目录
镜像的分层特性
在说docker的文件系统之前,我们需要先想清楚一个问题。我们知道docker的启动是依赖于image,docker在启动之前,需要先拉取image,然后启动。多个容器可以使用同一个image启动。那么问题来了:这些个容器是共用一个image,还是各自将这个image复制了一份,然后各自独立运行呢?
我们假设每个容器都复制了一份这个image,然后各自独立运行,那么就意味着,启动多少个容器,就需要复制多少个image,毫无疑问这是对空间的一种巨大浪费。事实上,在容器的设计当中,通过同一个Image启动的容器,全部都共享这个image,而并不复制。那么问题又随之而来:既然所有的容器都共用这一个image,那么岂不是我在任意一个容器中所做的修改,在其他容器中都可见?如果我一个容器要将一个配置文件修改成A,而另一个容器同样要将这个文件修改成B,两个容器岂不是会产生冲突?
我们把上面的问题放一放,先来看下面一个拉取镜像的示例:
root@ubuntu:~# docker pull nginx
Using default tag: latest
latest: Pulling from library/nginx
be8881be8156: Pull complete
32d9726baeef: Pull complete
87e5e6f71297: Pull complete
Digest: sha256:6ae5dd1664d46b98257382fd91b50e332da989059482e2944aaa41ae6cf8043a
Status: Downloaded newer image for nginx:latest上面的示例是从docker官方镜像仓库拉取一个nginx:latest镜像,可以看到在拉取镜像时,是一层一层的拉取的。事实上镜像也是这么一层一层的存储在磁盘上的。通常一个应用镜像包含多层,如下:
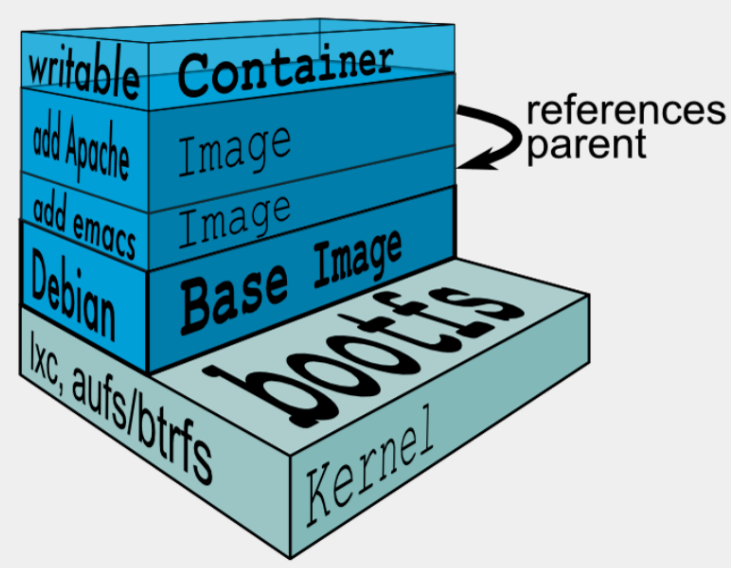
我们首先需要明确一点,镜像是只读的。每一层都只读。在上图上,我们可以看到,在内核之上,最底层首先是一个基础镜像层,这里是一个ubuntu的基础镜像,因为镜像的只读特性,如果我们想要在这个ubuntu的基础镜像上安装一个emacs编辑器,则只能在基础镜像之上,在构建一层新的镜像层。同样的道理,如果想要在当前的emacs镜像层之上添加一个apache,则只能在其上再构建一个新的镜像层。而这即是镜像的分层特性。
容器读写层的工作原理
我们刚刚在说镜像的分层特性的时候说到镜像是只读的。而事实上当我们使用镜像启动一个容器的时候,我们其实是可以在容器里随意读写的,从结果上看,似乎与镜像的只读特性相悖。
我们继续看上面的图,其实可以看到在镜像的最上层,还有一个读写层。而这个读写层,即在容器启动时为当前容器单独挂载。每一个容器在运行时,都会基于当前镜像在其最上层挂载一个读写层。而用户针对容器的所有操作都在读写层中完成。一旦容器销毁,这个读写层也随之销毁。
知识点: 容器=镜像+读写层
而我们针对这个读写层的操作,主要基于两种方式:写时复制和用时分配。
写时复制
所有驱动都用到的技术——写时复制(CoW)。CoW就是copy-on-write,表示只在需要写时才去复制,这个是针对已有文件的修改场景。比如基于一个image启动多个Container,如果为每个Container都去分配一个image一样的文件系统,那么将会占用大量的磁盘空间。而CoW技术可以让所有的容器共享image的文件系统,所有数据都从image中读取,只有当要对文件进行写操作时,才从image里把要写的文件复制到自己的文件系统进行修改。所以无论有多少个容器共享同一个image,所做的写操作都是对从image中复制到自己的文件系统中的复本上进行,并不会修改image的源文件,且多个容器操作同一个文件,会在每个容器的文件系统里生成一个复本,每个容器修改的都是自己的复本,相互隔离,相互不影响。使用CoW可以有效的提高磁盘的利用率。
用时配置
用时分配是用在原本没有这个文件的场景,只有在要新写入一个文件时才分配空间,这样可以提高存储资源的利用率。比如启动一个容器,并不会为这个容器预分配一些磁盘空间,而是当有新文件写入时,才按需分配新空间。
Docker存储驱动
接下来我们说一说,这些分层的镜像是如何在磁盘中存储的。
docker提供了多种存储驱动来实现不同的方式存储镜像,下面是常用的几种存储驱动:
- AUFS
- OverlayFS
- Devicemapper
- Btrfs
- ZFS
下面说一说AUFS、OberlayFS及Devicemapper,更多的存储驱动说明可参考:http://dockone.io/article/1513
AUFS
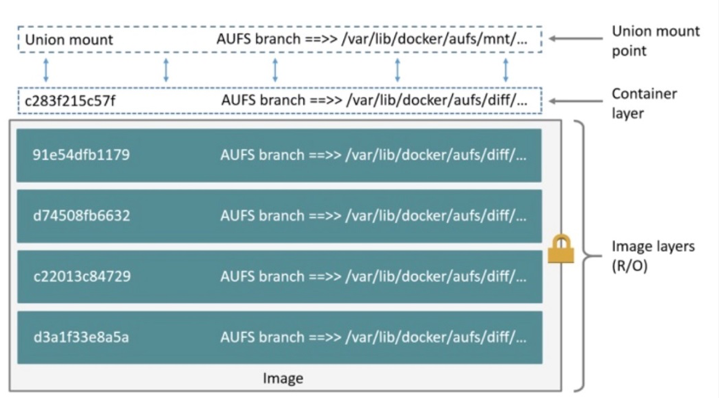
AUFS(AnotherUnionFS)是一种Union FS,是文件级的存储驱动。AUFS是一个能透明覆盖一个或多个现有文件系统的层状文件系统,把多层合并成文件系统的单层表示。简单来说就是支持将不同目录挂载到同一个虚拟文件系统下的文件系统。这种文件系统可以一层一层地叠加修改文件。无论底下有多少层都是只读的,只有最上层的文件系统是可写的。当需要修改一个文件时,AUFS创建该文件的一个副本,使用CoW将文件从只读层复制到可写层进行修改,结果也保存在可写层。在Docker中,底下的只读层就是image,可写层就是Container。结构如下图所示:
OverlayFS
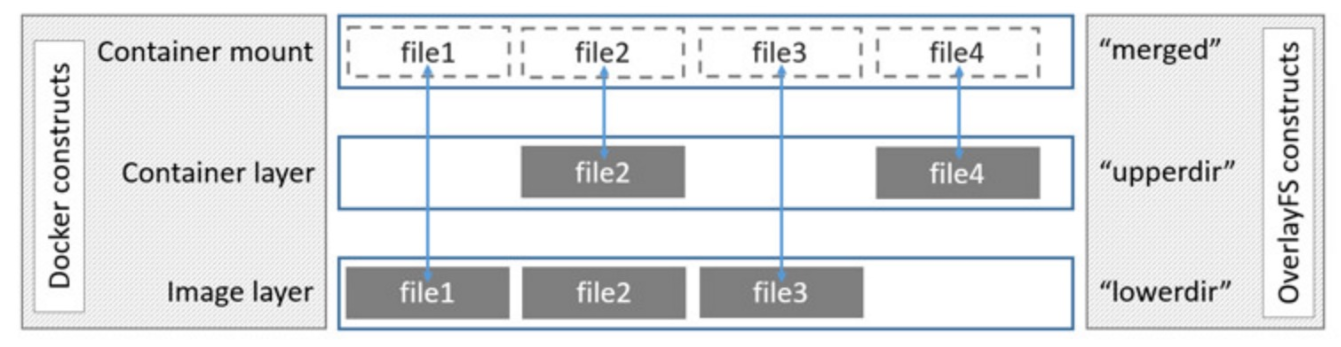
Overlay是Linux内核3.18后支持的,也是一种Union FS,和AUFS的多层不同的是Overlay只有两层:一个upper文件系统和一个lower文件系统,分别代表Docker的镜像层和容器层。当需要修改一个文件时,使用CoW将文件从只读的lower复制到可写的upper进行修改,结果也保存在upper层。在Docker中,底下的只读层就是image,可写层就是Container。目前最新的OverlayFS为Overlay2。结构如下图所示:
Devicemapper
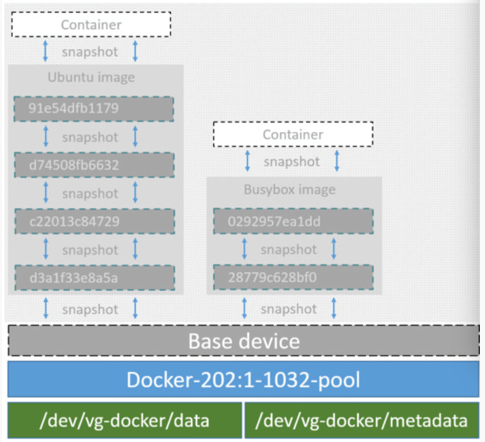
Device mapper是Linux内核2.6.9后支持的,提供的一种从逻辑设备到物理设备的映射框架机制,在该机制下,用户可以很方便的根据自己的需要制定实现存储资源的管理策略。前面讲的AUFS和OverlayFS都是文件级存储,而Device mapper是块级存储,所有的操作都是直接对块进行操作,而不是文件。Device mapper驱动会先在块设备上创建一个资源池,然后在资源池上创建一个带有文件系统的基本设备,所有镜像都是这个基本设备的快照,而容器则是镜像的快照。所以在容器里看到文件系统是资源池上基本设备的文件系统的快照,并没有为容器分配空间。当要写入一个新文件时,在容器的镜像内为其分配新的块并写入数据,这个叫用时分配。当要修改已有文件时,再使用CoW为容器快照分配块空间,将要修改的数据复制到在容器快照中新的块里再进行修改。Device mapper 驱动默认会创建一个100G的文件包含镜像和容器。每一个容器被限制在10G大小的卷内,可以自己配置调整。结构如下图所示:
常用存储驱动对比
| 存储驱动 | 特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| AUFS | 联合文件系统、未并入内核主线、文件级存储 | 作为docker的第一个存储驱动,已经有很长的历史,比较稳定,且在大量的生产中实践过,有较强的社区支持 | 有多层,在做写时复制操作时,如果文件比较大且存在比较低的层,可能会慢一些 | 大并发但少IO的场景 |
| overlayFS | 联合文件系统、并入内核主线、文件级存储 | 只有两层 | 不管修改的内容大小都会复制整个文件,对大文件进行修改显示要比小文件消耗更多的时间 | 大并发但少IO的场景 |
| Devicemapper | 并入内核主线、块级存储 | 块级无论是大文件还是小文件都只复制需要修改的块,并不是整个文件 | 不支持共享存储,当有多个容器读同一个文件时,需要生成多个复本,在很多容器启停的情况下可能会导致磁盘溢出 | 适合io密集的场景 |
| Btrfs | 并入linux内核、文件级存储 | 可以像devicemapper一样直接操作底层设备,支持动态添加设备 | 不支持共享存储,当有多个容器读同一个文件时,需要生成多个复本 | 不适合在高密度容器的paas平台上使用 |
| ZFS | 把所有设备集中到一个存储池中来进行管理 | 支持多个容器共享一个缓存块,适合内存大的环境 | COW使用碎片化问题更加严重,文件在硬盘上的物理地址会变的不再连续,顺序读会变的性能比较差 | 适合paas和高密度的场景 |
AUFS VS OverlayFS
AUFS和Overlay都是联合文件系统,但AUFS有多层,而Overlay只有两层,所以在做写时复制操作时,如果文件比较大且存在比较低的层,则AUSF可能会慢一些。而且Overlay并入了linux kernel mainline,AUFS没有。目前AUFS已基本被淘汰
OverlayFS VS Device mapper
OverlayFS是文件级存储,Device mapper是块级存储,当文件特别大而修改的内容很小,Overlay不管修改的内容大小都会复制整个文件,对大文件进行修改显示要比小文件要消耗更多的时间,而块级无论是大文件还是小文件都只复制需要修改的块,并不是整个文件,在这种场景下,显然device mapper要快一些。因为块级的是直接访问逻辑盘,适合IO密集的场景。而对于程序内部复杂,大并发但少IO的场景,Overlay的性能相对要强一些。