深度学习之对象检测
前言 (Foreword)
As the second article in the “Papers You Should Read” series, we are going to walk through both the history and some recent developments in a more difficult area of computer vision research: object detection. Before the deep learning era, hand-crafted features like HOG and feature pyramids are used pervasively to capture localization signals in an image. However, those methods usually can’t extend to generic object detection well, so most of the applications are limited to face or pedestrian detections. With the power of deep learning, we can train a network to learn which features to capture, as well as what coordinates to predict for an object. And this eventually led to a boom of applications based on visual perception, such as the commercial face recognition system and autonomous vehicle. In this article, I picked 12 must-read papers for newcomers who want to study object detection. Although the most challenging part of building an object detection system hides in the implementation details, reading these papers can still give you a good high-level understanding of where the ideas come from, and how would object detection evolve in the future.
作为“您应该阅读的论文”系列的第二篇文章,我们将探讨计算机视觉研究这一更加困难的领域的历史和最近的一些发展:对象检测。 在深度学习时代之前,像HOG和金字塔特征之类的手工特征已广泛用于捕获图像中的定位信号。 但是,这些方法通常不能很好地扩展到通用对象检测,因此大多数应用程序仅限于人脸或行人检测。 借助深度学习的力量,我们可以训练网络来学习要捕获的特征以及预测对象的坐标。 最终,这导致了基于视觉感知的应用程序的繁荣,例如商用人脸识别系统和自动驾驶汽车。 在本文中,我为想要研究对象检测的新手挑选了12篇必读的论文。 尽管构建对象检测系统最具挑战性的部分隐藏在实现细节中,但阅读这些文章仍可以使您对这些思想的来龙去脉以及对象检测在未来的发展中有一个很好的高级了解。
As a prerequisite for reading this article, you need to know the basic idea of the convolution neural network and the common optimization method such as gradient descent with back-propagation. It’s also highly recommended to read my previous article “10 Papers You Should Read to Understand Image Classification in the Deep Learning Era” first because many cool ideas of object detection originate from a more fundamental image classification research.
作为阅读本文的先决条件,您需要了解卷积神经网络的基本概念以及常见的优化方法,例如带有反向传播的梯度下降。 强烈建议先阅读我以前的文章“ 在深度学习时代应该读懂的10篇论文,以了解图像分类 ”,因为许多很酷的对象检测思想都来自于更基础的图像分类研究。
2013年 (2013: OverFeat)
OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
OverFeat:使用卷积网络的集成识别,定位和检测

Inspired by the early success of AlexNet in the 2012 ImageNet competition, where CNN-based feature extraction defeated all hand-crafted feature extractors, OverFeat quickly introduced CNN back into the object detection area as well. The idea is very straight forward: if we can classify one image using CNN, what about greedily scrolling through the whole image with different sizes of windows, and try to regress and classify them one-by-one using a CNN? This leverages the power of CNN for feature extraction and classification, and also bypassed the hard region proposal problem by pre-defined sliding windows. Also, since a nearby convolution kernel can share part of the computation result, it is not necessary to compute convolutions for the overlapping area, hence reducing cost a lot. OverFeat is a pioneer in the one-stage object detector. It tried to combine feature extraction, location regression, and region classification in the same CNN. Unfortunately, such a one-stage approach also suffers from relatively poorer accuracy due to less prior knowledge used. Thus, OverFeat failed to lead a hype for one-stage detector research, until a much more elegant solution coming out 2 years later.
受AlexNet在2012年ImageNet竞赛中早期成功的启发,基于CNN的特征提取击败了所有手工制作的特征提取器,OverFeat很快也将CNN引入了对象检测领域。 这个想法很简单:如果我们可以使用CNN对一个图像进行分类,那么如何在不同大小的窗口中贪婪地滚动浏览整个图像,然后尝试使用CNN逐一进行回归和分类呢? 这利用了CNN进行特征提取和分类的功能,还通过预定义的滑动窗口绕过了硬区域建议问题。 另外,由于附近的卷积核可以共享一部分计算结果,因此不必为重叠区域计算卷积,因此大大降低了成本。 OverFeat是一级目标检测器的先驱。 它试图在同一CNN中结合特征提取,位置回归和区域分类。 不幸的是,由于使用的先验知识较少,这种单阶段方法还遭受相对较差的准确性。 因此,OverFeat未能引起对一级探测器研究的大肆宣传,直到两年后出现了更为优雅的解决方案。
2013年:R-CNN (2013: R-CNN)
Region-based Convolutional Networks for Accurate Object Detection and Segmentation
基于区域的卷积网络,用于精确的目标检测和分割
Also proposed in 2013, R-CNN is a bit late compared with OverFeat. However, this region-based approach eventually led to a big wave of object detection research with its two-stage framework, i.e, region proposal stage, and region classification and refinement stage.
同样在2013年提出的R-CNN与OverFeat相比有点晚。 然而,这种基于区域的方法最终以其两个阶段的框架,即区域提议阶段,区域分类和细化阶段,引起了对象检测研究的热潮。
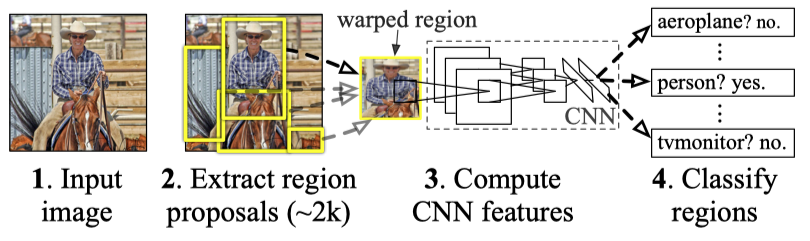
In the above diagram, R-CNN first extracts potential regions of interest from an input image by using a technique called selective search. Selective search doesn’t really try to understand the foreground object, instead, it groups similar pixels by relying on a heuristic: similar pixels usually belong to the same object. Therefore, the results of selective search have a very high probability to contain something meaningful. Next, R-CNN warps these region proposals into fixed-size images with some paddings, and feed these images into the second stage of the network for more fine-grained recognition. Unlike those old methods using selective search, R-CNN replaced HOG with a CNN to extract features from all region proposals in its second stage. One caveat of this approach is that many region proposals are not really a full object, so R-CNN needs to not only learn to classify the right classes, but also learn to reject the negative ones. To solve this problem, R-CNN treated all region proposals with a ≥ 0.5 IoU overlap with a ground-truth box as positive, and the rest as negatives.
在上图中,R-CNN首先使用称为选择性搜索的技术从输入图像中提取潜在的感兴趣区域。 选择性搜索并没有真正尝试理解前景对象,而是依靠启发式方法将相似像素进行分组:相似像素通常属于同一对象。 因此,选择性搜索的结果很有可能包含有意义的内容。 接下来,R-CNN将这些区域建议变形为带有一些填充的固定大小的图像,并将这些图像馈入网络的第二阶段以进行更细粒度的识别。 与那些使用选择性搜索的旧方法不同,R-CNN在第二阶段将HOG替换为CNN,以从所有区域提案中提取特征。 这种方法的一个警告是,许多区域提议并不是真正的完整对象,因此R-CNN不仅需要学习对正确的类别进行分类,而且还需要拒绝否定的类别。 为解决此问题,R-CNN将所有≥0.5 IoU重叠且与地面真实框重叠的区域提案视为正,其余部分视为负面。
Region proposal from selective search highly depends on the similarity assumption, so it can only provide a rough estimate of location. To further improve localization accuracy, R-CNN borrowed an idea from “Deep Neural Networks for Object Detection” (aka DetectorNet), and introduced an additional bounding box regression to predict the center coordinates, width and height of a box. This regressor is widely used in the future object detectors.
选择性搜索的区域提议在很大程度上取决于相似性假设,因此它只能提供位置的粗略估计。 为了进一步提高定位精度,R-CNN借鉴了“用于物体检测的深度神经网络”(又名DetectorNet)的思想,并引入了附加的包围盒回归来预测盒子的中心坐标,宽度和高度。 该回归器在未来的物体检测器中被广泛使用。
However, a two-stage detector like R-CNN suffers from two big issues: 1) It’s not fully convolutional because selective search is not E2E trainable. 2) region proposal stage is usually very slow compared with other one-stage detectors like OverFeat, and running on each region proposal separately makes it even slower. Later, we will see how R-CNN evolve over time to address these two issues.
但是,像R-CNN这样的两级检测器存在两个大问题:1)它不是完全卷积的,因为选择性搜索不可E2E训练。 2)与其他单阶段检测器(如OverFeat)相比,区域提议阶段通常非常慢,并且在每个区域提议上单独运行会使其变得更慢。 稍后,我们将了解R-CNN如何随着时间的发展而发展,以解决这两个问题。
2015年:快速R-CNN (2015: Fast R-CNN)
Fast R-CNN
快速R-CNN
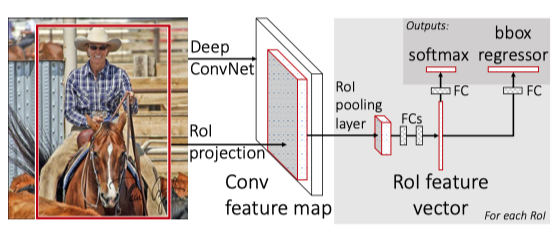
A quick follow-up for R-CNN is to reduce the duplicate convolution over multiple region proposals. Since these region proposals all come from one image, it’s naturally to improve R-CNN by running CNN over the entire image once and share the computation among many region proposals. However, different region proposals have different sizes, which also result in different output feature map sizes if we are using the same CNN feature extractor. These feature maps with various sizes will prevent us from using fully connected layers for further classification and regression because the FC layer only works with a fixed size input.
R-CNN的快速跟进是减少多个区域提案之间的重复卷积。 由于这些区域提案全部来自一张图像,因此自然可以通过在整个图像上运行一次CNN来改善R-CNN,并在许多区域提案中共享计算。 但是,不同的区域建议具有不同的大小,如果我们使用相同的CNN特征提取器,这也会导致不同的输出特征图大小。 这些具有各种尺寸的要素图将阻止我们使用完全连接的图层进行进一步的分类和回归,因为FC图层仅适用于固定大小的输入。
Fortunately, a paper called “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition” has already solved the dynamic scale issue for FC layers. In SPPNet, a feature pyramid pooling is introduced between convolution layers and FC layers to create a bag-of-words style of the feature vector. This vector has a fixed size and encodes features from different scales, so our convolution layers can now take any size of images as input without worrying about the incompatibility of the FC layer. Inspired by this, Fast R-CNN proposed a similar layer call the ROI Pooling layer. This pooling layer downsamples feature maps with different sizes into a fixed-size vector. By doing so, we can now use the same FC layers for classification and box regression, no matter how large or small the ROI is.
幸运的是,名为“用于视觉识别的深度卷积网络中的空间金字塔池化”的论文已经解决了FC层的动态缩放问题。 在SPPNet中,在卷积层和FC层之间引入了特征金字塔池,以创建特征向量的词袋样式。 此向量具有固定的大小,并编码不同比例的特征,因此我们的卷积层现在可以将任何大小的图像用作输入,而不必担心FC层的不兼容性。 受此启发,Fast R-CNN提出了一个类似的层,称为ROI Pooling层。 此池化层下采样将具有不同大小的特征图转换为固定大小的向量。 这样,无论ROI大小如何,我们现在都可以使用相同的FC层进行分类和框回归。
With a shared feature extractor and the scale-invariant ROI pooling layer, Fast R-CNN can reach a similar localization accuracy but having 10~20x faster training and 100~200x faster inference. The near real-time inference and an easier E2E training protocol for the detection part make Fast R-CNN a popular choice in the industry as well.
借助共享的特征提取器和尺度不变的ROI合并层,Fast R-CNN可以达到类似的定位精度,但训练速度提高10到20倍,推理速度提高100到200倍。 接近实时的推理和用于检测部分的更轻松的端到端培训协议使Fast R-CNN成为行业中的流行选择。
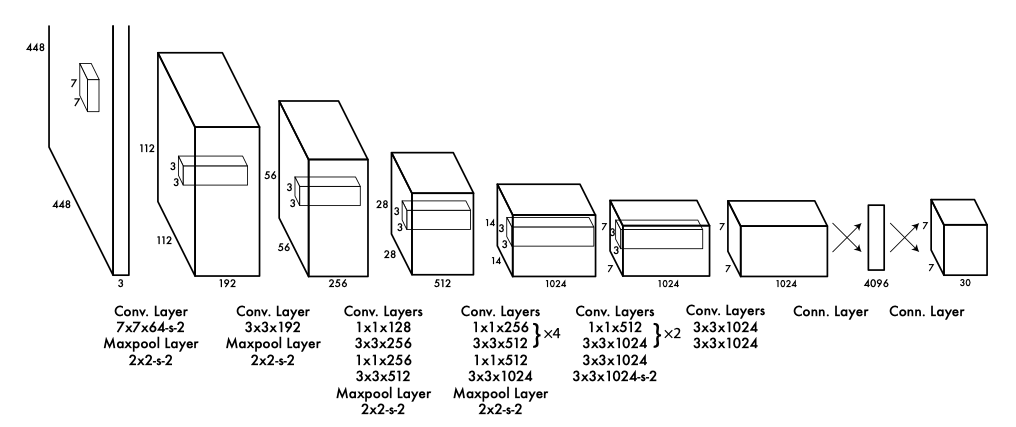
This dense prediction over the entire image can cause trouble in computation cost, so YOLO took the bottleneck structure from GooLeNet to avoid this issue. Another problem of YOLO is that two objects might fall into the same coarse grid cell, so it doesn’t work well with small objects such as a flock of birds. Despite lower accuracy, YOLO’s straightforward design and real-time inference ability makes one-stage object detection popular again in the research, and also a go-to solution for the industry.
这种对整个图像的密集预测会导致计算成本出现问题,因此YOLO采取了GooLeNet的瓶颈结构来避免此问题。 YOLO的另一个问题是两个物体可能会落入同一个粗网格单元中,因此它不适用于鸟群等较小的物体。 尽管精度较低,但YOLO的直接设计和实时推理能力使一阶段目标检测在研究中再次受到欢迎,并且也是行业首选的解决方案。
2015年:更快的R-CNN (2015: Faster R-CNN)
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
更快的R-CNN:通过区域提议网络实现实时目标检测
As we introduced above, in early 2015, Ross Girshick proposed an improved version of R-CNN called Fast R-CNN by using a shared feature extractor for proposed regions. Just a few months later, Ross and his team came back with another improvement again. This new network Faster R-CNN is not only faster than previous versions but also marks a milestone for object detection with a deep learning method.
正如我们上文所述,2015年初,罗斯·吉尔希克(Ross Girshick)通过使用提议区域的共享特征提取器,提出了一种改进的R-CNN版本,称为快速R-CNN。 仅仅几个月后,罗斯和他的团队又回来了,又有了另一个改进。 这个新的网络Faster R-CNN不仅比以前的版本快,而且标志着使用深度学习方法进行对象检测的里程碑。
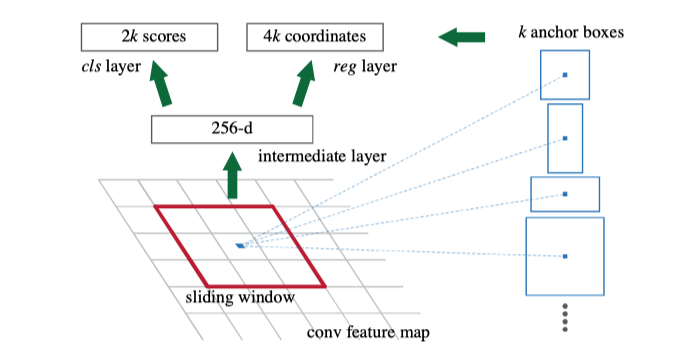
With Fast R-CNN, the only non-convolutional piece of the network is the selective search region proposal. As of 2015, researchers started to realize that the deep neural network is so magical, that it can learn anything given enough data. So, is it possible to also train a neural network to proposal regions, instead of relying on heuristic and hand-crafted approach like selective search? Faster R-CNN followed this direction and thinking, and successfully created the Region Proposal Network (RPN). To simply put, RPN is a CNN that takes an image as input and outputs a set of rectangular object proposals, each with an objectiveness score. The paper used VGG originally but other backbone networks such as ResNet become more widespread later. To generate region proposals, a 3x3 sliding window is applied over the CNN feature map output to generate 2 scores (foreground and background) and 4 coordinates each location. In practice, this sliding window is implemented with a 3x3 convolution kernel with a 1x1 convolution kernel.
使用Fast R-CNN,网络中唯一的非卷积部分是选择性搜索区域建议。 从2015年开始,研究人员开始意识到深度神经网络是如此神奇,以至于只要有足够的数据就可以学习任何东西。 因此,是否有可能将神经网络训练到投标区域,而不是依靠像选择搜索那样的启发式和手工方法? 更快的R-CNN遵循了这个方向和思想,并成功创建了区域提案网络(RPN)。 简而言之,RPN是一个CNN,它以图像作为输入并输出一组矩形的对象建议,每个对象建议都有一个客观评分。 本文最初使用VGG,但后来其他类似ResNet的骨干网络变得更加普及。 为了生成区域建议,将3x3滑动窗口应用于CNN特征图输出,以生成2个得分(前景和背景)以及每个位置4个坐标。 实际上,此滑动窗口是通过3x3卷积内核和1x1卷积内核实现的。
Although the sliding window has a fixed size, our objects may appear on different scales. Therefore, Faster R-CNN introduced a technique called anchor box. Anchor boxes are pre-defined prior boxes with different aspect ratios and sizes but share the same central location. In Faster R-CNN there are k=9 anchors for each sliding window location, which covers 3 aspect ratios for 3 scales each. These repeated anchor boxes over different scales bring nice translation-invariance and scale-invariance features to the network while sharing outputs of the same feature map. Note that the bounding box regression will be computed from these anchor box instead of the whole image.
尽管滑动窗口的大小是固定的,但我们的对象可能会以不同的比例出现。 因此,Faster R-CNN引入了一种称为锚框的技术。 锚框是预先定义的先验框,具有不同的纵横比和大小,但共享相同的中心位置。 在Faster R-CNN中,每个滑动窗口位置都有k = 9个锚点,每个锚点覆盖3个比例的3个宽高比。 这些在不同比例尺上重复出现的锚定框为网络带来了很好的平移不变性和比例不变性特征,同时共享了相同特征图的输出。 注意,将根据这些锚定框而不是整个图像计算边界框回归。
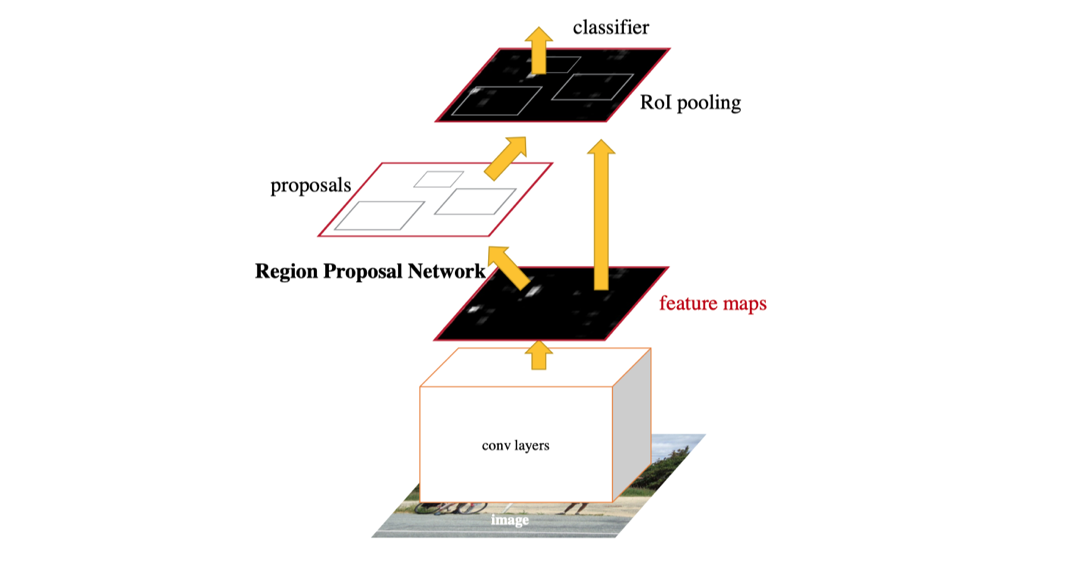
So far, we discussed the new Region Proposal Network to replace the old selective search region proposal. To make the final detection, Faster R-CNN uses the same detection head from Fast R-CNN to do classification and fine-grained localization. Do you remember that Fast R-CNN also uses a shared CNN feature extractor? Now that RPN itself is also a feature extraction CNN, we can just share it with detection head like the diagram above. This sharing design doesn’t bring some trouble though. If we train RPN and Fast R-CNN detector together, we will treat RPN proposals as a constant input of ROI pooling, and inevitably ignore the gradients of RPN’s bounding box proposals. One walk around is called alternative training where you train RPN and Fast R-CNN in turns. And later in a paper “Instance-aware semantic segmentation via multi-task network cascades”, we can see that the ROI pooling layer can also be made differentiable w.r.t. the box coordinates proposals.
到目前为止,我们讨论了新的区域提议网络以取代旧的选择性搜索区域提议。 为了进行最终检测,Faster R-CNN使用与Fast R-CNN相同的检测头进行分类和细粒度定位。 您还记得Fast R-CNN也使用共享的CNN特征提取器吗? 现在,RPN本身也是一个特征提取CNN,我们可以像上图一样与检测头共享它。 这种共享设计不会带来任何麻烦。 如果我们一起训练RPN和Fast R-CNN检测器,我们会将RPN建议视为ROI池的不变输入,并且不可避免地会忽略RPN边界框建议的梯度。 绕一圈称为替代训练,您可以依次训练RPN和Fast R-CNN。 稍后在“通过多任务网络级联进行实例感知的语义分割”一文中,我们可以看到,在框协调提议的情况下,也可以使ROI池化层具有差异性。
2015年:YOLO v1 (2015: YOLO v1)
You Only Look Once: Unified, Real-Time Object Detection
您只需看一次即可:统一的实时对象检测
While the R-CNN series started a big hype over two-stage object detection in the research community, its complicated implementation brought many headaches for engineers who maintain it. Does object detection need to be so cumbersome? If we are willing to sacrifice a bit of accuracy, can we trade for much faster speed? With these questions, Joseph Redmon submitted a network called YOLO to arxiv.org only four days after Faster R-CNN’s submission and finally brought popularity back to one-stage object detection two years after OverFeat’s debut.
尽管R-CNN系列在研究界开始大肆宣传两阶段目标检测,但其复杂的实现却给维护它的工程师带来了许多麻烦。 对象检测是否需要这么麻烦? 如果我们愿意牺牲一点准确性,我们可以以更快的速度进行交易吗? 有了这些问题,约瑟夫·雷德蒙(Joseph Redmon)在Faster R-CNN提交后仅四天就向arxiv.org提交了一个名为YOLO的网络,并在OverFeat首次亮相两年后,终于将流行度恢复到了一个阶段的对象检测。
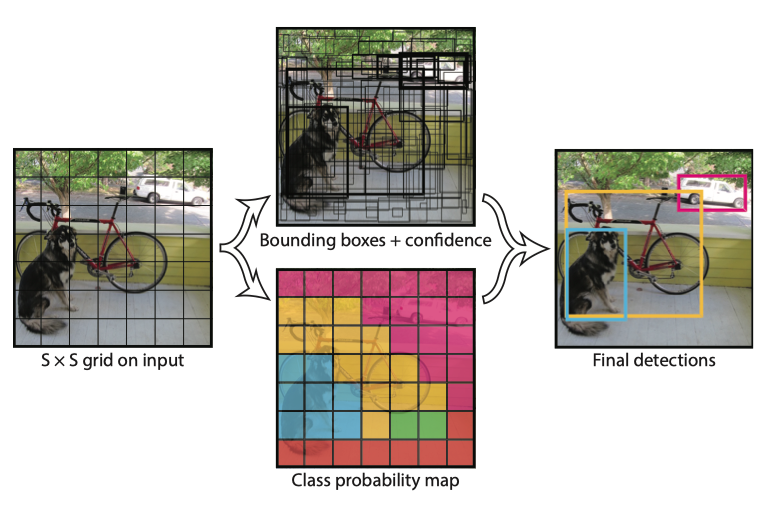
Unlike R-CNN, YOLO decided to tackle region proposal and region classification together in the same CNN. In other words, it treats object detection as a regression problem, instead of a classification problem relying on region proposals. The general idea is to split the input into an SxS grid and having each cell directly regress the bounding box location and the confidence score if the object center falls into that cell. Because objects may have different sizes, there will be more than one bounding box regressor per cell. During training, the regressor with the highest IOU will be assigned to compare with the ground-truth label, so regressors at the same location will learn to handle different scales over time. In the meantime, each cell will also predict C class probabilities, conditioned on the grid cell containing an object (high confidence score). This approach is later described as dense predictions because YOLO tried to predict classes and bounding boxes for all possible locations in an image. In contrast, R-CNN relies on region proposals to filter out background regions, hence the final predictions are much more sparse.
与R-CNN不同,YOLO决定在同一CNN中一起处理区域提议和区域分类。 换句话说,它将对象检测视为回归问题,而不是依赖于区域提议的分类问题。 一般的想法是将输入分成一个SxS网格,并在对象中心落入该单元格时让每个单元格直接回归边界框位置和置信度分数。 由于对象的大小可能不同,因此每个单元将有一个以上的包围盒回归器。 在训练期间,将分配具有最高IOU的回归变量与地面真实性标签进行比较,因此同一位置的回归变量将随着时间的推移学会处理不同的音阶。 同时,每个单元还将根据包含对象的网格单元(高置信度得分)来预测C类概率。 后来,这种方法被称为密集预测,因为YOLO试图预测图像中所有可能位置的类和边界框。 相比之下,R-CNN依靠区域提议来滤除背景区域,因此最终的预测要稀疏得多。
2015年:SSD (2015: SSD)
SSD: Single Shot MultiBox Detector
SSD:单发MultiBox检测器
YOLO v1 demonstrated the potentials of one-stage detection, but the performance gap from two-stage detection is still noticeable. In YOLO v1, multiple objects could be assigned to the same grid cell. This was a big challenge when detecting small objects, and became a critical problem to solve in order to improve a one-stage detector’s performance to be on par with two-stage detectors. SSD is such a challenger and attacks this problem from three angles.
YOLO v1展示了一级检测的潜力,但是与二级检测相比的性能差距仍然很明显。 在YOLO v1中,可以将多个对象分配给同一网格单元。 当检测小物体时,这是一个很大的挑战,并且成为要提高一级检测器的性能以使其与两级检测器相提并论的关键问题。 SSD就是这样的挑战者,并从三个角度解决这个问题。
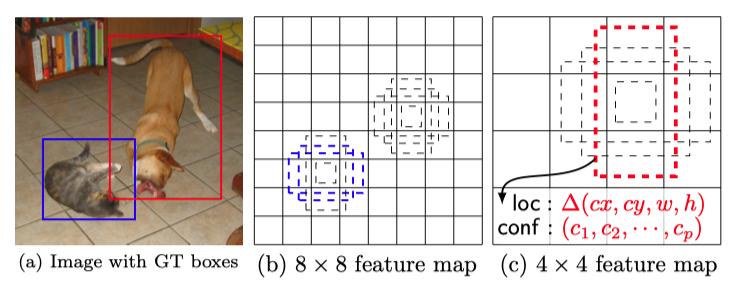
First, the anchor box technique from Faster R-CNN can alleviate this problem. Objects in the same area usually come with different aspect ratios to be visible. Introducing anchor box not only increased the amount of object to detect for each cell, but also helped the network to better differentiate overlapping small objects with this aspect ratio assumption.
首先,Faster R-CNN的锚框技术可以缓解此问题。 同一区域中的对象通常具有不同的长宽比以使其可见。 引入锚框不仅增加了每个单元要检测的对象数量,而且还通过这种长宽比假设帮助网络更好地区分了重叠的小对象。
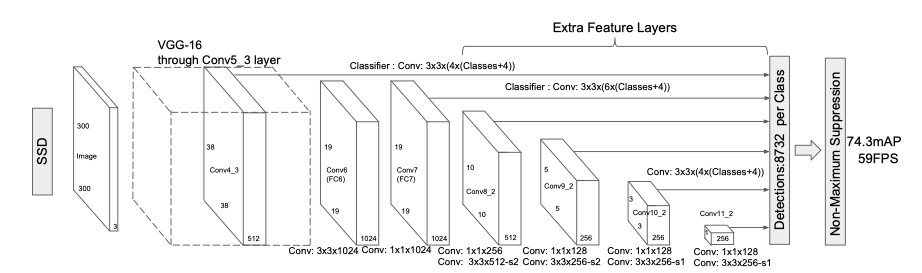
SSD went down on this road further by aggregating multi-scale features before detection. This is a very common approach to pick up fine-grained local features while preserving coarse global features in CNN. For example, FCN, the pioneer of CNN semantic segmentation, also merged features from multiple levels to refine the segmentation boundary. Besides, multi-scale feature aggregation can be easily performed on all common classification networks, so it’s very convenient to swap out the backbone with another network.
在检测之前,SSD通过整合多尺度功能进一步走上了这条道路。 这是在保留CNN中粗粒度全局特征的同时获取细粒度局部特征的一种非常常用的方法。 例如,CNN语义分割的先驱FCN也合并了多个级别的特征以完善分割边界。 此外,可以在所有常见分类网络上轻松执行多尺度特征聚合,因此将主干与另一个网络交换出去非常方便。
Finally, SSD leveraged a large amount of data augmentation, especially targeted to small objects. For example, images are randomly expanded to a much larger size before random cropping, which brings a zoom-out effect to the training data to simulate small objects. Also, large bounding boxes are usually easy to learn. To avoid these easy examples dominating the loss, SSD adopted a hard negative mining technique to pick examples with the highest loss for each anchor box.
最后,SSD利用了大量的数据扩充功能,尤其是针对小型对象。 例如,在随机裁剪之前将图像随机扩展到更大的尺寸,这会给训练数据带来缩小效果以模拟小物体。 而且,大型边界框通常易于学习。 为了避免这些简单的示例占主导地位的损失,SSD采用硬性负挖矿技术为每个锚定框选择损失最高的示例。
2016年:FPN (2016: FPN)
Feature Pyramid Networks for Object Detection
用于目标检测的特征金字塔网络
With the launch of Faster-RCNN, YOLO, and SSD in 2015, it seems like the general structure an object detector is determined. Researchers start to look at improving each individual parts of these networks. Feature Pyramid Networks is an attempt to improve the detection head by using features from different layers to form a feature pyramid. This feature pyramid idea isn’t very novel in computer vision research. Back then when features are still manually designed, feature pyramid is already a very effective way to recognize patterns at different scales. Using the Feature Pyramid in deep learning is also not a new idea: SSPNet, FCN, and SSD all demonstrated the benefit of aggregating multiple-layer features before classification. However, how to share the feature pyramid between RPN and the region-based detector is still yet to be determined.
随着2015年Faster-RCNN,YOLO和SSD的推出,似乎确定了对象检测器的一般结构。 研究人员开始考虑改进这些网络的各个部分。 特征金字塔网络是通过使用来自不同层的特征以形成特征金字塔来改进检测头的尝试。 这个特征金字塔的想法在计算机视觉研究中不是很新颖。 那时,当仍然手动设计要素时,要素金字塔已经是一种识别不同比例尺图案的非常有效的方法。 在深度学习中使用功能金字塔也不是一个新主意:SSPNet,FCN和SSD都展示了在分类之前聚合多层功能的好处。 然而,如何在RPN和基于区域的检测器之间共享特征金字塔仍有待确定。
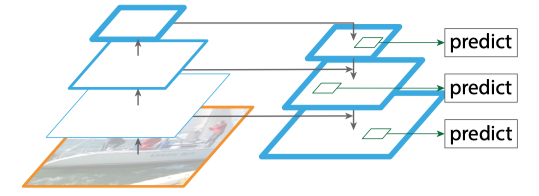
First, to rebuild RPN with an FPN structure like the diagram above, we need to have a region proposal running on multiple different scales of feature output. Also, we only need 3 anchors with different aspect ratios per location now because objects with different sizes will be handle by different levels of the feature pyramid. Next, to use an FPN structure in the Fast R-CNN detector, we also need to adapt it to detect on multiple scales of feature maps as well. Since region proposals might have different scales too, we should use them in the corresponding level of FPN as well. In short, if Faster R-CNN is a pair of RPN and region-based detector running on one scale, FPN converts it into multiple parallel branches running on different scales and collects the final results from all branches in the end.
首先,要使用上图所示的FPN结构重建RPN,我们需要有一个在多个不同比例的要素输出上运行的区域提议。 另外,现在每个位置只需要3个具有不同长宽比的锚点,因为具有不同大小的对象将由要素金字塔的不同级别处理。 接下来,要在Fast R-CNN检测器中使用FPN结构,我们还需要对其进行调整以在多个比例的特征图上进行检测。 由于区域提案的规模也可能不同,因此我们也应在相应的FPN级别中使用它们。 简而言之,如果Faster R-CNN是一对以单个比例运行的RPN和基于区域的检测器,则FPN会将其转换为以不同比例运行的多个并行分支,并最终收集所有分支的最终结果。
2016年:YOLO v2 (2016: YOLO v2)
YOLO9000: Better, Faster, Stronger
YOLO9000:更好,更快,更强大
While Kaiming He, Ross Girshick, and their team keep improving their two-stage R-CNN detectors, Joseph Redmon, on the other hand, was also busy improving his one-stage YOLO detector. The initial version of YOLO suffers from many shortcomings: predictions based on a coarse grid brought lower localization accuracy, two scale-agnostic regressors per grid cell also made it difficult to recognize small packed objects. Fortunately, we saw too many great innovations in 2015 in many computer vision areas. YOLO v2 just needs to find a way to integrate them all to become better, faster, and stronger. Here are some highlights of the modifications:
在何凯明,罗斯·吉尔希克(Ross Girshick)及其团队不断改进其两阶段R-CNN探测器的同时,约瑟夫·雷德蒙(Joseph Redmon)也忙于改进其一阶段YOLO探测器。 YOLO的初始版本存在许多缺点:基于粗网格的预测带来较低的定位精度,每个网格单元有两个与规模无关的回归变量,这也使得难以识别小的包装物体。 幸运的是,2015年我们在许多计算机视觉领域看到了太多伟大的创新。 YOLO v2只需要找到一种方法来整合它们,使其变得更好,更快,更强大。 以下是修改的一些重点:
YOLO v2 added Batch Normalization layers from a paper called “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”.
YOLO v2从名为“ 批处理规范化:通过减少内部协变量偏移来加速深度网络训练 ”的论文中添加了批处理规范化层。
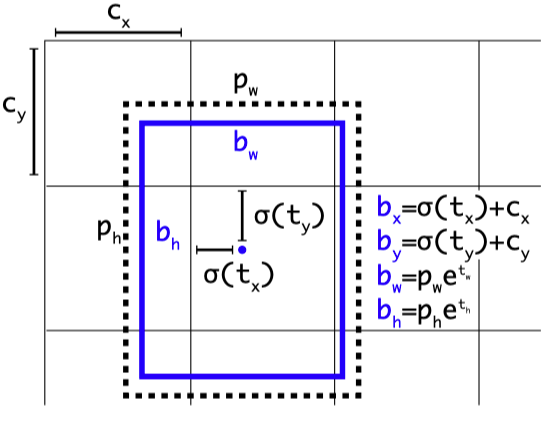
Just like SSD, YOLO v2 also introduced Faster R-CNN’s idea of anchor boxes for bounding box regression. But YOLO v2 did some customization for its anchor boxes. Instead of predicting offsets to anchor boxes, YOLOv2 constraints the object center regression tx and ty within the responsible grid cell to stabilize early training. Also, anchors sizes are determined by a K-means clustering of the target dataset to better align with object shapes.
就像SSD一样,YOLO v2也引入了Faster R-CNN的锚框用于边界框回归的想法。 但是YOLO v2对其锚框进行了一些自定义。 YOLOv2并没有预测锚框的偏移量,而是限制了责任网格单元内的对象中心回归tx和ty来稳定早期训练。 同样,锚点的大小由目标数据集的K均值聚类确定,以更好地与对象形状对齐。
A new backbone network called Darknet is used for feature extraction. This is inspired by “Network in Network” and GooLeNet’s bottleneck structure.
一种称为Darknet的新骨干网络用于特征提取。 这受到“ 网络中的网络 ”和GooLeNet瓶颈结构的启发。
- To improve the detection of small objects, YOLO v2 added a passthrough layer to merge features from an early layer. This part can be seen as a simplified version of SSD. 为了改善对小物体的检测,YOLO v2添加了直通层以合并早期层中的要素。 这部分可以看作是SSD的简化版本。
- Last but not least, Joseph realized that input resolution is a silver bullet for small object detection. It not only doubled the input for the backbone to 448x448 from 224x224 but also invented a multi-scale training schema, which involves different input resolutions at different periods of training. 最后但并非最不重要的一点,约瑟夫意识到输入分辨率是检测小物体的灵丹妙药。 它不仅将骨干网的输入从224x224增加了一倍,达到448x448,而且发明了一种多尺度训练方案,该方案在不同的训练阶段涉及不同的输入分辨率。
Note that YOLO v2 also experimented with a version that’s trained on 9000 classes hierarchical datasets, which also represents an early trial of multi-label classification in an object detector.
请注意,YOLO v2还试验了针对9000类分层数据集进行训练的版本,这也代表了在对象检测器中进行多标签分类的早期尝试。
2017年:RetinaNet (2017: RetinaNet)
Focal Loss for Dense Object Detection
密集物体检测的焦点损失
To understand why one-stage detectors are usually not as good as two-stage detectors, RetinaNet investigated the foreground-background class imbalance issue from a one-stage detector’s dense predictions. Take YOLO as an example, it tried to predict classes and bounding boxes for all possible locations in the meantime, so most of the outputs are matched to negative class during training. SSD addressed this issue by online hard example mining. YOLO used an objectiveness score to implicitly train a foreground classifier in the early stage of training. RetinaNet thinks they both didn’t get the key to the problem, so it invented a new loss function called Focal Loss to help the network learn what’s important.
为了了解为什么一级检测器通常不如二级检测器好,RetinaNet从一级检测器的密集预测中研究了前景-背景类不平衡问题。 以YOLO为例,它试图同时预测所有可能位置的类别和边界框,因此在训练过程中,大多数输出都与否定类别匹配。 SSD通过在线硬示例挖掘解决了此问题。 YOLO在训练的早期阶段使用客观分数来隐式训练前景分类器。 RetinaNet认为他们俩都没有找到解决问题的关键,因此,它发明了一个名为Focal Loss的新损失函数,以帮助网络了解重要信息。
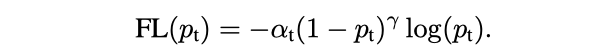
Focal Loss added a power γ (they call it focusing parameter) to Cross-Entropy loss. Naturally, as the confidence score becomes higher, the loss value will become much lower than a normal Cross-Entropy. The α parameter is used to balance such a focusing effect.
焦点损耗为交叉熵损耗增加了幂γ(它们称为聚焦参数)。 自然,随着置信度得分的提高,损失值将变得比正常的交叉熵要低得多。 α参数用于平衡这种聚焦效果。
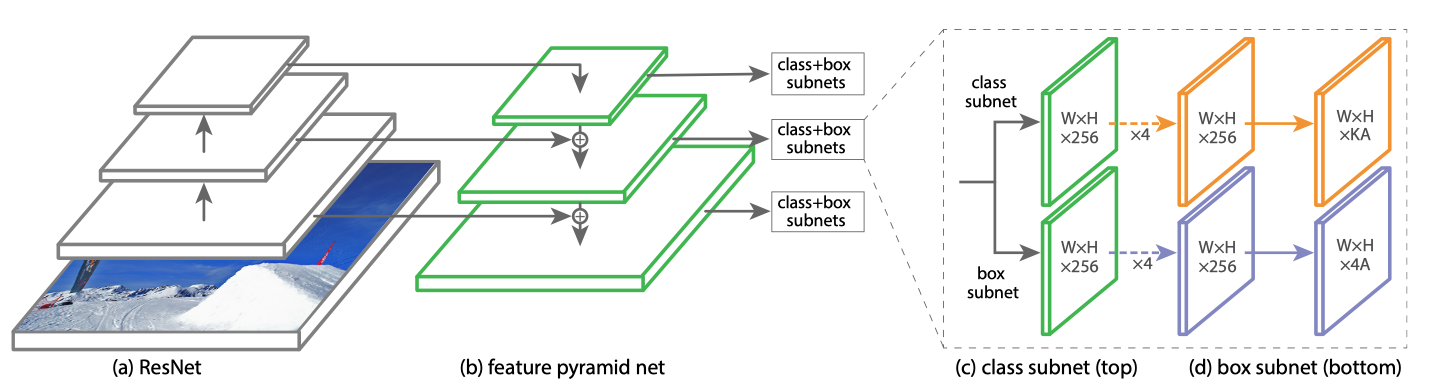
This idea is so simple that even a primary school student can understand. So to further justify their work, they adapted the FPN model they previously proposed and created a new one-stage detector called RetinaNet. It is composed of a ResNet backbone, an FPN detection neck to channel features at different scales, and two subnets for classification and box regression as detection head. Similar to SSD and YOLO v3, RetinaNet uses anchor boxes to cover targets of various scales and aspect ratios.
这个想法非常简单,甚至小学生也能理解。 因此,为进一步证明他们的工作合理性,他们改用了他们先前提出的FPN模型,并创建了一个新的称为RetinaNet的单级探测器。 它由ResNet主干网,FPN检测颈以不同尺度的通道特征组成,以及两个用于分类和框回归的子网作为检测头。 与SSD和YOLO v3相似,RetinaNet使用锚框覆盖各种比例和纵横比的目标。
A bit of a digression, RetinaNet used the COCO accuracy from a ResNeXT-101 and 800 input resolution variant to contrast YOLO v2, which only has a light-weighted Darknet-19 backbone and 448 input resolution. This insincerity shows the team’s emphasis on getting better benchmark results, rather than solving a practical issue like a speed-accuracy trade-off. And it might be part of the reason that RetinaNet didn’t take off after its release.
有点离题,RetinaNet使用ResNeXT-101和800输入分辨率变体的COCO精度来对比YOLO v2,后者仅具有轻量级Darknet-19主干和448输入分辨率。 这种不诚实表明团队强调获得更好的基准测试结果,而不是解决诸如速度精度折衷之类的实际问题。 这可能是RetinaNet发布后没有起飞的部分原因。
2018年:YOLO v3 (2018: YOLO v3)
YOLOv3: An Incremental Improvement
YOLOv3:增量改进
YOLO v3 is the last version of the official YOLO series. Following YOLO v2’s tradition, YOLO v3 borrowed more ideas from previous research and got an incredible powerful one-stage detector like a monster. YOLO v3 balanced the speed, accuracy, and implementation complexity pretty well. And it got really popular in the industry because of its fast speed and simple components. If you are interested, I wrote a very detailed explanation of how YOLO v3 works in my previous article “Dive Really Deep into YOLO v3: A Beginner’s Guide”.
YOLO v3是YOLO官方系列的最新版本。 遵循YOLO v2的传统,YOLO v3借鉴了以前的研究中的更多想法,并获得了令人难以置信的强大的一级检测器,就像怪物一样。 YOLO v3很好地平衡了速度,准确性和实现复杂性。 由于它的快速和简单的组件,它在行业中非常流行。 如果您有兴趣,我在我之前的文章“ 深入研究YOLO v3:入门指南 ”中对YOLO v3的工作方式进行了非常详细的说明。
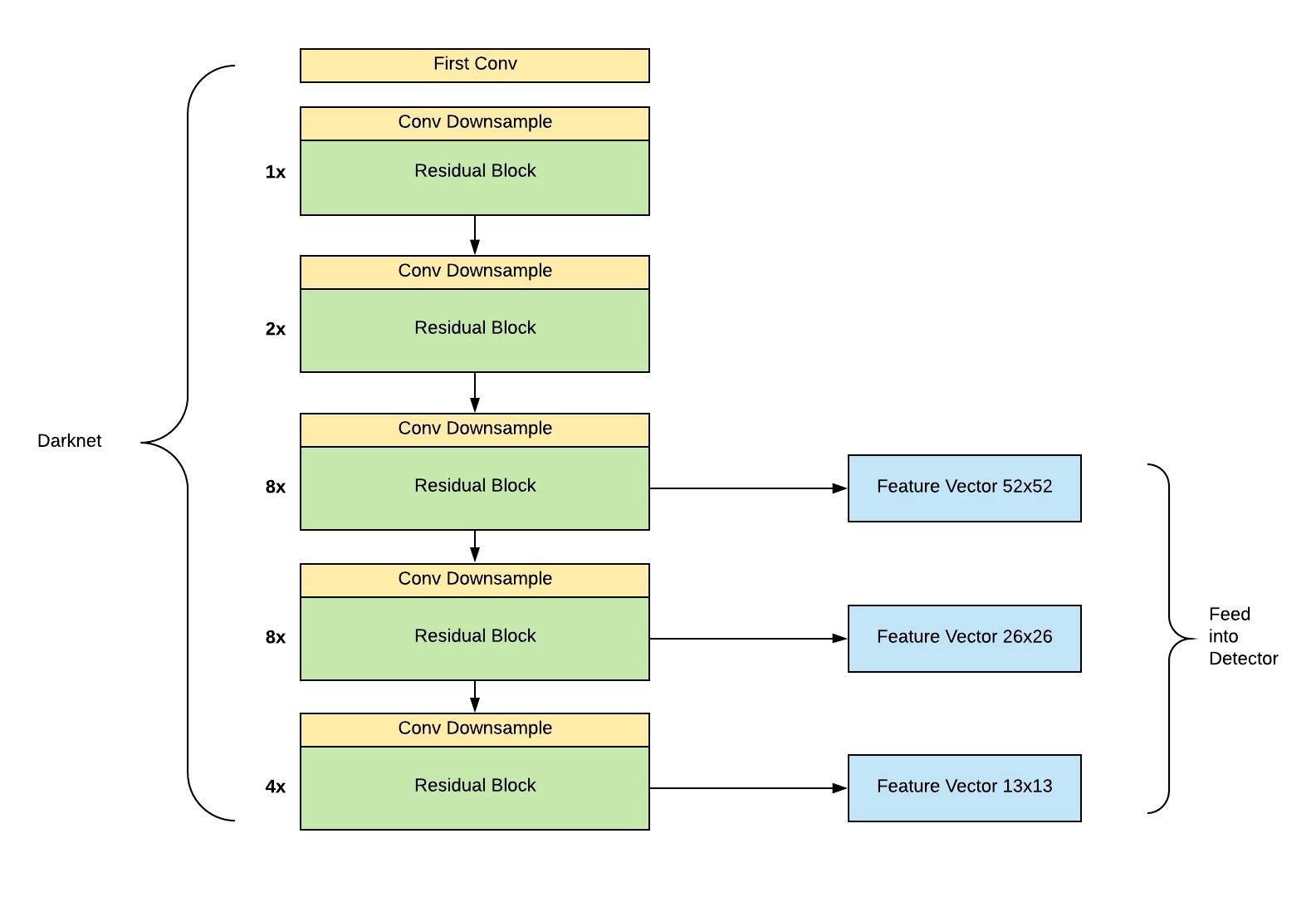
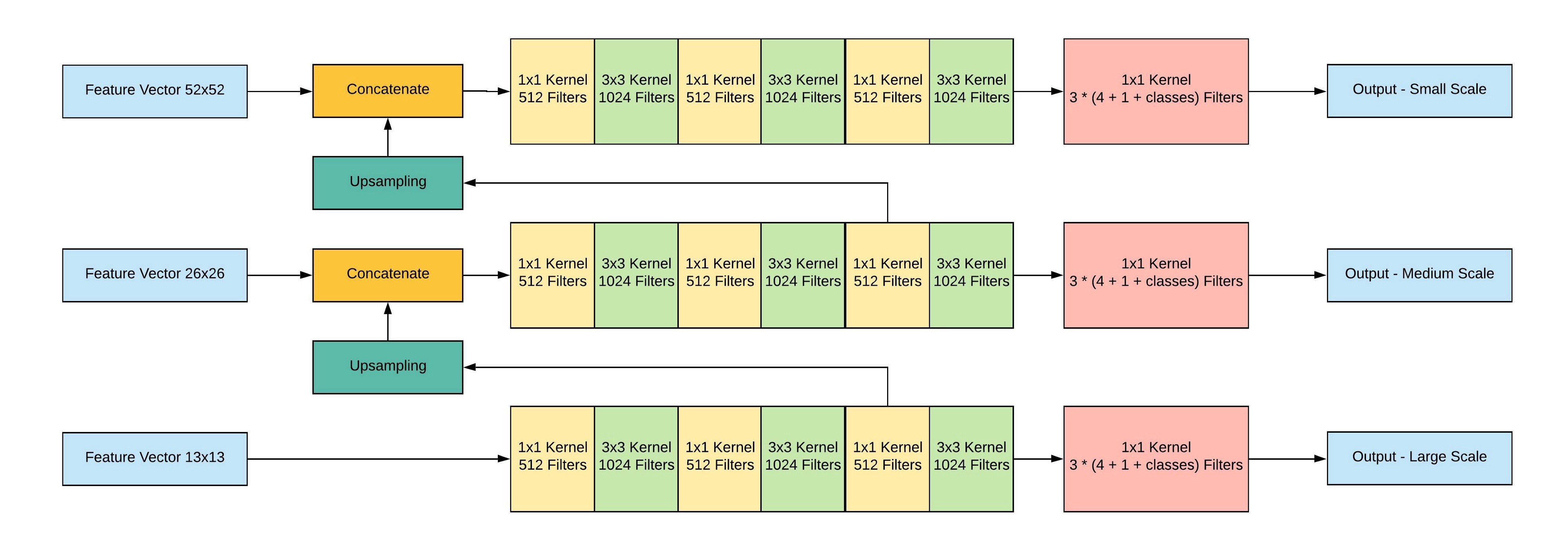
Simply put, YOLO v3’s success comes from its more powerful backbone feature extractor and a RetinaNet-like detection head with an FPN neck. The new backbone network Darknet-53 leveraged ResNet’s skip connections to achieve an accuracy that’s on par with ResNet-50 but much faster. Also, YOLO v3 ditched v2’s pass through layers and fully embraced FPN’s multi-scale predictions design. Since then, YOLO v3 finally reversed people’s impression of its poor performance when dealing with small objects.
简而言之,YOLO v3的成功来自更强大的主干特征提取器和带有FPN颈部的类似RetinaNet的检测头。 新的骨干网Darknet-53利用ResNet的跳过连接来实现与ResNet-50相同的准确性,但速度要快得多。 此外,YOLO v3放弃了v2的通过层,并完全接受了FPN的多尺度预测设计。 从那时起,YOLO v3终于扭转了人们对处理小物体时性能低下的印象。
Besides, there are a few fun facts about YOLO v3. It dissed the COCO mAP 0.5:0.95 metric, and also demonstrated the uselessness of Focal Loss when using a conditioned dense prediction. The author Joseph even decided to quit the whole computer vision research a year later, because of his concern of military usage.
此外,关于YOLO v3还有一些有趣的事实。 它放弃了COCO mAP 0.5:0.95指标,并且还证明了在使用条件密集预测时,焦点损失的无用性。 由于担心军事用途,作者约瑟夫甚至决定在一年后退出整个计算机视觉研究。
2019:以对象为点 (2019: Objects As Points)
Although the image classification area becomes less active recently, object detection research is still far from mature. In 2018, a paper called “CornerNet: Detecting Objects as Paired Keypoints” provided a new perspective for detector training. Since preparing anchor box targets is a quite cumbersome job, is it really necessary to use them as a prior? This new trend of ditching anchor boxes is called “anchor-free” object detection.
尽管近来图像分类领域变得不太活跃,但是对象检测研究还远远不成熟。 2018年,一篇名为“ CornerNet:将对象检测为配对的关键点”的论文为检测器培训提供了新的视角。 由于准备锚定框目标是一项非常繁琐的工作,因此真的有必要先使用它们吗? 抛开锚框的这种新趋势被称为“无锚”物体检测。

Inspired by the use of heat-map in the Hourglass network for human pose estimation, CornerNet uses a heat-map generated by box corners to supervise the bounding box regression. To learn more about how heat-map is used in Hourglass Network, you can read my previous article “Human Pose Estimation with Stacked Hourglass Network and TensorFlow”.
受Hourglass网络中使用热图进行人体姿势估计的启发,CornerNet使用由框角生成的热图来监督边界框回归。 要了解有关在沙漏网络中如何使用热图的更多信息,您可以阅读我以前的文章“ 使用堆叠式沙漏网络和TensorFlow进行人体姿势估计 ”。

Objects As Points, aka CenterNet, took a step further. It uses heat-map peaks to represent object centers, and the network will regress the box width and height directly from these box centers. Essentially, CenterNet is using every pixel as grid cells. With a Gaussian distributed heat-map, the training is also easier to converge compared with previous attempts which tried to regress bounding box size directly.
对象即点(又名CenterNet)又走了一步。 它使用热图峰表示对象中心,网络将直接从这些盒子中心回归盒子的宽度和高度。 本质上,CenterNet会将每个像素用作网格单元。 与以前的尝试直接使边界框大小回归的尝试相比,使用高斯分布的热图,训练也更易于收敛。
The elimination of anchor boxes also has another useful side effect. Previously, we rely on IOU ( such as > 0.7) between the anchor box and the ground truth box to assign training targets. By doing so, a few neighboring anchors may get all assigned a positive target for the same object. And the network will learn to predict multiple positive boxes for the same object too. The common way to fix this issue is to use a technique called Non-maximum Suppression (NMS). It’s a greedy algorithm to filter out boxes that are too close together. Now that anchors are gone and we only have one peak per object in the heat-map, there’s no need to use NMS any more. Since NMS is sometimes hard to implement and slow to run, getting rid of NMS is a big benefit for the applications that run in various environments with limited resources.
消除锚固盒也具有另一个有用的副作用。 以前,我们依靠锚框和地面真值框之间的IOU(例如> 0.7)来分配训练目标。 这样,几个相邻的锚可能会为所有相同对象分配正目标。 网络还将学习预测同一对象的多个肯定框。 解决此问题的常用方法是使用一种称为非最大抑制(NMS)的技术。 这是一种贪婪的算法,可过滤掉距离太近的盒子。 现在,锚点已经消失了,并且热图中每个对象只有一个峰,因此不再需要使用NMS。 由于NMS有时难以实施且运行缓慢,因此对于在资源有限的各种环境中运行的应用程序而言,摆脱NMS的好处是它的一大优势。
2019年:EfficientDet (2019: EfficientDet)
EfficientDet: Scalable and Efficient Object Detection
EfficientDet:可扩展且高效的对象检测
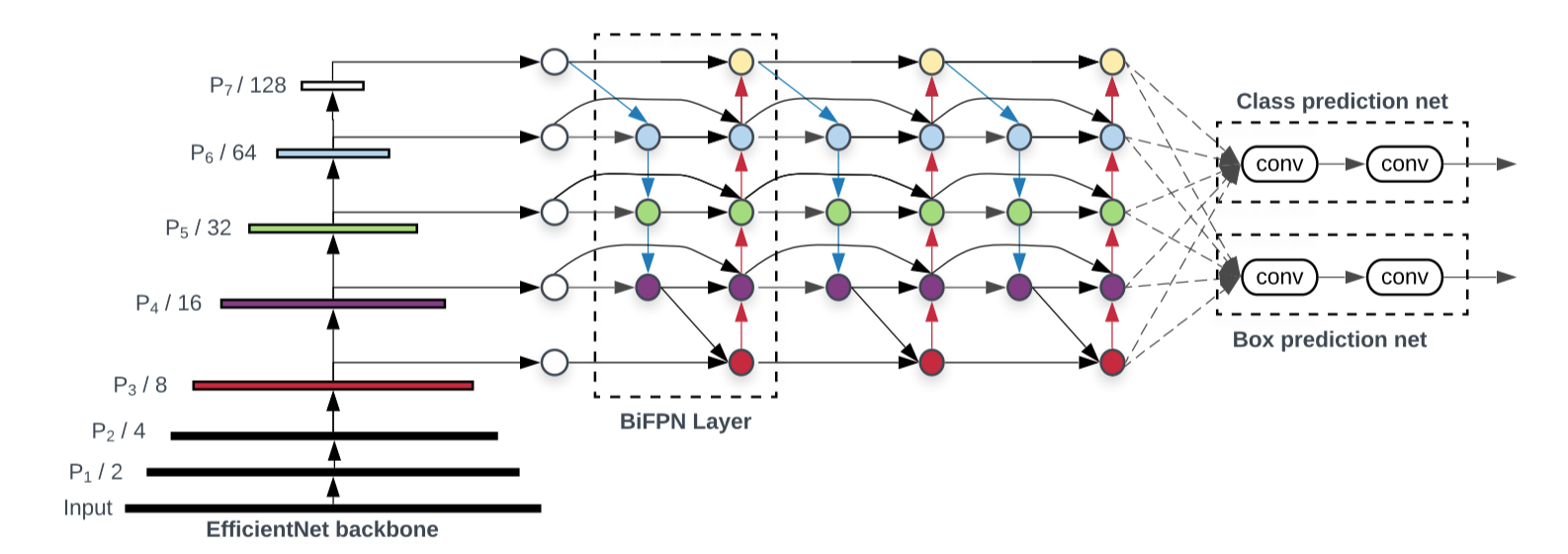
In the recent CVPR’20, EfficientDet showed us some more exciting development in the object detection area. FPN structure has been proved to be a powerful technique to improve the detection network’s performance for objects at different scales. Famous detection networks such as RetinaNet and YOLO v3 all adopted an FPN neck before box regression and classification. Later, NAS-FPN and PANet (please refer to Read More section) both demonstrated that a plain multi-layer FPN structure may benefit from more design optimization. EfficientDet continued exploring in this direction, eventually created a new neck called BiFPN. Basically, BiFPN features additional cross-layer connections to encourage feature aggregation back and forth. To justify the efficiency part of the network, this BiFPN also removed some less useful connections from the original PANet design. Another innovative improvement over the FPN structure is the weight feature fusion. BiFPN added additional learnable weights to feature aggregation so that the network can learn the importance of different branches.
在最近的CVPR'20中,EfficientDet向我们展示了物体检测领域中一些更令人兴奋的发展。 事实证明,FPN结构是一种改进检测网络针对不同规模物体的性能的强大技术。 诸如RetinaNet和YOLO v3之类的著名检测网络在盒回归和分类之前都采用了FPN颈。 后来,NAS-FPN和PANet(请参阅“阅读更多”部分)都证明,普通的多层FPN结构可能会受益于更多的设计优化。 EfficientDet继续朝这个方向进行探索,最终创建了一个称为BiFPN的新脖子。 基本上,BiFPN具有附加的跨层连接,以鼓励来回地进行特征聚合。 为了证明网络的效率部分是合理的,此BiFPN还从原始PANet设计中删除了一些不太有用的连接。 FPN结构的另一个创新改进是重量特征融合。 BiFPN为功能聚合增加了其他可学习的权重,以便网络可以了解不同分支机构的重要性。
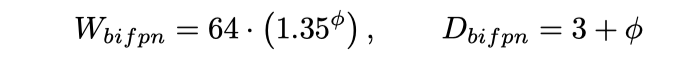
Moreover, just like what we saw in the image classification network EfficientNet, EfficientDet also introduced a principled way to scale an object detection network. The φ parameter in the above formula controls both width (channels) and depth (layers) of both BiFPN neck and detection head.
此外,就像我们在图像分类网络EfficientNet中看到的一样,EfficientDet也引入了一种原理化的方法来扩展对象检测网络。 上式中的φ参数控制BiFPN颈部和检测头的宽度(通道)和深度(层)。
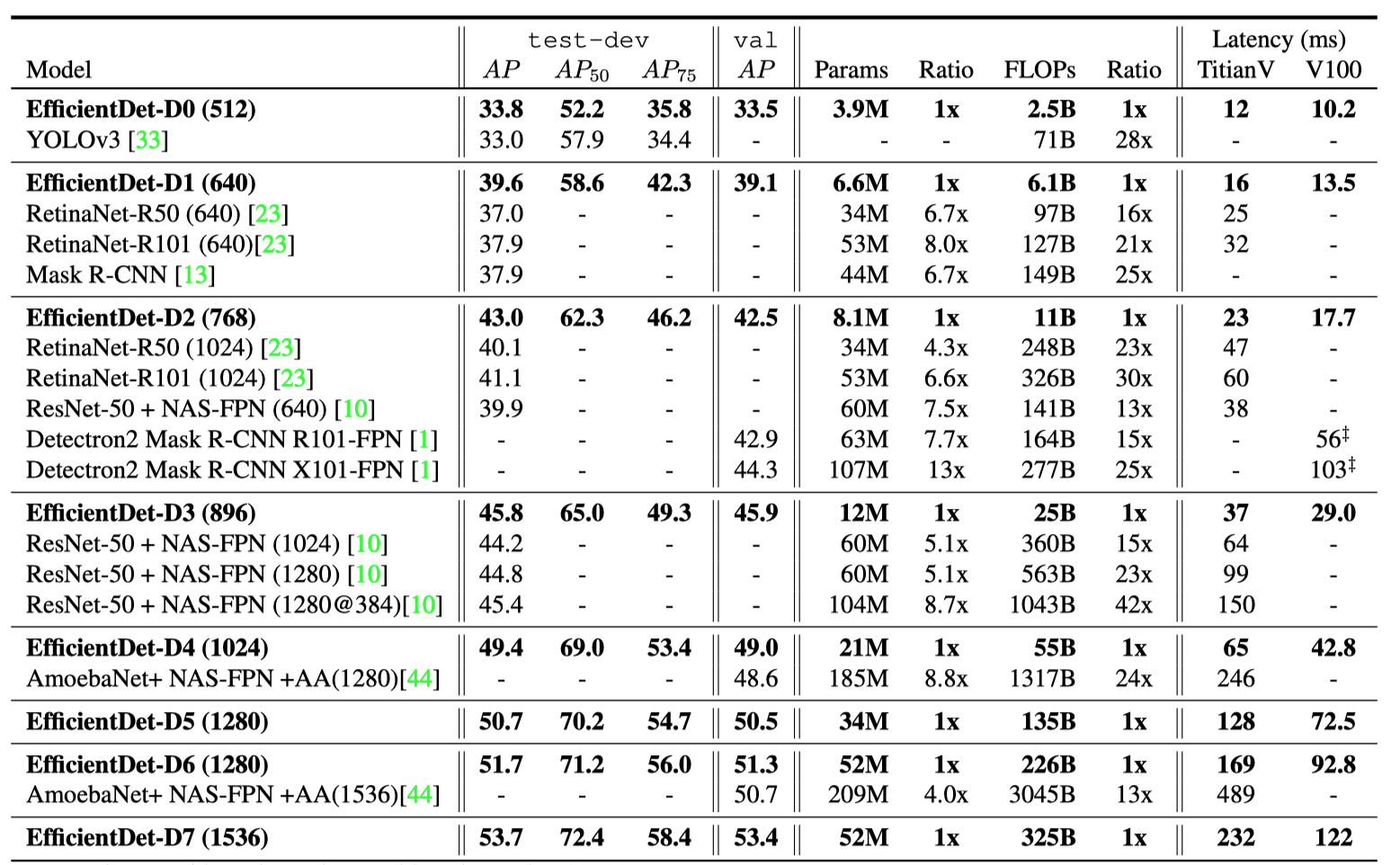
This new parameter results in 8 different variants of EfficientDet from D0 to D7. A light-weighed D0 variant can achieve similar accuracy with YOLO v3 while having much fewer FLOPs. A heavy-loaded D7 variant with monstrous 1536x1536 input can even reach 53.7 AP on COCO that dwarfed all other contenders.
此新参数导致从D0到D7的8种不同的EfficientDet变体。 重量轻的D0变体可以与YOLO v3达到类似的精度,而FLOP则少得多。 重负载的D7变种具有惊人的1536x1536输入,在COCO上甚至可以达到53.7 AP,这使所有其他竞争者都相形见war。
阅读更多 (Read More)
From R-CNN, YOLO to recent CenterNet and EfficientDet, we have witnessed most major innovations in the object detection research in the deep learning era. Aside from the above papers, I’ve also provided a list of additional papers for you to keep reading to get a deeper understanding. They either provided a different perspective for object detection or extended this area with more powerful features.
从R-CNN,YOLO到最新的CenterNet和EfficientDet,我们见证了深度学习时代对象检测研究中的大多数重大创新。 除了以上论文,我还提供了一些其他论文清单,供您继续阅读以加深了解。 他们为物体检测提供了不同的视角,或者通过更强大的功能扩展了该领域。
2009年:DPM (2009: DPM)
Object Detection with Discriminatively Trained Part Based Models
具有区别训练的基于零件的模型的目标检测
By matching many HOG features for each deformable parts, DPM was one of the most efficient object detection models before the deep learning era. Take pedestrian detection as an example, it uses a star structure to recognize the general person pattern first, and then recognize parts with different sub-filters and calculate an overall score. Even today, the idea to recognize objects with deformable parts is still popular after we switch from HOG features to CNN features.
通过为每个可变形零件匹配许多HOG功能,DPM是深度学习时代之前最有效的对象检测模型之一。 以行人检测为例,它使用星形结构先识别一般人的模式,然后再识别具有不同子过滤器的部分并计算总得分。 即使在今天,当我们从HOG功能切换到CNN功能之后,识别具有可变形零件的对象的想法仍然很流行。
2012:选择性搜寻 (2012: Selective Search)
Selective Search for Object Recognition
选择性搜索对象识别
Like DPM, Selective Search is also not a product of the deep learning era. However, this method combined so many classical computer vision approaches together, and also used in the early R-CNN detector. The core idea of selective search is inspired by semantic segmentation where pixels are group by similarity. Selective Search uses different criteria of similarity such as color space and SIFT-based texture to iteratively merge similar areas together. And these merged area areas served as foreground predictions and followed by an SVM classifier for object recognition.
像DPM一样,选择性搜索也不是深度学习时代的产物。 但是,这种方法将许多经典的计算机视觉方法结合在一起,并且也用于早期的R-CNN检测器。 选择性搜索的核心思想是受语义分割启发的,其中像素按相似性分组。 选择性搜索使用不同的相似性标准(例如颜色空间和基于SIFT的纹理)将相似区域迭代合并在一起。 这些合并的区域用作前景预测,随后是用于对象识别的SVM分类器。
2016年:R-FCN (2016: R-FCN)
R-FCN: Object Detection via Region-based Fully Convolutional Networks
R-FCN:通过基于区域的全卷积网络进行对象检测
Faster R-CNN finally combined RPN and ROI feature extraction and improved the speed a lot. However, for each region proposal, we still need fully connected layers to compute class and bounding box separately. If we have 300 ROIs, we need to repeat this by 300 hundred times, and this is also the origin of the major speed difference between one-stage and two-stage detector. R-FCN borrowed the idea from FCN for semantic segmentation, but instead of computing the class mask, R-FCN computes a positive sensitive score maps. This map will predict the probability of the appearance of the object at each location, and all locations will vote (average) to decide the final class and bounding box. Besides, R-FCN also used atrous convolution in its ResNet backbone, which is originally proposed in the DeepLab semantic segmentation network. To understand what is atrous convolution, please see my previous article “Witnessing the Progression in Semantic Segmentation: DeepLab Series from V1 to V3+”.
更快的R-CNN最终将RPN和ROI特征提取结合在一起,大大提高了速度。 但是,对于每个区域建议,我们仍然需要完全连接的图层来分别计算类和边界框。 如果我们有300个ROI,则需要重复进行300次,这也是一级和二级检测器之间主要速度差异的根源。 R-FCN借用了FCN的思想进行语义分割,但是R-FCN代替了计算类别掩码,而是计算了一个正敏感分数图。 该图将预测对象在每个位置出现的可能性,所有位置将投票(取平均值)以决定最终的类和边界框。 此外,R-FCN在其ResNet主干网中也使用了粗糙卷积,该卷积网最初是在DeepLab语义分段网络中提出的。 要了解什么是无意义的卷积,请参阅我以前的文章“ 见证语义分割的进展:从V1到V3 +的DeepLab系列 ”。
2017年:Soft-NMS (2017: Soft-NMS)
Improving Object Detection With One Line of Code
用一行代码改善对象检测
Non-maximum suppression (NMS) is widely used in anchor-based object detection networks to reduce duplicate positive proposals that are close-by. More specifically, NMS iteratively eliminates candidate boxes if they have a high IOU with a more confident candidate box. This could lead to some unexpected behavior when two objects with the same class are indeed very close to each other. Soft-NMS made a small change to only scaling down the confidence score of the overlapped candidate boxes with a parameter. This scaling parameter gives us more control when tuning the localization performance, and also leads to a better precision when a high recall is also needed.
非最大抑制(NMS)广泛用于基于锚的对象检测网络中,以减少附近的重复肯定建议。 更具体地说,如果NMS具有较高的IOU和更自信的候选框,则NMS迭代地消除它们。 当具有相同类的两个对象确实彼此非常接近时,这可能导致某些意外行为。 Soft-NMS进行了很小的更改,仅按比例缩小了重叠候选框的置信度。 当调整本地化性能时,此缩放参数可为我们提供更多控制权,并且在还需要较高召回率的情况下,还可以提高精度。
2017年:Cascade R-CNN (2017: Cascade R-CNN)
Cascade R-CNN: Delving into High Quality Object Detection
级联R-CNN:致力于高质量目标检测
While FPN exploring how to design a better R-CNN neck to use backbone features Cascade R-CNN investigated a redesign of R-CNN classification and regression head. The underlying assumption is simple yet insightful: the higher IOU criteria we use when preparing positive targets, the less false positive predictions the network will learn to make. However, we can’t simply increase such IOU threshold from commonly used 0.5 to more aggressive 0.7, because it could also lead to more overwhelming negative examples during training. Cascade R-CNN’s solution is to chain multiple detection head together, each will rely on the bounding box proposals from the previous detection head. Only the first detection head will use the original RPN proposals. This effectively simulated an increasing IOU threshold for latter heads.
在FPN探索如何设计更好的R-CNN颈部以使用骨干功能时,Cascade R-CNN研究了R-CNN分类和回归头的重新设计。 基本假设是简单而有见地的:准备正目标时使用的IOU标准越高,网络将学会做出的假正预测就越少。 但是,我们不能简单地将此类IOU阈值从常用的0.5提高到更具侵略性的0.7,因为它还可能导致训练过程中出现大量的负面案例。 Cascade R-CNN的解决方案是将多个检测头链接在一起,每个都将依赖于先前检测头的边界框建议。 仅第一个检测头将使用原始RPN建议。 这有效地模拟了后头的增加的IOU阈值。
2017: Mask R-CNN (2017: Mask R-CNN)
Mask R-CNN
Mask R-CNN
Mask R-CNN is not a typical object detection network. It was designed to solve a challenging instance segmentation task, i.e, creating a mask for each object in the scene. However, Mask R-CNN showed a great extension to the Faster R-CNN framework, and also in turn inspired object detection research. The main idea is to add a binary mask prediction branch after ROI pooling along with the existing bounding box and classification branches. Besides, to address the quantization error from the original ROI Pooling layer, Mask R-CNN also proposed a new ROI Align layer that uses bilinear image resampling under the hood. Unsurprisingly, both multi-task training (segmentation + detection) and the new ROI Align layer contribute to some improvement over the bounding box benchmark.
Mask R-CNN is not a typical object detection network. It was designed to solve a challenging instance segmentation task, ie, creating a mask for each object in the scene. However, Mask R-CNN showed a great extension to the Faster R-CNN framework, and also in turn inspired object detection research. The main idea is to add a binary mask prediction branch after ROI pooling along with the existing bounding box and classification branches. Besides, to address the quantization error from the original ROI Pooling layer, Mask R-CNN also proposed a new ROI Align layer that uses bilinear image resampling under the hood. Unsurprisingly, both multi-task training (segmentation + detection) and the new ROI Align layer contribute to some improvement over the bounding box benchmark.
2018: PANet (2018: PANet)
Path Aggregation Network for Instance Segmentation
Path Aggregation Network for Instance Segmentation
Instance segmentation has a close relationship with object detection, so often a new instance segmentation network could also benefit object detection research indirectly. PANet aims at boosting information flow in the FPN neck of Mask R-CNN by adding an additional bottom-up path after the original top-down path. To visualize this change, we have a ↑↓ structure in the original FPN neck, and PANet makes it more like a ↑↓↑ structure before pooling features from multiple layers. Also, instead of having separate pooling for each feature layer, PANet added an “adaptive feature pooling” layer after Mask R-CNN’s ROIAlign to merge (element-wise max of sum) multi-scale features.
Instance segmentation has a close relationship with object detection, so often a new instance segmentation network could also benefit object detection research indirectly. PANet aims at boosting information flow in the FPN neck of Mask R-CNN by adding an additional bottom-up path after the original top-down path. To visualize this change, we have a ↑↓ structure in the original FPN neck, and PANet makes it more like a ↑↓↑ structure before pooling features from multiple layers. Also, instead of having separate pooling for each feature layer, PANet added an “adaptive feature pooling” layer after Mask R-CNN's ROIAlign to merge (element-wise max of sum) multi-scale features.
2019: NAS-FPN (2019: NAS-FPN)
NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
PANet’s success in adapting FPN structure drew attention from a group of NAS researchers. They used a similar reinforcement learning method from the image classification network NASNet and focused on searching the best combination of merging cells. Here, a merging cell is the basic build block of an FPN that merges any two input features layers into one output feature layer. The final results proved the idea that FPN could use further optimization, but the complex computer-searched structure made it too difficult for humans to understand.
PANet's success in adapting FPN structure drew attention from a group of NAS researchers. They used a similar reinforcement learning method from the image classification network NASNet and focused on searching the best combination of merging cells. Here, a merging cell is the basic build block of an FPN that merges any two input features layers into one output feature layer. The final results proved the idea that FPN could use further optimization, but the complex computer-searched structure made it too difficult for humans to understand.
结论 (Conclusion)
Object detection is still an active research area. Although the general landscape of this field is well shaped by a two-stage detector like R-CNN and one-stage detector such as YOLO, our best detector is still far from saturating the benchmark metrics, and also misses many targets in complicated background. At the same time, Anchor-free detector like CenterNet showed us a promising future where object detection networks can become as simple as image classification networks. Other directions of object detection, such as few-shot recognition and NAS, are still at an early age, and we will see how it goes in the next few years. Nevertheless, as object detection technology becomes more mature, we need to be very cautious about its adoption by the military and police. A dystopia where Terminators hunt and shoot humans with a YOLO detector is the last thing we want to see in our life.
Object detection is still an active research area. Although the general landscape of this field is well shaped by a two-stage detector like R-CNN and one-stage detector such as YOLO, our best detector is still far from saturating the benchmark metrics, and also misses many targets in complicated background. At the same time, Anchor-free detector like CenterNet showed us a promising future where object detection networks can become as simple as image classification networks. Other directions of object detection, such as few-shot recognition and NAS, are still at an early age, and we will see how it goes in the next few years. Nevertheless, as object detection technology becomes more mature, we need to be very cautious about its adoption by the military and police. A dystopia where Terminators hunt and shoot humans with a YOLO detector is the last thing we want to see in our life.
Originally published at http://yanjia.li on Aug 9, 2020
Originally published at http://yanjia.li on Aug 9, 2020
深度学习之对象检测