数据分析
数据分析作用
在商业领域中,进行数据分析的目的是把隐藏在一大批看似杂乱无章的数据背后的信息集中和提炼出来,总结出所研究对象的内在规律,帮助管理者进行有效的判断和决策。数据分析在企业日常经营分析中主要有三大作用:
- 现状分析:告诉你当前的状况
- 原因分析:告诉你某一现状为什么发生
- 预测分析:告诉你将来会发生什么
数据分析基本步骤
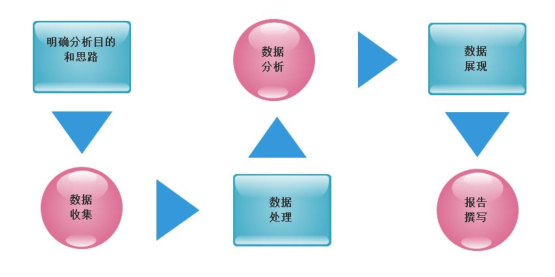
明确分析目的和思路:比如用户行为理论
用户行为轨迹 》》 用户的网站行为 》》 网站分析指标- 数据收集
一般数据来源主要有以下几种方式:数据库、公开出版物、互联网、市场调查 - 数据处理
数据处理主要包括 数据清洗、数据转化、数据提取、数据 计算等处理方法 - 数据分析
数据分析是指用适当的分析方法及工具,对处理过的数据进行分析,提取有价值的信息,形成有效结论的过程。
数据挖掘其实是一种高级的数据分析方法,一般来说,数据挖掘侧重解决四类数据分析问题:分类、聚类、关联和预测,重点在寻找模式和规律。 - 数据展现
一般情况下,数据是通过表格和图形的方式来呈现的 报告撰写
数据分析报告其实是对整个数据分析过程的一个总结与呈现。
一份好的数据分析报告,首先需要有一个好的分析框架,并且图文并茂,层次明晰,能够让阅读者一目了然。另外,数据分析报告需要有明确的结论。最后,好的分析报告一定要有建议或解决方案。
大数据分析系统
概念、分类
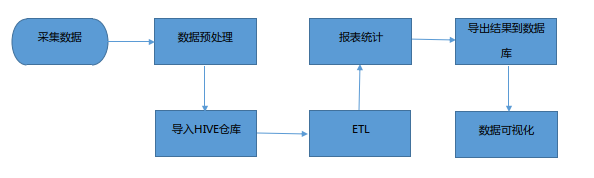
根据数据的流转流程,一般会有以下几个模块: 数据 收集(采集)、数据存储、 数据计算、数据分析、 数据展示等。
按照数据分析的时效性,我们一般会把大数据分析系统分为实时、离线两种类型。
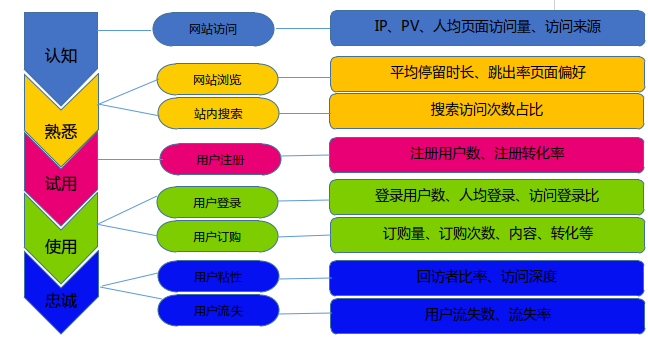
网站流量日志数据分析
- 系统的意义
改善网站的运营,获取更高投资回报率(ROI)。 也就是赚更多的钱 - 系统架构
- 数据采集:定制开发采集程序,或使用开源框架 Flume
- 数据预处理:定制开发 mapreduce 程序运行于 hadoop 集群
- 数据仓库技术:基于 hadoop 之上的 Hive
- 数据导出:基于 hadoop 的 sqoop 数据导入导出工具
- 数据可视化:定制开发 web 程序(echarts)或使用 kettle 等产品
- 整个过程的流程调度:hadoop 生态圈中的 azkaban 工具或其他类似 开源产品
- Web 访问日志
访问日志指用户访问网站时的所有访问、浏览、点击行为数据。
日志的生成渠道分为以下两种:
一是:web 服务器软件(httpd、nginx、tomcat)自带的日志记录功能,如 Nginx的 access.log 日志;
二是:自定义采集用户行为数据,通过在页面嵌入自定义的 javascript 代码来获取用户的访问行为,然后通过 ajax请求到后台记录日志,这种方式所能采集的信息会更加全面。
在实际操作中,有以下几个方面的数据可以自定义的采集:- 系统特征:比如所采用的操作系统、浏览器、域名和访问速度等。
- 访问特征:包括停留时间、点击的 URL、所点击的标签的属性等。
- 来源特征:包括来访 URL,来访 IP 等。
- 产品特征:包括所访问的产品编号、产品类别、产品颜色、产品价格、产品利润、产品数量和特价等级等。
网站流量日志数据自定义采集
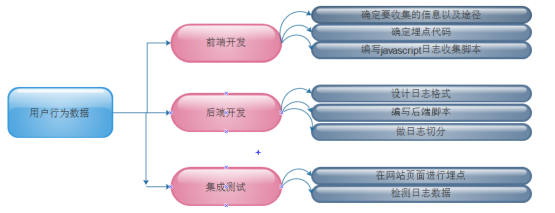
确定收集信息
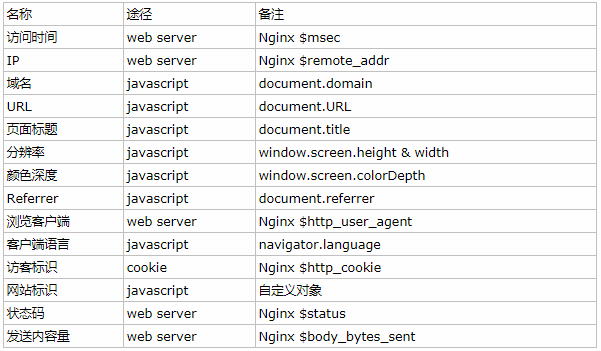
确定埋点代码
埋点是指:在网页中预先加入小段 javascript 代码,这个代码片段一般会动态创建一个 script 标签,并将 src 属性指向一个单独的 js 文件,此时这个单独的 js 文件(图中绿色节点)会被浏览器请求到并执行,这个 js 往往就是真正的数据收集脚本。
js自调用匿名函数格式: (function(){})();自调用匿名函数的好处是,避免重名,自调用匿名函数只会在运行时执行一次,一般用于初始化。
前端数据收集脚本
- 通过浏览器内置javascript对象收集信息
- 解析_maq 收集配置信息。
- 将上面两步收集的数据按预定义格式解析并拼接。
- 请求一个后端脚本,将信息放在 http request 参数中携带给后端脚本。一种通用的方法是 js 脚本创建一个 Image 对象,将 Image 对象的 src 属性指向后端脚本并携带参数,此时即实现了跨域请求后端。
后端脚本
- 解析 http 请求参数得到信息。
- 从 Web 服务器中获取一些客户端无法获取的信息,如访客 ip 等。
- 将信息按格式写入 log。
- 生成一副 1×1 的空 gif 图片作为响应内容并将响应头的 Content-type设为 image/gif。
- 在响应头中通过 Set-cookie 设置一些需要的 cookie 信息。
日志格式
日志分隔符:固定数量的字符、制表符分隔符、空格分隔符、其他一个或多个字符、特定的开始和结束文本。
日志切分
通过 crontab 定时调用一个 shell 脚本