三大编程范式
三大编程范式(这三者各有千秋,不分好坏):
面向过程编程
函数式编程
面向对象编程
面向过程编程
“面向过程”(Procedure Oriented)是一种以过程为中心的编程思想。
过程是指解决问题的步骤。例如问题:如何把大象放入一个冰箱?步骤:先打开冰箱,在将大象放入冰箱,最后关上冰箱。面向过程是一种较机械式的思维方式。
优点:
复杂的问题流程化,进而简单化(一个复杂的问题,分成一个个小的步骤去实现,实现小的步骤将会非常简单)。
性能比面向对象高,因为类调用时需要实例化,比较消耗资源
缺点:
没有面向对象易维护、易复用、易扩展
应用场景:
一旦完成基本很少改变的场景,著名的例子有Linux內核,git,以及Apache HTTP Server、嵌入式开发等
函数式编程
特点:不可变数据、第一类对象、尾调用
更多见:Python之旅(三)函数
面向对象编程
面向对象(Object Oriented,OO)是一种对现实世界理解和抽象的方法,是计算机编程技术发展到一定阶段后的产物。
对象是属性和方法结合体,与面向过程机械式的思维方式形成鲜明对比,面向对象更加注重对现实世界的模拟。
优点:
易维护、易复用、易扩展
缺点:
1. 复杂度远高于面向过程,新手极容易出现过度设计的问题。一些扩展性要求低的场景使用面向对象会徒增编程难度,比如管理linux系统的shell脚本就不适合用面向对象去设计,面向过程反而更加适合。
2. 无法向面向过程的程序设计流水线式的可以很精准的预测问题的处理流程与结果,面向对象的程序一旦开始就由对象之间的交互解决问题,即便是上帝也无法准确地预测最终结果。于是我们经常看到对
战类游戏,新增一个游戏人物,在对战的过程中极容易出现的bug技能,一刀砍死3个人,这种情况是无法准确预知的,只有对象之间交互才能准确地知道最终的结果。
应用场景:
需求经常变化的软件,一般需求的变化都集中在用户层,互联网应用,企业内部软件,游戏等都是面向对象的程序设计大显身手的好地方
面向对象的程序设计并不是全部。对于一个软件质量来说,面向对象的程序设计只是用来解决扩展性。
对编程的理解
最开始就是无组织无结构的,在简单控制流中按步写指令
从上述的指令中提取重复代码块或逻辑,组织到一起(比如函数),可以提高代码重用性,此时代码开始结构化,更具有逻辑性
但是只有函数的话,数据和方法(方法即函数-->操作数据的过程)不方便结合
当把数据和行为内嵌到一个东西(函数或类)里面,此时数据和行为就可以很好的结合,由此产生了“对象”的概念。对象就是数据和行为的结合体
类和对象
对象和类的理解
1在现实世界中:先有对象,再有类。
世界上肯定是先出现各种各样的客观存在的物体,然后随着人类文明的发展,人类站在不同的角度总结出了不同的种类,如人类、动物类、植物类等概念.
也就说,对象是具体的存在,而类仅仅只是一个抽象化的概念,并不真实存在
2在程序中:务必保证先定义类,后产生对象
这与函数的使用是类似的,先定义函数,后调用函数,类也是一样的,在程序中需要先定义类,后调用类
不一样的是,调用函数会执行函数体代码返回的是函数体执行的结果,而调用类会产生对象,返回的是对象
类:将一种事物的共同点(共同属性、共同行为)提取并整合到一起就形成了类
对象:类的具体化产物,即通过类产生一个对象,这个过程就是实例化,对象也称为实例
面向对象设计与面向对象编程
面向对象设计(Object oriented design)将一类事物的数据和行为整合到一起
面向对象编程(object-oriented programming)用定义类 + 对象/实例 的方式实现面向对象的设计
1 # 面向对象设计 2 def dog(name, color, type): 3 def init(name, color): 4 dic = { 5 'color':color, 6 'name':name, 7 'type':type, 8 'run':run, 9 'bark':bark, 10 } 11 return dic 12 13 def bark(dog): 14 print('{} can bark'.format(name)) 15 16 def run(dog): 17 print('{} can run'.format(name)) 18 19 return init(name, color) 20 21 dog01 = dog('xiaohuang', 'yellow', '藏獒') 22 print(dog01) 23 24 print(dog01['name'], dog01['color']) 25 dog01['run'](dog01) 26 27 # 执行结果 28 # {'color': 'yellow', 'name': 'xiaohuang', 'type': '藏獒', 'run': <function dog.<locals>.run at 0x00BA38A0>, 'bark': <function dog.<locals>.bark at 0x00BA3858>} 29 # xiaohuang yellow 30 # xiaohuang can run
# 面向对象编程 class dog(): """定义一个有狗有关的类,能跑能吠""" subject = '动物界 / 脊索动物门 / 哺乳纲 / 食肉目 / 犬科' # 类的数据属性-->类变量 def bark(): #类的函数属性-->方法 print('can bark' ) def run(self): print('can run') print(dog.__dict__) #查看所有属性名和属性值组成的字典 print(dog.subject) #访问类变量,本质就是通过__dict__来实现这个过程 print(dog.__dict__['subject']) dog.bark() #调用类的函数属性-->方法,本质也是通过__dict__来实现 dog.__dict__['bark']() print(dog.__module__) #__main__ print(dog.__name__) #dog print(dog.__doc__) #定义一个有狗有关的类,能跑能吠 # #python为类内置的特殊属性 # 类名.__name__# 类的名字(字符串) # 类名.__doc__# 类的文档字符串 # 类名.__base__# 类的第一个父类 # 类名.__bases__# 类所有父类构成的元组 # 类名.__dict__# 类的字典属性 # 类名.__module__# 类定义所在的模块 # 类名.__class__# 实例对应的类(仅新式类中)
实例化
1 class dog(): 2 """定义一个有狗有关的类,能跑能吠""" 3 subject = '动物界 / 脊索动物门 / 哺乳纲 / 食肉目 / 犬科' 4 5 def __init__(self, name, color, type): #用于对象的初始化 6 self.name = name #实例属性 7 self.color = color 8 self.type = type 9 10 def bark(self): 11 print('%s can bark' %(self.name)) 12 13 def run(self): 14 print(' can run') 15 16 #类名加上括号就是在实例化,创建了一个对象(可以理解为函数的运行,返回值就是一个实例) 17 #实例化会自动调用__init__函数,创建对象需要的参数会自动传给__init__函数 18 dog1 = dog('小黄', 'yello', '藏獒') 19 20 print(dog1.__dict__) #这里查看了dog1这个对象的属性字典 21 22 print(dog1.subject) #对象可以访问到类变量。在dog1对象的属性字典中找不到会去类变量中找 23 24 dog.bark(dog1) #通过类调用类方法 25 dog1.bark() #通过实例调用类方法,实例中是没有这个方法的,会到类中找到该方法,这样可以减少内存的占用 26 # dog1.bark(dog1) #此处会报错,因为实例调用类方法时class会自动将d实例dog1传给self参数
类变量和实例变量
类变量:


1 class dog(): 2 """定义一个有狗有关的类,能跑能吠""" 3 subject = '动物界 / 脊索动物门 / 哺乳纲 / 食肉目 / 犬科' 4 5 def __init__(self, name, color, type): #用于对象的初始化 6 self.name = name #实例属性 7 self.color = color 8 self.type = type 9 10 def bark(self): 11 print('%s can bark' %(self.name)) 12 13 def run(self): 14 print(' can run') 15 16 17 # 类属性的相关操作 18 print(dog.subject) #查看类属性 19 20 dog.subject = '犬科' #修改类属性 21 print(dog.subject) 22 dog1 = dog('小黄', 'yellow', '藏獒') 23 print(dog1.__dict__) 24 print(dog1.subject) #实例变量可以访问到类属性 25 26 dog.friend = 'human' #增加类属性 27 print(dog.friend) 28 def eat_meat(self): 29 print('eat meat') 30 dog.eat = eat_meat 31 dog1.eat() 32 print(dog.__dict__) #查看类的属性字典 33 34 del dog.friend #删除类属性 35 del dog.eat 36 print(dog.__dict__)
实例变量:
1 class dog(): 2 """定义一个有狗有关的类,能跑能吠""" 3 subject = '动物界 / 脊索动物门 / 哺乳纲 / 食肉目 / 犬科' 4 5 def __init__(self, name, color, type): #用于对象的初始化 6 self.name = name #实例属性 7 self.color = color 8 self.type = type 9 10 def bark(self): 11 print('%s can bark' %(self.name)) 12 13 def run(self): 14 print(' can run') 15 16 17 dog1 = dog('小黄', 'yello', '藏獒') #创建实例 18 print(dog1.__dict__) 19 20 # 查看实例属性 21 print(dog1.name) 22 print(dog1.run) 23 dog1.run() 24 25 # 增加实例属性 26 dog1.age = 4.5 27 print(dog1.age) 28 29 # 不要修改底层的字典属性 30 # dog1.__dict__['name'] = '大黄' 31 # print(dog1.__dict__) 32 33 # 修改实例属性 34 dog1.age = 5 35 print(dog1.age) 36 37 # 删除实例属性 38 del dog1.age
类变量与实例变量注意点:
使用类名或实例名加 . 点时,对变量只搜找到类,类里没有找到就报错
1 class dog(): 2 """定义一个有狗有关的类,能跑能吠""" 3 subject = '食肉目 / 犬科' 4 x = ['a', 'b'] 5 6 def __init__(self, name): 7 self.name = name #实例属性 8 def bark(self): 9 print('%s can bark' %(self.name)) 10 11 12 dog1 = dog("小黄") 13 print(dog1.subject) #食肉目 / 犬科 14 15 #会在实例的属性中添加新变量,不会影响同名的类属性 16 dog1.subject = '狗科' 17 print(dog1.subject) #狗科 18 19 print(dog.subject) #食肉目 / 犬科 20 21 dog2 = dog('小蓝') 22 print(dog2.subject) #食肉目 / 犬科 23 24 # 追加类变量的值 25 dog1.x.append(1) 26 print(dog1.x) #['a', 'b', 1] 27 print(dog.x) #['a', 'b', 1] 28 print(dog2.x) #['a', 'b', 1]
1 area = 'asia' 2 class dog(): 3 """定义一个有狗有关的类,能跑能吠""" 4 subject = '食肉目 / 犬科' 5 6 def __init__(self, name): 7 self.name = name #实例属性 8 print('area', area) 9 def bark(self): 10 print('%s can bark' %(self.name)) 11 12 # 使用类名或实例名加 . 点时对变量只搜找到类,类里没有找到就报错 13 dog1 = dog('小黄') 14 print(dog1.area) #AttributeError: 'dog' object has no attribute 'area'
1 area = 'asia' 2 class dog(): 3 """定义一个有狗有关的类,能跑能吠""" 4 subject = '食肉目 / 犬科' 5 area = 'europen' 6 def __init__(self, name): 7 self.name = name 8 print('area:', area) #没加 点号,访问不到类中的area 9 def bark(self): 10 print('%s can bark' %(self.name)) 11 12 dog1 = dog('小黄') 13 # 运行结果 14 # area:asia
静态变量、类方法、静态方法
静态变量
可以封装一个函数的内部逻辑,实例对这个函数的调用变得和对属性的调用一样。
既可以访问实例属性,也可以访问类属性
@property
类方法
类方法是可以使用类名直接调用的方法,不用传入实例
不能访问实例属性
@classmethod
静态方法
静态方法只是作为类的工具包
不能访问实例属性和类属性
@staticmethod
class box():
"""描述箱子的类"""
use = '装货物'
def __init__(self, type, long, width, height):
self.type = type
self.long = long
self.width = width
self.height = height
def load_things(self):
print('{} 能用来装东西'.format(self.type))
#静态变量可以封装这个函数的内部逻辑,让实例对这个方法的调用和对属性的调用变得一样
# 既可以访问实例属性,也可以访问类属性
@property
def cal_valume(self):#对自动将实例本身传给self
return self.long*self.width*self.height
#类方法可以让类直接调用其中的方法
# 不能访问实例属性
@classmethod
def use_print(cls):#会自动被类本身传给cls
print(cls)
print(cls.use)
# 静态方法只是作为类的工具包使用
# 不能访问类属性和实例属性
@staticmethod
def sta_print(a, b, c):
print(a,b,c)
box1 = box('纸箱', 10, 20, 30)
print(box1.type)
box1.load_things()#普通方法
print(box1.cal_valume)# 静态变量
box.use_print()#类方法
box.sta_print(1,2,3)#静态方法继承与派生
继承
父类又称作基类,子类也称作派生类
继承可以提高代码复用性
单继承,多继承
1 class Fat(): 2 """用来描述父类的类""" 3 money = 1000 4 def __init__(self, name): 5 self.name = name 6 print('这是fat类中的一个实例属性:{}'.format(name)) 7 8 class Mot(): 9 """mot类""" 10 pass 11 12 class Dau(Mot): #单继承 13 pass 14 15 class Son(Fat, Mot): #多继承 16 money = 1
继承原理
对于你定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个简单的所有基类的线性顺序列表
__mro__
继承顺序:
python3中都是广度优先
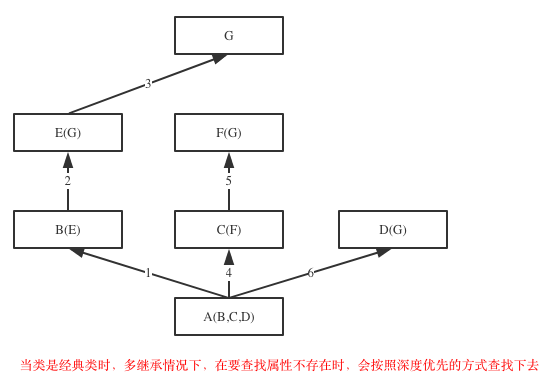
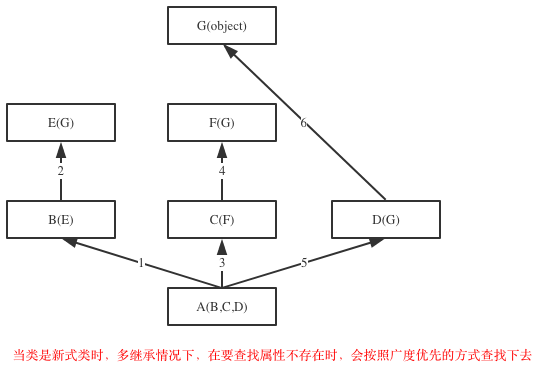
查看父类
__base__只查看从左到右继承的第一个父类
__bases__则是查看所有继承的父类
#__base__只查看从左到右继承的第一个父类,__bases__则是查看所有的父类 print(Son.__base__) #<class '__main__.Fat'> print(Son.__bases__) #(<class '__main__.Fat'>, <class '__main__.Mot'>
经典类和新式类
1.只有在python2中才分新式类和经典类,python3中统一都是新式类
2.在python2中,没有显式的继承object类的类,以及该类的子类,都是经典类
3.在python2中,显式地声明继承object的类,以及该类的子类,都是新式类
3.在python3中,如果没有指定基类,python的类会默认继承object类,object是所有python类的基类,即python3中所有类均为新式类
先抽象再继承
抽象:提取共同点
继承:实现抽象中的共同点
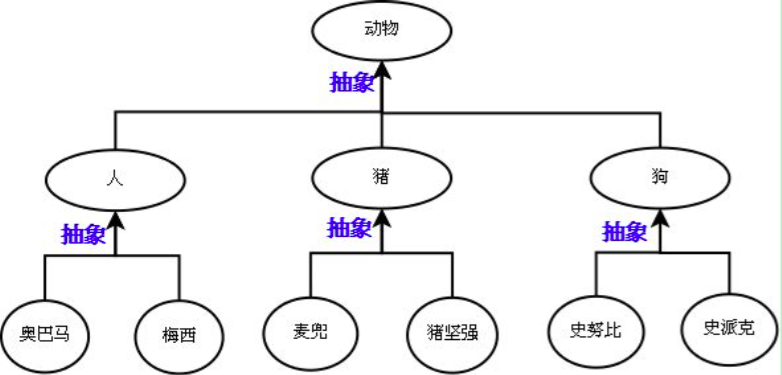
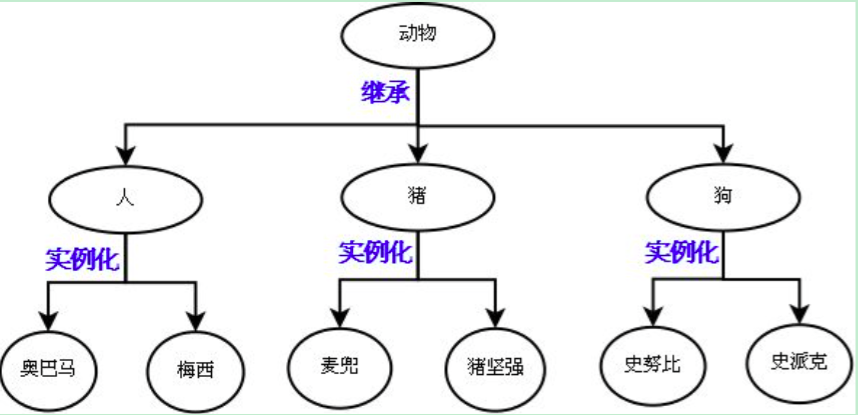
派生
子类实例找不到的属性会到父类中找
子类实例中可以找到的属性就不会到父类中找
子类中也可以定义新的属性(不会影响到父类)
1 class Fat(): 2 """用来描述父类的类""" 3 money = 1000 4 def __init__(self, name): 5 self.name = name 6 print('这是fat类中的一个实例属性:{}'.format(name)) 7 class Son(Fat): 8 money = 1 9 10 # s1= Son() #报错,子类中找不到__init__,会到父类中找 11 s1= Son('Lin') 12 print(s1.money) #子类中找到了money,就不会去父类中找
组合与继承
组合:在一个类中把另一个类的对象作为实例变量的值
作用:可以提高代码复用性
1 class School(): 2 def __init__(self, name, adr): 3 self.name = name 4 self.adr = adr 5 6 class Teacher(): 7 def __init__(self, name, school): 8 self.name = name 9 self.school =school 10 11 class Course(): 12 def __init__(self, name, school, teacher): 13 self.name = name 14 self.school = school 15 self.teacher = teacher 16 17 s1 = School('清华', '北京') 18 t1 = Teacher('李老师', s1) #将对象作为参数传入另一个对象,让这两个有了一定的关联 19 c1 = Course('计算机基础', s1, t1) 20 21 print('由{2}大学开办的{0}课程,授课老师:{1}'.format(c1.name, c1.teacher.name, c1.school.name))
组合和继承:
1.继承的方式
通过继承建立了派生类与基类之间的关系,它是一种'是'的关系,比如白马是马,人是动物。
当类之间有很多相同的功能,提取这些共同的功能做成基类,用继承比较好,比如老师是人,学生是人
2.组合的方式
用组合的方式建立了类与组合的类之间的关系,它是一种‘有’的关系,比如教授有生日,教授教python和linux课程,教授有学生s1、s2、s3...
当类之间有显著不同,并且较小的类是较大的类所需要的组件时,用组合比较好
接口与归一化
接口提取了一群类共同的函数,在接口中可以不用写这些函数的内部逻辑。可以把接口当做一个函数的集合。然后让子类去具体实现接口中的函数。
归一化:接口用于规范子类,强制要求子类中必须要实现的函数
归一化作用:
归一化让使用者无需关心对象的类是什么,只需要的知道这些对象都具备某些功能就可以了,这极大地降低了使用者的使用难度。
归一化使得高层的外部使用者可以不加区分的处理所有接口兼容的对象集合
利用继承实现接口:
1 import abc 2 3 # 接口继承,被修饰的函数要求在子类中必须声明,否则子类在创建对象时会报错 4 # 接口中被修饰的函数不用写内部逻辑,接口用于规范子类,强制要求子类中必须编写哪些函数 5 class Animal(metaclass=abc.ABCMeta): 6 @abc.abstractmethod 7 def run(self): 8 pass 9 10 @abc.abstractmethod 11 def jiao(self): 12 pass 13 14 class Dog(Animal): 15 def run(self): 16 print('狗跑') 17 def jiao(self): 18 print('汪汪汪') 19 20 class Cat(Animal): 21 def run(self): 22 pass 23 def jiao(self): 24 print('喵喵喵') 25 26 27 d1 = Dog() 28 c1 = Cat() 29 c1.jiao()
子类中调用父类的方法
一、使用 父类名.父类方法()
1 #_*_coding:utf-8_*_ 2 __author__ = 'Linhaifeng' 3 4 class Vehicle: #定义交通工具类 5 Country='China' 6 def __init__(self,name,speed,load,power): 7 self.name=name 8 self.speed=speed 9 self.load=load 10 self.power=power 11 12 def run(self): 13 print('开动啦...') 14 15 class Subway(Vehicle): #地铁 16 def __init__(self,name,speed,load,power,line): 17 Vehicle.__init__(self,name,speed,load,power) #使用父类名 18 self.line=line 19 20 def run(self): 21 print('地铁%s号线欢迎您' %self.line) 22 Vehicle.run(self) 23 24 line13=Subway('中国地铁','180m/s','1000人/箱','电',13) 25 line13.run()
二、super()
1 class Vehicle: #定义交通工具类 2 Country='China' 3 def __init__(self,name,speed,load,power): 4 self.name=name 5 self.speed=speed 6 self.load=load 7 self.power=power 8 9 def run(self): 10 print('开动啦...') 11 12 class Subway(Vehicle): #地铁 13 def __init__(self,name,speed,load,power,line): 14 #super(Subway,self) 就相当于实例本身 在python3中super()等同于super(Subway,self) 15 super().__init__(name,speed,load,power) 16 self.line=line 17 18 def run(self): 19 print('地铁%s号线欢迎您' %self.line) 20 super(Subway,self).run() 21 22 class Mobike(Vehicle):#摩拜单车 23 pass 24 25 line13=Subway('中国地铁','180m/s','1000人/箱','电',13) 26 line13.run()
二者推荐使用super(),不要混合使用这两个
1 #指名道姓 2 class A: 3 def __init__(self): 4 print('A的构造方法') 5 class B(A): 6 def __init__(self): 7 print('B的构造方法') 8 A.__init__(self) 9 10 11 class C(A): 12 def __init__(self): 13 print('C的构造方法') 14 A.__init__(self) 15 16 17 class D(B,C): 18 def __init__(self): 19 print('D的构造方法') 20 B.__init__(self) 21 C.__init__(self) 22 23 pass 24 f1=D() #A.__init__被重复调用 25 ''' 26 D的构造方法 27 B的构造方法 28 A的构造方法 29 C的构造方法 30 A的构造方法 31 ''' 32 33 34 #使用super() 35 class A: 36 def __init__(self): 37 print('A的构造方法') 38 class B(A): 39 def __init__(self): 40 print('B的构造方法') 41 super(B,self).__init__() 42 43 44 class C(A): 45 def __init__(self): 46 print('C的构造方法') 47 super(C,self).__init__() 48 49 50 class D(B,C): 51 def __init__(self): 52 print('D的构造方法') 53 super(D,self).__init__() 54 55 f1=D() #super()会基于mro列表,往后找 56 ''' 57 D的构造方法 58 B的构造方法 59 C的构造方法 60 A的构造方法 61 '''
当你使用super()函数时,Python会在MRO列表上继续搜索下一个类。只要每个重定义的方法统一使用super()并只调用它一次,那么控制流最终会遍历完整个MRO列表,每个方法也只会被调用一次(注意注意注意:使用super调用的所有属性,都是从MRO列表当前的位置往后找,千万不要通过看代码去找继承关系,一定要看MRO列表)
多态
多态:不同类的对象可以调用相同的方法
例如python的__len__,列表和字符类的对象都可以调用该函数
1 # 多态:不同类的对象可以调用相同的方法 2 class H2o(): 3 def __init__(self, type, temperature): 4 self.type = type 5 self.temperature = temperature 6 7 def turn_type(self): 8 if self.temperature < 0 : 9 print('[{}]当温度低于0摄氏度,结成冰'.format(self.type)) 10 elif self.temperature > 0 and self.temperature < 100: 11 print('[{}]当温度在1-100℃,变成液态水'.format(self.type)) 12 elif self.temperature > 100: 13 print('[{}]当温度高于100℃,变成水蒸气'.format(self.type)) 14 class Water(H2o): 15 def __init__(self, temperature): 16 super().__init__('水', temperature) 17 18 class Ice(H2o): 19 def __init__(self, temperature): 20 super().__init__('冰', temperature) 21 22 class Steam(H2o): 23 def __init__(self, temperature): 24 super().__init__('水蒸气', temperature) 25 26 w1 = Water(-20) 27 i1 = Ice(-30) 28 s1 = Steam(101) 29 30 w1.turn_type() #[水]当温度低于0摄氏度,结成冰 31 i1.turn_type() #[冰]当温度低于0摄氏度,结成冰 32 s1.turn_type() #[水蒸气]当温度高于100℃,变成水蒸气 33 34 35 def turn(x): 36 x.turn_type() 37 38 turn(w1) 39 turn(i1) 40 turn(s1) 41 42 # python3中的多态 43 lis = [1, 2, 3, 4] 44 st = 'hello' 45 print(len(lis)) 46 print(len(st))
多态好处:
增加程序的灵活性。以不变应万变,不论对象千变万化,使用者都是同一种形式去调用,len()
增加程序的可拓展性。
封装
封:隐藏 装:放入
例如 python3内置函数len(),作为使用者在调用这个函数时只知道它是用来做什么的,但是不清楚它内部具体的实现方法,这就是封装
封装的表现形式:
类、私有化变量(将变量隐藏,让外部不能访问)
其他
类和私有化变量都没有真正意义上限制我们对数据的访问,不是真正意义上的封装
真正的封装:
封装的真谛在于明确地区分内外,封装的属性只可以直接在内部使用,而不能被外部直接使用,然而定义属性的目的终归是要用,外部要想用类中隐藏的属性,需要我们为其开辟接口(定义接口函数),让外部能够间接地用到我们隐藏起来的属性,
私有变量
-
xx:公有变量
-
_xx:单前置下划线,私有化属性或方法,类对象和子类可以访问,from somemodule import *禁止导入
-
__xx:双前置下划线,私有化属性或方法,无法在外部直接访问(名字重整所以访问不到)
-
__xx__:双前后下划线,系统定义名字(不要自己发明这样的名字)
-
xx_:单后置下划线,用于避免与Python关键词的冲突
python并不会真的阻止你访问私有的属性,模块也遵循这种约定,例如:如果模块名以单下划线开头,那么from module import *时不能被导入,但是你from module import _private_module依然是可以导入的
1 class H2o(): 2 sub = '化学' 3 _sub = '一个下划线的sub' 4 __sub = '两个下划线的sub' 5 def __init__(self): 6 pass 7 # def turn_type(self): 8 # if self.temperature < 0 : 9 # print('[{}]当温度低于0摄氏度,结成冰'.format(self.type)) 10 # elif self.temperature > 0 and self.temperature < 100: 11 # print('[{}]当温度在1-100℃,变成液态水'.format(self.type)) 12 # elif self.temperature > 100: 13 # print('[{}]当温度高于100℃,变成水蒸气'.format(self.type)) 14 15 16 print(H2o.sub) 17 18 print(H2o._sub) 19 20 #print(h1.__sub) #报错,__dict__中没有这个属性,python自动为其重命名 21 print(H2o.__dict__) 22 print(H2o._H2o__sub) #_sub 重命名为 _H2o__sub