为什么要搭建主从复制集群
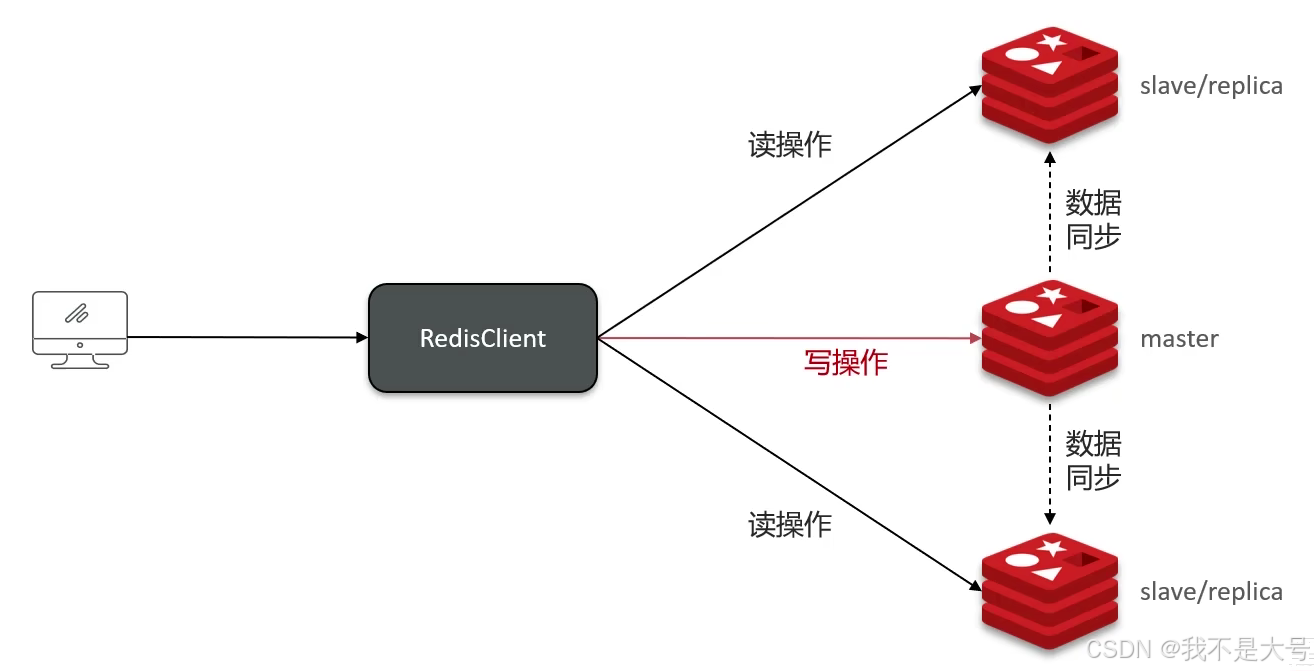
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
其中是一个结点是主节点,其他的都是从结点,主节点负责写操作,从节点负责写操作,所以在主节点写操作结束后,需要向从节点同步数据,这样就实现了读写分离
主从数据同步流程
主从全量同步
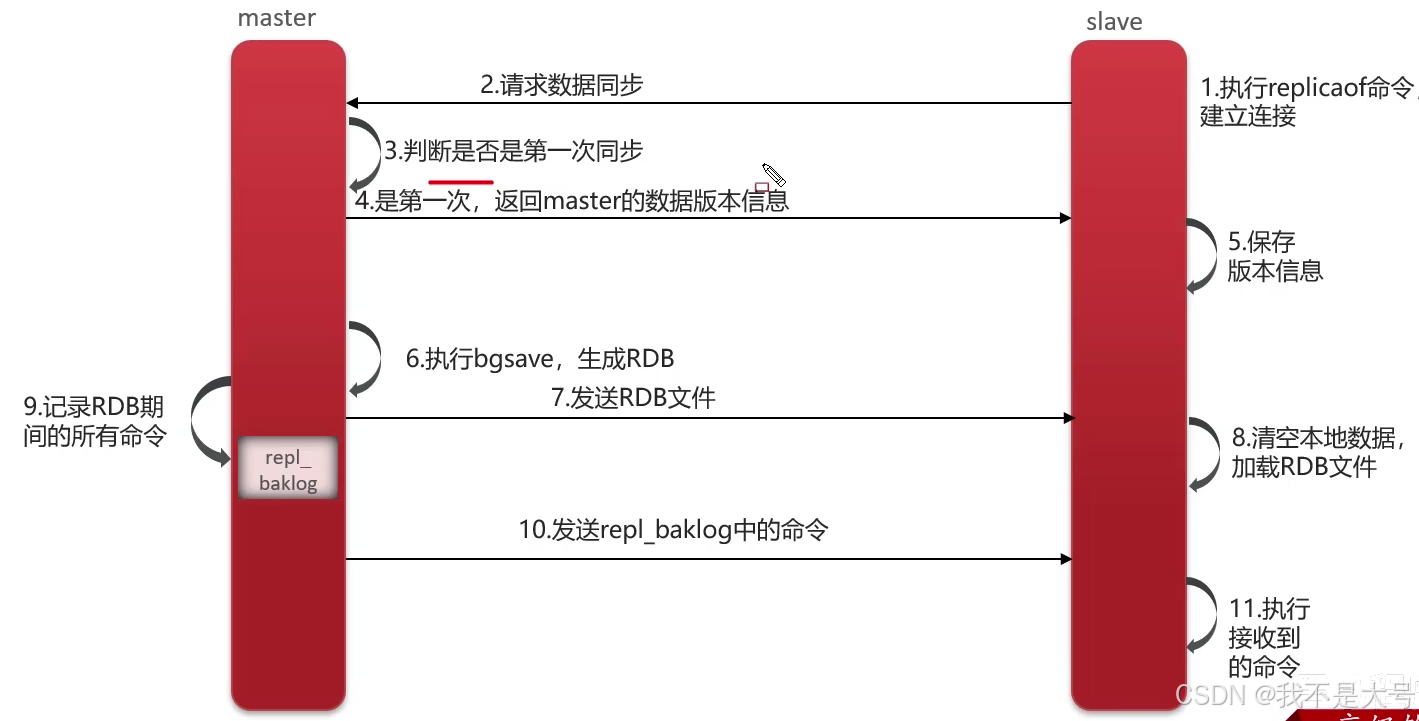
首先从节点会执行replicaof命令跟主节点建立连接,请求数据同步,主节点接受请求后,会先判断当前结点是否是第一次同步,如果是第一次同步,就会把主节点的数据版本信息发送给从结点,之后从节点就会把数据版本信息保存在本地,同时,主节点会执行bgsave命令,生成RDB快照文件,文件生成后,就会将他发送给从节点,从节点接受到数据后就会清空本地的数据,然后执行接受到的RDB文件

但是这样还不能确定是否数据同步,假如在主节点生成RDB文件的时候,又去接受了客户端的其他请求,那么刚刚发送过去的数据就不是最新的数据,这个问题redis官方出来了一种解决方案,主节点在记录RDB文件的过程中,他会把新的请求记录到一个日志文件reol_ baklog中,然后再把日志文件发送给从节点,从结点执行完这个日志文件后,就完成了主从同步
主节点如何判断从节点是第一次同步?
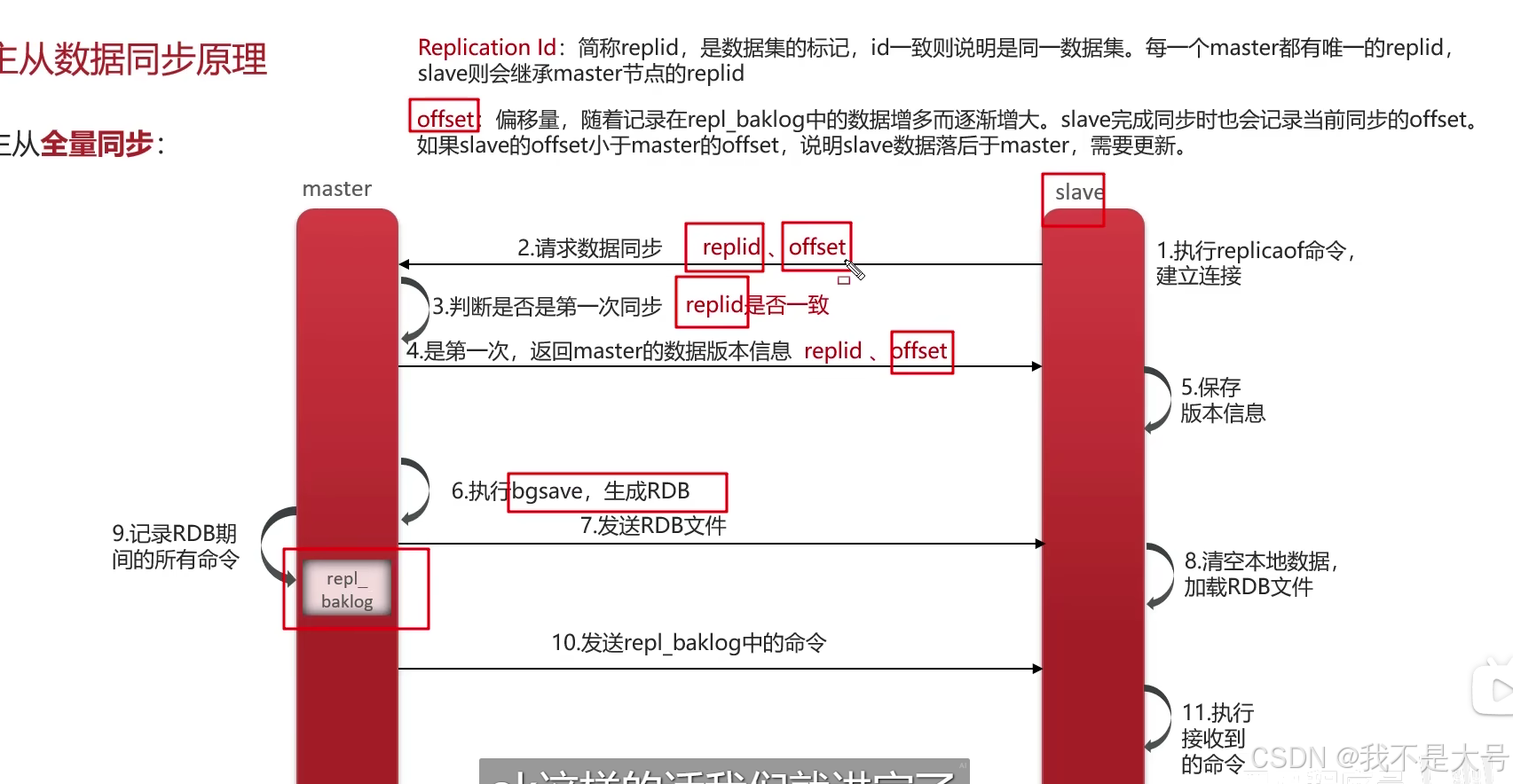
Replication ld:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset.如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
如果主节点跟从节点是同一个replid,则说明他们是同一个数据集 ,判断是否是第一次同步,其实就是判断replid是否一致,如果一致则不是第一次同步,不一致则是第一次同步,如果不是第一次同步,则在返回的数据版本信息里面就有replid,从节点就会继承这个id,下一次判断就不是第一次同步了

第二次同步数据是怎么样的
当从节点第二次去获取数据的时候,主节点就不会再生成RDB文件,会通过repl_baklog来同步数据,在版本信息同步的时候,从节点也会携带offset值,假如现在从节点的offset的值为50,主节点的offset为80,所以50~80这部分数据没有同步,所以主节点再次与从节点同步时就会把这部分数据进行同步
增量同步(从节点重启或数据后期变化)
从结点重启之后,会先给主节点发起同步数据的请求,会携带两个值分别是replid和offset,主节点去判断replid是否一致,因为不是第一次同步,所以replid是一致的,然后主节点会从repl_baklog中获取offset之后的数据,然后发送给从节点去同步数据
