更多深度文章,请关注:https://yq.aliyun.com/cloud
今天我们来介绍一下如何使用(opencv/python)来实现OCR处理银行票据。文末有代码和相关文档下载!
在第一部分中,我们将讨论两个主题:
1. 首先,我们将了解MICR E-13B字体,美国,英国,加拿大等国家用于支票上都是使用的这种字体。
2. 其次,我们将讨论如何从MICR E-13B参考图像中提取数字和符号。这将使我们能够提取每个字符的ROI,然后将其用于OCR银行支票。
MICR E-13B 字体:

MICR(磁墨字符识别)是处理文件的金融工业技术。
MICR的E-13B变体包含14个字符:
· 数字:数字0-9。
· ⑆过境:银行分行分隔。
· ⑇金额:交易金额分隔符。
· ⑈在我们:客户帐号分隔符。
· ⑉dash:数字分隔符(例如路由和帐号之间)。
银行支票字符识别看起来更难:

在银行支票上使用的MICR E-13B字体中,数字有一个轮廓。但是,控制符号对于每个角色具有三个轮廓,使任务稍微更具挑战性。我们不能使用简单的轮廓和边框方法。相反,我们需要设计自己的方法来可靠地提取数字和符号。
用OpenCV提取MICR数字和符号:
创建一个新的文件,命名为bank_check_ocr.py,并插入以下代码:
# import the necessary packages
from skimage.segmentation import clear_border
from imutils import contours
import numpy as np
import argparse
import imutils
import cv2
首先我们先导入各种我们需要的包,以确保程序的正确运行
· OpenCV:从此页面选择适合您系统的安装版本。
· scikit-image :这是通过pip安装的, pip install -U scikit-image
· numpy :通过 pip install numpy。
· imutils :这是可以通过 pip 安装: pip install --upgrade imutils。
接着我们来构建一个从MICR字体中提取字符的函数:
def extract_digits_and_symbols(image, charCnts, minW=5, minH=15):
charIter = charCnts.__iter__()
rois = []
locs = []
对于初学者,我们的功能需要4个参数:
· image:MICR E-13B字体图像(代码下载中提供)。
· charCnts:包含参考图像中的字符轮廓的列表。
· minW :表示最小字符宽度的可选参数。默认值为5像素宽度。
· minH :最小字符高度。默认值为15像素。
接着我们初始化我们的charCnts列表的迭代器。列表对象本质上是“可迭代的”,意味着__iter__方法是由生成器完成的。
最后初始化空列表以保存我们的rois(感兴趣的区域)和loc(ROI位置)。我们将在函数结尾的一个元组中返回这些列表。
我们开始循环,看一下迭代器的工作原理:
while True:
try:
c = next(charIter)
(cX, cY, cW, cH) = cv2.boundingRect(c)
roi = None
在我们的函数中,我们开始一个无限循环,我们的退出条件是当我们捕获 StopIterator异常时。为了捕获这个异常,我们需要设置try-catch块。对于循环的每次迭代,我们通过调用next(charIter)来获取下一个字符轮廓。从这个函数调用,我们可以提取矩形的(x,y)坐标和宽度/高度。接着我们初始化一个roi,我们将在短时间内存储字符图像。
接下来,我们将检查我们的边框宽度和高度的大小,并采取相应的措施:
if cW >= minW and cH >= minH:
roi = image[cY:cY + cH, cX:cX + cW]
rois.append(roi)
locs.append((cX, cY, cX + cW, cY + cH))如果字符计数器的尺寸分别大于或等于最小宽度和高度,我们采取以下措施:
1. 使用我们的边界矩形调用的坐标和width / height从图像中提取roi。将roi添加到rois 。
3. 向locs附加一个元组。该元组由矩形的两个角的(x,y)坐标组成。稍后我们将返回这个位置列表。
否则,我们假设我们正在使用MICRE-13B字符符号,需要应用更高级的一组处理操作:
else:
parts = [c, next(charIter), next(charIter)]
(sXA, sYA, sXB, sYB) = (np.inf, np.inf, -np.inf,-np.inf)
for p in parts:
(pX, pY, pW, pH) = cv2.boundingRect(p)
sXA = min(sXA, pX)
sYA = min(sYA, pY)
sXB = max(sXB, pX + pW)
sYB = max(sYB, pY + pH)
roi = image[sYA:sYB, sXA:sXB]
rois.append(roi)
locs.append((sXA, sYA, sXB, sYB))
if-else的else块具有分析包含在MICR E-13B字体中的多个轮廓的特殊符号的逻辑。我们做的第一件事就是建立符号的部分。正如我们需要知道一个具有一个轮廓角色的边框,我们需要知道包含三个轮廓的角色的边框。为了实现这一点,通过sYB初始化四个边界框参数sXA。
现在我们将循环遍历表示一个字符/符号的部分列表。使用边界矩形参数,我们比较和计算与先前值相关的最小值和最大值。这是我们首先通过 sYB 将sXA初始化为正/负无限值的原因。
现在我们已经找到了围绕符号的框的坐标,我们从图像中提取出roi,将roi附加到rois,并将框坐标元组附加到locs
我们函数的剩余代码块处理我们的while循环退出条件和return语句。
Except StopIteration:
break
return (rois, locs)如果在charIter(我们的iterator对象)上调用next来抛出一个StopIteration异常,那么说明我们已经到达了最后一个轮廓。
现在我们已经准备好解析命令行参数并继续执行脚本:
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-r", "--reference", required=True,
help="path to reference MICR E-13B font")
args = vars(ap.parse_args())
在上面的代码中,我们建立了两个必需的命令行参数:
· - image:我们的查询图像。
· - reference :我们的参考MICR E-13B字体图像。
接下来,我们将为每个符号/字符创建“名称”,并将其存储在列表中。
charNames = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "0", "T", "U", "A", "D"]上面的代码很简单,我们只是在参考图像中从左到右建立了我们遇到的符号的名称。
注意:由于OpenCV不支持unicode中的绘图字符,因此需要定义“T”表示transit,“U”表示“on-us”,“A”表示amount,“D”表示dash。
接下来,我们将参考图像加载到内存中,并执行一些预处理:
ref = cv2.imread(args["reference"])
ref = cv2.cvtColor(ref, cv2.COLOR_BGR2GRAY)
ref = imutils.resize(ref, width=400)
ref = cv2.threshold(ref, 0, 255, cv2.THRESH_BINARY_INV |cv2.THRESH_OTSU)[1]
在上面的代码中,我们完成了四个任务:
1. 加载 图像到存储器中作为 参考。
2. 图片转换为灰度级。
3. 调整 width=400 。
4. 使用Otsu方法的二进制逆阈值。
这些简单操作的结果可以在下图中看到:

其余的代码遍历分为两部分。首先,我将向您展示一个逻辑和简单的轮廓方法以及生成的图像。
然后,我们将继续使用更高级的方法,利用我们在脚本顶部写的函数extract_digits_and_symbols 。
对于这两个部分,我们将使用一些常见的数据,包括ref(参考图像,我们刚刚预处理的)和refCnt(参考轮廓,我们即将提取)。
refCnts = cv2.findContours(ref.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
refCnts = refCnts[0] if imutils.is_cv2() else refCnts[1]
refCnts = contours.sort_contours(refCnts, method="left-to-right")[0]
clone = np.dstack([ref.copy()] * 3)
# loop over the (sorted) contours
for c in refCnts:
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(clone, (x, y), (x + w, y + h), (0, 255, 0), 2)
# show the output of applying the simple contour method
cv2.imshow("Simple Method", clone)
cv2.waitKey(0)
要从参考图像中提取轮廓,我们利用OpenCV的cv2 .findContours函数
接下来,我们要绘制图像,所以我们将所有频道复制到上称为克隆的图像。在显示结果之前,简单轮廓方法的最后一步是循环遍历排序轮廓。在这个循环中,我们计算每个轮廓的边界框,然后在其周围绘制一个矩形。通过显示图像显示结果并在此处暂停直到按下一个键参见图4
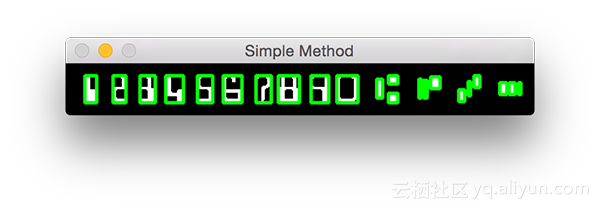
你看到这种方法的问题吗?问题是我们有22个边框,而不是所需的14个边界轮廓(每个角色一个)。显然,这个问题可以通过更先进的方法来解决。
更先进的方法如下所示和描述
(refROIs, refLocs) = extract_digits_and_symbols(ref, refCnts,
minW=10, minH=20)
chars = {}
clone = np.dstack([ref.copy()] * 3)
for (name, roi, loc) in zip(charNames, refROIs, refLocs):
# draw a bounding box surrounding the character on the output
# image
(xA, yA, xB, yB) = loc
cv2.rectangle(clone, (xA, yA), (xB, yB), (0, 255, 0), 2)
# resize the ROI to a fixed size, then update the characters
# dictionary, mapping the character name to the ROI
roi = cv2.resize(roi, (36, 36))
chars[name] = roi
# display the character ROI to our screen
cv2.imshow("Char", roi)
cv2.waitKey(0)
# show the output of our better method
cv2.imshow("Better Method", clone)
cv2.waitKey(0)
我们初始化一个空字典,chars,它将保存每个符号的name和roi。我们通过用新的ref副本覆盖clone图像来执行此操作(以摆脱刚刚绘制的矩形)。
最后在for循环的主体中,首先我们为clone图像中的每个角色绘制一个矩形 。
其次,我们调整roi到36像素和从词典的roi和name 的键值对,更新我们的chars。最后一步(主要用于调试/开发目的)是在屏幕上显示每个 roi,直到按下一个键。所产生的“更好的方法”图像显示在屏幕,直到按下一个键,并且结束了我们的脚本。
数字和符号提取结果:
现在我们已经编码了我们的MICR E-13B数字和符号提取器,让我们试一试。
从那里执行以下脚本:
$ python bank_check_ocr.py --image example_check.png \
--reference micr_e13b_reference.png总结
我们可以看到OCR的银行支票比OCR的信用卡更难识别,主要是由于银行支票符号由多个部分组成。我们不能假设我们的引用字体图像中的每个轮廓映射到一个单独的角色。
相反,我们需要插入额外的逻辑来检查每个轮廓的尺寸,并确定我们正在检查数字或符号。在我们找到一个符号的情况下,我们需要抓住下两个轮廓来构建我们的边界框(因为银行检查控制字符由三个不同的部分组成)。
希望上述的介绍能够帮助到你!
本文由北邮@爱可可-爱生活老师推荐,@阿里云云栖社区组织翻译。
文章原标题《Bank check OCR with OpenCV and Python | PyImageSearch》
作者:Adrian Rosebrock译者:袁虎 审阅:
文章为简译,更为详细的内容,请查看原文