引言
llama3在4月19日刚刚发布,官方的对比结果中在开源模型中堪称世界第一,整好周六日有时间,在魔搭社区上测试一下
一、启动环境
登录魔搭社区,到自己的机器资源,可以看到,可选的机器配置, 这里我们选择:8核32G内存,24G显存; 预装ModelScope 预装镜像为:ubuntu22.04-cuda12.1.0-py310-torch2.1.2-tf2.14.0-1.13.3
点击启动:
启动后,可以进入terminal,检查机器配置:
进入命令行界面:
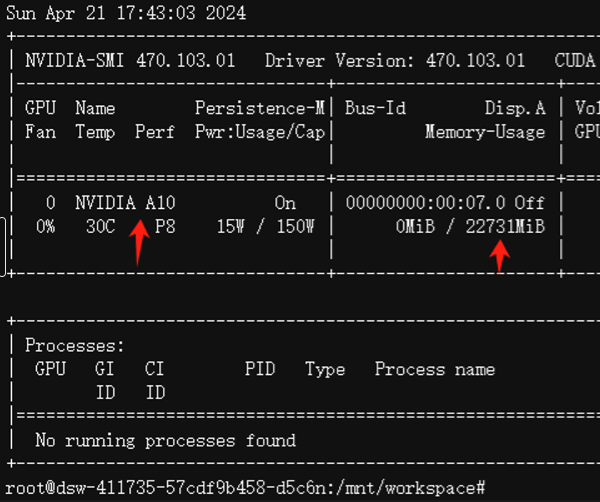
输入invdia-smi, 可以看到是A10卡,24G显存
二、模型下载
这里可以借助modelscope进行模型下载
from modelscope import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer
# 下载模型参数
model_dir=snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct')
print(model_dir)
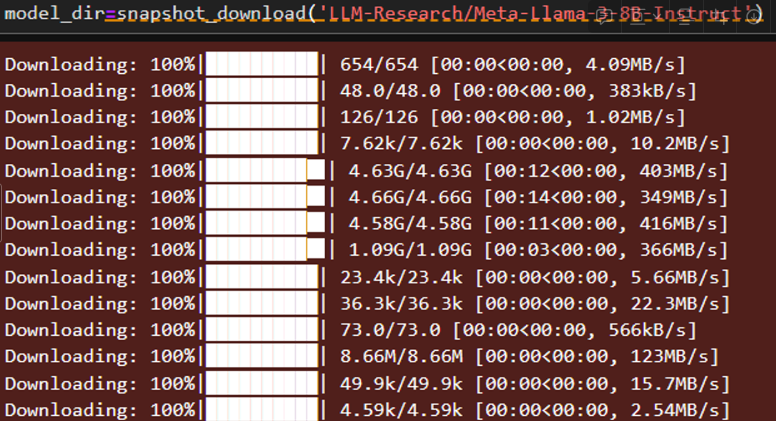
可以看到,使用魔搭社区下载模型参数可以达到400M每秒,非常快(因为是从modelscope的托管平台,下载到modelscope的云平台)。
三、运行本地大模型:
1、使用transfomer运行本地大模型
1.1、 加载我们下载好的模型
# 使用transformer加载模型
# 这行设置将模型加载到 GPU 设备上,以利用 GPU 的计算能力进行快速,
device ="cuda"
# 加载了一个因果语言模型。
# model dir 是模型文件所在的目录。# torch_dtype="auto" 自动选择最优的数据类型以平衡性能和精度。# device_map="auto" 自动将模型的不同部分映射到可用的设备上。
model= AutoModelForCausalLM.from_pretrained(model dir,torch_dtype='auto',device_map="auto")
# 加载与模型相匹配的分词器。分词器用于将文本转换成模型能够理解和处
tokenizer=AutoTokenizer.from pretrained(model_dir)
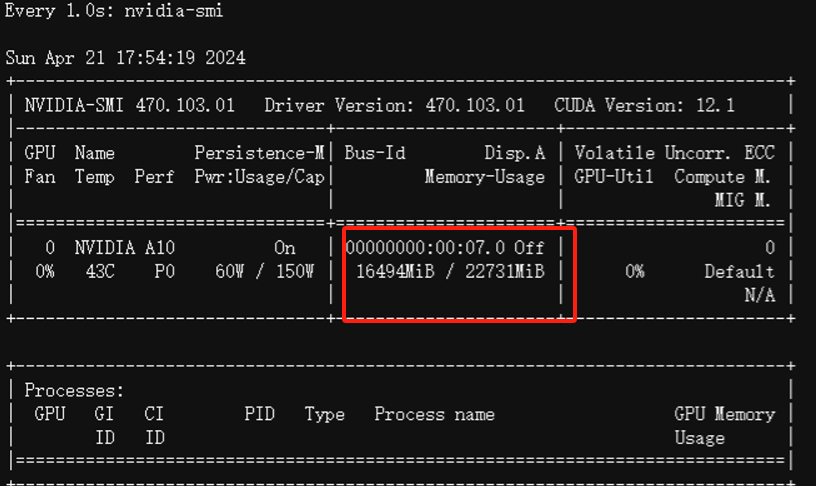
1.2、 检查npu使用情况,可以看到加载完成后占用17G左右显存:
1.3、使用transformer 调用大模型
#加载与模型相匹配的分词器。分词器用于将文本转换成模型能够理解和处
prompt="你好,请介绍下你自己。"
messages=[{'role':'system','content':'You are a helpful assistant system'},
{'role': 'user','content': prompt}]
# 使用分词器的 apply_chat_template 方法将上面定义的消,息列表转护# tokenize=False 表示此时不进行令牌化,add_generation_promp
text =tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
#将处理后的文本令牌化并转换为模型输入张量,然后将这些张量移至之前
model_inputs=tokenizer([text],return_tensors="pt").to('cuda')
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
# 对输出进行解码
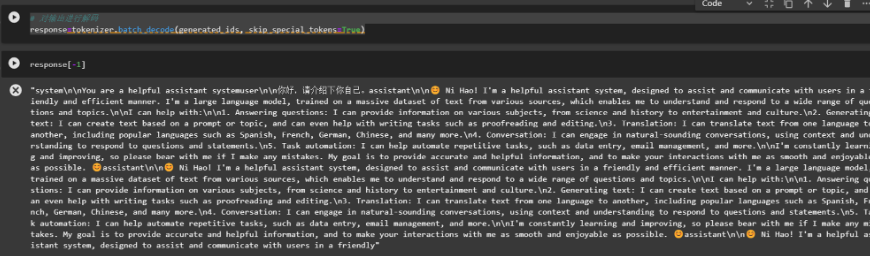
response=tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
1.4、成功返回
2、使用ollama在本地部署模型服务
最常用的开源大模型部署和调用工具有两类,其一是ollama、其二是vLLM。这两款工具定位类似,但功能实现各有侧重。ollama更加侧重于为个人用户提供更加便捷的开源模型部署和调用服务,olama提供了openai风格的调用方法、GPU和CPU混合运行模式、以及更加便捷的显存管理方法,而vLLM则更加适用于企业级应用场景,采用的是服务端和客户端分离的模式,更适合企业级项目使用。
2.1、首先下载并安装运行脚本
curl -fsSL https://ollama.com/install.sh|sh
可以看到,安装完成了
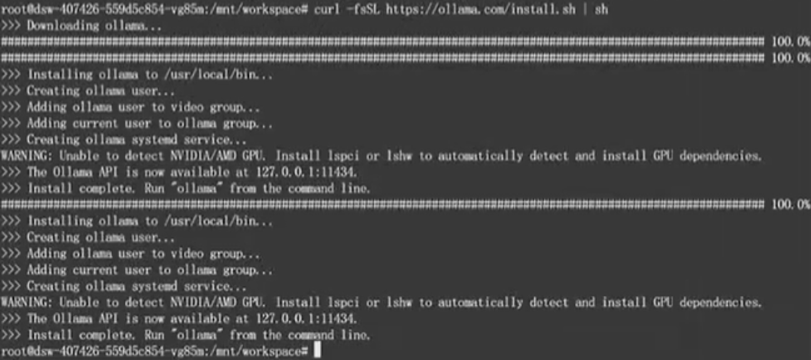
2.2、然后开启ollama服务:
ollama serve
然后,再打开一个窗口,执行下面的命令安装和在命令行中调用llama3大模型:
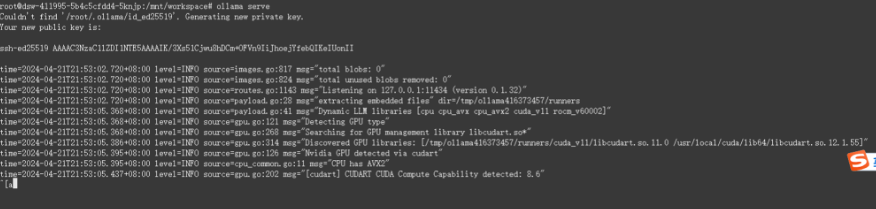
ollama run llama3
启动后,可以在命令行调用:
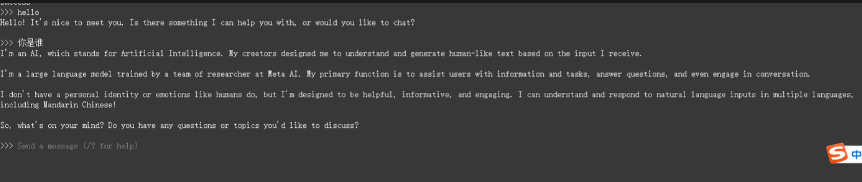
2.3、另外,回到代码环境,可以使用openai风格代码调用
!pip install openai
from openai import OpenAI
client =0penAI(
base url='http://localhost:11434/v1/',
api key='ollama', # required but ignored
)
chat_completion=client.chat.completions.create(
messages=[{'role':'user''content':'你好,请介绍下你自己’}],
model='llama3',
)
chat_completion.choices[0]
写一个多轮对话脚本
lef run chat session():
# 初始化客户端
client = 0penAI(base_url='http://localhost:11434/v1/',
api_key='ollama', # API key is required but ig
#初始化对话历史
chat_history =[]
#启动对话循环
while True:
# 获取用户输入
user_input = input("你:")
# 检查是否退出对话
if user_input.lower()=='exit':
print("退出对话。”)
break
#更新对话历史
chat_history.append({'role': 'user','content':user_input})
# 调用模型获取回答
try:
chat completion=client.chat.completions.create(
messages=chat_history,
model='llama3'
)
# 获取最新回答,适当修改以适应对象属性
model_response=chat_completion.choices[0]
print("AI:"model response)
# 更新对话历史
chat_history.append({'role':'assistant', 'content':model_response)
except Exception as e:
print("发生错误:",e)
break
run_chat_session()
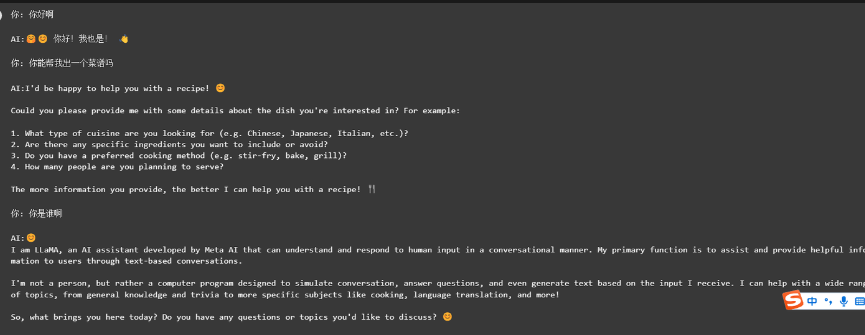
总结
至此,完成了LLAMA3的模型部署,从测试的结果可以看到, llama3的基础模型对于中文的支持并不好,我们的问题是中文,它却返回了英文的结果,原因可能是因为它的训练集有15个T但是其中95%是英文,想要它支持中文更好,还需要使用中文的训练集进行微调,可喜的是,微调llma系列的中文训练集并不少(可能是因为llama系列都有这个问题),后续我会接着对llama3进行微调, 待续。。。