课程链接:点这里
数据集:课程评论区有课件链接,里面有数据集
刘洪普老师个人网站:点这里
1. GPU版本的程序:
1.1 环境要求
python3.8.3
torch==1.7.1+cu101
cuda 10.1
显卡: Tesla V100
1.2 程序
import math
import time
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch.nn.utils.rnn import pack_padded_sequence
import gzip
import csv
import matplotlib.pyplot as plt
import numpy as np
# 读取数据集以及获取数据集信息
class NameDataset(Dataset):
def __init__(self, is_train_set=True):
filename = '/home/Datasets/names_train.csv.gz' if is_train_set else '/home/Datasets/names_test.csv.gz'
with gzip.open(filename, 'rt') as f:
reader = csv.reader(f)
rows = list(reader)
# 取出来名字那一列
self.names = [row[0] for row in rows]
self.len = len(self.names)
self.countries = [row[1] for row in rows]
# set去除重复元素
self.country_list = list(sorted(set(self.countries)))
self.country_dict = self.getCountryDict()
self.country_num = len(self.country_list)
# 根据索引获取元素
def __getitem__(self, index):
return self.names[index], self.country_dict[self.countries[index]]
def __len__(self):
return self.len
""" 作用:生成无重复的国家字典
# 示例:
countries = ['China', 'America', 'Jap', 'China', 'England', 'Jap', 'Koera', 'Russian', 'America', 'India', 'India', 'China', 'Germ', 'Franch', 'Germ', 'Austra', 'Franch']
country_list = list(sorted(set(countries)))
print(country_list)
def getCountryDict():
country_dict = dict()
for idx, country_name in enumerate(country_list, 0):
country_dict[country_name] = idx
return country_dict
country_dict = getCountryDict()
print(country_dict)
# 输出:
>> ['America', 'Austra', 'China', 'England', 'Franch', 'Germ', 'India', 'Jap', 'Koera', 'Russian']
>> {'America': 0, 'Austra': 1, 'China': 2, 'England': 3, 'Franch': 4, 'Germ': 5, 'India': 6, 'Jap': 7, 'Koera': 8, 'Russian': 9}
"""
def getCountryDict(self):
country_dict = dict()
for idx, country_name in enumerate(self.country_list, 0):
country_dict[country_name] = idx
return country_dict
# 根据索引返回国家的字符串
def idx2country(self, index):
return self.country_list[index]
def getCountriesNum(self):
return self.country_num
class RNNClassifier(nn.Module):
# __init__参数是底下所有的搭建网络所需要用到的参数
# bidirection:双向GRU
def __init__(self, input_size, hidden_size, output_size, n_layers=1, bidirectional=True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, n_layers, bidirectional=bidirectional)
self.fc = nn.Linear(hidden_size * self.n_directions, output_size)
# 初始化输入的数据
def _init_hidden(self, batch_size):
hidden = torch.zeros(self.n_layers * self.n_directions, batch_size, self.hidden_size)
return create_tensor(hidden)
def forward(self, input, seq_lengths):
# 转置矩阵 将Batch*Seq转换成Seq*Batch 适合Embedding需要
input = input.t()
# input_data = input_data.transpose(0,1)
batch_size = input.size(1)
hidden = self._init_hidden(batch_size)
# 形状:(seqLen, batch_size, hidden_size)
embedding = self.embedding(input)
# pack_padded_sequence作用:去掉全零的序列,节省空间,
gru_input = pack_padded_sequence(embedding, seq_lengths.cpu())
output, hidden = self.gru(gru_input, hidden)
if self.n_directions ==2:
hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=-1)
else:
hidden_cat = hidden[-1]
fc_output = self.fc(hidden_cat)
return fc_output
def names2list(name):
# ord()返回对应ASCLL表示
arr = [ord(c) for c in name]
return arr, len(arr)
def create_tensor(tensor):
if USE_GPU:
device = torch.device('cuda:0')
tensor = tensor.to(device)
return tensor
def time_since(since):
s = time.time() - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' %(m, s)
def make_tensor(names, countries):
sequence_and_lengths = [names2list(name) for name in names]
name_sequences = [sl[0] for sl in sequence_and_lengths]
seq_lengths = torch.LongTensor([sl[1] for sl in sequence_and_lengths])
countries = countries.long()
# 先设置一个全零数组 然后把ASCLL数据替代过去
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long()
# 遍历名字、序列长度组成的元组,从0开始
for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)
"""
# 示例:
import torch
seq_lengths = torch.LongTensor([10, 9 , 10, 7, 8])
seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True)
seq_lengths, perm_idx
# 输出
>> (tensor([10, 10, 9, 8, 7]), tensor([0, 2, 1, 4, 3]))
"""
seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True)
# 将ASCLL表按照所需的顺序排列好
seq_tensor = seq_tensor[perm_idx]
# 将城市的名字按照所需的顺序排列好
countries = countries[perm_idx]
return create_tensor(seq_tensor), create_tensor(seq_lengths), create_tensor(countries)
# 训练模型
def trainModel():
total_loss = 0
"""
训练集13374个名字,BATCH_SIZE=256 = 53
i的范围[1, 53]
"""
for i, (names, countries) in enumerate(trainloader, 1):
inputs, seq_lengths, target = make_tensor(names, countries)
output = classifier(inputs, seq_lengths)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if i % 10 == 0:
print(f'[{time_since(start)}] Epoch {epoch}', end=' ')
print(f'[{i * len(inputs)}/{len(trainset)}]', end=' ')
print(f'loss = {total_loss / (i * len(inputs))}')
return total_loss
def testModel():
correct = 0
total = len(testset)
print('Evaluating trained model...')
with torch.no_grad():
for i, (names, countries) in enumerate(testloader, 1):
inputs, seq_lengths, target = make_tensor(names, countries)
output = classifier(inputs, seq_lengths)
pred = output.max(dim=1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
percent = '%.2f' % (100 * correct / total)
print(f'Test set: Accuracy {correct} / {total} {percent}%')
return correct / total
if __name__ == '__main__':
HIDDEN_SIZE = 100
BATCH_SIZE = 256 # 每个batch_size256个名字在
N_LAYERS = 2
N_EPOCHS = 100 # 训练100轮
N_CHARS = 128 # 字典长度128
USE_GPU = True
# USE_GPU = False
trainset = NameDataset(is_train_set=True)
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True)
testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset, batch_size=BATCH_SIZE, shuffle=False)
N_COUNTRY = trainset.getCountriesNum()
classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYERS)
if USE_GPU:
device = torch.device('cuda:0')
classifier.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(classifier.parameters(), lr=0.001)
start = time.time()
print('Training for %d epochs...' %N_EPOCHS)
acc_list = []
# 每训练一个Epoch就验证一下准确率
for epoch in range(1, N_EPOCHS + 1):
trainModel()
acc = testModel()
acc_list.append(acc)
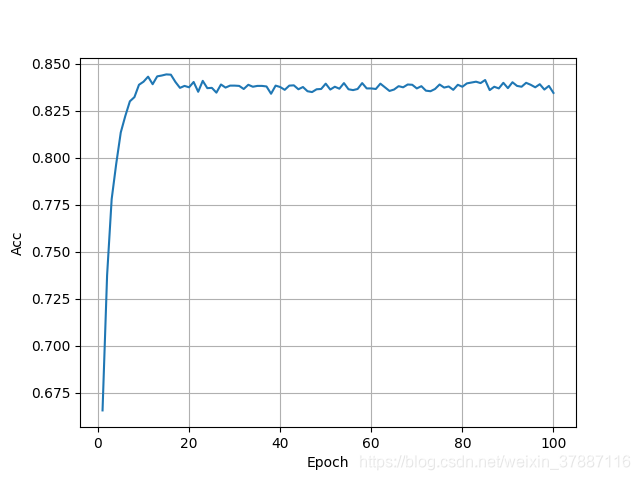
# 绘图,展示训练的结果,发现训练到N_EPOCHS=10的时候就效果不再显著
epoch = np.arange(1, len(acc_list) + 1, 1)
acc_list = np.array(acc_list)
fig = plt.figure()
ax = fig.add_subplot()
ax.plot(epoch, acc_list, label='Accuracy')
ax.set_title('Change of Accuracy')
ax.set_xlabel('Epoch')
ax.set_ylabel('Acc')
ax.legend()
ax.grid()
plt.show()
gru_input = pack_padded_sequence(embedding, seq_lengths.cpu())
.cpu() 课程中没有,但是不加无法在GPU运行
1.3 运行结果
.....
[3m 13s] Epoch 100[2560/13374]loss = 0.00012714920594589785
[3m 14s] Epoch 100[5120/13374]loss = 0.00013297978839545976
[3m 14s] Epoch 100[7680/13374]loss = 0.00013881954461491356
[3m 14s] Epoch 100[10240/13374]loss = 0.00014577317033399596
[3m 15s] Epoch 100[12800/13374]loss = 0.00015000603394582868
Evaluating trained model...
Test set: Accuracy 5591 / 6700 83.45%
2. CPU版本的程序:
2.1 修改
USE_GPU = False
.....
[22m 10s] Epoch 100[2560/13374]loss = 0.00010133394935110118
[22m 13s] Epoch 100[5120/13374]loss = 0.0001161873473392916
[22m 15s] Epoch 100[7680/13374]loss = 0.000131447339784548
[22m 17s] Epoch 100[10240/13374]loss = 0.00014009950637046132
[22m 20s] Epoch 100[12800/13374]loss = 0.00014168857444019523
Evaluating trained model...
Test set: Accuracy 5594 / 6700 83.49%
可以看出来GPU加速效果还是很明显的,大概快了7倍