Qt实现爬取网页图片
实现原理
1.获取网页HTML
2.解析HTML得到图片链接
3.下载图片
展示效果图,如下所示:
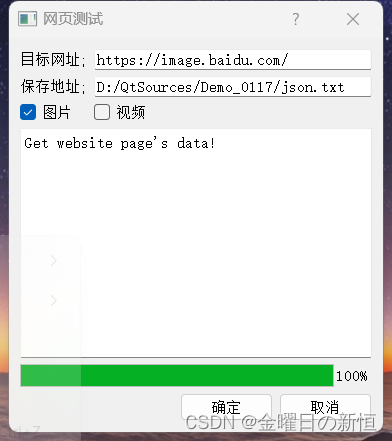

一、获取到网页的HTML。
这里需要用到Qt网络编程常用的三个类:QNetworkAccessManager、QNetworkRequest和QNetworkReply。
使用上面的类需要引入network模块
QT += network
向网页发送get请求
QNetworkRequest mTestRequest(QUrl(ui->UrlLineEdit->text()));
//进行网络请求,会返回一个回复,服务器回复结束,QnetworkReply就会释放finished信号
QNetworkReply *networkReply = mManager->get(mTestRequest);
//回复结束的时候QnetworkReply会释放readyRead信号
connect(networkReply,SIGNAL(readyRead()),this,SLOT(readFinishedSlot()),Qt::UniqueConnection);
返回的网页数据会在readFinshedSlot中处理
//sender()函数作用就是得到一个指针,这个指针是:当前槽函数所对应的信号是哪个对象发送的
QNetworkReply *reply = (QNetworkReply *) sender();
QByteArray data1 = reply->readAll(); //读取传回来的HTML数据
QString strData = QString(data1);
if(strData != "")
{
ui->textEdit->setText("Get website page's data!");
}
reply->deleteLater(); //记得释放内存
getPictureLinkFromHTML(strData); //解析HTML,将图片链接存储在mDownloadList中
downloadResource(mDownloadList); //对这些链接进行下载
strData中存放的就是get请求返回的HTML内容
二、解析HTML,获取到图片链接
getPictureLinkFromHTML这个接口通过正则表达式获取到匹配的字符串,并将其处理成可跳转的链接
qDebug()<<"-----------picture------------";
QStringList qsList;
qsList.clear();
QRegularExpression re("<img src=(?<path>\\S+?) (?<junk2>.*?)>", QRegularExpression::CaseInsensitiveOption);
//QRegularExpression globalMatch全部匹配,获取到所有符合这个规则的字符串集合
QRegularExpressionMatchIterator itor = re.globalMatch(qsContent);
while(itor.hasNext())
{
QRegularExpressionMatch match = itor.next();
QString junk2 = match.captured("junk2");
QString path = match.captured("path");
qsList<<path;
}
//处理downloadList数据
foreach (QString var, qsList) {
QString str = var.replace("\"","");
str = str.replace(">","");
str = str.replace("'","");
qDebug() << "_strData: " << str;
mDownloadList << str;
}
QRegularExpression 可以使用正则表达式进行模式匹配
DownloadList中存放的是匹配成功的链接
三、下载图片
先简单说一下,下载图片的原理:仍然是通过get请求获取到链接的HTML数据,但这次我们并不是要对数据做解析,而是将这些数据写入文件中,并将文件重命名为.png格式,这样就实现了通过url下载图片。
OK,上代码
foreach (QString var, _list) {
DownloadTipMessage _tips;
iImageName++;
//可以在resourcename这个属性中加入相对路径,从而将图片下载到指定文件夹
_tips.resourcename = QString::number(iImageName);
_tips.resourcename += ".png";
_tips.urlpath = var;
//初始化QFile对象
_tips.file = new QFile(_tips.resourcename);
//链接地址发送get请求
QUrl url(_tips.urlpath);
QNetworkRequest request(url);
QNetworkReply *currentDownload;
currentDownload = mManager->get(request);
connect(currentDownload, SIGNAL(finished()),SLOT(downloadFinshined()));
connect(currentDownload, SIGNAL(readyRead()),SLOT(downloadReadyRead()));
connect(currentDownload,SIGNAL(downloadProgress(qint64,qint64)),this,SLOT(updateProgress(qint64,qint64)));
mNetworkmap.insert(currentDownload,_tips);
}
downloadReadyRead中主要实现将返回的HTML数据写入图片文件中
QNetworkReply *arg= dynamic_cast<QNetworkReply*>(sender());
if(!mNetworkmap[arg].file->open(QIODevice::WriteOnly)){
delete mNetworkmap[arg].file;
mNetworkmap[arg].file=NULL;
return;
}
mNetworkmap[arg].file->write(arg->readAll());
downloadFinshed中实现文件的写入关闭以及QNetworkReply对象的释放
QNetworkReply *arg= dynamic_cast<QNetworkReply*>(sender());
mNetworkmap[arg].file->close();
arg->deleteLater();
arg = 0;
结尾
到这里为止,爬取网页图片到本地的流程已经结束了。
其中第二步,对于html的处理并不是很全面,但是不影响完整的实现流程。(后续,我会再更新对正则表达式的处理)
下载链接