前情提要
2023-06-18 周日 杭州 小雨
小记: 昨天搞的好累,10点左右就想着先躺一会儿,然后就睡过去了,很奇怪,如果进行 AI 绘画,晚上就会做很奇怪的梦,说不上来的那种感觉,就是莫名的不舒服。
人类到底是宇宙的一种偶然奇迹还是概率统计下的一种必然现象,不必要搞那么清楚,只要保持原始的生物欲望就可以了,往往好奇心是害死猫的最常规途径。
任务清单:
a. LORA 训练脚本;
b. 训练集选择;
c. 裁剪&打标;
d. 生成模型;
简介
LoRA的全称是LoRA: Low-Rank Adaptation of Large Language Models,可以理解为stable diffusion(SD)模型的一种插件,和hyper-network,controlNet一样,都是在不修改SD模型的前提下,利用少量数据训练出一种画风/IP/人物,实现定制化需求,所需的训练资源比训练SD模要小很多,非常适合社区使用者和个人开发者。LoRA最初应用于NLP领域,用于微调GPT-3等模型(也就是ChatGPT的前生)。由于GPT参数量超过千亿,训练成本太高,因此LoRA采用了一个办法,仅训练低秩矩阵(low rank matrics),使用时将LoRA模型的参数注入(inject)SD模型,从而改变SD模型的生成风格,或者为SD模型添加新的人物/IP。用数据公式表达如下,其中
是初始SD模型的参数(Weights),
为低秩矩阵也就是LoRA模型的参数,
代表被LORA模型影响后的最终SD模型参数。整个过程是一个简单的线性关系,可以认为是原SD模型叠加LORA模型后,得到一个全新效果的模型。
在著名的模型分享网站https://civitai.com/上,有大量的SD模型和LoRA模型,其中SD模型仅有2000个,剩下4万个基本都是LoRA等小模型。例如下图,水墨画和原神八重神子就是LoRA模型来实现特定的画风和人物IP。
应用实践
1. LORA 模型训练脚本
方式一: Dreambooth
Dreambooth 是一种使用少量图像来训练模型的方法,是一种基于深度学习的图像风格转换技术。它可以将一张图片的风格应用到另一张图片上,以生成新的图像,Dreambooth 的一个优点是它可以生成高质量的艺术作品,而无需用户具备专业艺术技能。
特点:
- 模型文件很大,2-4GB
- 适于训练人脸,宠物和物件
- 使用时需要 加载模型
- 可以进行模型融合,跟其他模型文件融合成新的模型
- 本地训练时需要高显存,>=12GB
- 推荐训练人物*画风
方式二: Lora
Lora是一种使用少量图像来训练模型的方法。与 Dreambooth 不同,LoRA 训练速度更快:当 Dreambooth 需要大约二十分钟才能运行并产生几个 GB 的模型时,LoRA 只需八分钟就能完成训练,并产生约 5MB 的模型,推荐使用kohya_ss GUI 进行lora训练。
特点:
- 模型大小适中,8~140MB
- 使用时只需要加载对应的lora模型,可以多个不同的(lora模型+权重)叠加使用
- 可以进行lora模型其他模型的融合
- 本地训练时需要显存适中,>=7GB
- 推荐训练人物
** 下载地址 **
链接:https://pan.baidu.com/s/1xrsbVvpkkPs7dzJ3nY2yuQ
提取码:goat
# 下载项目到本地
git clone https://github.com/bmaltais/kohya_ss.git
# 运行设置脚本
setup.bat
2. 优秀训练集选择
** 参数 **
选择标准: 风格一致,统一;
训练集数量: 30张左右的图片(100以内,不然容易过拟合);
** 目标 **
自我假设: 我是一个 UI 设计师,我有一个比较中意的图标设计,但是居然收费,我只需要学习他的风格,然后定制类似的图标进行设计;
目标网站(挑选喜欢的图标): https://www.iconfont.cn
3. 裁剪&打标
** 参数 **
显卡: 8G及以上
图片尺寸: 512512/512768/768*768;
标签参数: 排除颜色或者特定限制性的词汇;
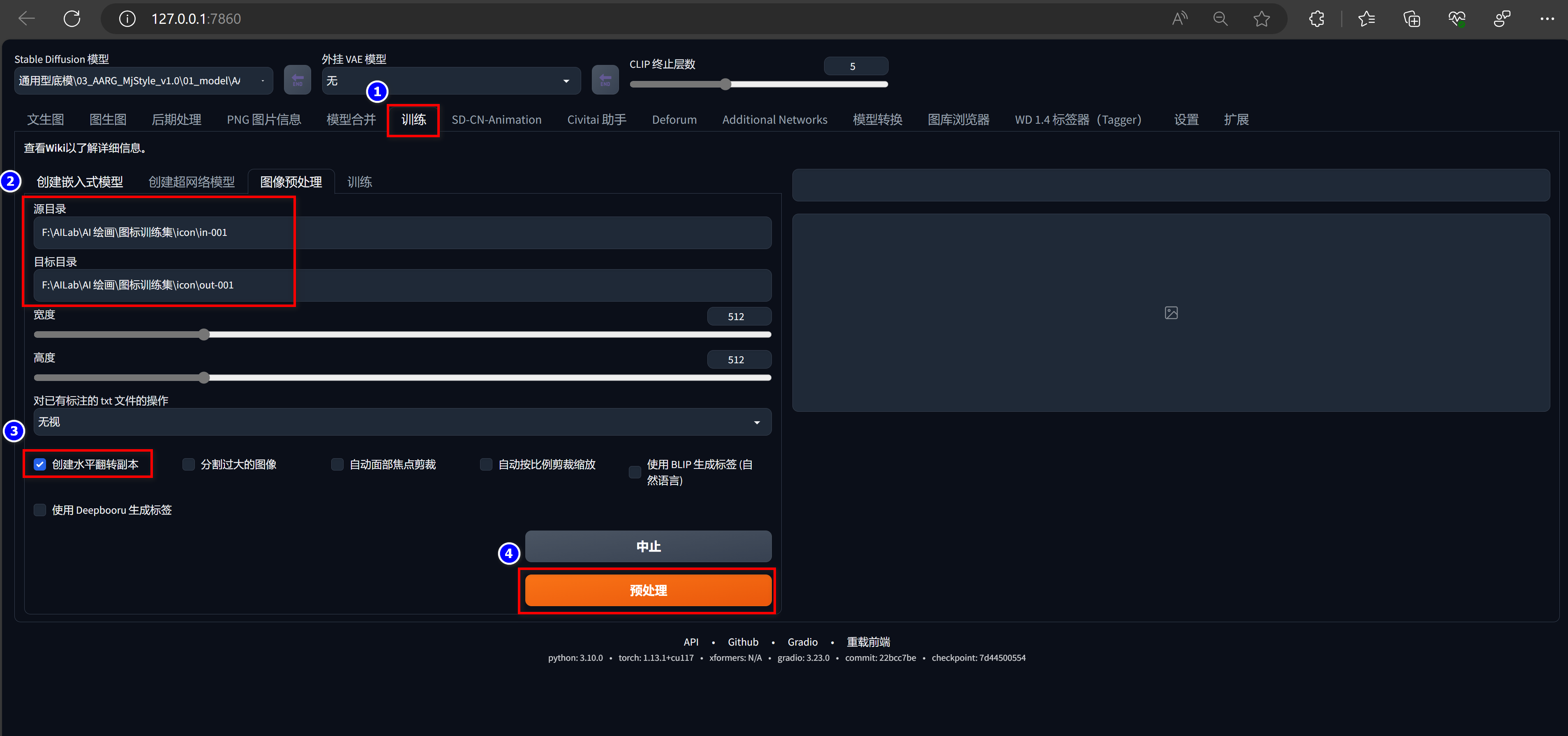
** 裁剪 **
图片源路径: F:\AILab\AI 绘画\图标训练集\icon\in-001
图片目标路径: F:\AILab\AI 绘画\图标训练集\icon\out-001
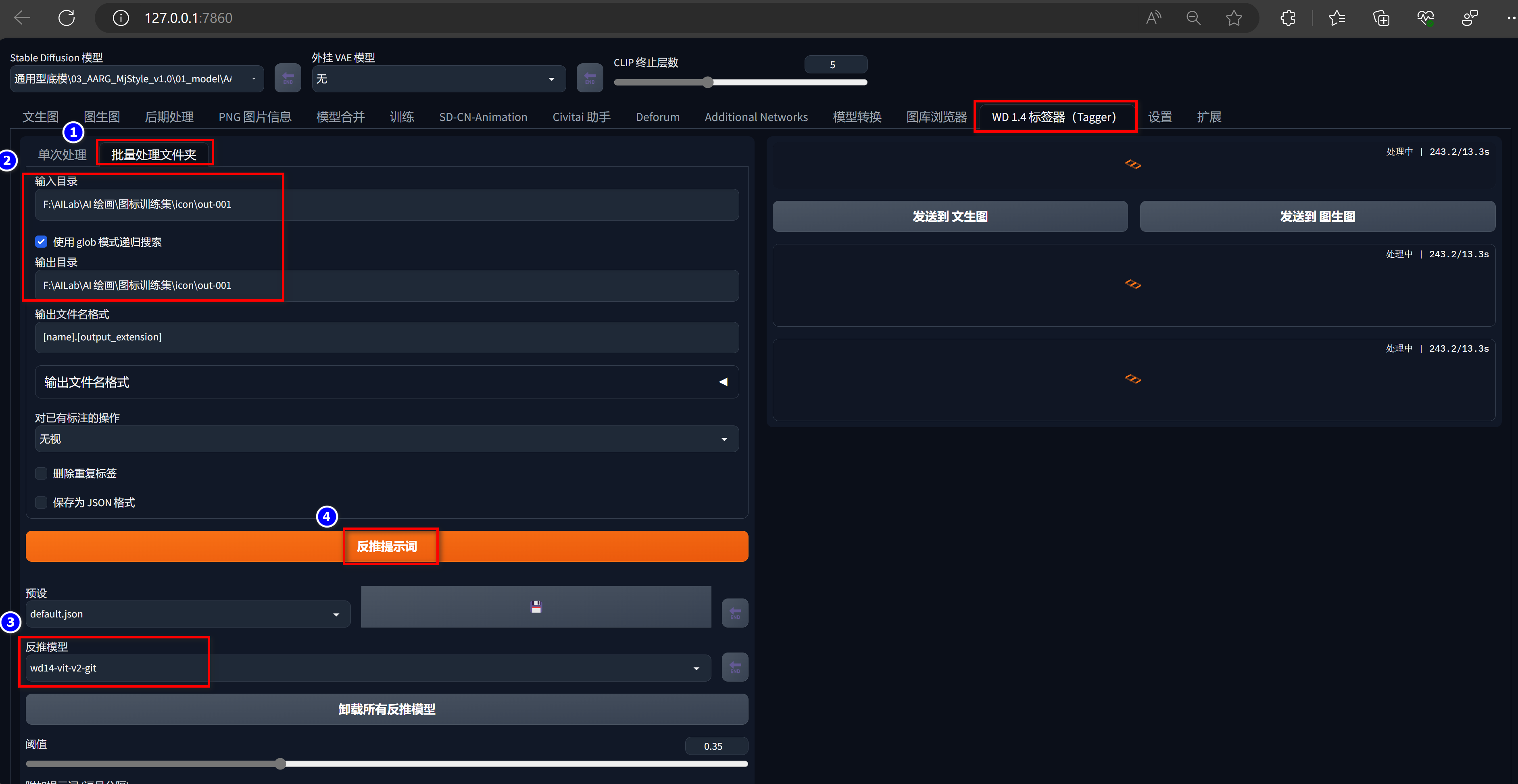
** 打标 **
输入目录: F:\AILab\AI 绘画\图标训练集\icon\out-001
输出目录: F:\AILab\AI 绘画\图标训练集\icon\out-001
4. 模型训练
** 训练集 **
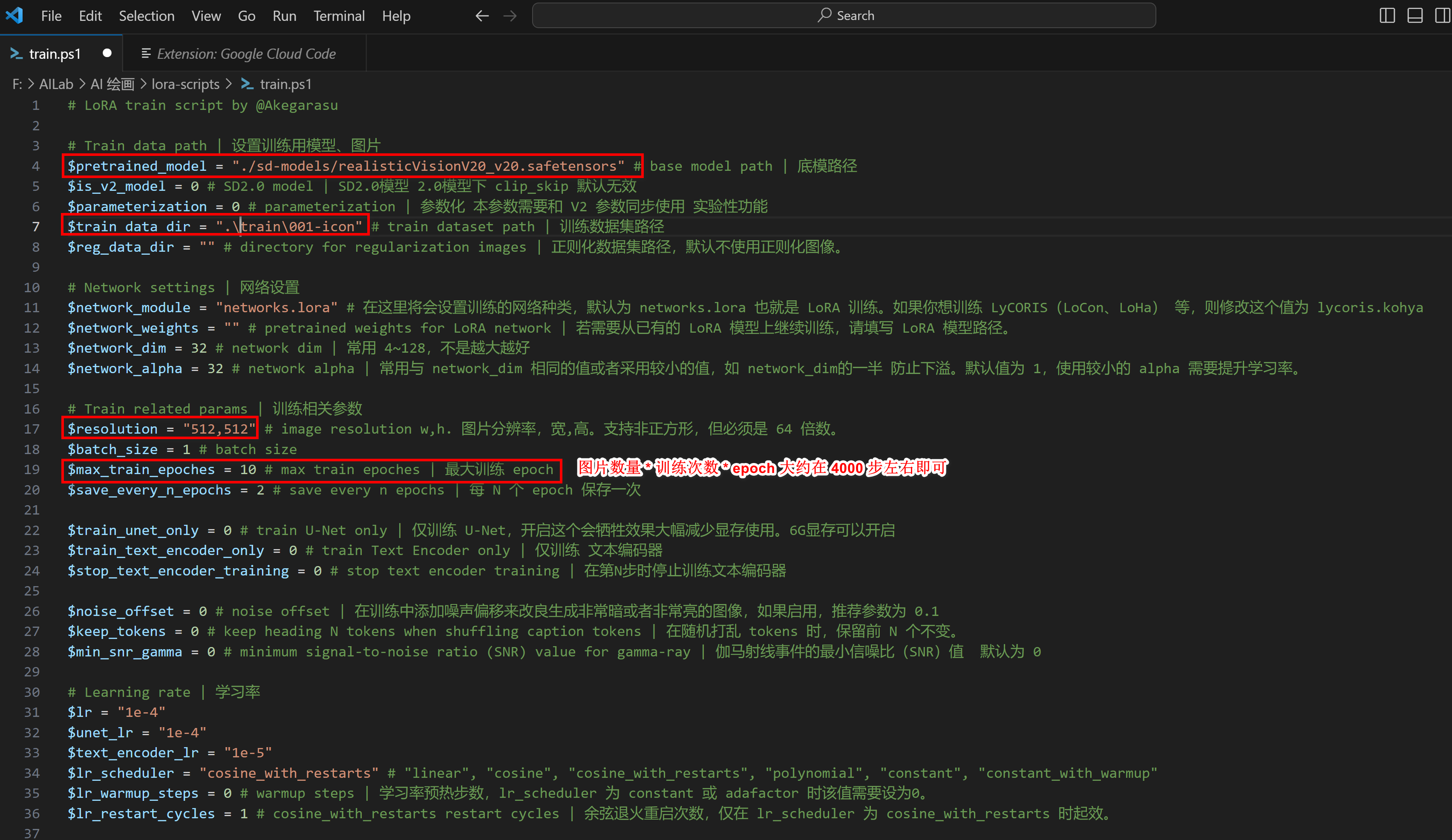
训练图片路径 F:\AILab\AI 绘画\lora-scripts\train\001-icon\5_icon
# 备注: 001-icon 训练图片的路径,可随意;5_icon,其中的数字表示每张图片训练的次数;
** 选定底模 **
训练底模: F:\AILab\AI 绘画\lora-scripts\sd-models
SD模型位置: F:\AILab\AI 绘画\sd-webui-aki-v4\models\Stable-diffusion\chilloutmix_NiPrunedFp32Fix.safetensors
** 训练参数 **
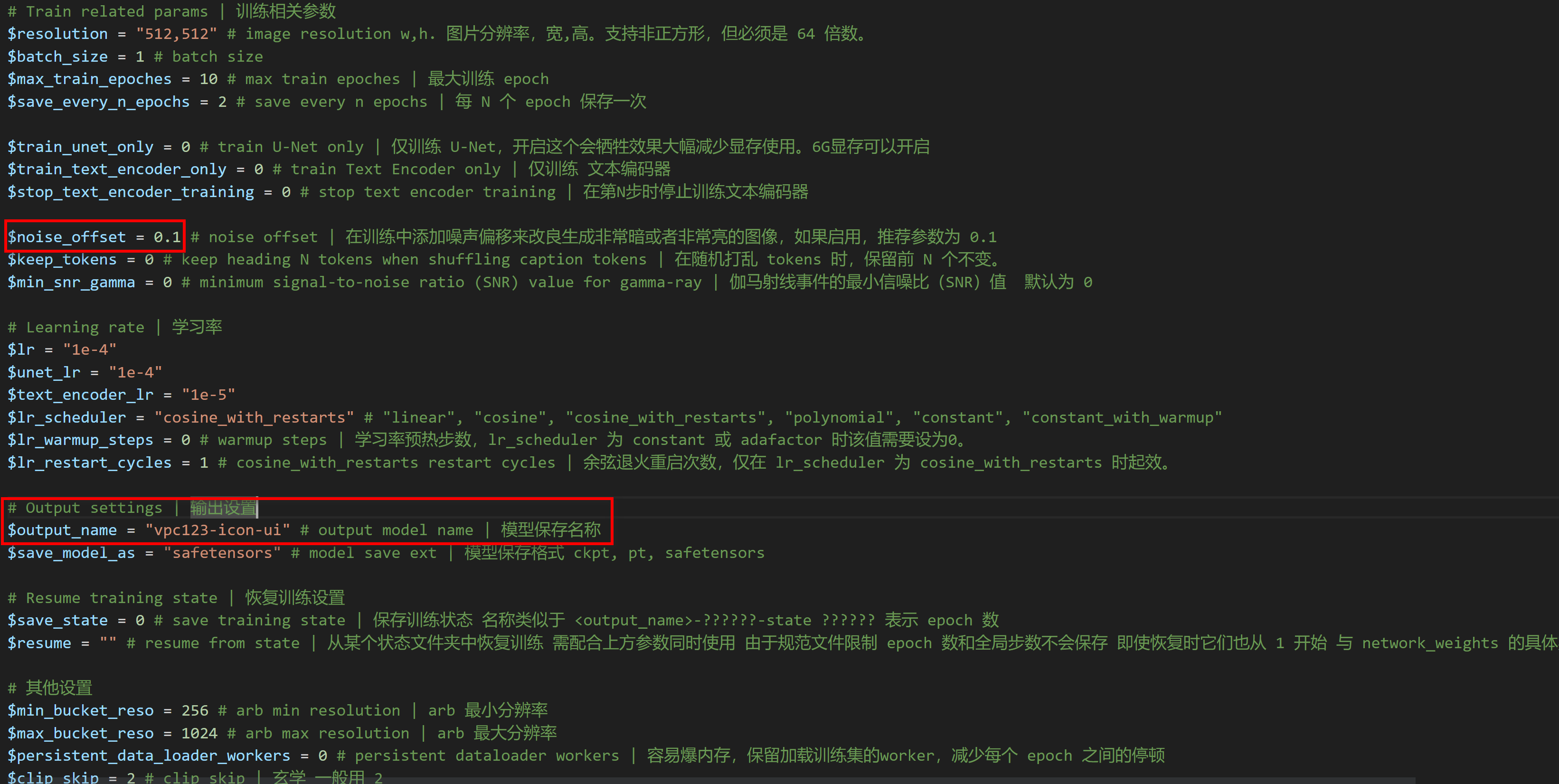
** 运行训练 **
5. 模型测试(鸡准测试)
** 参数配置 **
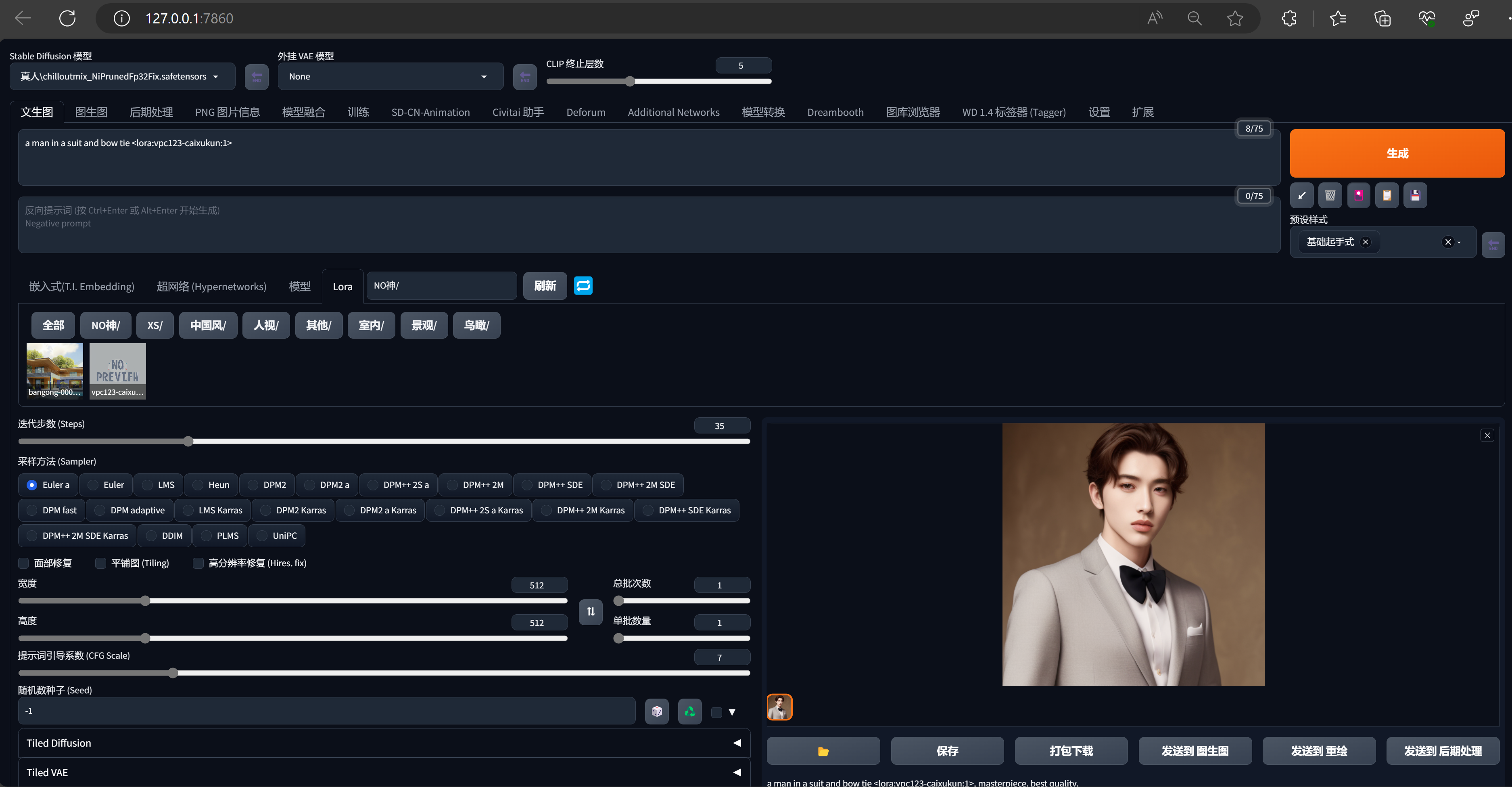
文生图描述: a man in a suit and bow tie <lora:vpc123-caixukun:1>
训练就绪的模型: vpc123-caixukun.safetensors
底模: chilloutmix_NiPrunedFp32Fix.safetensors
# 测试时,底模和 lora 最好配套,不然可能文不对题

生成图:

总结
AI 绘画界一大神器,蔡徐坤的鸡准测试,当代二次元的少年们就是这么直白的嘲讽不留任何情面的,测试的模型还是可以看到生成人物的风格特色的,不过也走了不少的弯路,底模和基于底模训练出来的 lora 模型需要配合使用,还有些底模是不包含图片特征的关键字的,所以人物和建筑模型训练时选择的模型是不同的,需要结合实际需要进行合理的选择与训练。
QA
问题一: 无脚本执行权限
无法加载文件 F:\AILab\AI 绘画\lora-scripts\train.ps1。未对文件 F:\AILab\AI 绘画\lora-scripts\train.ps1 进 行数字签名。无法在当前系统上运行该脚本。有关运行脚本和设置执行策略的详细信息,请参阅 https:/go.microsoft.com/fwlink/?Li nkID=135170 中的 about_Execution_Policies

# 开启脚本执行能力
set-ExecutionPolicy RemoteSigned
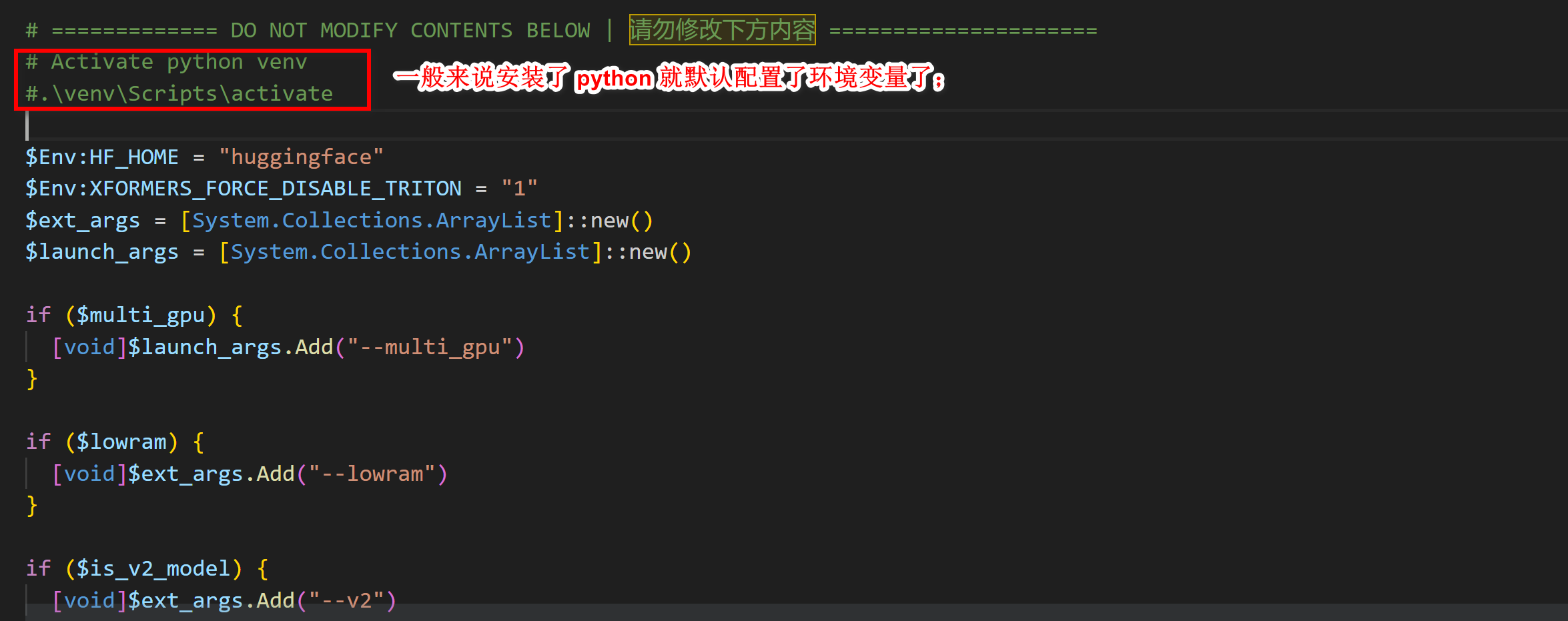
问题二: 开启 python 环境变量设置失败
activate : 无法将“activate”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径正确,然后再试一次。 所在位置 行:1 字符: 1
问题三: 缺少训练脚本依赖
处理办法:
cd F:\AILab\AI 绘画\lora-scripts\sd-scripts\
pip install -r .\requirements.txt