论文DerainCycleGAN: An Attention-guided Unsupervised Benchmark for Single Image Deraining and Rainmaking于2019.12.15收录于arxiv
论文链接
目前已有的去雨模型绝大多数是全监督的。全监督模型的良好性能来源于经过训练之后,训练集中雨水层的信息已经被模型学到了,因此使用成对数据时通常有很好的泛化性能。但是对于没有GT的真实雨图,大部分模型对不规则和不均匀的雨水没辙了
用半监督或者无监督做去雨的工作比全监督模型发展得慢得多,原因有两点:
-
真实雨图的雨水的形状和方向非常不规则,即使是合成的数据集,在没有严格的成对约束的情况下,也很难准确地得到雨图和背景图像之间的映射关系
-
对于现有的合成数据集,监督模型仍不能得到理想的修复结果
该论文在CycleGAN的基础上,提出无监督去雨模型DerainCycleGAN。主要贡献如下:
-
利用雨图和背景图之间的注意力机制引导的传输能力,以及具有两个约束分支的CycleGAN循环结构来去雨
-
提出无监督的注意力机制引导的雨水提取模型U-ARSE,对雨图和无雨图的空间域都使用注意力机制,一阶段一阶段地提取雨水。这样的操作也可用于解决两个空间之间的信息不对称
-
在无雨图到无雨图的循环一致性分支中得到的副产品,成对雨图数据集Rain200A,是第一个生成不规则形状和线条的去雨数据集,与真实数据集更加接近
相关工作
CycleGAN
CycleGAN在没有成对数据的情况下,将图像从原域x翻译到目标域y。首先学习x到y的映射 G : x − > y G:x->y G:x−>y,希望通过对抗损失(adversarial loss)使得产生的图像的分布 G ( x ) G(x) G(x)与 y y y足够相似、能够以假乱真。但由于这个过程的约束过少,模型又学习一个反向的映射 F : y − > x F:y->x F:y−>x,并引入一个循环一致性损失(cycle consistency loss) F ( G ( x ) ) ≈ x F(G(x))\approx x F(G(x))≈x,迫使反向学习到的 F ( y ) F(y) F(y)与 x x x足够接近
这个做法来自于马克吐温的观点:如果一把一段话从英文翻译成法文,再从法文翻译回英文,应该得到跟之前原始输入的英文一样的内容。对于图像生成问题也是一样,如果把马变成斑马,然后再变回马,那么最后的马和开始输入的马应该是一样的
图源:一文读懂GAN, pix2pix, CycleGAN和pix2pixHD(CycleGAN作者朱俊彦博士的线上报告总结)
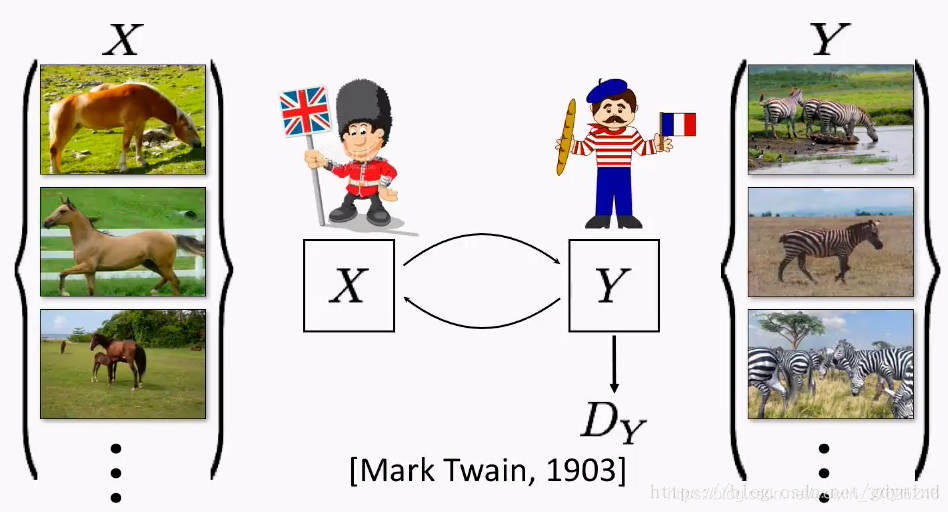
同样的概念也可以应用到去雨问题上:从雨图得到无雨图后,再变回雨图,得到的雨图应该和开始输入的雨图一致。也就是说,CycleGAN自然地,可以用于无监督去雨
但是直接用CycleGAN解决去雨问题有难度,因为雨图和无雨图的领域知识是不对称的,雨图有背景层和雨水层,而无雨图只有背景层。直接使用CycleGAN会带来颜色、结构丢失的问题
本模型与CycleGAN不同之处在于:
- 本模型专门针对去雨而设计,通过由多损失约束的U-ARSE可以很好地保留图像的颜色和结构
- 充分利用CycleGAN的循环结构,在模型中使用两个约束分支
RR-GAN
RR-GAN是一个无监督的去雨模型,定义了一种新的多尺度注意力记忆生成器和多尺度深度监督鉴别器,与一些基于GAN监督模型比较类似。该模型有两个缺陷:
- 只考虑图像的一致性损失(consistency loss),直接将去雨图加到提取的雨水上,使得雨图和无雨图之间的约束较弱
- 仅使用雨图训练雨水提取器,没有利用无雨图中的重要信息,无法有效提取雨水
本模型较RR-GAN作出的改进在于,雨图和无雨图的信息都充分利用,并且构建了两对生成器和判别器,形成一个两个分支的网络,提供更稳定的约束
模型
模型包含三个部分:
- U-ARSE,从雨图中一阶段一阶段地提取雨水
- 两个生成器 G N G_{N} GN, G R G_{R} GR,分别生成无雨图和雨图
- 两个判别器 D N D_{N} DN, D R D_{R} DR,区分真图和G生成的图
两个分支:
- 雨-雨分支(rainy to rainy cycle-consistency branch): r − > n r − > r ~ r->n_{r}->\widetilde{r} r−>nr−>r ,用雨图生成无雨图,再重构成雨图
- 无雨-无雨分支(rain-free to rain-free cycle-consistency branch):
n
−
>
r
n
−
>
n
~
n->r_{n}->\widetilde{n}
n−>rn−>n
,用无雨图生成雨图,再重构成无雨图
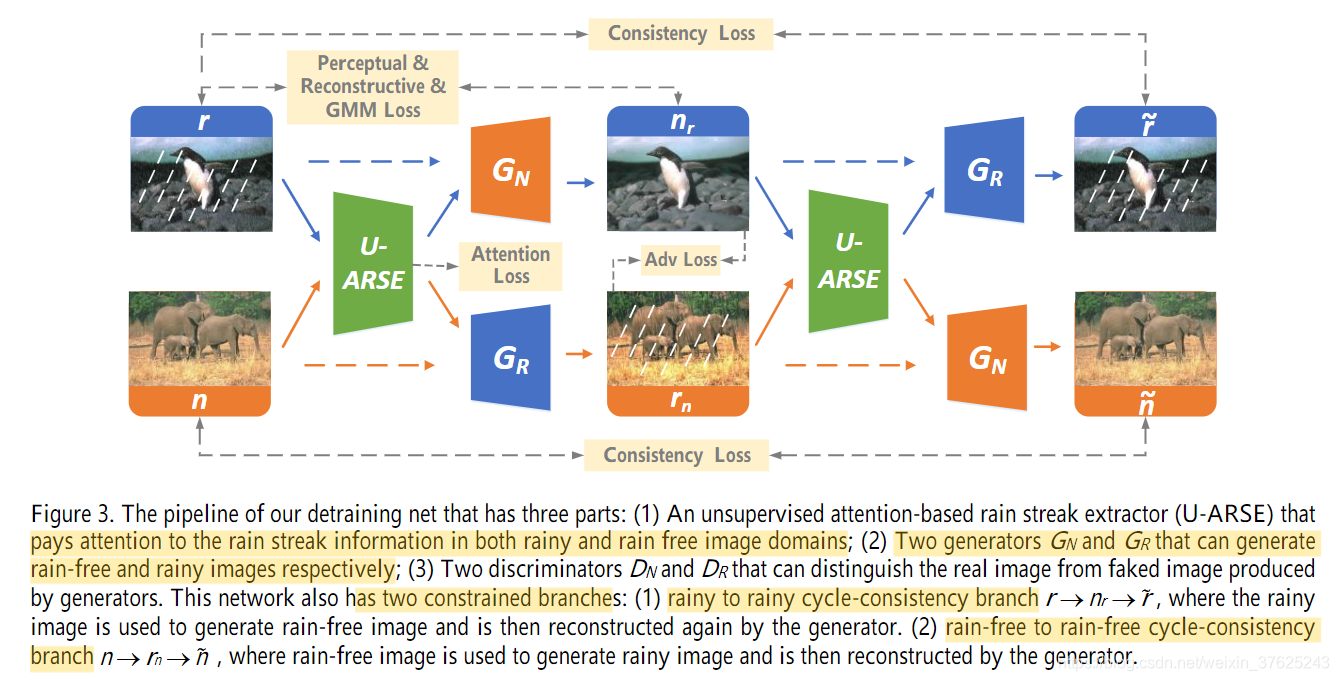
U-ARSE(Unsupervised Attention guided Rain Streak Extractor)
视觉注意力机制关注图像中的重要区域并捕捉这些区域的特征。U-ARSE同时对雨图和无雨图进行关注
U-ARSE包含6个阶段,每个阶段包含一个Hybrid Block单元(dual-path residual dense block,双路径残差密集块),一个LSTM单元和一个CNN,如下图所示
Hybrid Block有两条路径,可以重用前一层学到的通用特征,同时学习当前层的新特征。在训练时的每个步骤中,输入的图像将与前一个阶段中提取的雨水掩码(mask) 拼接,输入到Hybrid Block中。经过一个个阶段,提取到的mask与雨图中的雨水越来越接近。最后一个阶段提取到的mask与输入雨图一起作为生成器的输入

为了提取到准确的mask,定义了雨层注意力 A t t ( r ) Att(r) Att(r)和背景层注意力 A t t ( n ) Att(n) Att(n)上的先验作为约束,在多雨域和无雨域之间传输信息,解决两个域之间的不对称。
总的注意力损失如下:
N
N
N是高斯分布,N~(0,1);
Z
Z
Z是与mask相同大小、所有值为0的分布。用
L
a
t
t
n
r
L_{attn_{r}}
Lattnr计算
A
t
t
(
r
)
Att(r)
Att(r)与N之间的均方误差;因为背景图中没有雨层,因此用
L
a
t
t
n
n
L_{attn_{n}}
Lattnn约束
A
t
t
(
n
)
Att(n)
Att(n)尽可能与0接近
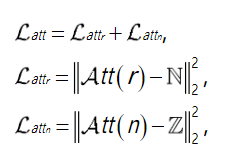
Generators & Discriminators
作者使用U-Net作为G。G的输入是原始雨图与上一个U-ARSE输出的最后一个attention map的拼接
G N G_{N} GN利用雨图 r r r和 A t t r Att_{r} Attr生成无雨图 n r n_{r} nr, G r G_{r} Gr利用无雨图 n n n和 A t t n Att_{n} Attn生成雨图 r n r_{n} rn
U-ARSE从生成的 n r n_{r} nr和 r n r_{n} rn中提取到雨水信息 A t t n r Att_{n_{r}} Attnr和 A t t r n Att_{r_{n}} Attrn, G r G_{r} Gr利用无雨图 n r n_{r} nr和 A t t n r Att_{n_{r}} Attnr重构雨图 r ~ \widetilde{r} r , G n G_{n} Gn利用雨图 r n r_{n} rn和 A t t r n Att_{r_{n}} Attrn重构无雨图 n ~ \widetilde{n} n
D r D_{r} Dr用于区分真实雨图 r r r和生成的雨图 r n r_{n} rn, D n D_{n} Dn用于区分无雨图 n n n和生成的无雨图 n r n_{r} nr
D采用多尺度结构,每个尺度上的特征映射经过三个卷积层,然后输入sigmoid
目标函数
模型总目标函数如下:
所有
λ
\lambda
λ是trade-off参数,
L
a
t
t
L_{att}
Latt在前文已经介绍过

L a d v L_{adv} Ladv
雨水域R上的对抗损失为:
D
R
D_{R}
DR试图最大化损失函数,从而正确区分生成的雨图和真实雨图,
G
R
G_{R}
GR则需要最小化损失函数来生成能够以假乱真的雨图
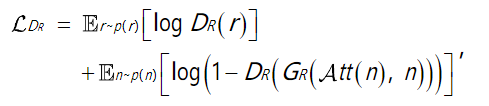
无雨域N上的对抗损失为:
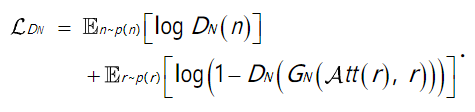
L c c L_{cc} Lcc
在雨水域R和无雨域N上受约束的双分支的循环一致性损失函数
L
c
c
L_{cc}
Lcc(Constrained two-branch cycle-consistency loss)是原始雨图和生成雨图之间以及无雨图与生成的无雨图之间的L1损失的期望之和,可以限制生成样本的空间,保留图像的内容
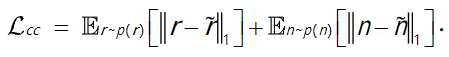
L p L_{p} Lp
CycleGAN生成的图像总是包含一些有瑕疵的区域。从预处理的网络中提取的特征包含丰富的语义信息,它们之间的距离可以作为感知相似性度量(perceptual similarity measure),因此作者采用感知损失对生成的无雨图
n
r
n_{r}
nr与原始雨图之间的差异:
ϕ
l
\phi_{l}
ϕl为预训练CNN的第l层特征提取器。作者使用在ImageNet上训练的VGG-16的
c
o
n
v
2
,
3
conv_{2,3}
conv2,3作为预训练模型
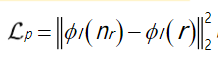
L g m m L_{gmm} Lgmm
该损失描述用GMM(Gaussian Mixture Model)提取的雨水层,用负的对数相似性函数表示:
S
S
S是雨层,k是混合构件的数量,
π
k
\pi_{k}
πk是混合系数,
N
\mathscr{N}
N表示高斯分布,
μ
k
\mu_{k}
μk,
∑
k
\sum_{k}
∑k分别是高斯分布的均值和方差
S
=
r
−
n
r
=
r
n
S=r-n_{r}=r_{n}
S=r−nr=rn是雨层
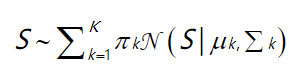
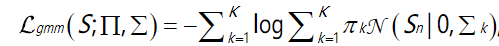
L r L_{r} Lr
重构损失(reconstructive loss)对雨图
r
r
r与恢复的雨图
r
′
r'
r′之间的不匹配进行描述,最小化合成的雨图
r
′
=
A
t
t
(
r
)
+
n
r
r'=Att(r)+n_{r}
r′=Att(r)+nr和原始雨图
r
r
r之间的差异:
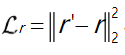
其他
测试
测试时,先使用U-ARSE提取雨水特征
A
t
t
(
r
)
Att(r)
Att(r),然后
G
N
G_{N}
GN利用
A
t
t
(
r
)
Att(r)
Att(r)和原始雨图
r
r
r生成去雨图
n
r
n_{r}
nr:
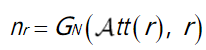
Rain200A数据集
将200张图像输入该论文模型的第二个分支:
n
−
>
r
n
−
>
n
~
n->r_{n}->\widetilde{n}
n−>rn−>n
,则雨水层会被自动地加到无雨图上,得到雨图:
这种方式生成的雨水有更多的形状和方向,更接近真实雨水。通过这个过程得到新的去雨成对数据集Rain200A
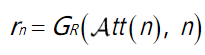
作者做了个实验,分别用Rain100L(用PS合成的数据集,训练集也为200张)和Rain200A作为训练接训练PReNet,然后在真实雨图上进行测试,结果发现在Rain200A上训练的模型对真实雨图的去雨效果更好,证明了使用该数据集训练做真实雨图去雨任务的模型的优越性

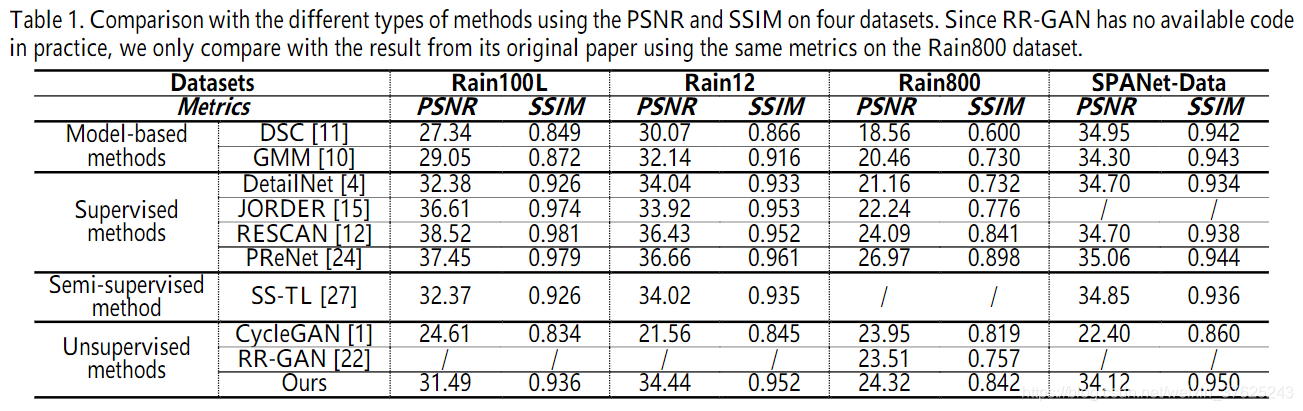
实验结果
作者给出了该模型与一些模型驱动的方法、全监督模型、半监督模型、无监督模型在三个合成数据集和一个真实数据集(SPANet-Data)上的定量比较结果。结果表明,作者提出的模型完胜其他无监督模型,可以与表现最好的全监督模型抗衡,甚至可以比过半监督模型