:00 pts/3 00:00:00 redis
root 21143 1 0 19:54 ? 00:00:00 ./redis-server *:6380
#测试 主redis设置后,从redis直接查看数据是否同步
# 主redis
127.0.0.1:6379> set mymaster 123456789
OK
127.0.0.1:6379> get mymaster
"123456789"
127.0.0.1:6379>
#从redis
[root@localhost bin]# ./redis-cli -p 6380
127.0.0.1:6380> get mymaster
"123456789"
#连接成功进入命令行后,可以通过以下命令行查看连接该数据库的其他库信息:
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:3
master_sync_in_progress:0
slave_repl_offset:331
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:f6491b1278dc44a7f1785ccd01485bc45b8141e6
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:331
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:331
127.0.0.1:6380>
Redis主从原理
Redis全量复制一般发生在slave的初始阶段,这时slave需要将master上的数据都复制一份,具体步骤如下:
(1)、slave连接master,发送SYNC命令;
(2)、master街道SYNC命令后,执行BGSAVE命令生产RDB文件并使用缓冲区记录此后执行的所有写命令;
(3)、master的BGSAVE执行完成后,向所有的slave发送快照文件,并在发送过程中继续记录执行的写命令;
(4)、slave收到快照后,丢弃所有的旧数据,载入收到的数据;
(5)、master快照发送完成后就会开始向slave发送缓冲区的写命令;
(6)、slave完成对快照的载入,并开始接受命令请求,执行来自master缓冲区的写命令;
(7)、slave完成上面的数据初始化后就可以开始接受用户的读请求了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-amdLjuGu-1647763935851)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211016193341191.png)]
Redis主从同步的策略
主从同步刚连接的时候进行全量同步;全量同步结束后开始增量同步。如果有需要,slave在任何时候都可以发起全量同步,其主要策略就是无论如何首先会尝试进行增量同步,如果步成功,则会要求slave进行全量同步,之后再进行增量同步。
注意:如果多个slave同时断线需要重启的时候,因为只要slave启动,就会和master建立连接发送SYNC请求和主机全量同步,如果多个同时发送SYNC请求,可能导致master IO突增而发送宕机。
主从同步的特点
(1)、采用异步复制;
(2)、可以一主多从;
(3)、主从复制对于master来说是非阻塞的,也就是说slave在进行主从复制的过程中,master依然可以处理请求;
(4)、主从复制对于slave来说也是非阻塞的,也就是说slave在进行主从复制的过程中也可以接受外界的查询请求,只不过这时候返回的数据不一定是正确的。为了避免这种情况发生,可以在slave的配置文件中配置,在同步过程中阻止查询;
(5)、每个slave可以接受来自其他slave的连接;
(6)、主从复制提高了Redis服务的扩展性,避免单节点问题,另外也为数据备份冗余提供了一种解决方案;
(7)、为了降低主redis服务器写磁盘压力带来的开销,可以配置让主redis不在将数据持久化到磁盘,而是通过连接让一个配置的从redis服务器及时的将相关数据持久化到磁盘,不过这样会存在一个问题,就是主redis服务器一旦重启,因为主redis服务器数据为空,这时候通过主从同步可能导致从redis服务器上的数据也被清空;
哨兵模式(sentinel)
Redis哨兵模式搭建
只要配置需要监控的master就可以了,哨兵会监控连接该master的slave
cd /usr/local/redis/bin
#配置sentinel.conf文件
port 26379
dir "/tmp/23679" #工作路径,注意路径不要和主重复
#哨兵监控的master,主从配置一样,这里只用输入redis主节点的ip/port和法定人数。
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 192.168.0.103 6379 1 # 修改sentinel.conf文件
# 启动哨兵
# /usr/local/redis/bin/redis-server /usr/local/redis/bin/sentinel.conf --sentinel &
[root@localhost bin]# ./redis-server sentinel.conf --sentinel &
22113:X 16 Oct 2021 20:49:34.370 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
22113:X 16 Oct 2021 20:49:34.370 # Redis version=5.0.3, bits=64, commit=00000000, modified=0, pid=22113, just started
22113:X 16 Oct 2021 20:49:34.370 # Configuration loaded
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 5.0.3 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 22113
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
22113:X 16 Oct 2021 20:49:34.373 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
22113:X 16 Oct 2021 20:49:34.374 # Sentinel ID is 68501a891d8fb51b7c69a1239339b29c565d1d92
22113:X 16 Oct 2021 20:49:34.374 # +monitor master mymaster 192.168.0.103 6379 quorum 1
#sentinel slaves 配置:sentinel.conf文件
sentinel auth-pass mymaster 123456
daemonize yes
#通过哨兵查看集群状态
[root@localhost bin]# ./redis-cli -p 26379
127.0.0.1:26379> sentinel master mymaster
1) "name"
2) "mymaster"
3) "ip"
4) "192.168.0.103"
5) "port"
6) "6379"
7) "runid"
8) ""
127.0.0.1:26379> sentinel slaves mymaster
#模拟主redis down掉
#观察sentinel的状态
127.0.0.1:26379> sentinel master mymaster
1) "name"
2) "mymaster"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6381"
Redis哨兵的任务
哨兵主要用于管理多个Redis服务器,主要有以下三个任务:
(1)、监控:哨兵会不断的检测master和slave之间是否运行正常;
(2)、提醒:当监控的某个Redis出现问题,哨兵可以通过API向管理员或其他应用程序发送通知;
(3)、故障迁移:当一个master不能正常工作时,哨兵会开始一次自动故障迁移操作,它会将失效master的其中一个slave提升为master,并让失效master和其他slave该为复制新的master,当客户端试图连接失效的master时,集群也会向客户端返回新的master地址,使得集群可以使用新的master代替失效的master。
Redis哨兵的工作原理
哨兵是一个分布式系统,你可以在一个架构中运行多个哨兵(sentinel) 进程,这些进程使用流言协议来接收关于Master是否下线的信息,并使用投票协议来决定是否执行自动故障迁移,以及选择哪个Slave作为新的Master。
每个哨兵会向其它哨兵、master、slave定时发送消息,以确认对方是否”活”着,如果发现对方在指定时间(可配置)内未回应,则暂时认为对方已挂。若“哨兵群”中的多数sentinel都报告某一master没响应,系统才认为该master"彻底死亡",通过一定的vote算法,从剩下的slave节点中,选一台提升为master,然后自动修改相关配置。
虽然哨兵释出为一个单独的可执行文件 redis-sentinel ,但实际上它只是一个运行在特殊模式下的 Redis 服务器,你可以在启动一个普通 Redis 服务器时通过给定 --sentinel 选项来启动哨兵。
集群模式(cluster)
Redis集群搭建
要求:至少6个节点,3主3从
#Redis.conf配置:大致如下
port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
# 创建集群
redis集群的命令工具redis-trib可以让我们创建集群变得非常简单。redis-trib是一个用ruby写的脚本,用于给各节点发指令创建集群、检查集群状态或给集群重新分片等。
redis-trib在Redis源码的src目录下,需要gem redis来运行redis-trib。
# 安装ruby环境
# yum -y install zlib zlib-devel pcre pcre-devel gcc gcc-c++ openssl openssl-devel libevent libevent-devel perl unzip net-tools wget curl
# yum install rubygems -y
1.安装curl
sudo yum install curl
2. 安装RVM
curl -L get.rvm.io | bash -s stable
离线安装rvm
https://github.com/rvm/rvm/tags
tar -xzvf rvm-1.29.12.tar.gz
1051 cd rvm-1.29.12
1053 ./install --auto-dotfiles
1054 source /usr/local/rvm/
1056 source /usr/local/rvm/scripts/rvm
4. 查看rvm库中已知的ruby版本
rvm list known
5. 安装一个ruby版本
rvm install 3.0.0
6. 使用一个ruby版本
rvm use 3.0.0
/usr/local/rvm/rvm-1.29.12
7. 设置默认版本
rvm remove 3.0.0
8. 卸载一个已知版本
ruby --version
9. 再安装redis就可以了
gem install redis
/usr/local/rvm/gems/ruby-3.0.0/gems/redis-4.5.1/lib
# 启动集群 方式1:(先启动 6台redis) 该方式 未测试成功
cd /usr/local/redis-5.0.3/src
./redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384
# 启动集群 方式2: (先启动 6台redis)
cd /usr/local/redis/bin
./redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 --cluster-replicas 1
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y0C4DeT1-1647763935851)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211016225113031.png)]
# 测试集群
[root@localhost bin]# ./redis-cli -c -p 6379 # 使用-c参数来启动集群模式
127.0.0.1:6379> set wang ffffffffffffffffffff
OK
127.0.0.1:6379> get wang
"ffffffffffffffffffff"
[root@localhost bin]# ./redis-cli -c -p 6380
127.0.0.1:6380> get wang
-> Redirected to slot [2919] located at 127.0.0.1:6379
"ffffffffffffffffffff"
127.0.0.1:6379> get wang
[root@localhost bin]# ./redis-cli -c -p 6381
127.0.0.1:6381> get wang
-> Redirected to slot [2919] located at 127.0.0.1:6379
"ffffffffffffffffffff"
#1.集群状态
[root@localhost bin]# ./redis-cli -h 127.0.0.1 -p 6379 -a 123456 cluster info
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:703
cluster_stats_messages_pong_sent:729
cluster_stats_messages_sent:1432
cluster_stats_messages_ping_received:724
cluster_stats_messages_pong_received:703
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:1432
#2.集群节点信息
[root@localhost bin]# ./redis-cli -h 127.0.0.1 -p 6379 -a 123456 cluster nodes
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
482572f408ad8ab6b7e06400902f62496eaba00a 127.0.0.1:6379@16379 myself,master - 0 1634396512000 1 connected 0-5460
72868b7199ee48f15419c3d941ec031c4df74edc 127.0.0.1:6381@16381 master - 0 1634396514000 3 connected 10923-16383
51b98c7eee4f45835f2850324f173c8752f4e330 127.0.0.1:6384@16384 slave 91eaf126490f7500cc2601061905efc969f16a3c 0 1634396515960 6 connected
af9a0f09bdba3c23110f2ece0fa6dda5aecdb376 127.0.0.1:6382@16382 slave 72868b7199ee48f15419c3d941ec031c4df74edc 0 1634396512000 4 connected
91eaf126490f7500cc2601061905efc969f16a3c 127.0.0.1:6380@16380 master - 0 1634396514000 2 connected 5461-10922
aa507218f99a8e302797c952e851fc5a48ce67fe 127.0.0.1:6383@16383 slave 482572f408ad8ab6b7e06400902f62496eaba00a 0 1634396513000 5 connected
#3.节点内存、cpu、key数量等信息(每个节点都需查看)
[root@localhost bin]# ./redis-cli -h 127.0.0.1 -p 6379 -a 123456 info
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
# Server
redis_version:5.0.3
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:8196240b4f31c7c3
redis_mode:cluster
#4.从redis集群中查看key(只需要连接master节点查看)
a.查看该节点的所有key
./redis-cli -h 127.0.0.1 -p 6379 -a 123456 keys *
b.查看key的value值
./redis-cli -h 127.0.0.1 -p 6379 -a 123456 -c get key
c.查看key值得有效期
./redis-cli -h 127.0.0.1 -p 6379 -a 123456 -c ttl key
Redis集群的特征
Redis集群有以下几个重要的特征:
(1)、Redis集群的分片特征在于将空间拆分为16384个槽位,某一个节点负责其中一些槽位;
(2)、Redis集群提供一定程度的可用性,可以在某个节点宕机或者不可达的情况继续处理命令;
(3)、Redis集群不存在中心节点或代理节点,集群的其中一个最重要的设计目标是达到线性可扩展性;
Redis集群的原理
Redis Cluster中有一个16384长度的槽的概念,他们的编号为0、1、2、3……16382、16383。这个槽是一个虚拟的槽,并不是真正存在的。正常工作的时候,Redis Cluster中的每个Master节点都会负责一部分的槽,当有某个key被映射到某个Master负责的槽,那么这个Master负责为这个key提供服务,至于哪个Master节点负责哪个槽,这是可以由用户指定的,也可以在初始化的时候自动生成(redis-trib.rb脚本)。这里值得一提的是,在Redis Cluster中,只有Master才拥有槽的所有权,如果是某个Master的slave,这个slave只负责槽的使用,但是没有所有权。
Redis缓存
Rocketmq
RocketMQ 简介
RcoketMQ 是一款低延迟、高可靠、可伸缩、易于使用的消息中间件。具有以下特性:
支持发布/订阅(Pub/Sub)和点对点(P2P)消息模型
在一个队列中可靠的先进先出(FIFO)和严格的顺序传递
支持拉(pull)和推(push)两种消息模式
单一队列百万消息的堆积能力
支持多种消息协议,如 JMS、MQTT 等
分布式高可用的部署架构,满足至少一次消息传递语义
提供 docker 镜像用于隔离测试和云集群部署
提供配置、指标和监控等功能丰富的 Dashboard
专业术语
Producer
消息生产者,生产者的作用就是将消息发送到 MQ,生产者本身既可以产生消息,如读取文本信息等。也可以对外提供接口,由外部应用来调用接口,再由生产者将收到的消息发送到 MQ。
Producer Group
生产者组,简单来说就是多个发送同一类消息的生产者称之为一个生产者组。在这里可以不用关心,只要知道有这么一个概念即可。
Consumer
消息消费者,简单来说,消费 MQ 上的消息的应用程序就是消费者,至于消息是否进行逻辑处理,还是直接存储到数据库等取决于业务需要。
Consumer Group
消费者组,和生产者类似,消费同一类消息的多个 consumer 实例组成一个消费者组。
Topic
Topic 是一种消息的逻辑分类,比如说你有订单类的消息,也有库存类的消息,那么就需要进行分类,一个是订单 Topic 存放订单相关的消息,一个是库存 Topic 存储库存相关的消息。
Message
Message 是消息的载体。一个 Message 必须指定 topic,相当于寄信的地址。Message 还有一个可选的 tag 设置,以便消费端可以基于 tag 进行过滤消息。也可以添加额外的键值对,例如你需要一个业务 key 来查找 broker 上的消息,方便在开发过程中诊断问题。
Tag
标签可以被认为是对 Topic 进一步细化。一般在相同业务模块中通过引入标签来标记不同用途的消息。
Broker
Broker 是 RocketMQ 系统的主要角色,其实就是前面一直说的 MQ。Broker 接收来自生产者的消息,储存以及为消费者拉取消息的请求做好准备。
Name Server
Name Server 为 producer 和 consumer 提供路由信息
RocketMQ 架构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7R6roAUE-1647763935853)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211017164331078.png)]
由这张图可以看到有四个集群,分别是 NameServer 集群、Broker 集群、Producer 集群和 Consumer 集群:
- NameServer: 提供轻量级的服务发现和路由。 每个 NameServer 记录完整的路由信息,提供等效的读写服务,并支持快速存储扩展。
- Broker: 通过提供轻量级的 Topic 和 Queue 机制来处理消息存储,同时支持推(push)和拉(pull)模式以及主从结构的容错机制。
- Producer:生产者,产生消息的实例,拥有相同 Producer Group 的 Producer 组成一个集群。
- Consumer:消费者,接收消息进行消费的实例,拥有相同 Consumer Group 的Consumer 组成一个集群。
简单说明一下图中箭头含义,从 Broker 开始,Broker Master1 和 Broker Slave1 是主从结构,它们之间会进行数据同步,即 Date Sync。同时每个 Broker 与
NameServer 集群中的所有节点建立长连接,定时注册 Topic 信息到所有 NameServer 中。
Producer 与 NameServer 集群中的其中一个节点(随机选择)建立长连接,定期从 NameServer 获取 Topic 路由信息,并向提供 Topic 服务的 Broker Master 建立长连接,且定时向 Broker 发送心跳。Producer 只能将消息发送到 Broker master,但是 Consumer 则不一样,它同时和提供 Topic 服务的 Master 和 Slave
建立长连接,既可以从 Broker Master 订阅消息,也可以从 Broker Slave 订阅消息
RocketMQ 集群部署模式
1.单 master 模式
也就是只有一个 master 节点,称不上是集群,一旦这个 master 节点宕机,那么整个服务就不可用,适合个人学习使用。
2.多 master 模式
多个 master 节点组成集群,单个 master 节点宕机或者重启对应用没有影响。
优点:所有模式中性能最高
缺点:单个 master 节点宕机期间,未被消费的消息在节点恢复之前不可用,消息的实时性就受到影响。
注意:使用同步刷盘可以保证消息不丢失,同时 Topic 相对应的 queue 应该分布在集群中各个节点,而不是只在某各节点上,否则,该节点宕机会对订阅该 topic 的应用造成影响。
3.多 master 多 slave 异步复制模式
在多 master 模式的基础上,每个 master 节点都有至少一个对应的 slave。master节点可读可写,但是 slave 只能读不能写,类似于 mysql 的主备模式。
优点: 在 master 宕机时,消费者可以从 slave 读取消息,消息的实时性不会受影响,性能几乎和多 master 一样。
缺点:使用异步复制的同步方式有可能会有消息丢失的问题。
4.多 master 多 slave 同步双写模式
同多 master 多 slave 异步复制模式类似,区别在于 master 和 slave 之间的数据同步方式。
优点:同步双写的同步模式能保证数据不丢失。
缺点:发送单个消息 RT 会略长,性能相比异步复制低10%左右。
刷盘策略:同步刷盘和异步刷盘(指的是节点自身数据是同步还是异步存储)
同步方式:同步双写和异步复制(指的一组 master 和 slave 之间数据的同步)
注意:要保证数据可靠,需采用同步刷盘和同步双写的方式,但性能会较其他方式低
RocketMQ 单主部署
下载源码并安装
安装maven: wget https://dlcdn.apache.org/maven/maven-3/3.8.3/binaries/apache-maven-3.8.3-bin.tar.gz
vi /etc/profile 配置环境变量。
#在适当的位置添加
export M2_HOME=/usr/local/maven/apache-maven-3.8.3
export PATH=$M2_HOME/bin:$PATH
#保存退出后运行下面的命令使配置生效,或者重启服务器生效。
source /etc/profile
#验证版本
[root@localhost apache-maven-3.8.3]# mvn -v
Apache Maven 3.8.3 (ff8e977a158738155dc465c6a97ffaf31982d739)
Maven home: /usr/local/maven/apache-maven-3.8.3
Java version: 1.8.0_221, vendor: Oracle Corporation, runtime: /usr/java/jdk1.8.0_221/jre
Default locale: zh_CN, platform encoding: UTF-8
OS name: "linux", version: "3.10.0-1160.11.1.el7.x86_64", arch: "amd64", family: "unix"
#方式1:
> git clone https://github.com/alibaba/RocketMQ.git /opt/RocketMQ
> cd /opt/RocketMQ && mvn -Dmaven.test.skip=true clean package install assembly:assembly -U
> cd target/alibaba-rocketmq-broker/alibaba-rocketmq
#方式2:(这里用 方式2)
下载 rocketmq4.2.0发行版源代码
https://www.apache.org/dyn/closer.cgi?path=rocketmq/4.2.0/rocketmq-all-4.2.0-source-release.zip
#或者: https://dlcdn.apache.org/rocketmq/4.9.1/rocketmq-all-4.9.1-source-release.zip
> unzip rocketmq-all-4.9.1-source-release.zip
> cd rocketmq-all-4.9.1-source-release
> mvn -Prelease-all -DskipTests clean install -U
> cd /usr/local/rocketmq/rocketmq-all-4.9.1-source-release/distribution/target/rocketmq-4.9.1/rocketmq-4.9.1
安装成功如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rdbLozSa-1647763935855)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211017174947985.png)]
启动 Rocketmq
启动 Name Server
cd /usr/local/rocketmq/rocketmq-all-4.9.1-source-release/distribution/target/rocketmq-4.9.1/rocketmq-4.9.1/bin
> nohup sh mqnamesrv &
//执行 jps 查看进程
> jps
53770 NamesrvStartup
//查看日志确保服务已正常启动
> tail -f /root/logs/rocketmqlogs/namesrv.log
INFO main - The Name Server boot success. serializeType=JSON
启动 broker
cd /usr/local/rocketmq/rocketmq-all-4.9.1-source-release/distribution/target/rocketmq-4.9.1/rocketmq-4.9.1/bin
> nohup sh mqbroker -n localhost:9876 &
//执行 jps 查看进程
> jps
25954 BrokerStartup
//查看日志确保服务已正常启动
> tail -f ~/logs/rocketmqlogs/broker.log
INFO main - The broker[localhost.localdomain, 192.168.0.103:10911] boot success. serializeType=JSON and name server is localhost:9876
rocketmq搭建的时候内存不足的问题
[root@localhost bin]# sh mqbroker -n localhost:9876
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000005c0000000, 8589934592, 0) failed; error='Cannot allocate memory' (errno=12)
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map 8589934592 bytes for committing reserved memory.
# An error report file with more information is saved as:
# /usr/local/rocketmq/rocketmq-all-4.9.1-source-release/distribution/target/rocketmq-4.9.1/rocketmq-4.9.1/bin/hs_err_pid54327.log
vim bin/runserver.sh ## 记住这个是编译之前改源码里面的改完再次编译,或者直接改编译后的配置
修改内存
JAVA_OPT="${JAVA_OPT} -server -Xms1g -Xmx1g -Xmn512m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
vim bin/runbroker.sh
修改内存
JAVA_OPT="${JAVA_OPT} -server -Xms1g -Xmx1g -Xmn512g"
发送和接收消息
发送/接收消息之前,我们需要告诉客户端 NameServer 地址。RocketMQ 提供了多种方式来实现这一目标。为简单起见,我们使用环境变量 NAMESRV_ADDR。
cd /usr/local/rocketmq/rocketmq-all-4.9.1-source-release/distribution/target/rocketmq-4.9.1/rocketmq-4.9.1/bin
> export NAMESRV_ADDR=localhost:9876
> sh tools.sh org.apache.rocketmq.example.quickstart.Producer
> export NAMESRV_ADDR=localhost:9876
> sh tools.sh org.apache.rocketmq.example.quickstart.Consumer
发送消息:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ziLqs3lT-1647763935858)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211017182418514.png)]
消费消息:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RoM8KoTu-1647763935858)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211017182434246.png)]
关闭服务
#关闭broker
> sh bin/mqshutdown broker
The mqbroker(36695) is running...
Send shutdown request to mqbroker(36695) OK
#关闭namesrv
> sh bin/mqshutdown namesrv
The mqnamesrv(36664) is running...
Send shutdown request to mqnamesrv(36664) OK
java使用 rocketmq demo
第一步:导入依赖
<!-- https://mvnrepository.com/artifact/org.apache.rocketmq/rocketmq-client -->
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.9.1</version>
</dependency>
第二步:创建生产者
package rocketmq;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.client.producer.SendResult;
import org.apache.rocketmq.common.message.Message;
import org.apache.rocketmq.remoting.common.RemotingHelper;
public class Producer {
public static void main(String[] args) throws MQClientException, InterruptedException {
//声明并初始化一个producer
//需要一个producer group名字作为构造方法的参数,这里为producer1
DefaultMQProducer producer = new DefaultMQProducer("producer1");
//设置NameServer地址,此处应改为实际NameServer地址,多个地址之间用;分隔 192.168.0.103:9876;192.168.0.104:9876
//NameServer的地址必须有,但是也可以通过环境变量的方式设置,不一定非得写死在代码里
producer.setNamesrvAddr("192.168.0.103:9876"); //实际为broker的端口为9876
//调用start()方法启动一个producer实例
producer.start();
//发送10条消息到Topic为TopicTest,tag为TagA,消息内容为“Hello RocketMQ”拼接上i的值
for (int i = 0; i < 10; i++) {
try {
Message msg = new Message("TopicTest",// topic
"TagA",// tag
("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET)// body
);
//调用producer的send()方法发送消息
//这里调用的是同步的方式,所以会有返回结果
SendResult sendResult = producer.send(msg);
//打印返回结果,可以看到消息发送的状态以及一些相关信息
System.out.println(sendResult);
} catch (Exception e) {
e.printStackTrace();
Thread.sleep(1000);
}
}
//发送完消息之后,调用shutdown()方法关闭producer
producer.shutdown();
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7agVU7qh-1647763935859)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211017184421122.png)]
第三步:创建消费者
package rocketmq;
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyContext;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.common.message.MessageExt;
import java.util.List;
public class Consumer {
public static void main(String[] args) throws MQClientException {
//创建一个消费者
//consumerGroup:做同样事情的Consumer归为同一个Group,应用必须设置,并保证命名唯一
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("rmq-group");
//设置名称srv地址
consumer.setNamesrvAddr("192.168.0.103:9876");
//实例名称
consumer.setInstanceName("consumer");
//实现订阅
consumer.subscribe("TopicTest", "TagA");
//注册消息监听器
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
for (MessageExt msg : msgs) {
System.out.println(msg.getMsgId() + "---" + new String(msg.getBody()));
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
//启动消费者
consumer.start();
System.out.println("Consumer Started.");
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AKXBCJPQ-1647763935860)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211017185106192.png)]
查看消息是否堆积
cd /usr/local/rocketmq/rocketmq-all-4.9.1-source-release/distribution/target/rocketmq-4.9.1/rocketmq-4.9.1/bin
[root@localhost bin]# sh mqadmin consumerProgress -g rmq-group
RocketMQLog:WARN No appenders could be found for logger (io.netty.util.internal.InternalThreadLocalMap).
RocketMQLog:WARN Please initialize the logger system properly.
#Topic #Broker Name #QID #Broker Offset #Consumer Offset #Diff #LastTime
%RETRY%rmq-group localhost.localdomain 0 0 0 0 N/A
TopicTest localhost.localdomain 0 1008 758 250 2021-10-17 18:48:22
TopicTest localhost.localdomain 1 1007 757 250 2021-10-17 18:48:22
TopicTest localhost.localdomain 2 1007 757 250 2021-10-17 18:48:22
TopicTest localhost.localdomain 3 1008 758 250 2021-10-17 18:48:22
# 说明
#Broker Offset为生产的条数
#Consumer Offset为消费的条数
#Diff为堆积的条数
#消费组:rmq-group 对应topic:TopicTest 还有 Diff= 250*4= 1000条消息还没有消费
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NqGLm8kg-1647763935861)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211017190025184.png)]
rocketmq可视化控制台
1、源码下载地址: https://github.com/apache/rocketmq-externals/releases/tag/rocketmq-console-1.0.0
# 1、修改配置文件,使管理界面与rocketmq集群产生关联。
vi /usr/local/rocketmq/rocketmq-externals-rocketmq-console-1.0.0/rocketmq-console/src/main/resources/application.properties
#if this value is empty,use env value rocketmq.config.namesrvAddr NAMESRV_ADDR
rocketmq.config.namesrvAddr=192.168.0.103:9876
#rocketmq-console's data path:dashboard/monitor
rocketmq.config.dataPath=/tmp/rocketmq-console/data
#2、编译rocketmq-console
cd /usr/local/rocketmq/rocketmq-externals-rocketmq-console-1.0.0/rocketmq-console
# mvn clean package -Dmaven.test.skip=true (注意:不要直接使用mvn package,会提示很多错误)
#3.运行jar包
# cd /usr/local/rocketmq/rocketmq-externals-rocketmq-console-1.0.0/rocketmq-console/target
# nohup java -jar rocketmq-console-ng-1.0.0.jar &
[2021-10-17 22:17:04.655] INFO No TaskScheduler/ScheduledExecutorService bean found for scheduled processing
[2021-10-17 22:17:04.694] INFO Initializing ProtocolHandler ["http-nio-8080"]
[2021-10-17 22:17:04.825] INFO Tomcat started on port(s): 8080 (http)
[2021-10-17 22:17:04.844] INFO Started App in 12.928 seconds (JVM running for 14.49)
#4、使用浏览器访问管理界面
地址:http://192.168.0.200:8080
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o2USsihq-1647763935862)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211017222850200.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cBMJ1dj2-1647763935863)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211017222603234.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2S6bD59k-1647763935864)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211017222655176.png)]
python使用 rocket demo
第一步:安装依赖
pip3 install rocketmq
pip3 install rocketmq-client-python
第二步:创建生产者
# 特此说明: rocketmq-python不支持windows!!!,代码只能在linux or mac环境下执行
from rocketmq.client import Producer, Message
import time
producer = Producer('producer1-louis') #随便
#当有多个服务器地址(集群模式)时,可以使用:
# producer.set_namesrv_addr("xxx.xxx.xxx.xxx:xxxxx,xxx.xxx.xxx.xxx:xxxxx,xxx.xxx.xxx.xxx:xxxxx")
producer.set_namesrv_addr("192.168.0.103:9876")#ip和端口
producer.start()
msg = Message('TopicTest-louis') #topic
msg.set_keys('2021-10-17')
msg.set_tags('TagA')
msg.set_body('{"name":"louiswang","age":"18","address":"nanjing","storage_time":1213ewqw230438refmsl853y2432df}')
for i in range(10):
ret = producer.send_sync(msg)
print(ret.status, ret.msg_id, ret.offset)
producer.shutdown()
生产者 执行 发送消息如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q2HQgE86-1647763935866)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211017225429813.png)]
控制台查看消息:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QEL5uGtj-1647763935867)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211017225532890.png)]
第三步:创建消费者
# 特此说明: rocketmq-python不支持windows!!!,代码只能在linux or mac环境下执行
# 消费方式PushConsumer(即时消费)(不可重复消费)
import time
from rocketmq.client import PushConsumer
def callback(msg):
print(msg)
consumer = PushConsumer('rmq-group-louis')
consumer.set_namesrv_addr('192.168.0.103:9876')
consumer.subscribe("TopicTest-louis",callback)
consumer.start()
while True:
time.sleep(30)
consumer.shutdown()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gzZ8Ccf6-1647763935867)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211017230817178.png)]
JVM
(一):Java 类的加载机制
1、什么是类的加载
类的加载指的是将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个java.lang.Class对象,用来封装类在方法区内的数据结构。类的加载的最终产品是位于堆区中的Class对象,Class对象封装了类在方法区内的数据结构,并且向Java程序员提供了访问方法区内的数据结构的接口。
2、类的生命周期
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WcAf0Tte-1647763935868)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023202350815.png)]
3、类加载器
package com.neo.classloader;
public class ClassLoaderTest {
public static void main(String[] args) {
ClassLoader loader = Thread.currentThread().getContextClassLoader();
System.out.println(loader);
System.out.println(loader.getParent());
System.out.println(loader.getParent().getParent());
}
}
运行后,输出结果:
sun.misc.Launcher$AppClassLoader@64fef26a
sun.misc.Launcher$ExtClassLoader@1ddd40f3
null
从上面的结果可以看出,并没有获取到ExtClassLoader的父Loader,原因是Bootstrap Loader(引导类加载器)是用C语言实现的,找不到一个确定的返回父Loader的方式,于是就返回null。
JVM类加载机制
- 全盘负责,当一个类加载器负责加载某个Class时,该Class所依赖的和引用的其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入
- 父类委托,先让父类加载器试图加载该类,只有在父类加载器无法加载该类时才尝试从自己的类路径中加载该类
- 缓存机制,缓存机制将会保证所有加载过的Class都会被缓存,当程序中需要使用某个Class时,类加载器先从缓存区寻找该Class,只有缓存区不存在,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存入缓存区。这就是为什么修改了Class后,必须重启JVM,程序的修改才会生效
4、类的加载
类加载有三种方式:
- 1、命令行启动应用时候由JVM初始化加载
- 2、通过Class.forName()方法动态加载
- 3、通过ClassLoader.loadClass()方法动态加载
package com.neo.classloader;
public class loaderTest {
public static void main(String[] args) throws ClassNotFoundException {
ClassLoader loader = HelloWorld.class.getClassLoader();
System.out.println(loader);
//使用ClassLoader.loadClass()来加载类,不会执行初始化块
loader.loadClass("Test2");
//使用Class.forName()来加载类,默认会执行初始化块
//Class.forName("Test2");
//使用Class.forName()来加载类,并指定ClassLoader,初始化时不执行静态块
//Class.forName("Test2", false, loader);
}
}
分别切换加载方式,会有不同的输出结果。
Class.forName()和ClassLoader.loadClass()区别
Class.forName():将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块;ClassLoader.loadClass():只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。Class.forName(name, initialize, loader)带参函数也可控制是否加载static块。并且只有调用了newInstance()方法采用调用构造函数,创建类的对象 。
(二): Jvm 内存结构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xxkhudlb-1647763935869)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023203624011.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rnwD6DQp-1647763935870)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023203649864.png)]
JVM内存结构主要有三大块:堆内存、方法区和栈。
堆内存是JVM中最大的一块由年轻代和老年代组成,而年轻代内存又被分成三部分:
年轻代: Eden空间、From Survivor空间、To Survivor空间, 默认情况下年轻代按照8:1:1的比例来分配
方法区 存储类信息、常量、静态变量等数据,是线程共享的区域,为与Java堆区分,方法区还有一个别名Non-Heap(非堆);栈又分为java虚拟机栈和本地方法栈主要用于方法的执行
在通过一张图来了解如何通过参数来控制各区域的内存大小:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bBYHYgak-1647763935871)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023204349266.png)]
控制参数
- -Xms设置堆的最小空间大小。
- -Xmx设置堆的最大空间大小。
- -XX:NewSize设置新生代最小空间大小。
- -XX:MaxNewSize设置新生代最大空间大小。
- -XX:PermSize设置永久代最小空间大小。
- -XX:MaxPermSize设置永久代最大空间大小。
- -Xss设置每个线程的堆栈大小。
没有直接设置老年代的参数,但是可以设置堆空间大小和新生代空间大小两个参数来间接控制
JVM和系统调用之间的关系:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Kp2rCeXO-1647763935872)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023204912029.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XB5GPDev-1647763935873)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023205527689.png)]
Java堆(Heap)
Java堆(Java Heap)是Java虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。
Java堆是垃圾收集器管理的主要区域,因此很多时候也被称做“GC堆”。如果从内存回收的角度看,由于现在收集器基本都是采用的分代收集算法,所以Java堆中还可以细分为:新生代和老年代;再细致一点的有Eden空间、From Survivor空间、To Survivor空间等。
根据Java虚拟机规范的规定,Java堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,就像我们的磁盘空间一样。在实现时,既可以实现成固定大小的,也可以是可扩展的,不过当前主流的虚拟机都是按照可扩展来实现的(通过-Xmx和-Xms控制)。
如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError异常
方法区(Method Area)
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,**它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。**虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来
当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常。
方法区有时被称为持久代(PermGen)。
所有的对象在实例化后的整个运行周期内,都被存放在堆内存中。堆内存又被划分成不同的部分:伊甸区(Eden),幸存者区域(Survivor Sapce),老年代(Old Generation Space)。
方法的执行都是伴随着线程的。原始类型的本地变量以及引用都存放在线程栈中。而引用关联的对象比如String,都存在在堆中。
通过JConsole工具可以查看运行中的Java程序的一些信息:堆内存的分配,线程的数量以及加载的类的个数;
打开 jdk1.8.0_161\bin\JConsole.exe应用程序:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fW4kSpmf-1647763935873)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023211306919.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zgVmmzOH-1647763935875)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023211359399.png)]
程序计数器(Program Counter Register)
程序计数器 是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里(仅是概念模型,各种虚拟机可能会通过一些更高效的方式去实现),字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成.
JVM栈(JVM Stacks)
与程序计数器一样,Java虚拟机栈(Java Virtual Machine Stacks)也是线程私有的,**它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的内存模型:**每个方法被执行的时候都会同时创建一个栈帧(Stack Frame)用于存储局部变量表、操作栈、动态链接、方法出口等信息。每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常;
如果虚拟机栈可以动态扩展(当前大部分的Java虚拟机都可动态扩展,只不过Java虚拟机规范中也允许固定长度的虚拟机栈),当扩展时无法申请到足够的内存时会抛出OutOfMemoryError异常。
本地方法栈(Native Method Stacks)
本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而**本地方法栈则是为虚拟机使用到的Native方法服务。**虚拟机规范中对本地方法栈中的方法使用的语言、使用方式与数据结构并没有强制规定,因此具体的虚拟机可以自由实现它。甚至有的虚拟机(譬如Sun HotSpot虚拟机)直接就把本地方法栈和虚拟机栈合二为一。
与虚拟机栈一样,本地方法栈区域也会抛出StackOverflowError和OutOfMemoryError异常。
不同OutOfMemoryErrors产生的原因如下:
Exception in thread “main”: java.lang.OutOfMemoryError: Java heap space
原因:对象不能被分配到堆内存中
Exception in thread “main”: java.lang.OutOfMemoryError: PermGen space
原因:类或者方法不能被加载到持久代。它可能出现在一个程序加载很多类的时候,比如引用了很多第三方的库;
Exception in thread “main”: java.lang.OutOfMemoryError: Requested array size exceeds VM limit
原因:创建的数组大于堆内存的空间
Exception in thread “main”: java.lang.OutOfMemoryError: request <size> bytes for <reason>. Out of swap space?
原因:分配本地分配失败。JNI、本地库或者Java虚拟机都会从本地堆中分配内存空间。
Exception in thread “main”: java.lang.OutOfMemoryError: <reason> <stack trace>(Native method)
原因:同样是本地方法内存分配失败,只不过是JNI或者本地方法或者Java虚拟机发现
(三):GC 算法 垃圾收集器
垃圾收集 Garbage Collection 通常被称为“GC”。
jvm 中,程序计数器、虚拟机栈、本地方法栈都是随线程而生随线程而灭,栈帧随着方法的进入和退出做入栈和出栈操作,实现了自动的内存清理,因此,我们的内存垃圾回收主要集中于 java 堆和方法区中,在程序运行期间,这部分内存的分配和使用都是动态的
对象存活判断
判断对象是否存活一般有两种方式:
引用计数:每个对象有一个引用计数属性,新增一个引用时计数加1,引用释放时计数减1,计数为0时可以回收。此方法简单,无法解决对象相互循环引用的问题。
可达性分析(Reachability Analysis):从GC Roots开始向下搜索,搜索所走过的路径称为引用链。当一个对象到GC Roots没有任何引用链相连时,则证明此对象是不可用的。不可达对象。
在Java语言中,GC Roots包括:
- 虚拟机栈中引用的对象。
- 方法区中类静态属性实体引用的对象。
- 方法区中常量引用的对象。
- 本地方法栈中JNI引用的对象。
对象流转过程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UQNvXWZX-1647763935876)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211024203346109.png)]
垃圾收集算法
标记 -清除算法
标记-清除(Mark-Sweep)算法,如它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。之所以说它是最基础的收集算法,是因为后续的收集算法都是基于这种思路并对其缺点进行改进而得到的。
它的主要缺点有两个:一个是效率问题,标记和清除过程的效率都不高;另外一个是空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致,当程序在以后的运行过程中需要分配较大对象时无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6KCxtRkZ-1647763935876)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023212642194.png)]
复制算法
“复制”(Copying)的收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
这样使得每次都是对其中的一块进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为原来的一半,持续复制长生存期的对象则导致效率降低。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3Q2XvpnR-1647763935877)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023212717920.png)]
标记-压缩(整理)算法
复制收集算法在对象存活率较高时就要执行较多的复制操作,效率将会变低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
根据老年代的特点,有人提出了另外一种“标记-整理”(Mark-Compact)算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ztgusPSd-1647763935878)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023212751959.png)]
分代收集算法
GC分代的基本假设:绝大部分对象的生命周期都非常短暂,存活时间短。
“分代收集”(Generational Collection)算法,把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。
在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。
而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用**“标记-清理**”或“标记-整理”算法来进行回收。
垃圾收集器
收集算法是内存回收的方法论,垃圾收集器就是内存回收的具体实现
串行(Serial)收集器
串行收集器是最古老,最稳定以及效率高的收集器,可能会产生较长的停顿,只使用一个线程去回收。新生代、老年代使用串行回收;新生代复制算法、老年代标记-压缩;垃圾收集的过程中会Stop The World(服务暂停)
参数控制:-XX:+UseSerialGC 串行收集器
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gkfGlWVU-1647763935879)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023213001757.png)]
**ParNew收集器 **其实就是Serial收集器的多线程版本。新生代并行,老年代串行;新生代复制算法、老年代标记-压缩
参数控制:
-XX:+UseParNewGC ParNew收集器
-XX:ParallelGCThreads 限制线程数量
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mwf96WR2-1647763935880)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023213030395.png)]
Parallel收集器
Parallel Scavenge收集器类似ParNew收集器,Parallel收集器更关注系统的吞吐量。可以通过参数来打开自适应调节策略,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或最大的吞吐量;也可以通过参数控制GC的时间不大于多少毫秒或者比例;新生代复制算法、老年代标记-压缩
参数控制:-XX:+UseParallelGC 使用Parallel收集器+ 老年代串行
Parallel Old 收集器
Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法。这个收集器是在JDK 1.6中才开始提供
参数控制: -XX:+UseParallelOldGC 使用Parallel收集器+ 老年代并行
CMS收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。目前很大一部分的Java应用都集中在互联网站或B/S系统的服务端上,这类应用尤其重视服务的响应速度,希望系统停顿时间最短,以给用户带来较好的体验。
从名字(包含“Mark Sweep”)上就可以看出CMS收集器是基于“标记-清除”算法实现的,它的运作过程相对于前面几种收集器来说要更复杂一些,整个过程分为4个步骤,包括:
- 初始标记(CMS initial mark)
- 并发标记(CMS concurrent mark)
- 重新标记(CMS remark)
- 并发清除(CMS concurrent sweep)
其中初始标记、重新标记这两个步骤仍然需要“Stop The World”。初始标记仅仅只是标记一下GC Roots能直接关联到的对象,速度很快,并发标记阶段就是进行GC Roots Tracing的过程,而重新标记阶段则是为了修正并发标记期间,因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。
由于整个过程中耗时最长的并发标记和并发清除过程中,收集器线程都可以与用户线程一起工作,所以总体上来说,CMS收集器的内存回收过程是与用户线程一起并发地执行。老年代收集器(新生代使用ParNew)
优点: 并发收集、低停顿
缺点: 产生大量空间碎片、并发阶段会降低吞吐量
参数控制:
-XX:+UseConcMarkSweepGC 使用CMS收集器
-XX:+ UseCMSCompactAtFullCollection Full GC后,进行一次碎片整理;整理过程是独占的,会引起停顿时间变长
-XX:+CMSFullGCsBeforeCompaction 设置进行几次Full GC后,进行一次碎片整理
-XX:ParallelCMSThreads 设定CMS的线程数量(一般情况约等于可用CPU数量)
G1收集器
G1是目前技术发展的最前沿成果之一,HotSpot开发团队赋予它的使命是未来可以替换掉JDK1.5中发布的CMS收集器。与CMS收集器相比G1收集器有以下特点:
- 空间整合,G1收集器采用标记整理算法,不会产生内存空间碎片。分配大对象时不会因为无法找到连续空间而提前触发下一次GC。
- 可预测停顿,这是G1的另一大优势,降低停顿时间是G1和CMS的共同关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为N毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒,这几乎已经是实时Java(RTSJ)的垃圾收集器的特征了。
上面提到的垃圾收集器,收集的范围都是整个新生代或者老年代,而G1不再是这样。使用G1收集器时,Java堆的内存布局与其他收集器有很大差别,它将整个Java堆划分为多个大小相等的独立区域(Region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔阂了,它们都是一部分(可以不连续)Region的集合。
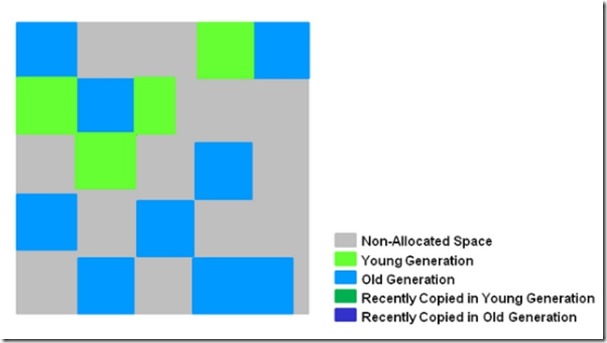
G1的新生代收集跟ParNew类似,当新生代占用达到一定比例的时候,开始出发收集。和CMS类似,G1收集器收集老年代对象会有短暂停顿。
收集步骤:
- 1、标记阶段,首先初始标记(Initial-Mark),这个阶段是停顿的(Stop the World Event),并且会触发一次普通Mintor GC。对应GC log:GC pause (young) (inital-mark)
- 2、Root Region Scanning,程序运行过程中会回收survivor区(存活到老年代),这一过程必须在young GC之前完成。
- 3、Concurrent Marking,在整个堆中进行并发标记(和应用程序并发执行),此过程可能被young GC中断。在并发标记阶段,若发现区域对象中的所有对象都是垃圾,那个这个区域会被立即回收(图中打X)。同时,并发标记过程中,会计算每个区域的对象活性(区域中存活对象的比例)。
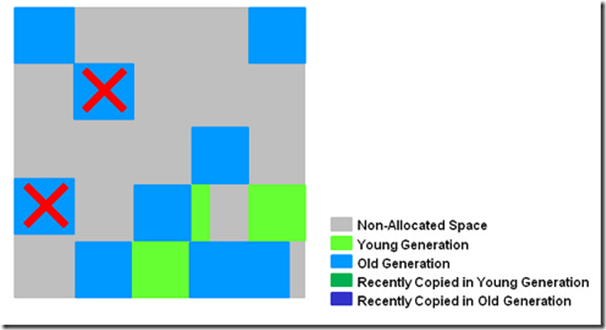
- 4、Remark, 再标记,会有短暂停顿(STW)。再标记阶段是用来收集 并发标记阶段 产生新的垃圾(并发阶段和应用程序一同运行);G1中采用了比CMS更快的初始快照算法:snapshot-at-the-beginning (SATB)。
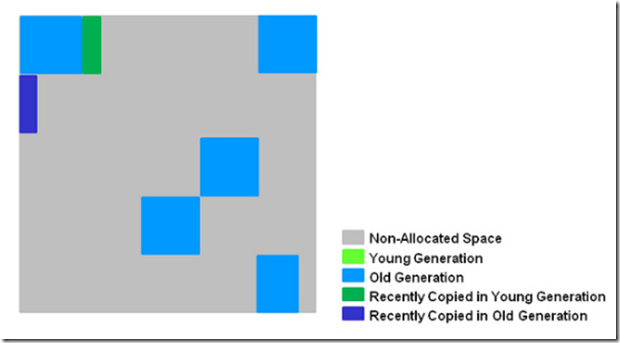
- 5、Copy/Clean up,多线程清除失活对象,会有STW。G1将回收区域的存活对象拷贝到新区域,清除Remember Sets,并发清空回收区域并把它返回到空闲区域链表中。

- 6、复制/清除过程后。回收区域的活性对象已经被集中回收到深蓝色和深绿色区域。
常用的收集器组合
| 收集器组合 | 新生代GC策略 | 老年代GC策略 | 说明 |
|---|---|---|---|
| 组合1 | Serial | Serial Old | Serial和Serial Old都是单线程进行GC,特点就是GC时暂停所有应用线程。 |
| 组合2 | Serial | CMS+Serial Old | CMS(Concurrent Mark Sweep)是并发GC,实现GC线程和应用线程并发工作,不需要暂停所有应用线程。另外,当CMS进行GC失败时,会自动使用Serial Old策略进行GC。 |
| 组合3 | ParNew | CMS | 使用-XX:+UseParNewGC选项来开启。ParNew是Serial的并行版本,可以指定GC线程数,默认GC线程数为CPU的数量。可以使用-XX:ParallelGCThreads选项指定GC的线程数。如果指定了选项-XX:+UseConcMarkSweepGC选项,则新生代默认使用ParNew GC策略。 |
| 组合4 | ParNew | Serial Old | 使用-XX:+UseParNewGC选项来开启。新生代使用ParNew GC策略,年老代默认使用Serial Old GC策略。 |
| 组合5 | Parallel Scavenge | Serial Old | Parallel Scavenge策略主要是关注一个可控的吞吐量:应用程序运行时间 / (应用程序运行时间 + GC时间),可见这会使得CPU的利用率尽可能的高,适用于后台持久运行的应用程序,而不适用于交互较多的应用程序。 |
| 组合6 | Parallel Scavenge | Parallel Old | Parallel Old是Serial Old的并行版本 |
| 组合7 | G1GC | G1GC | -XX:+UnlockExperimentalVMOptions -XX:+UseG1GC #开启;-XX:MaxGCPauseMillis =50 #暂停时间目标;-XX:GCPauseIntervalMillis =200 #暂停间隔目标;-XX:+G1YoungGenSize=512m #年轻代大小;-XX:SurvivorRatio=6` #幸存区比例 |
(四): Jvm 调优-命令篇
运用jvm自带的命令可以方便的在生产监控和打印堆栈的日志信息帮忙我们来定位问题!虽然jvm调优成熟的工具已经有很多:jconsole、大名鼎鼎的VisualVM,IBM的Memory Analyzer等等,但是在生产环境出现问题的时候,一方面工具的使用会有所限制,另一方面喜欢装X的我们,总喜欢在出现问题的时候在终端输入一些命令来解决。所有的工具几乎都是依赖于jdk的接口和底层的这些命令,研究这些命令的使用也让我们更能了解jvm构成和特性。
Sun JDK监控和故障处理命令有 jps jstat jmap jhat jstack jinfo
jps
JVM Process Status Tool,显示指定系统内所有的HotSpot虚拟机进程。
命令格式
jps [options] [hostid]
option参数
- -l : 输出主类全名或jar路径
- -q : 只输出LVMID
- -m : 输出JVM启动时传递给main()的参数
- -v : 输出JVM启动时显示指定的JVM参数
其中[option]、[hostid]参数也可以不写。
示例
[root@localhost springboot]# jps -l -m
3027 org.apache.rocketmq.broker.BrokerStartup -n localhost:9876
15258 sun.tools.jps.Jps -l -m
11422 springboot_demo-0.0.1-SNAPSHOT.jar
2991 org.apache.rocketmq.namesrv.NamesrvStartup
jstat
jstat(JVM statistics Monitoring)是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。
命令格式
jstat [option] LVMID [interval] [count]
参数
- [option] : 操作参数
- LVMID : 本地虚拟机进程ID
- [interval] : 连续输出的时间间隔
- [count] : 连续输出的次数
option 参数总览
| Option | Displays… |
|---|---|
| class | class loader的行为统计。Statistics on the behavior of the class loader. |
| compiler | HotSpt JIT编译器行为统计。Statistics of the behavior of the HotSpot Just-in-Time compiler. |
| gc | 垃圾回收堆的行为统计。Statistics of the behavior of the garbage collected heap. |
| gccapacity | 各个垃圾回收代容量(young,old,perm)和他们相应的空间统计。Statistics of the capacities of the generations and their corresponding spaces. |
| gcutil | 垃圾回收统计概述。Summary of garbage collection statistics. |
| gccause | 垃圾收集统计概述(同-gcutil),附加最近两次垃圾回收事件的原因。Summary of garbage collection statistics (same as -gcutil), with the cause of the last and |
| gcnew | 新生代行为统计。Statistics of the behavior of the new generation. |
| gcnewcapacity | 新生代与其相应的内存空间的统计。Statistics of the sizes of the new generations and its corresponding spaces. |
| gcold | 年老代和永生代行为统计。Statistics of the behavior of the old and permanent generations. |
| gcoldcapacity | 年老代行为统计。Statistics of the sizes of the old generation. |
| gcpermcapacity | 永生代行为统计。Statistics of the sizes of the permanent generation. |
| printcompilation | HotSpot编译方法统计。HotSpot compilation method statistics. |
option 参数详解
-gc (常用命令)
垃圾回收堆的行为统计
[root@localhost springboot]# jstat -gc 11422
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
4096.0 4096.0 93.1 0.0 33088.0 29455.7 82516.0 50765.4 67120.0 62365.5 8752.0 7985.3 296 9.382 5 46.301 55.683
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zY90TBDX-1647763935887)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023215039113.png)]
C即Capacity 总容量,U即Used 已使用的容量
- S0C : survivor0区的总容量
- S1C : survivor1区的总容量
- S0U : survivor0区已使用的容量
- S1U : survivor1区已使用的容量
- EC : Eden区的总容量
- EU : Eden区已使用的容量
- OC : Old区的总容量
- OU : Old区已使用的容量
- PC 当前perm的容量 (KB)
- PU perm的使用 (KB)
- YGC : 新生代垃圾回收次数
- YGCT : 新生代垃圾回收时间
- FGC : 老年代垃圾回收次数
- FGCT : 老年代垃圾回收时间
- GCT : 垃圾回收总消耗时间
$ jstat -gc 11422 2000 20
这个命令意思就是每隔2000ms输出11422(PID) 的gc情况,一共输出20次
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KuATnxQR-1647763935888)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023215222588.png)]
-gcutil
同-gc,不过输出的是已使用空间占总空间的百分比
[root@localhost springboot]# jstat -gcutil 11422
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
4.44 0.00 76.94 61.76 92.93 91.25 468 10.264 5 46.301 56.565
-class
监视类装载、卸载数量、总空间以及耗费的时间
[root@localhost springboot]# jstat -class 11422
Loaded Bytes Unloaded Bytes Time
11742 21309.6 180 210.7 96.38
- Loaded : 加载class的数量
- Bytes : class字节大小
- Unloaded : 未加载class的数量
- Bytes : 未加载class的字节大小
- Time : 加载时间
-compiler
输出JIT编译过的方法数量耗时等
[root@localhost springboot]# jstat -compiler 11422
Compiled Failed Invalid Time FailedType FailedMethod
12070 2 0 117.59 1 org/springframework/beans/factory/support/AbstractBeanFactory isTypeMatch
- Compiled : 编译数量
- Failed : 编译失败数量
- Invalid : 无效数量
- Time : 编译耗时
- FailedType : 失败类型
- FailedMethod : 失败方法的全限定名
-gccapacity
同-gc,不过还会输出Java堆各区域使用到的最大、最小空间
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UeA6UaaK-1647763935889)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023215601288.png)]
[root@localhost springboot]# jstat -gccapacity 11422
NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC
10240.0 155648.0 41280.0 4096.0 4096.0 33088.0 20480.0 311296.0 82516.0 82516.0 0.0 1107968.0 67120.0 0.0 1048576.0 8752.0 468 5
- NGCMN : 新生代占用的最小空间
- NGCMX : 新生代占用的最大空间
- OGCMN : 老年代占用的最小空间
- OGCMX : 老年代占用的最大空间
- OGC:当前年老代的容量 (KB)
- OC:当前年老代的空间 (KB)
- PGCMN : perm占用的最小空间
- PGCMX : perm占用的最大空间
-gccause
垃圾收集统计概述(同-gcutil),附加最近两次垃圾回收事件的原因
[root@localhost springboot]# jstat -gccause 11422
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT LGCC GCC
4.44 0.00 77.03 61.76 92.93 91.25 468 10.264 5 46.301 56.565 Allocation Failure No GC
- LGCC:最近垃圾回收的原因
- GCC:当前垃圾回收的原因
-gcnew
统计新生代的行为
[root@localhost springboot]# jstat -gcnew 11422
S0C S1C S0U S1U TT MTT DSS EC EU YGC YGCT
4096.0 4096.0 181.9 0.0 15 15 2048.0 33088.0 25505.3 468 10.264
- TT:Tenuring threshold(提升阈值)
- MTT:最大的tenuring threshold
- DSS:survivor区域大小 (KB)
-gcnewcapacity
新生代与其相应的内存空间的统计
$ jstat -gcnewcapacity 11422
[root@localhost springboot]# jstat -gcnewcapacity 11422
NGCMN NGCMX NGC S0CMX S0C S1CMX S1C ECMX EC YGC FGC
10240.0 155648.0 41280.0 15552.0 4096.0 15552.0 4096.0 124544.0 33088.0 468 5
- NGC:当前年轻代的容量 (KB)
- S0CMX:最大的S0空间 (KB)
- S0C:当前S0空间 (KB)
- ECMX:最大eden空间 (KB)
- EC:当前eden空间 (KB)
-gcold
统计旧生代的行为
[root@localhost springboot]# jstat -gcold 11422
MC MU CCSC CCSU OC OU YGC FGC FGCT GCT
67120.0 62376.1 8752.0 7986.4 82516.0 50964.3 468 5 46.301 56.565
-gcoldcapacity
统计旧生代的大小和空间
$ jstat -gcoldcapacity 11422
OGCMN OGCMX OGC OC YGC FGC FGCT GCT
6291456.0 6291456.0 6291456.0 6291456.0 4 0 0.000 0.242
-gcpermcapacity
永生代行为统计
$ jstat -gcpermcapacity 28920
PGCMN PGCMX PGC PC YGC FGC FGCT GCT
1048576.0 2097152.0 1048576.0 1048576.0 4 0 0.000 0.242
-printcompilation
hotspot编译方法统计
$ jstat -printcompilation 28920
Compiled Size Type Method
1291 78 1 java/util/ArrayList indexOf
- Compiled:被执行的编译任务的数量
- Size:方法字节码的字节数
- Type:编译类型
- Method:编译方法的类名和方法名。类名使用”/” 代替 “.” 作为空间分隔符. 方法名是给出类的方法名. 格式是一致于HotSpot - XX:+PrintComplation 选项
jmap
jmap(JVM Memory Map)命令用于生成 heap dump文件,如果不使用这个命令,还阔以使用-XX:+HeapDumpOnOutOfMemoryError参数来让虚拟机出现OOM的时候·自动生成dump文件。 jmap不仅能生成dump文件,还阔以查询finalize执行队列、Java堆和永久代的详细信息,如当前使用率、当前使用的是哪种收集器等。
命令格式
jmap [option] LVMID
jmap -dump:live,format=b,file=dump.hprof 11422
dump.hprof 这个后缀是为了后续可以直接用MAT(Memory Anlysis Tool)打开。
option参数
- dump : 生成堆转储快照
- finalizerinfo : 显示在F-Queue队列等待Finalizer线程执行finalizer方法的对象 (打印等待回收对象的信息)
- heap : 显示Java堆详细信息
- histo : 显示堆中对象的统计信息
- permstat : to print permanent generation statistics
- F : 当-dump没有响应时,强制生成dump快照
示例
-dump
常用格式
-dump::live,format=b,file=<filename> pid
dump堆到文件,format指定输出格式,live指明是活着的对象,file指定文件名
$ jmap -dump:live,format=b,file=dump.hprof 11422
Dumping heap to /home/xxx/dump.hprof ...
Heap dump file created
dump.hprof这个后缀是为了后续可以直接用MAT(Memory Anlysis Tool)打开。
-finalizerinfo
打印等待回收对象的信息
$ jmap -finalizerinfo 28920
Attaching to process ID 28920, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 24.71-b01
Number of objects pending for finalization: 0
可以看到当前F-QUEUE队列中并没有等待Finalizer线程执行finalizer方法的对象。
-heap
打印heap的概要信息,GC使用的算法,heap的配置及wise heap的使用情况,可以用此来判断内存目前的使用情况以及垃圾回收情况
$ jmap -heap 11422
Attaching to process ID 28920, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 24.71-b01
using thread-local object allocation.
Parallel GC with 4 thread(s)//GC 方式
Heap Configuration: //堆内存初始化配置
MinHeapFreeRatio = 0 //对应jvm启动参数-XX:MinHeapFreeRatio设置JVM堆最小空闲比率(default 40)
MaxHeapFreeRatio = 100 //对应jvm启动参数 -XX:MaxHeapFreeRatio设置JVM堆最大空闲比率(default 70)
MaxHeapSize = 2082471936 (1986.0MB) //对应jvm启动参数-XX:MaxHeapSize=设置JVM堆的最大大小
NewSize = 1310720 (1.25MB)//对应jvm启动参数-XX:NewSize=设置JVM堆的‘新生代’的默认大小
MaxNewSize = 17592186044415 MB//对应jvm启动参数-XX:MaxNewSize=设置JVM堆的‘新生代’的最大大小
OldSize = 5439488 (5.1875MB)//对应jvm启动参数-XX:OldSize=<value>:设置JVM堆的‘老生代’的大小
NewRatio = 2 //对应jvm启动参数-XX:NewRatio=:‘新生代’和‘老生代’的大小比率
SurvivorRatio = 8 //对应jvm启动参数-XX:SurvivorRatio=设置年轻代中Eden区与Survivor区的大小比值
PermSize = 21757952 (20.75MB) //对应jvm启动参数-XX:PermSize=<value>:设置JVM堆的‘永生代’的初始大小
MaxPermSize = 85983232 (82.0MB)//对应jvm启动参数-XX:MaxPermSize=<value>:设置JVM堆的‘永生代’的最大大小
G1HeapRegionSize = 0 (0.0MB)
Heap Usage://堆内存使用情况
PS Young Generation
Eden Space://Eden区内存分布
capacity = 33030144 (31.5MB)//Eden区总容量
used = 1524040 (1.4534378051757812MB) //Eden区已使用
free = 31506104 (30.04656219482422MB) //Eden区剩余容量
4.614088270399305% used //Eden区使用比率
From Space: //其中一个Survivor区的内存分布
capacity = 5242880 (5.0MB)
used = 0 (0.0MB)
free = 5242880 (5.0MB)
0.0% used
To Space: //另一个Survivor区的内存分布
capacity = 5242880 (5.0MB)
used = 0 (0.0MB)
free = 5242880 (5.0MB)
0.0% used
PS Old Generation //当前的Old区内存分布
capacity = 86507520 (82.5MB)
used = 0 (0.0MB)
free = 86507520 (82.5MB)
0.0% used
PS Perm Generation//当前的 “永生代” 内存分布
capacity = 22020096 (21.0MB)
used = 2496528 (2.3808746337890625MB)
free = 19523568 (18.619125366210938MB)
11.337498256138392% used
670 interned Strings occupying 43720 bytes.
可以很清楚的看到Java堆中各个区域目前的情况。
-histo
打印堆的对象统计,包括对象数、内存大小等等 (因为在dump:live前会进行full gc,如果带上live则只统计活对象,因此不加live的堆大小要大于加live堆的大小 )
$ jmap -histo:live 11422 | more
num #instances #bytes class name
----------------------------------------------
1: 83613 12012248 <constMethodKlass>
2: 23868 11450280 [B
3: 83613 10716064 <methodKlass>
4: 76287 10412128 [C
5: 8227 9021176 <constantPoolKlass>
6: 8227 5830256 <instanceKlassKlass>
7: 7031 5156480 <constantPoolCacheKlass>
8: 73627 1767048 java.lang.String
9: 2260 1348848 <methodDataKlass>
10: 8856 849296 java.lang.Class
....
仅仅打印了前10行
xml class name是对象类型,说明如下:
B byte
C char
D double
F float
I int
J long
Z boolean
[ 数组,如[I表示int[]
[L+类名 其他对象
-F
强制模式。如果指定的pid没有响应,请使用jmap -dump或jmap -histo选项。此模式下,不支持live子选项。
jhat
jhat(JVM Heap Analysis Tool)命令是与jmap搭配使用,用来分析jmap生成的dump,jhat内置了一个微型的HTTP/HTML服务器,生成dump的分析结果后,可以在浏览器中查看。在此要注意,一般不会直接在服务器上进行分析,因为jhat是一个耗时并且耗费硬件资源的过程,一般把服务器生成的dump文件复制到本地或其他机器上进行分析。
命令格式
jhat [dumpfile]
参数
- -stack false|true 关闭对象分配调用栈跟踪(tracking object allocation call stack)。 如果分配位置信息在堆转储中不可用. 则必须将此标志设置为 false. 默认值为 true.>
- -refs false|true 关闭对象引用跟踪(tracking of references to objects)。 默认值为 true. 默认情况下, 返回的指针是指向其他特定对象的对象,如反向链接或输入引用(referrers or incoming references), 会统计/计算堆中的所有对象。>
- -port port-number 设置 jhat HTTP server 的端口号. 默认值 7000.>
- -exclude exclude-file 指定对象查询时需要排除的数据成员列表文件(a file that lists data members that should be excluded from the reachable objects query)。 例如, 如果文件列列出了 java.lang.String.value , 那么当从某个特定对象 Object o 计算可达的对象列表时, 引用路径涉及 java.lang.String.value 的都会被排除。>
- -baseline exclude-file 指定一个基准堆转储(baseline heap dump)。 在两个 heap dumps 中有相同 object ID 的对象会被标记为不是新的(marked as not being new). 其他对象被标记为新的(new). 在比较两个不同的堆转储时很有用.>
- -debug int 设置 debug 级别. 0 表示不输出调试信息。 值越大则表示输出更详细的 debug 信息.>
- -version 启动后只显示版本信息就退出>
- -J< flag > 因为 jhat 命令实际上会启动一个JVM来执行, 通过 -J 可以在启动JVM时传入一些启动参数. 例如, -J-Xmx512m 则指定运行 jhat 的Java虚拟机使用的最大堆内存为 512 MB. 如果需要使用多个JVM启动参数,则传入多个 -Jxxxxxx.
示例
[root@localhost springboot]# jhat -J-Xmx512m dump.hprof
Reading from dump.hprof...
Dump file created Sat Oct 23 22:05:27 CST 2021
Snapshot read, resolving...
Resolving 445924 objects...
Chasing references, expect 89 dots.........................................................................................
Eliminating duplicate references.........................................................................................
Snapshot resolved.
Started HTTP server on port 7000
Server is ready.
中间的-J-Xmx512m是在dump快照很大的情况下分配512M内存去启动HTTP服务器,运行完之后就可在浏览器打开
Http://localhost:7000进行快照分析 堆快照分析主要在最后面的Heap Histogram里,里面根据class列出了dump的时候所有存活对象。
分析同样一个dump快照,MAT需要的额外内存比jhat要小的多的多,所以建议使用MAT来进行分析,当然也看个人偏好。
分析
打开浏览器Http://localhost:7000,该页面提供了几个查询功能可供使用:
All classes including platform
Show all members of the rootset
Show instance counts for all classes (including platform)
Show instance counts for all classes (excluding platform)
Show heap histogramShow finalizer summary
Execute Object Query Language (OQL) query
一般查看堆异常情况主要看这个两个部分: Show instance counts for all classes (excluding platform),平台外的所有对象信息。如下图:

Show heap histogram 以树状图形式展示堆情况。如下图:

具体排查时需要结合代码,观察是否大量应该被回收的对象在一直被引用或者是否有占用内存特别大的对象无法被回收。
一般情况,会down到客户端用工具来分析
jstack
jstack用于 生成java虚拟机当前时刻的 线程快照。线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,
生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。 线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源。
如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。另外,jstack工具还可以附属到正在运行的java程序中,看到当时运行的java程序的java stack和native stack的信息, 如果现在运行的java程序呈现hung的状态,jstack是非常有用的。
命令格式
jstack [option] LVMID
option参数
- -F : 当正常输出请求不被响应时,强制输出线程堆栈
- -l : 除堆栈外,显示关于锁的附加信息
- -m : 如果调用到本地方法的话,可以显示C/C++的堆栈
示例
[root@localhost ~]# jstack -l 11422 | more
[root@localhost ~]# jstack -l 11422 > jstack.log
2021-10-23 22:27:57
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.221-b11 mixed mode):
"http-nio-8080-exec-282" #406 daemon prio=5 os_prio=0 tid=0x00007f5e1c162000 nid=0x3e3e waiting on condition [0x00007f5dfd19c000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000edf45f68> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)
at org.apache.tomcat.util.threads.TaskQueue.take(TaskQueue.java:146)
at org.apache.tomcat.util.threads.TaskQueue.take(TaskQueue.java:33)
at org.apache.tomcat.util.threads.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1114)
at org.apache.tomcat.util.threads.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1176)
at org.apache.tomcat.util.threads.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:659)
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)
at java.lang.Thread.run(Thread.java:748)
Locked ownable synchronizers:
- None
jinfo
jinfo(JVM Configuration info)这个命令作用是实时查看和调整虚拟机运行参数。 之前的jps -v口令只能查看到显示指定的参数,如果想要查看未被显示指定的参数的值就要使用jinfo口令
命令格式
jinfo [option] [args] LVMID
option参数
- -flag : 输出指定args参数的值
- -flags : 不需要args参数,输出所有JVM参数的值
- -sysprops : 输出系统属性,等同于System.getProperties()
示例
$ jinfo -flag 11422 -XX:CMSInitiatingOccupancyFraction=80
(五): Java GC日志分析
什么是 Java GC
Java GC(Garbage Collection,垃圾收集,垃圾回收)机制,是Java与C++/C的主要区别之一,作为Java开发者,一般不需要专门编写内存回收和垃圾清理代码,对内存泄露和溢出的问题,也不需要像C程序员那样战战兢兢。
这是因为在Java虚拟机中,存在自动内存管理和垃圾清扫机制。概括地说,该机制对JVM(Java Virtual Machine)中的内存进行标记,并确定哪些内存需要回收,根据一定的回收策略,自动的回收内存,永不停息(Nerver Stop)的保证JVM中的内存空间,防止出现内存泄露和溢出问题。
在Java语言出现之前,就有GC机制的存在,如Lisp语言),Java GC机制已经日臻完善,几乎可以自动的为我们做绝大多数的事情。然而,如果我们从事较大型的应用软件开发,曾经出现过内存优化的需求,就必定要研究Java GC机制。
简单总结一下,Java GC就是通过GC收集器回收不在存活的对象,保证JVM更加高效的运转。
如何获取 Java GC日志
一般情况可以通过两种方式来获取GC日志,
一种是使用命令动态查看,
一种是在容器中设置相关参数打印GC日志。
命令动态查看
Java 自动的工具行命令,jstat可以用来动态监控JVM内存的使用,统计垃圾回收的各项信息。
比如常用命令,jstat -gc 统计垃圾回收堆的行为
$ jstat -gc 11422
S0C S1C S0U S1U EC EU OC OU PC PU YGC YGCT FGC FGCT GCT
26112.0 24064.0 6562.5 0.0 564224.0 76274.5 434176.0 388518.3 524288.0 42724.7 320 6.417 1 0.398 6.815
也可以设置间隔固定时间来打印:
$ jstat -gc 11422 2000 20
这个命令意思就是每隔2000ms输出1262的gc情况,一共输出20次
GC参数
JVM的GC日志的主要参数包括如下几个:
-XX:+PrintGC输出GC日志-XX:+PrintGCDetails输出GC的详细日志-XX:+PrintGCTimeStamps输出GC的时间戳(以基准时间的形式)-XX:+PrintGCDateStamps输出GC的时间戳(以日期的形式,如 2017-09-04T21:53:59.234+0800)-XX:+PrintHeapAtGC在进行GC的前后打印出堆的信息-Xloggc:../logs/gc.log日志文件的输出路径
在生产环境中,根据需要配置相应的参数来监控JVM运行情况。
nohup java -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -Xloggc:gc.log -jar springboot_demo-0.0.1-SNAPSHOT.jar &
Tomcat 设置示例
我们经常在tomcat的启动参数中添加JVM相关参数,这里有一个典型的示例:
JAVA_OPTS="-server -Xms2000m -Xmx2000m -Xmn800m -XX:PermSize=64m -XX:MaxPermSize=256m -XX:SurvivorRatio=4
-verbose:gc -Xloggc:$CATALINA_HOME/logs/gc.log
-Djava.awt.headless=true
-XX:+PrintGCTimeStamps -XX:+PrintGCDetails
-Dsun.rmi.dgc.server.gcInterval=600000 -Dsun.rmi.dgc.client.gcInterval=600000
-XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=15"
根据上面的参数我们来做一下解析:
-Xms2000m -Xmx2000m -Xmn800m -XX:PermSize=64m -XX:MaxPermSize=256m
Xms,即为jvm启动时得JVM初始堆大小,Xmx为jvm的最大堆大小,xmn为新生代的大小,permsize为永久代的初始大小,MaxPermSize为永久代的最大空间。-XX:SurvivorRatio=4
SurvivorRatio为新生代空间中的Eden区和救助空间Survivor区的大小比值,默认是8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10。调小这个参数将增大survivor区,让对象尽量在survitor区呆长一点,减少进入年老代的对象。去掉救助空间的想法是让大部分不能马上回收的数据尽快进入年老代,加快年老代的回收频率,减少年老代暴涨的可能性,这个是通过将-XX:SurvivorRatio 设置成比较大的值(比如65536)来做到。-verbose:gc -Xloggc:$CATALINA_HOME/logs/gc.log
将虚拟机每次垃圾回收的信息写到日志文件中,文件名由file指定,文件格式是平文件,内容和-verbose:gc输出内容相同。-Djava.awt.headless=trueHeadless模式是系统的一种配置模式。在该模式下,系统缺少了显示设备、键盘或鼠标。-XX:+PrintGCTimeStamps -XX:+PrintGCDetails
设置gc日志的格式-Dsun.rmi.dgc.server.gcInterval=600000 -Dsun.rmi.dgc.client.gcInterval=600000
指定rmi调用时gc的时间间隔-XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=15采用并发gc方式,经过15次minor gc 后进入年老代
如何分析GC日志
摘录GC日志一部分
nohup java -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -Xloggc:gc.log -jar springboot_demo-0.0.1-SNAPSHOT.jar &
# Allocation Failure:表明本次引起GC的原因是因为在年轻代中没有足够的空间能够存储新的数据了
Java HotSpot(TM) 64-Bit Server VM (25.221-b11) for linux-amd64 JRE (1.8.0_221-b11), built on Jul 4 2019 04:27:00 by "java_re" with gcc 7.3.0
Memory: 4k page, physical 1863004k(372128k free), swap 2097148k(1312692k free)
CommandLine flags: -XX:InitialHeapSize=29808064 -XX:MaxHeapSize=476929024 -XX:+PrintGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops
2021-10-23T17:55:47.585+0800: 0.495: [GC (Allocation Failure) 2021-10-23T17:55:47.585+0800: 0.495: [DefNew: 8192K->1023K(9216K), 0.0031688 secs] 8192K->1525K(29696K), 0.0032308 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
2021-10-23T22:05:26.666+0800: 14979.576: [Full GC (Heap Dump Initiated GC) 2021-10-23T22:05:26.666+0800: 14979.576: [Tenured: 48524K->47297K(82516K), 0.3677685 secs] 51607K->47297K(119700K), [Metaspace: 62381K->62381K(1107968K)], 0.3679763 secs] [Times: user=0.27 sys=0.06, real=0.37 secs]
2021-10-23T22:11:03.589+0800: 15316.500: [Full GC (Heap Inspection Initiated GC) 2021-10-23T22:11:03.589+0800: 15316.500: [Tenured: 47297K->41569K(82516K), 0.5060519 secs] 76374K->41569K(119700K), [Metaspace: 62367K->62367K(1107968K)], 0.5061461 secs] [Times: user=0.13 sys=0.01, real=0.50 secs]
Young GC回收日志:
2016-07-05T10:43:18.093+0800: 25.395: [GC [PSYoungGen: 274931K->10738K(274944K)] 371093K->147186K(450048K), 0.0668480 secs] [Times: user=0.17 sys=0.08, real=0.07 secs]
Full GC回收日志:
2016-07-05T10:43:18.160+0800: 25.462: [Full GC [PSYoungGen: 10738K->0K(274944K)] [ParOldGen: 136447K->140379K(302592K)] 147186K->140379K(577536K) [PSPermGen: 85411K->85376K(171008K)], 0.6763541 secs] [Times: user=1.75 sys=0.02, real=0.68 secs]
通过上面日志分析得出,PSYoungGen、ParOldGen、PSPermGen属于Parallel收集器。其中
PSYoungGen表示gc回收前后年轻代的内存变化;
ParOldGen表示gc回收前后老年代的内存变化;
PSPermGen表示gc回收前后永久区的内存变化。
young gc 主要是针对年轻代进行内存回收比较频繁,耗时短;
full gc 会对整个堆内存进行回城,耗时长,因此一般尽量减少full gc的次数
通过两张图非常明显看出gc日志构成:
Young GC日志:
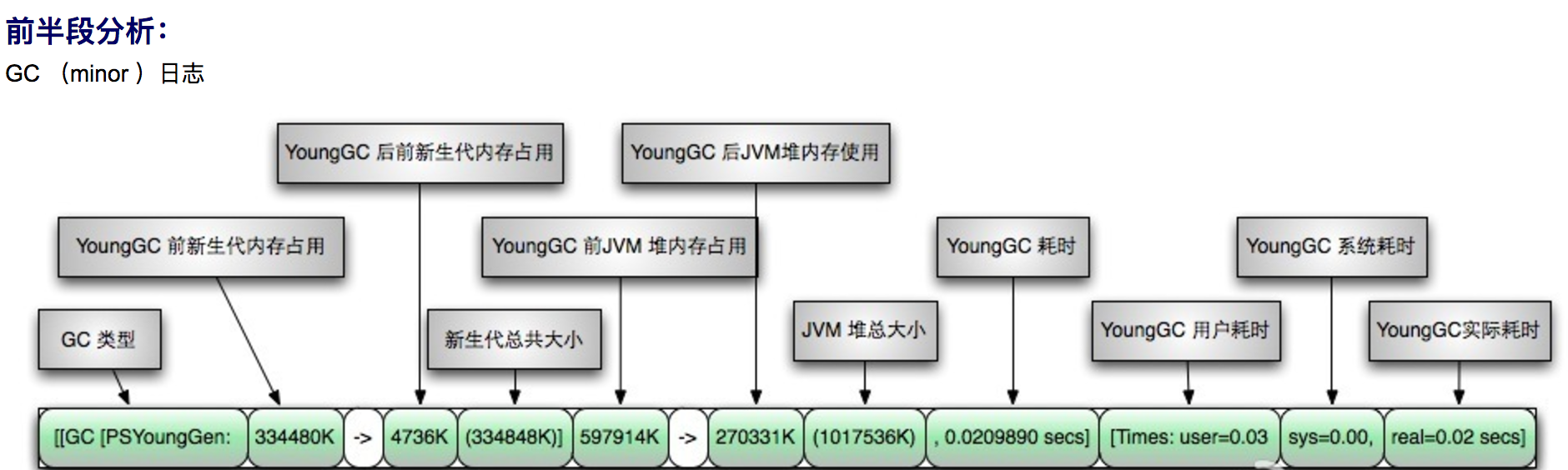
Full GC日志:
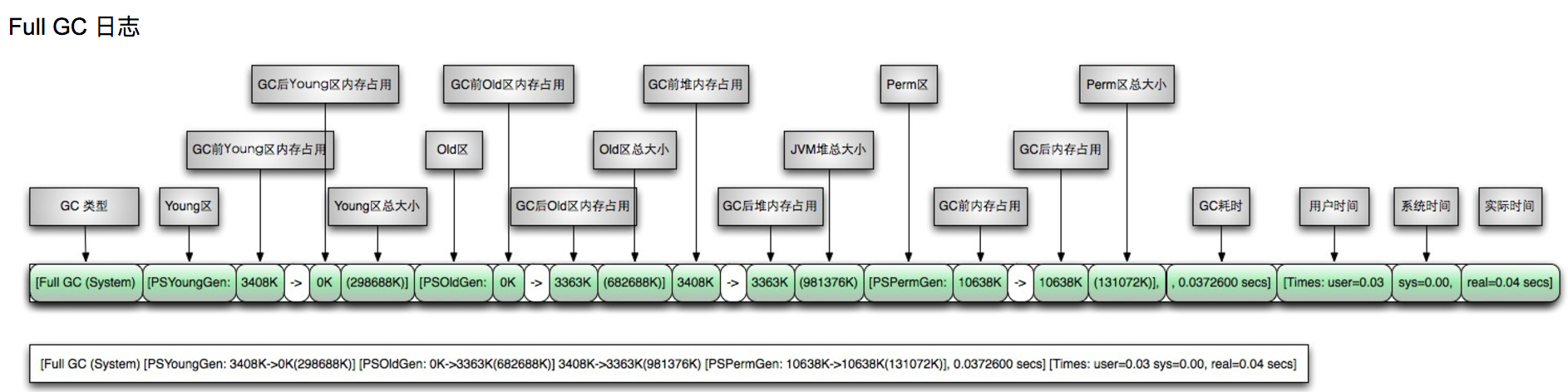
GC分析工具
GChisto
GChisto是一款专业分析gc日志的工具,可以通过gc日志来分析:Minor GC、full gc的时间、频率等等,通过列表、报表、图表等不同的形式来反应gc的情况。虽然界面略显粗糙,但是功能还是不错的。
配置好本地的jdk环境之后,双击 GChisto.jar,在弹出的输入框中点击 add 选择gc.log日志
- GC Pause Stats:可以查看GC 的次数、GC的时间、GC的开销、最大GC时间和最小GC时间等,以及相应的柱状图
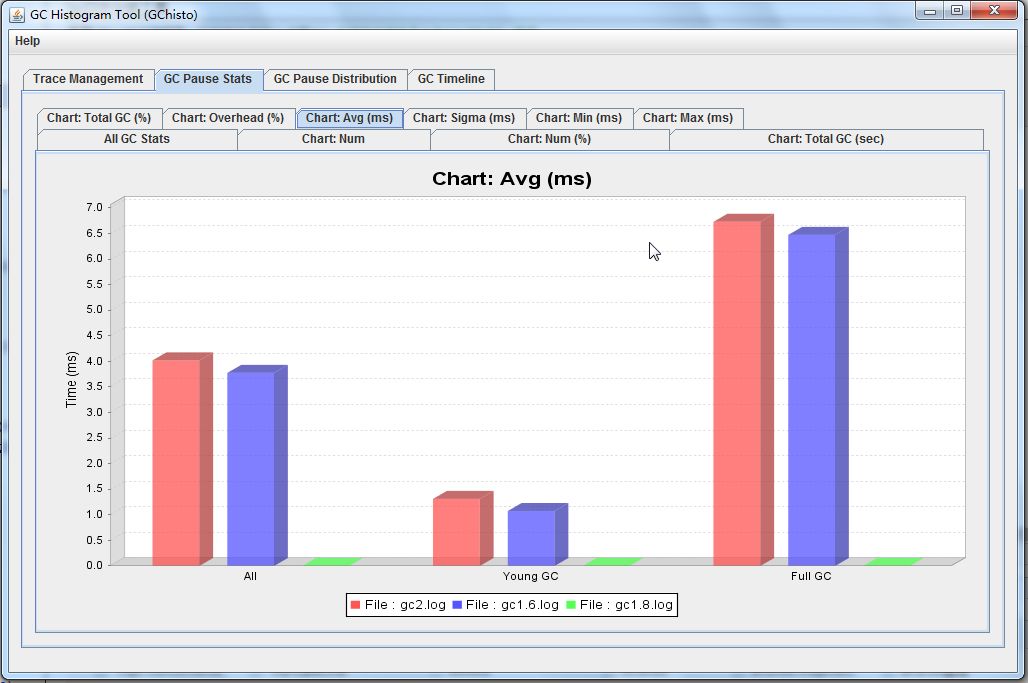
- GC Pause Distribution:查看GC停顿的详细分布,x轴表示垃圾收集停顿时间,y轴表示是停顿次数。
- GC Timeline:显示整个时间线上的垃圾收集
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uvlc0y8K-1647763935896)(http://favorites.ren/assets/images/2017/jvm/g3.jpg)]
不过这款工具已经不再维护
GC Easy
这是一个web工具,在线使用非常方便.
地址: http://gceasy.io
进入官网,讲打包好的zip或者gz为后缀的压缩包上传,过一会就会拿到分析结果。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vWLTk3Dm-1647763935897)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023224538004.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ct3cyhwc-1647763935898)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023224620558.png)]
推荐使用此工具进行gc分析。
(六): Java 服务 GC 参数调优案例
本文介绍了一次生产环境的JVM GC相关参数的调优过程,通过参数的调整避免了GC卡顿对JAVA服务成功率的影响
背景以及遇到的问题
我们的Java HTTP服务属于OLTP类型,对成功率和响应时间的要求比较高,在生产环境中出现偶现的成功率突然下降然后又自动恢复的情况,如图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-60KoAYO4-1647763935898)(https://segmentfault.com/img/bVzypy?w=710&h=258)]
JVM和GC相关的参数如下:
-Xmx22528m
-Xms22528m
-XX:NewRatio=2
-XX:+UseConcMarkSweepGC
-XX:+UseParNewGC
-XX:+CMSParallelRemarkEnabled
总结来说,由于服务中大量使用了Cache,所以堆大小开到了22G。GC算法使用CMS(UseConcMarkSweepGC),开启了降低标记停顿(CMSParallelRemarkEnabled),设置年轻代为并行收集(UseParNewGC),年轻代和老年代的比例为1:2 (NewRatio=2).
JVM GC日志相关的参数如下:
-Xloggc:/data/gc.log
-XX:GCLogFileSize=10M
-XX:NumberOfGCLogFiles=10
-XX:+UseGCLogFileRotation
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-XX:+PrintGCDetails
-XX:+DisableExplicitGC
-verbose:gc
问题解决过程
排除应用程序的内存使用问题
首先使用jmap查看内存使用情况:
jmap -histo:live PID
这个命令把程序中当前的对象按照个数和占用的空间排序以后打印出来。这里没有发现使用异常的对象。
排除Cache内容过多的问题
如果Cache内容过多也会导致JVM老年代容易被用满导致频繁GC,因此调出GC日志进行查看,发现每次GC以后内存使用一般是从20G降低到5G左右,因此常驻内存的Cache不是导致GC长时间卡顿的根本原因。对于GC LOG的查看有多种方式,使用VisualVM比较直观,需要安装VisualGC插件:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uU4kNKRW-1647763935899)(https://segmentfault.com/img/bVzCJy?w=738&h=406)]
从图中我们可以看到伊甸园和老年代的空间分配,由于整体内存是20G,设置 -XX:NewRatio=2 因此老年代是14G,伊甸园+S0+S1=7G
调整GC时间点(成功率抖动问题加重)
如果GC需要处理的内存量比较大,执行的时间也就比较长,STW (Stop the World)时间也就更长。按照这个思路调整CMS启动的时间点,希望提早GC,也就是让GC变得更加频繁但是期望每次执行的时间较少。添加了下面这两个参数:
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=50
意思是说在Old区使用了50%的时候触发GC。实验后发现GC的频率有所增加,但是每次GC造成的陈功率降低现象并没有减弱,因此弃用这两个参数。
调整对象在年轻代内存中驻留的时间(效果不明显)
如果能够降低老年代GC的频率也可以达到降低GC影响的目的,因此尝试让对象在年轻代内存中进行更长时间的驻留,提升这些对象在年轻代GC时候被销毁的概率。使用参数 -XX:MaxTenuringThreshold=31调整以后收效不明显。
CMS-Remark之前强制进行年轻代的GC
首先补充一下CMS的相关知识,在CMS整个过程中有两个步骤是STW的,如图红色部分:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fpsvF93D-1647763935900)(https://segmentfault.com/img/bVzCJG?w=826&h=372)]
CMS并非没有暂停,而是用两次短暂停来替代串行标记整理算法的长暂停,它的收集周期是这样:
- 初始标记(CMS-initial-mark),从root对象开始标记存活的对象
- 并发标记(CMS-concurrent-mark)
- 重新标记(CMS-remark),暂停所有应用程序线程,重新标记并发标记阶段遗漏的对象(在并发标记阶段结束后对象状态的更新导致)
- 并发清除(CMS-concurrent-sweep)
- 并发重设状态等待下次CMS的触发(CMS-concurrent-reset)。
通过GC日志和成功率下降的时间点进行比对发现并不是每一次老年代GC都会导致成功率的下降,但是从中发现了一个规律:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ot4muUwL-1647763935901)(https://segmentfault.com/img/bVzCJH?w=540&h=78)]
前两次GC CMS-Remark过程在4s左右造成了成功率的下降,但是第三次GC并没有对成功率造成明显的影响,CMS-Remark只有0.18s。Java HTTP 服务是通过Nginx进行反向代理的,nginx设置的超时时间是3s,所以如果GC卡顿在3s以内就不会对成功率造成太大的影响。
从GC日志中又发现一个信息:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9t0xJLOV-1647763935902)(https://segmentfault.com/img/bVzCJP?w=588&h=120)]
在文档和相关资料中没有找到蓝色部分的含义,猜测是remark处理的内存量,处理的越多就越慢。添加下面两个参数强制在remark阶段和FULL GC阶段之前先在进行一次年轻代的GC,这样需要进行处理的内存量就不会太多。
-XX:+ScavengeBeforeFullGC
-XX:+CMSScavengeBeforeRemark
调优以后效果很明显,下面是两台配置完全相同的服务器在同一时间段的成功率和响应时间监控图,第一个没有添加强制年轻代GC的参数。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uNqC1puc-1647763935903)(https://segmentfault.com/img/bVzCJR?w=1576&h=342)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rFlFNVAl-1647763935904)(https://segmentfault.com/img/bVzCJY?w=1574&h=338)]
结论
- 在CMS-remark阶段需要对堆中所有的内存对象进行处理,如果在这个阶段之前强制执行一次年轻代的GC会大量减少remark需要处理的内存数量,进而降低JVM卡顿对成功率的影响
- 对于Java HTTP服务,JVM的卡顿时间应该小于HTTP客户端的调用超时时间,否则JVM卡顿会对成功率造成影响
(七): Jvm 调优-工具篇
jdk自带的工具
jconsole
Jconsole(Java Monitoring and Management Console)是从java5开始,在JDK中自带的java监控和管理控制台,用于对JVM中内存,线程和类等的监控,是一个基于JMX(java management extensions)的GUI性能监测工具。jconsole使用jvm的扩展机制获取并展示虚拟机中运行的应用程序的性能和资源消耗等信息。
直接在jdk/bin目录下点击jconsole.exe即可启动,界面如下:
在弹出的框中可以选择本机的监控本机的java应用,也可以选择远程的java服务来监控,如果监控远程服务需要在tomcat启动脚本中添加如下代码:
-Dcom.sun.management.jmxremote.port=6969
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
连接进去之后,就可以看到jconsole概览图和主要的功能:概述、内存、线程、类、VM、MBeans
- 概述,以图表的方式显示出堆内存使用量,活动线程数,已加载的类,CUP占用率的折线图,可以非常清晰的观察在程序执行过程中的变动情况。
- 内存,主要展示了内存的使用情况,同时可以查看堆和非堆内存的变化值对比,也可以点击执行GC来处罚GC的执行
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y0vXe9jx-1647763935906)(http://favorites.ren/assets/images/2017/jvm/jconsole03.jpg)]
- 线程,主界面展示线程数的活动数和峰值,同时点击左下方线程可以查看线程的详细信息,比如线程的状态是什么,堆栈内容等,同时也可以点击“检测死锁”来检查线程之间是否有死锁的情况。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1XenslU3-1647763935907)(http://favorites.ren/assets/images/2017/jvm/jconsole04.jpg)]
- 类,主要展示已加载类的相关信息。
- VM 概要,展示JVM所有信息总览,包括基本信息、线程相关、堆相关、操作系统、VM参数等。
- Mbean,查看Mbean的属性,方法等。
VisualVM
简介
VisualVM 是一个工具,它提供了一个可视界面,用于查看 Java 虚拟机 (Java Virtual Machine, JVM) 上运行的基于 Java 技术的应用程序(Java 应用程序)的详细信息。VisualVM 对 Java Development Kit (JDK) 工具所检索的 JVM 软件相关数据进行组织,并通过一种使您可以快速查看有关多个 Java 应用程序的数据的方式提供该信息。您可以查看本地应用程序以及远程主机上运行的应用程序的相关数据。此外,还可以捕获有关 JVM 软件实例的数据,并将该数据保存到本地系统,以供后期查看或与其他用户共享。

VisualVM 是javajdk自带的最牛逼的调优工具了吧,也是我平时使用最多调优工具,几乎涉及了jvm调优的方方面面。同样是在jdk/bin目录下面双击jvisualvm.exe既可使用,启动起来后和jconsole 一样同样可以选择本地和远程,如果需要监控远程同样需要配置相关参数,主界面如下;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ORCXJ6Iz-1647763935909)(http://favorites.ren/assets/images/2017/jvm/jvisualvm01.jpg)]
VisualVM可以根据需要安装不同的插件,每个插件的关注点都不同,有的主要监控GC,有的主要监控内存,有的监控线程等。
如何安装:
1、从主菜单中选择“工具”>“插件”。
2、在“可用插件”标签中,选中该插件的“安装”复选框。单击“安装”。
3、逐步完成插件安装程序。
我这里以 Eclipse(pid 22296)为例,双击后直接展开,主界面展示了系统和jvm两大块内容,点击右下方jvm参数和系统属性可以参考详细的参数信息.
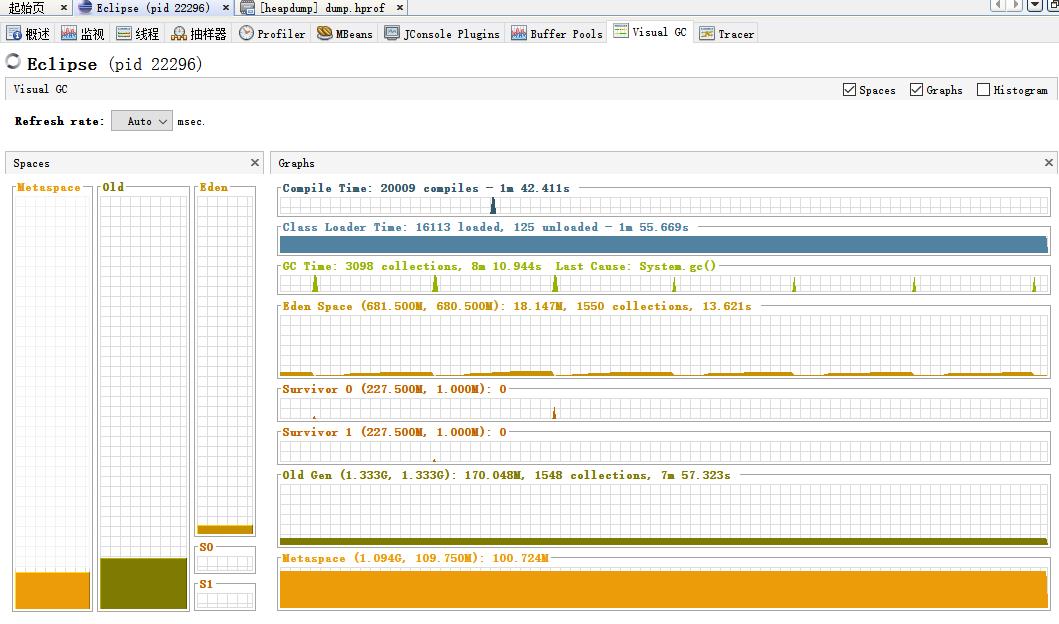
因为VisualVM的插件太多,我这里主要介绍三个我主要使用几个:监控、线程、Visual GC
监控的主页其实也就是,cpu、内存、类、线程的图表
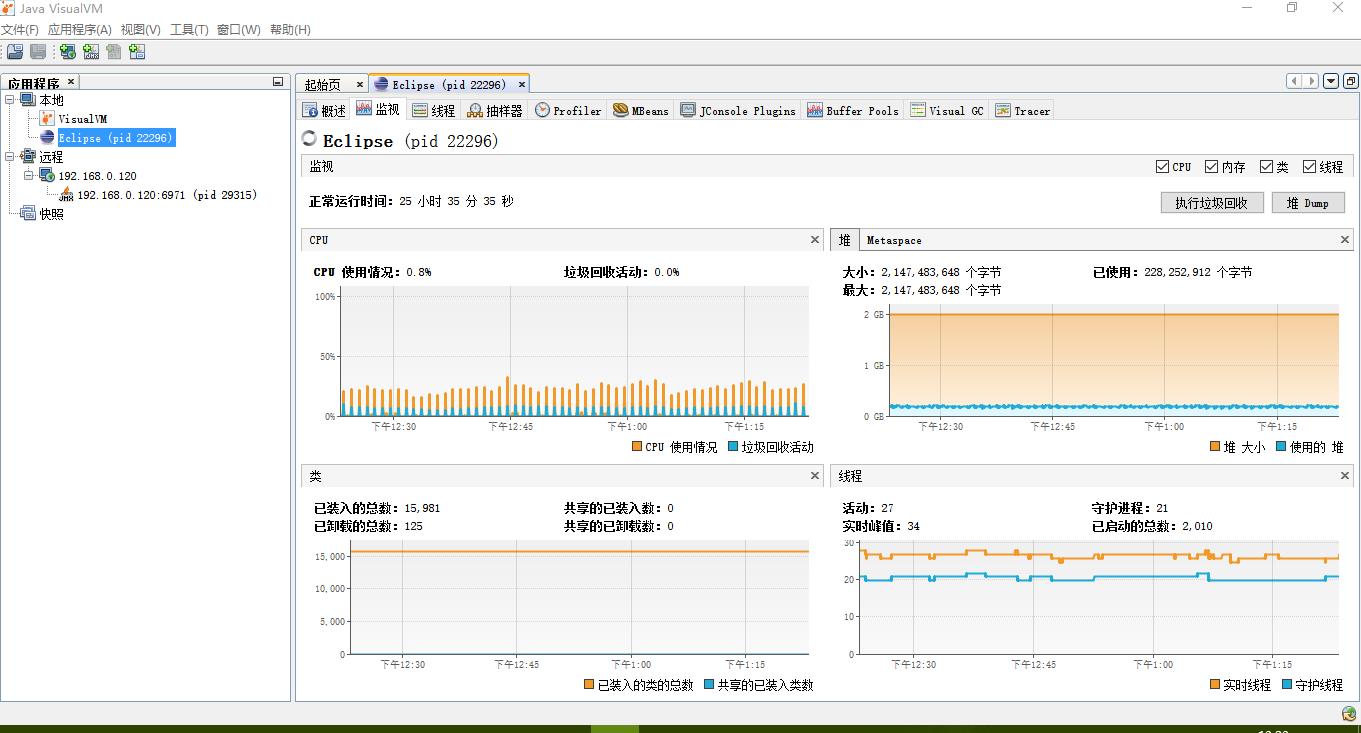
线程和jconsole功能没有太大的区别
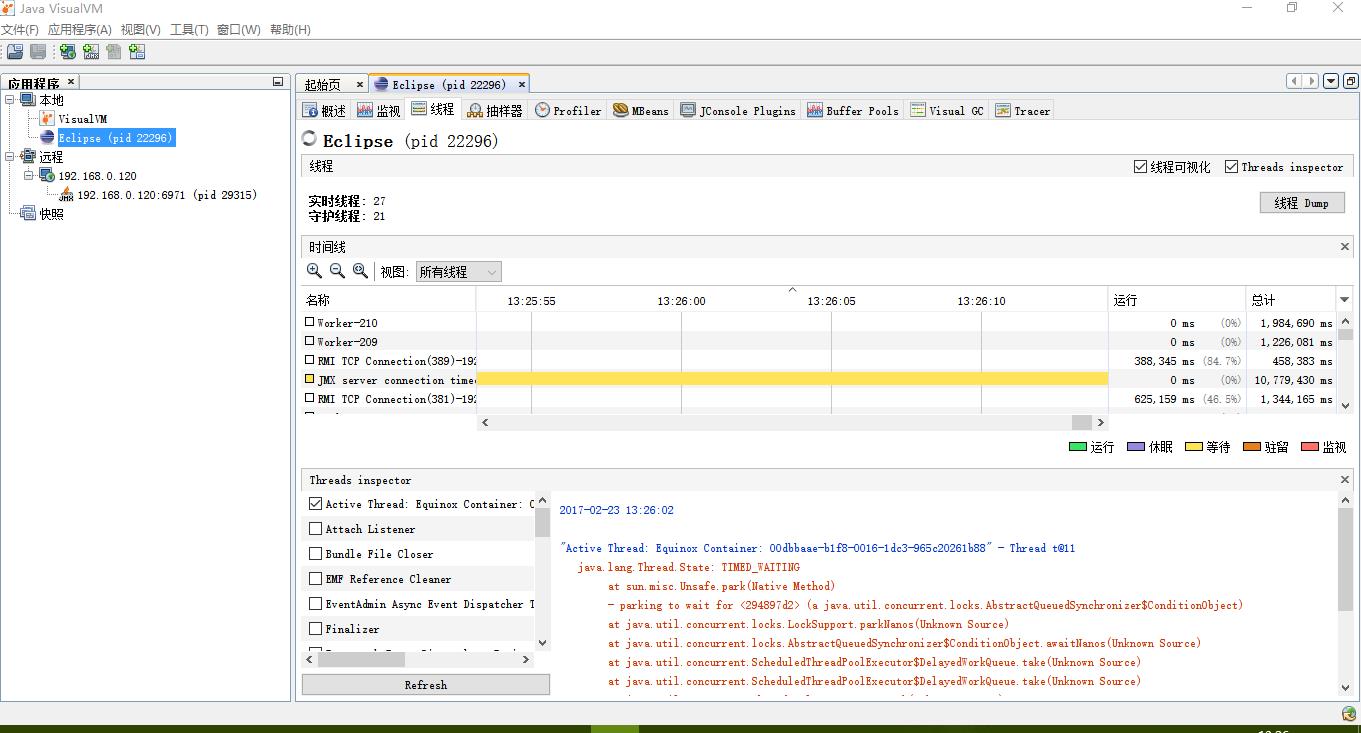
Visual GC 是常常使用的一个功能,可以明显的看到年轻代、老年代的内存变化,以及gc频率、gc的时间等。
以上的功能其实jconsole几乎也有,VisualVM更全面更直观一些,另外VisualVM非常多的其它功能,可以分析dump的内存快照,dump出来的线程快照并且进行分析等,还有其它很多的插件大家可以去探索
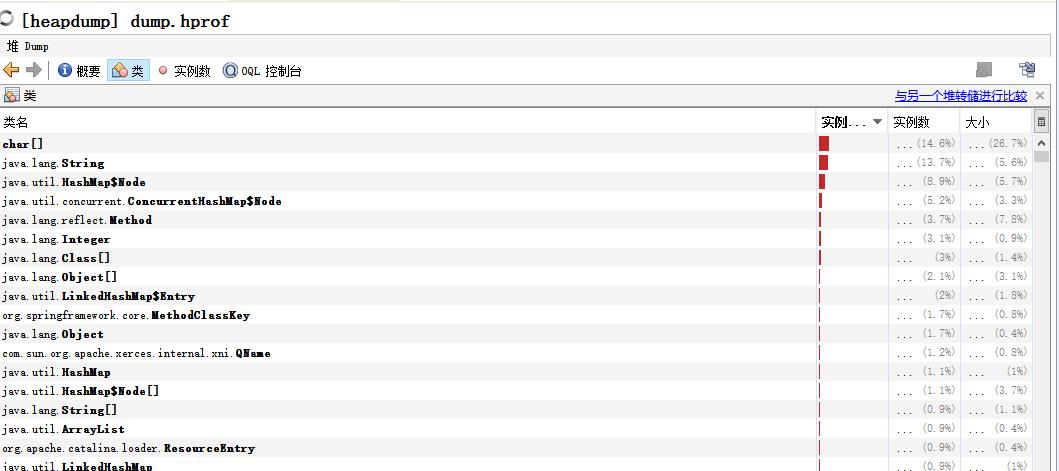
第三方调优工具
MAT
MAT是什么?
MAT(Memory Analyzer Tool),一个基于Eclipse的内存分析工具,是一个快速、功能丰富的Java heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗。使用内存分析工具从众多的对象中进行分析,快速的计算出在内存中对象的占用大小,看看是谁阻止了垃圾收集器的回收工作,并可以通过报表直观的查看到可能造成这种结果的对象。
通常内存泄露分析被认为是一件很有难度的工作,一般由团队中的资深人士进行。不过要介绍的 MAT(Eclipse Memory Analyzer)被认为是一个“傻瓜式“的堆转储文件分析工具,你只需要轻轻点击一下鼠标就可以生成一个专业的分析报告。和其他内存泄露分析工具相比,MAT 的使用非常容易,基本可以实现一键到位,即使是新手也能够很快上手使用。
MAT以eclipse 插件的形式来安装,具体的安装过程就不在描述了,可以利用visualvm或者是 jmap命令生产堆文件,导入eclipse mat中生成分析报告:
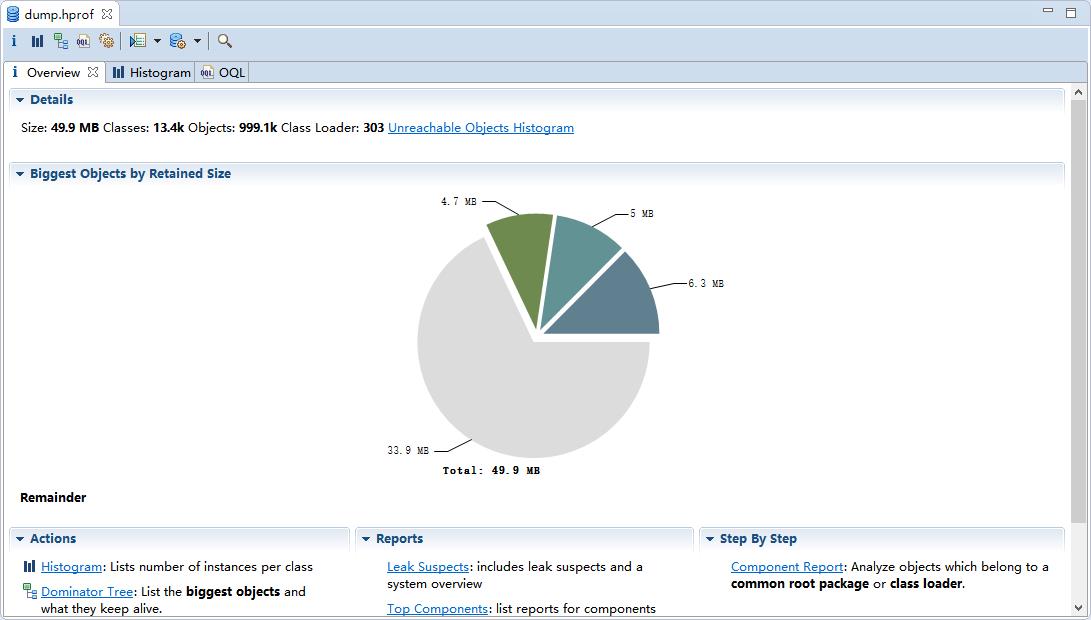
生产这会报表的同时也会在dump文件的同级目录下生成三份(dump_Top_Consumers.zip、dump_Leak_Suspects.zip、dump_Top_Components.zip)分析结果的html文件,方便发送给相关同事来查看。
需要关注的是下面的Actions、Reports、Step by Step区域:
- Histogram:列出内存中的对象,对象的个数以及大小,支持正则表达式查找,也可以计算出该类所有对象的retained size
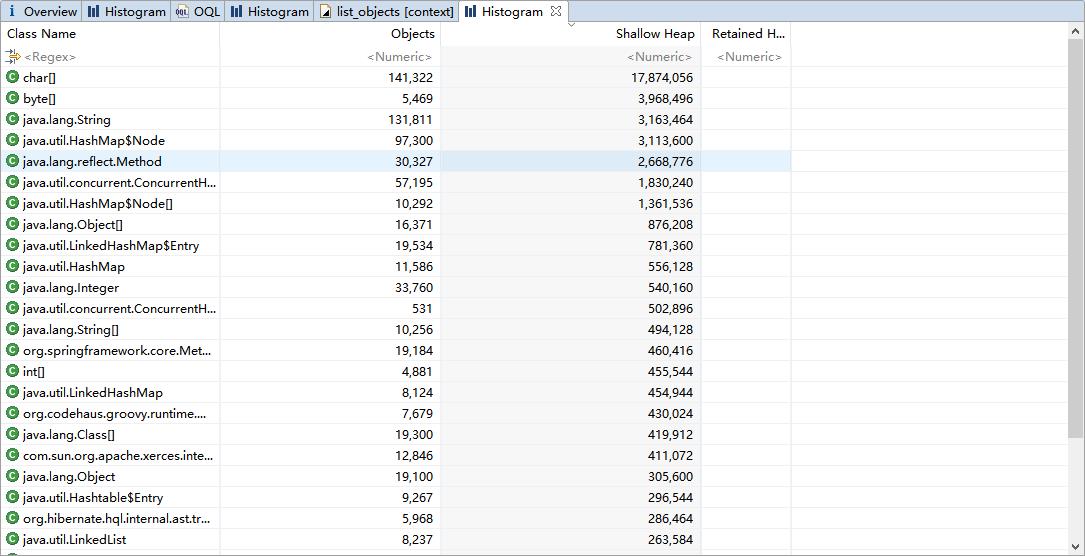
- Dominator Tree:列出最大的对象以及其依赖存活的Object (大小是以Retained Heap为标准排序的)
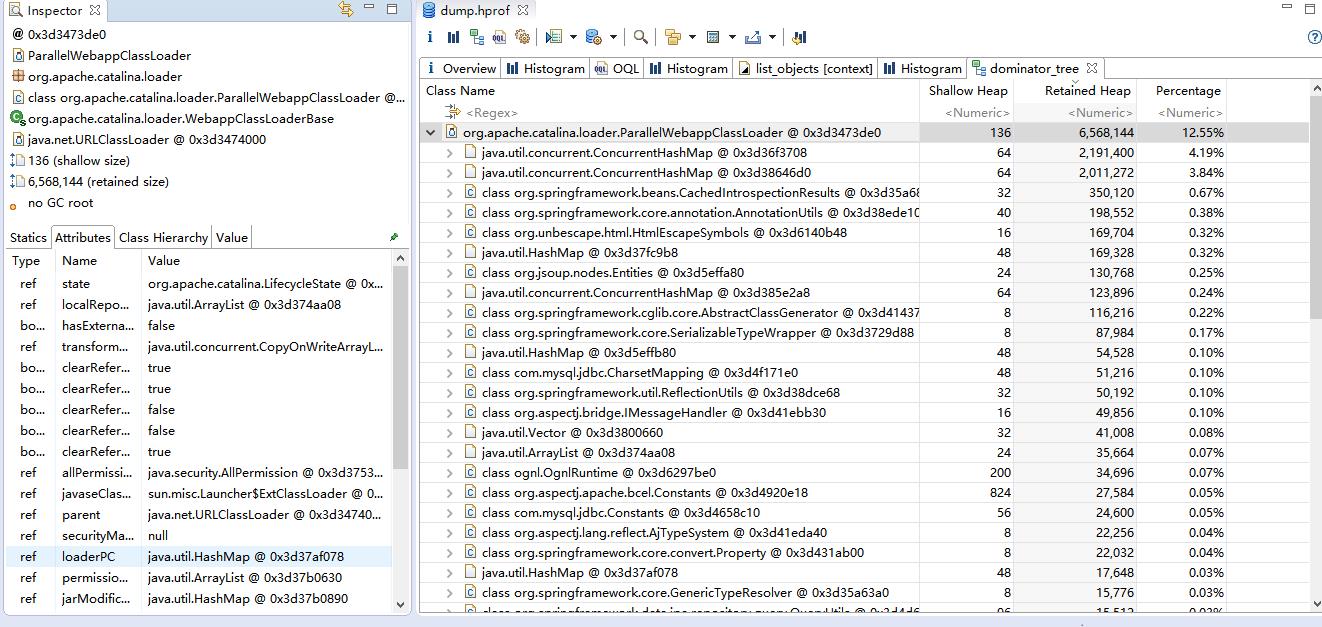
- Top Consumers : 通过图形列出最大的object
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nrI9SdS9-1647763935917)(http://favorites.ren/assets/images/2017/jvm/mat04.jpg)]
- duplicate classes :检测由多个类装载器加载的类
- Leak Suspects :内存泄漏分析
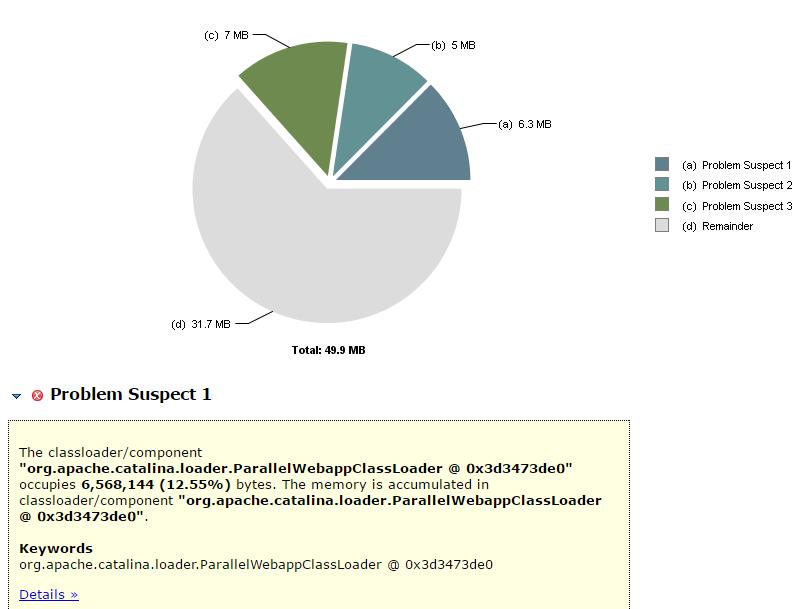
- Top Components: 列出大于总堆数的百分之1的报表。
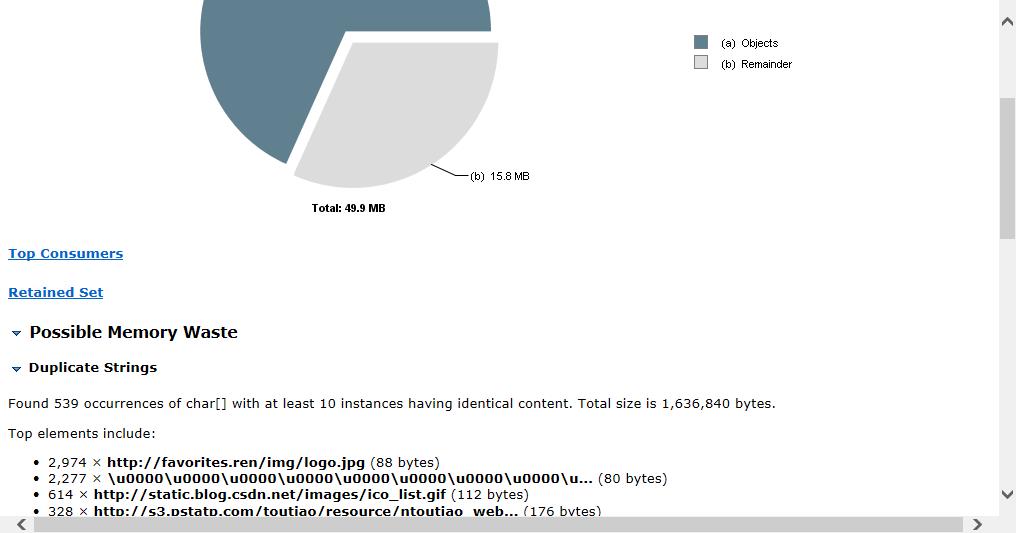
- Component Report:分析对象属于同一个包或者被同一个类加载器加载
以上只是一个初级的介绍,mat还有更强大的使用,比如对比堆内存,在生产环境中往往为了定位问题,每隔几分钟dump出一下内存快照,随后在对比不同时间的堆内存的变化来发现问题。
GChisto
GChisto是一款专业分析gc日志的工具,可以通过gc日志来分析:Minor GC、full gc的时间、频率等等,通过列表、报表、图表等不同的形式来反应gc的情况。虽然界面略显粗糙,但是功能还是不错的。
配置好本地的jdk环境之后,双击GChisto.jar,在弹出的输入框中点击 add 选择gc.log日志
- GC Pause Stats:可以查看GC 的次数、GC的时间、GC的开销、最大GC时间和最小GC时间等,以及相应的柱状图
- GC Pause Distribution:查看GC停顿的详细分布,x轴表示垃圾收集停顿时间,y轴表示是停顿次数。
- GC Timeline:显示整个时间线上的垃圾收集
不过这款工具已经不再维护,不能识别最新jdk的日志文件。
gcviewer
GCViewer也是一款分析小工具,用于可视化查看由Sun / Oracle, IBM, HP 和 BEA Java 虚拟机产生的垃圾收集器的日志,gcviewer个人感觉显示 的界面比较乱没有GChisto更专业一些。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xTF7YTYH-1647763935922)(http://favorites.ren/assets/images/2017/jvm/gv.jpg)]
GC Easy
这是一个web工具,在线使用非常方便.
地址: http://gceasy.io
进入官网,讲打包好的zip或者gz为后缀的压缩包上传,过一会就会拿到分析结果。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nhdydZfm-1647763935922)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023224538004.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Cqo37NkL-1647763935923)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211023224620558.png)]
推荐使用此工具进行gc分析.
Kafka+Zookeeper
简介
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。
基础架构及术语
先看一下Kafka基础架构示意图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IcEuMqTY-1647763935924)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211121171350875.png)]
Producer: Producer即生产者,消息的产生者,是消息的入口。
kafka cluster:
Broker: Broker是kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等……
Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。
Partition: Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹!
Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
Message:每一条发送的消息主体。
Consumer:消费者,即消息的消费方,是消息的出口。
Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
Zookeeper: kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
Kafka优势及应用场景
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。简单地说,Kafka就相比是一个邮箱,生产者是发送邮件的人,消费者是接收邮件的人,Kafka就是用来存东西的,只不过它提供了一些处理邮件的机制。
一、Kafka的优势如下:
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒;
可扩展性:kafka集群支持热扩展;
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
容错性:允许集群中节点故障(若副本数量为n,则允许n-1个节点故障);
高并发:支持数千个客户端同时读写。
二、Kafka适合以下应用场景:
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer;
消息系统:解耦生产者和消费者、缓存消息等;
用户活动跟踪:kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后消费者通过订阅这些topic来做实时的监控分析,亦可保存到数据库;
运营指标:kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
流式处理:比如spark streaming和storm。
Kafka安装及配置过程
安装
kafka可以通过官网下载:https://kafka.apache.org/downloads
kafka根据Scala版本不同,又分为多个版本,我不需要使用Scala,所以就下载官方推荐版本kafka_2.13-2.7.0.tgz。
[root@localhost kafka]# wget https://archive.apache.org/dist/kafka/2.7.0/kafka_2.13-2.7.0.tgz
使用tar -xzvf kafka_2.12-2.4.0.tgz 解压
kafka的安装需要依赖Zookeeper,下面先介绍Kafka与Zookeeper的关系,然后在介绍如何安装Zookeeper
Kafka与Zookeeper的关系
一个典型的Kafka集群中包含若干Produce,若干broker(一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UzFSGvEJ-1647763935925)(C:\Users\d\AppData\Roaming\Typora\typora-user-images\image-20211121174804104.png)]
1)Producer端直接连接broker.list列表,从列表中返回TopicMetadataResponse,该Metadata包含Topic下每个partition leader建立socket连接并发送消息.
2)Broker端使用zookeeper用来注册broker信息,以及监控partition leader存活性.
3)Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息。
zk作用:管理broker,consumer
创建Broker后,向zookeeper注册新的broker信息,实现在服务器正常运行下的水平拓展。具体的,通过注册watcher,获取partition的信息。
Topic的注册,zookeeper会维护topic与broker的关系,通/brokers/topics/topic.name节点来记录。
Producer向zookeeper中注册watcher,了解topic的partition的消息,以动态了解运行情况,实现负载均衡。Zookeepr不管理producer,只是能够提供当前broker的相关信息。
Consumer可以使用group形式消费kafka中的数据。所有的group将以轮询的方式消费broker中的数据,具体的按照启动的顺序。Zookeeper会给每个consumer group一个ID,即同一份数据可以被不同的用户ID多次消费。因此这就是单播与多播的实现。以单个消费者还是以组别的方式去消费数据,由用户自己去定义。Zookeeper管理consumer的offset跟踪当前消费的offset。
kafka使用ZooKeeper用于管理、协调代理。每个Kafka代理通过Zookeeper协调其他Kafka代理。
当Kafka系统中新增了代理或某个代理失效时,Zookeeper服务将通知生产者和消费者。生产者与消费者据此开始与其他代理协调工作。
Zookeeper在Kakfa中扮演的角色:Kafka将元数据信息保存在Zookeeper中,但是发送给Topic本身的数据是不会发到Zk上的
· kafka使用zookeeper来实现动态的集群扩展,不需要更改客户端(producer和consumer)的配置。broker会在zookeeper注册并保持相关的元数据(topic,partition信息等)更新。
· 而客户端会在zookeeper上注册相关的watcher。一旦zookeeper发生变化,客户端能及时感知并作出相应调整。这样就保证了添加或去除 broker时,各broker间仍能自动实现负载均衡。这里的客户端指的是Kafka的消息生产端(Producer)和消息消费端(Consumer)
· Broker端使用zookeeper来注册broker信息,以及监测partitionleader存活性.
· Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partitionleader建立socket连接,并获取消息.
· Zookeer和Producer没有建立关系,只和Brokers、Consumers建立关系以实现负载均衡,即同一个ConsumerGroup中的Consumers可以实现负载均衡(因为Producer是瞬态的,可以发送后关闭,无需直接等待)
Zookeeper配置
1:单独安装zookeeper
ZooKeeper的安装和配置过程 参考: https://www.cnblogs.com/zhaoshizi/p/12105143.html
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
wget https://downloads.apache.org/zookeeper/zookeeper-3.5.9/
zk单机部署:
单机模式:ZooKeeper也支持单机部署,单机模式可以看做一种特殊的集群模式,整体配置流程与集群部署一致,不同的地方在于,zoo.cfg配置文件中,只需要配置一个server地址,而且不需要在dataDir目录下配置myid文件
(1) 配置cfg文件
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/zookeeper/data
dataLogDir=/usr/local/zookeeper/zookeeper/log
clientPort=2181
(2) 启动服务器
cd /usr/local/zookeeper/zookeeper/bin
[root@localhost bin]# ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
(3) 验证服务器
#使用zkServer.sh status 命令验证
[root@localhost bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false. ##############待解决 启动失败
Error contacting service. It is probably not running.
(4) 关闭服务器
bin/zkServer.sh stop
2.直接使用其自带的Zookeeper建立集群
由于这里主要介绍Kafka,所以Zookeeper没有建立集群,只使用了单节点。
kafka自带的Zookeeper程序脚本与配置文件名与原生Zookeeper稍有不同。
kafka自带的Zookeeper程序使用bin/zookeeper-server-start.sh,以及bin/zookeeper-server-stop.sh来启动和停止Zookeeper。
而Zookeeper的配制文件是config/zookeeper.properties,可以修改其中的参数
(1)启动Zookeeper
cd /usr/local/kafka/kafka/bin
./zookeeper-server-start.sh -daemon ../config/zookeeper.properties
加-daemon参数,可以在后台启动Zookeeper,输出的信息在保存在执行目录的logs/zookeeper.out/ hs_err_pid73185.log文件中。
对于小内存的服务器,启动时有可能会出现如下错误
os::commit_memory(0x00000000e0000000, 536870912, 0) failed; error=‘Not enough space’ (errno=12)
可以通过修改bin/zookeeper-server-start.sh中的参数,来减少内存的使用,将下图中的-Xmx512M -Xms512M改小。
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx256M -Xms256M"
查看 zk启动日志:
cd /usr/local/kafka/kafka/logs
[root@localhost logs]# tail -f zookeeper.out
[2021-11-21 19:21:26,409] INFO Configuring NIO connection handler with 10s sessionless connection timeout, 1 selector thread(s), 2 worker threads, and 64 kB direct buffers. (org.apache.zookeeper.server.NIOServerCnxnFactory)
[2021-11-21 19:21:26,428] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
[2021-11-21 19:21:26,469] INFO zookeeper.snapshotSizeFactor = 0.33 (org.apache.zookeeper.server.ZKDatabase)
[2021-11-21 19:21:26,478] INFO Reading snapshot /tmp/zookeeper/version-2/snapshot.0 (org.apache.zookeeper.server.persistence.FileSnap)
[2021-11-21 19:21:26,491] INFO Snapshotting: 0x0 to /tmp/zookeeper/version-2/snapshot.0
(2)关闭Zookeeper
./zookeeper-server-stop.sh -daemon ../config/zookeeper.properties
Kafka配置
kafka的配置文件在config/server.properties文件中,主要修改参数如下
#broker.id是kafka broker的编号,集群里每个broker的id需不同。我是从0开始
broker.id=0
#listeners是监听地址,需要提供外网服务的话,要设置本地的IP地址
listeners=PLAINTEXT://:9092
#log.dirs是日志目录,需要设置
log.dirs=/tmp/kafka-logs
#设置Zookeeper集群地址,我是在同一个服务器上搭建了kafka和Zookeeper,所以填的本地地址
zookeeper.connect=localhost:2181
#num.partitions 为新建Topic的默认Partition数量,partition数量提升,一定程度上可以提升并发性,数值应该小于等于broker的数量
num.partitions=1
因为要创建kafka集群,所以kafka的所有文件都复制两份,配置文件做相应的修改,尤其是brokerid、IP地址和日志目录。分别创建软链接kafka1和kafka2
启动kafka
cd /usr/local/kafka/kafka/bin
./kafka-server-start.sh -daemon ../config/server.properties # -daemon表示后台启动
[root@localhost bin]# ./kafka-server-start.sh ../config/server.properties
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c0000000, 1073741824, 0) failed; error='Cannot allocate memory' (errno=12)
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map 1073741824 bytes for committing reserved memory.
# An error report file with more information is saved as:
# /usr/local/kafka/kafka/bin/hs_err_pid76343.log
#修改bin目录下的kafka-server-start.sh文件,将初始堆的大小(-Xms)设置小一些
export KAFKA_HEAP_OPTS="-Xmx128G -Xms128M" # -Xmx256M -Xms256M
#修改bin目录下的 zookeeper-server-start.sh,将初始堆的大小(-Xms)设置小一些
export KAFKA_HEAP_OPTS="-Xmx128M -Xms128M" #-Xmx256M -Xms256M
[2021-11-21 19:40:50,182] INFO Loaded 0 logs in 31ms. (kafka.log.LogManager)
[2021-11-21 19:40:56,657] INFO Awaiting socket connections on 0.0.0.0:9092. (kafka.network.Acceptor)
[2021-11-21 19:40:56,781] INFO [SocketServer brokerId=0] Created data-plane acceptor and processors for endpoint : ListenerName(PLAINTEXT) (kafka.network.SocketServer)
[2021-11-21 19:40:56,879] INFO [ExpirationReaper-0-Produce]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[2021-11-21 19:40:56,900] INFO [ExpirationReaper-0-DeleteRecords]: Starting
[2021-11-21 19:40:56,981] INFO [LogDirFailureHandler]: Starting (kafka.server.ReplicaManager$LogDirFailureHandler)
[2021-11-21 19:40:57,067] INFO Creating /brokers/ids/0 (is it secure? false) (kafka.zk.KafkaZkClient)
[2021-11-21 19:40:57,203] INFO Stat of the created znode at /brokers/ids/0 is: 24,24,1637494857182,1637494857182,1,0,0,72061693169369088,202,0,24
(kafka.zk.KafkaZkClient)
停止kafka
./kafka-server-stop.sh ../config/server.properties
测试
前提:kafka和Zookeeper已启动完成
#1. 创建topic
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 2 --topic test
#2. 查看主题
./kafka-topics.sh --list --zookeeper localhost:2181
#3. 发送消息
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
#4. 接收消息
./kafka-console-consumer.sh --bootstrap-server localhost:9093 --topic test --from-beginning
#5. 查看特定主题的详细信息
./kafka-topics.sh --zookeeper localhost:2181 --describe --topic test
#6. 删除主题
./kafka-topics.sh --zookeeper localhost:2181 --delete --topic test
Rabbitmq
安装运行环境
RabbitMQ使用erlang语言开发(想要了解的可以自行google),所以我们首先安装erlang
#1.安装erlang
rpm -Uvh http://www.rabbitmq.com/releases/erlang/erlang-18.1-1.el7.centos.x86_64.rpm
#2.安装RabbitMQ-Server
rpm -Uvh http://www.rabbitmq.com/releases/rabbitmq-server/v3.5.6/rabbitmq-server-3.5.6-1.noarch.rpm
MongoDB
Memcached
HTTP
WebSocket
okeeper.properties
## Kafka配置
kafka的配置文件在config/server.properties文件中,主要修改参数如下
```shell
#broker.id是kafka broker的编号,集群里每个broker的id需不同。我是从0开始
broker.id=0
#listeners是监听地址,需要提供外网服务的话,要设置本地的IP地址
listeners=PLAINTEXT://:9092
#log.dirs是日志目录,需要设置
log.dirs=/tmp/kafka-logs
#设置Zookeeper集群地址,我是在同一个服务器上搭建了kafka和Zookeeper,所以填的本地地址
zookeeper.connect=localhost:2181
#num.partitions 为新建Topic的默认Partition数量,partition数量提升,一定程度上可以提升并发性,数值应该小于等于broker的数量
num.partitions=1
因为要创建kafka集群,所以kafka的所有文件都复制两份,配置文件做相应的修改,尤其是brokerid、IP地址和日志目录。分别创建软链接kafka1和kafka2
启动kafka
cd /usr/local/kafka/kafka/bin
./kafka-server-start.sh -daemon ../config/server.properties # -daemon表示后台启动
[root@localhost bin]# ./kafka-server-start.sh ../config/server.properties
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c0000000, 1073741824, 0) failed; error='Cannot allocate memory' (errno=12)
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map 1073741824 bytes for committing reserved memory.
# An error report file with more information is saved as:
# /usr/local/kafka/kafka/bin/hs_err_pid76343.log
#修改bin目录下的kafka-server-start.sh文件,将初始堆的大小(-Xms)设置小一些
export KAFKA_HEAP_OPTS="-Xmx128G -Xms128M" # -Xmx256M -Xms256M
#修改bin目录下的 zookeeper-server-start.sh,将初始堆的大小(-Xms)设置小一些
export KAFKA_HEAP_OPTS="-Xmx128M -Xms128M" #-Xmx256M -Xms256M
[2021-11-21 19:40:50,182] INFO Loaded 0 logs in 31ms. (kafka.log.LogManager)
[2021-11-21 19:40:56,657] INFO Awaiting socket connections on 0.0.0.0:9092. (kafka.network.Acceptor)
[2021-11-21 19:40:56,781] INFO [SocketServer brokerId=0] Created data-plane acceptor and processors for endpoint : ListenerName(PLAINTEXT) (kafka.network.SocketServer)
[2021-11-21 19:40:56,879] INFO [ExpirationReaper-0-Produce]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[2021-11-21 19:40:56,900] INFO [ExpirationReaper-0-DeleteRecords]: Starting
[2021-11-21 19:40:56,981] INFO [LogDirFailureHandler]: Starting (kafka.server.ReplicaManager$LogDirFailureHandler)
[2021-11-21 19:40:57,067] INFO Creating /brokers/ids/0 (is it secure? false) (kafka.zk.KafkaZkClient)
[2021-11-21 19:40:57,203] INFO Stat of the created znode at /brokers/ids/0 is: 24,24,1637494857182,1637494857182,1,0,0,72061693169369088,202,0,24
(kafka.zk.KafkaZkClient)
停止kafka
./kafka-server-stop.sh ../config/server.properties
测试
前提:kafka和Zookeeper已启动完成
#1. 创建topic
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 2 --topic test
#2. 查看主题
./kafka-topics.sh --list --zookeeper localhost:2181
#3. 发送消息
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
#4. 接收消息
./kafka-console-consumer.sh --bootstrap-server localhost:9093 --topic test --from-beginning
#5. 查看特定主题的详细信息
./kafka-topics.sh --zookeeper localhost:2181 --describe --topic test
#6. 删除主题
./kafka-topics.sh --zookeeper localhost:2181 --delete --topic test
Rabbitmq
安装运行环境
RabbitMQ使用erlang语言开发(想要了解的可以自行google),所以我们首先安装erlang
#1.安装erlang
rpm -Uvh http://www.rabbitmq.com/releases/erlang/erlang-18.1-1.el7.centos.x86_64.rpm
#2.安装RabbitMQ-Server
rpm -Uvh http://www.rabbitmq.com/releases/rabbitmq-server/v3.5.6/rabbitmq-server-3.5.6-1.noarch.rpm