1.WITH ROLLUP:在group分组字段的基础上再进行统计数据。
例子:首先在name字段上进行分组,然后在分组的基础上进行某些字段统计,表结构如下:
CREATE TABLE `test` ( `Id` int(11) NOT NULL AUTO_INCREMENT, `title` varchar(25) DEFAULT NULL COMMENT '标题', `uid` int(11) DEFAULT NULL COMMENT 'uid', `money` decimal(2,0) DEFAULT '0', `name` varchar(25) DEFAULT NULL, PRIMARY KEY (`Id`) ) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4;
存几条数据看看:
INSERT INTO `test`.`test` (`Id`, `title`, `uid`, `money`, `name`) VALUES ('2', '国庆节', '2', '12', '周伯通'); INSERT INTO `test`.`test` (`Id`, `title`, `uid`, `money`, `name`) VALUES ('3', '这次是8天假哦', '3', '33', '老顽童'); INSERT INTO `test`.`test` (`Id`, `title`, `uid`, `money`, `name`) VALUES ('4', '这是Uid=1的第一条数据哦', '1', '70', '欧阳锋'); INSERT INTO `test`.`test` (`Id`, `title`, `uid`, `money`, `name`) VALUES ('5', '灵白山少主', '4', '99', '欧阳克'); INSERT INTO `test`.`test` (`Id`, `title`, `uid`, `money`, `name`) VALUES ('7', '九阴真经创始人', '3', '12', '小顽童'); INSERT INTO `test`.`test` (`Id`, `title`, `uid`, `money`, `name`) VALUES ('8', '双手互博', '2', '56', '周伯通'); INSERT INTO `test`.`test` (`Id`, `title`, `uid`, `money`, `name`) VALUES ('9', '销魂掌', '2', '19', '周伯通'); INSERT INTO `test`.`test` (`Id`, `title`, `uid`, `money`, `name`) VALUES ('10', '蛤蟆功', '1', '57', '欧阳锋'); INSERT INTO `test`.`test` (`Id`, `title`, `uid`, `money`, `name`) VALUES ('11', '绝杀掌', '3', '800', '小顽童'); INSERT INTO `test`.`test` (`Id`, `title`, `uid`, `money`, `name`) VALUES ('12', '九阴真经', '3', '84', '老顽童');
分组统计:
SELECT name, SUM(money) as money FROM test GROUP BY name WITH ROLLUP;
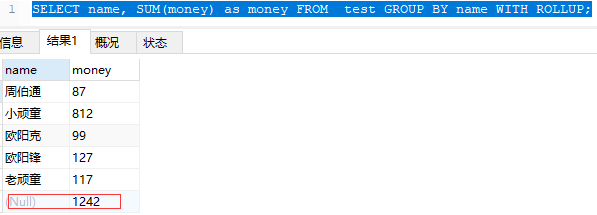
可以看到按照name分组后对money求和统计了。上面看到 null 1242, 如何搞个别名字段比如 总金额:1242呢?也可以滴,咱们继续:
coalesce(a,b,c);
参数说明:如果a==null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null(没意义)。
SELECT coalesce(name, '总金额'),name, SUM(money) as money FROM test GROUP BY name WITH ROLLUP;
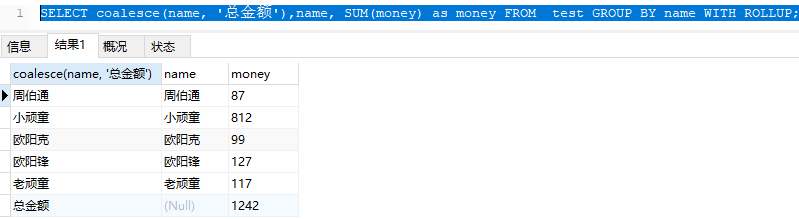
上面可以看出,在数据汇总方面。用途还是很方便滴。