2.1.5 多字节字符和宽字符
为了容纳可能包含大量字符的非英语字母,标准C引入了宽字符和宽字符串的概念。为了表示宽字符以及外部世界中面向字节的字符串,标准C还引入了多字节字符的概念。C89修正案1提供了扩展,以处理宽字符和多字节字符。
宽字符和宽字符串 宽字符是扩展字符集(extended character set)中的元素的二进制表示形式。它的类型是整数类型wchar_t,这个类型是在头文件stddef.h中声明的。C89修正案1添加了整数类型wint_t,它必须可以表示wchar_t类型的所有值,并且可以表示一个额外的、可以区分的非宽字符值,用WEOF表示。标准C并没有指定任何宽字符编码方案,但0这个值被保留为“空的宽字符值”。宽字符常量可以用一种特殊的常量语法来表示(第2.7.3节)。
例子
一般情况下,宽字符占据16位。因此,在32位的计算机上,wchar_t可以用short或unsigned short来表示。如果wchar_t用short表示,并且-1并不是合法的宽字符,则wint_t可以用short表示,WEOF可以用-1表示。但是,更典型的方法是用int或unsigned int表示wint_t。
如果编译器厂商选择不支持扩展字符集(美国的C编译器厂商经常采用这种做法),wchar_t可以被定义为char,“扩展字符集”就与常规的字符集相同。
宽字符串(wide string)是以一个null宽字符结尾的连续的宽字符序列。null宽字符就是表示形式为0的宽字符。除了null宽字符以及另外的WEOF之外,标准C并没有指定扩展字符集的编码方案。宽字符常量可以用特殊的字符串常量来指定(第2.7.4节)。
多字节字符 在C程序中,宽字符可以作为一个单独的单元进行操作,但大多数外部媒介(例如文件)和C源程序是基于单个字节长度的字符的。熟悉扩展字符集的程序员设计了多字节编码(multibyte encoding),这是一种区域特定的方法,在字节长度的字符序列和宽字符序列之间进行映射。
多字节字符是源字符集或执行字符集中宽字符的表示形式(它们可能具有不同的编码形式)。因此,多字节字符串是常规的C字符串,但是这些字符可以被解释为一系列的多字节字符。多字节字符的形式以及多字节字符和宽字符之间的映射取决于定义的实现方式。在编译时,这种映射是针对宽字符常量和宽字符串常量执行的,标准函数库提供了一些函数,可以在运行时执行这种映射。
多节字字符可以使用依赖状态的编码(state-depedent encoding),即多字节字符的解释可能取决于前一个出现的多字节字符。一般情况下,这种编码利用了转移字符。这是一种控制字符,属于多字节字符的一部分,用于更改当前以及后续字符的解释。在一个多字节字符序列中,当前解释被称为编码的转换状态(conversion state),或称转移状态(shift state)。开始对一个多字节字符序列进行转换时,总是使用一个可区分的初始转换(转移)状态,并且这个状态经常在转换结束时被返回。
例子
A编码(我们在这个例子中所使用的一种假设编码)是一种取决于状态的编码方案,它具有两个转移状态:“上”和“下”。↑字符把转移状态修改为“上”,↓字符把转移状态修改为“下”。“下”状态是初始状态,所有的非转移字符具有常规的解释。在“上”状态中,每个多字节字符由一对字母数字字符组成,它们以一种我们并未指定的方式定义了一个宽字符。
在下面这些字符序列中,每个序列包含了3个A编码形式的多字节字符,都从初始的转换状态开始。
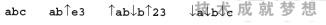
***一个字符串包含了并非严格必需的转移字符。如果允许冗余的转移序列,多字节字符可以变成任意长度(例如↓↓…↓x)。除非知道转换状态位于多字节字符序列的开始,否则就无法对诸如abcdef这样的序列进行解析,它既可以表示3个也可以表示6位宽字符。
ab|?x这个序列在A编码形式下是非法的,因为在“上”转移状态中出现了非字母数字字符。a↑b这个序列是非法的,因为***一个多字节字符过早结束。
多字节字符也可以使用状态无关编码(state-independent encoding),即一个多字节字符的解释并不依赖于前一个多字节字符(尽管可能需要在一个多字节序列中从头开始寻找一个在字符串中间开始的多字节字符)。例如,C的转义字符的语法(第2.7.5节)表示一种char类型的状态独立编码,因为反斜杠字符(\)改变了它后面的一个或多个字符的解释,形成一个char类型的值。
例子
B编码是另一种假设的编码方案,它是一种状态无关编码,并使用了一个特殊的字符,用表示,用于更改它后面的非null字符的含义。在B编码方案中,下面这些字符序列各自包含了3个多字节字符:
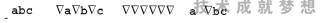
在B编码方案中,这个序列是非法的,因为它的***并不是一个非null字符。
标准C对多字节字符设置了一些限制:
1. 标准字符集中的所有字符都必须出现在编码中。
2. 在初始的转移状态中,标准字符集中的所有单字节字符都保留正常的解释,并不影响转换状态。
3. 包含全0的字符不管是什么转移状态都被认为是null字符。多字节字符不能使用全0的字节作为它的第二个或后续的字符。
总而言之,这些规则保证多字节序列能够作为正常的C字符串(即中间不会嵌入null字符)处理。并且,没有特殊多字节编码的C字符和多字节序列一样可以得到预期的解释。
多字节字符的源代码和执行用法 多字节字符可以出现在注释、标识符、预处理器头文件名、字符串常量和字符常量中。每个注释、标识符、预处理器头文件名、字符串常量和字符常量必须以初始转移状态开始并结束,并且必须由合法的多字节字符序列组成。源代码的物理表示形式中的多字节字符在任何词法分析、预处理或甚至延续行的连接之前就被确认。
例子
一个日文文本编辑程序允许在字符串常量和注释中使用日文字符。如果文本被写入到一个字节流文件中,则日文字符将被转换为多字节序列,这对于字符串常量而言是可以接受的,可以被标准C编辑器所理解。
在预处理期间,字符串和字符常量中的字符被转换为执行字符集,然后才被解释为多字节序列。因此,在形成多字节字符时,转义序列能使用到。在这个阶段之前,程序中的注释已经被删除,因此多字节注释中的转义序列可能没有什么意义。
例子
如果源字符集和执行字符集相同,并且如果'a'的值在执行字符集为1418,那么字符串常量"aa"所包含的两个多字节字符与"\141\141"相同(B编码方案)。
参考:字符常量 第2.7.3节;注释 第2.2节;多字节转换工具 第11.7、11.8节;字符串常量 第2.7.4节;wchar_t、WEOF第11.1节;宽字符 2.7.3节;宽字符串 第2.7.4节;wint_t 第11.1节。
【责任编辑:云霞 TEL:(010)68476606】
点赞 0