目录
2.2 安装nvidia混合精度库apex(我是参考这篇博客说明)
前言:
大数据时代,标注图片过往都是需要耗费大量的人工操作,用labelImg标注是一种方式,如果有一批2W张图片数据,按照1天8小时标注的2000张工作量,至少80个小时,几乎要10天,而且当数据量大,人工标注容出错,难以逐一排查。那我们换个角度思考,就是可以先标注3000张左右图片,训练一个模型,然后用这个模型再预测其他未标注的图片,这也是监督学习的一个思维方法。接下来,看完这篇文章,希望能帮到每个小白快速上车,话不多说,直奔主题。
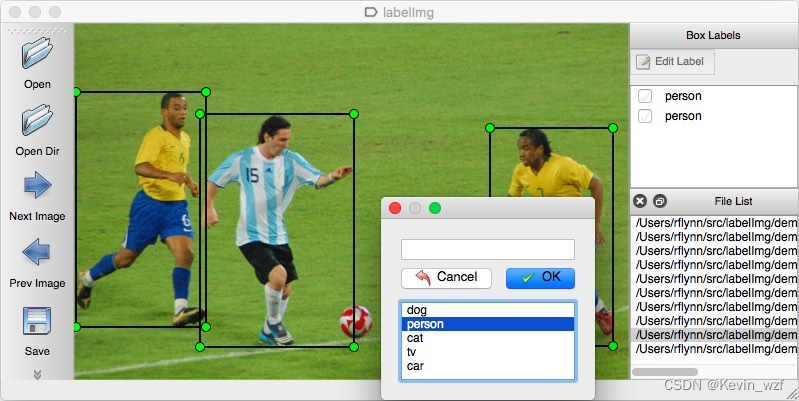
一、认识标注数据的格式
我们用labelImg标注一张图片,用VOC格式标注后会生成一个下方以.xml为后缀的标签文件,这个标签文件就是包含了图片的一些元素,包括folder名称,图片尺寸大小size,目标物体object的目标框信息等等。关键的是,如何将这些目标框信息与图片中的物体一一对应,这个就是我们用算法模型能辅助我们做的。我们用YOLOX的算法模型识别一张图片,就会输出检测物体的bbox信息和类别以及预测物体的概率,那我们现在实现自动标注的关键就是,把这些识别出来的信息写入到xml文件中就好。
<annotation>
<folder>JPEGImages</folder>
<filename>person_1.jpg</filename>
<path>/home/kevin/yolox/data/JPEGImages/person_1.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>640</width>
<height>480</height>
</size>
<segmented>0</segmented>
<object>
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>31</xmin>
<ymin>242</ymin>
<xmax>245</xmax>
<ymax>437</ymax>
</bndbox>
</object>
</annotation>

二、YOLOX配置环境(代码在这)
2.1安装依赖
官网步骤如下:
git clone [email protected]:Megvii-BaseDetection/YOLOX.git
cd YOLOX
pip3 install -v -e . # or python3 setup.py develop我看到其他博主的文章,是需要安装如下环境,可以根据电脑环境进行安装自己缺的包
pip3 install -U pip
pip3 install -r requirements.txt 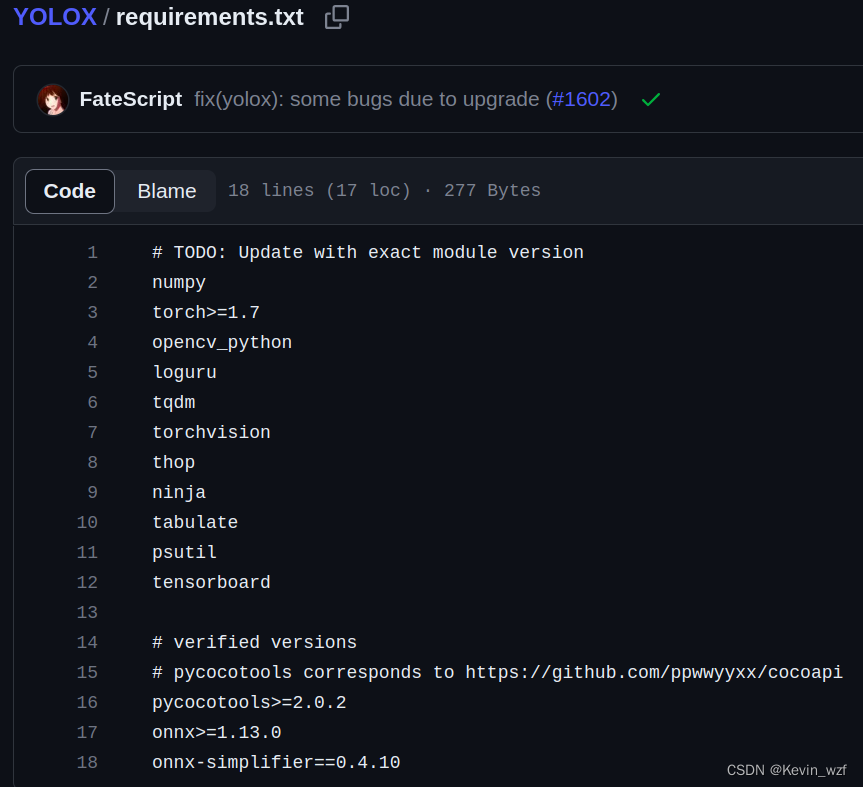
我是华硕天选2笔记本电脑,RTX3060的显卡(6G)+16G内存,安装的是pytorch-gpu-2.0环境
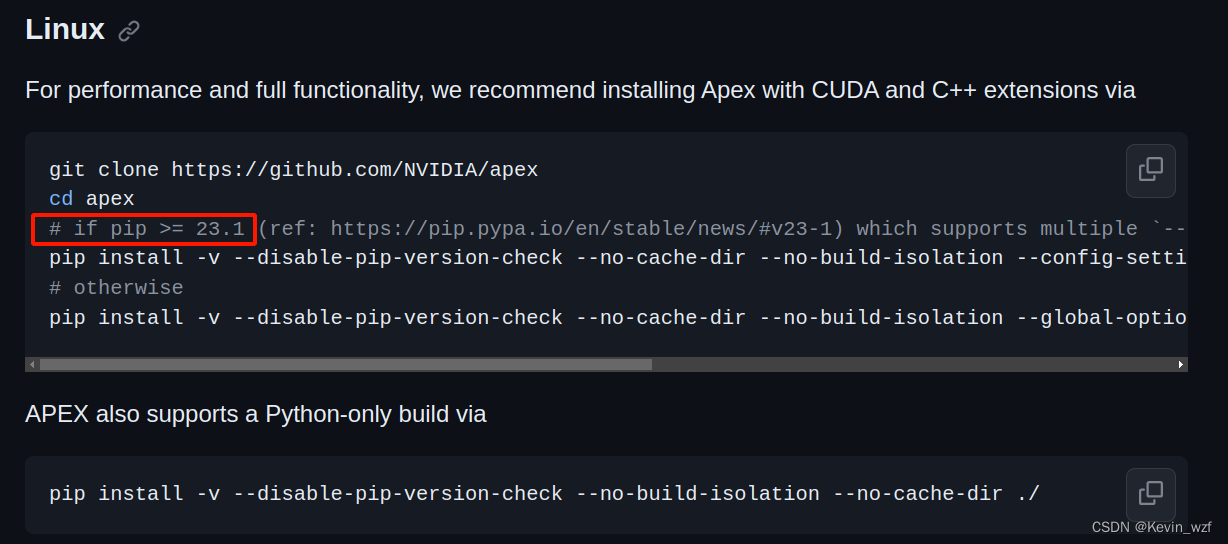
2.2 安装nvidia混合精度库apex(我是参考这篇博客说明)
git clone https://github.com/NVIDIA/apex
cd apex
# if pip >= 23.1 (ref: https://pip.pypa.io/en/stable/news/#v23-1) which supports multiple `--config-settings` with the same key...
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./
# otherwise
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --global-option="--cpp_ext" --global-option="--cuda_ext" ./官方的安装步骤如下
我之前也改了setup.py这个代码,加了return,但还是报错,大概意思是cuda版本和pytorch版本不 太一样,我当时忘了怎么解决的,好像是用了上面的方式2就好了。

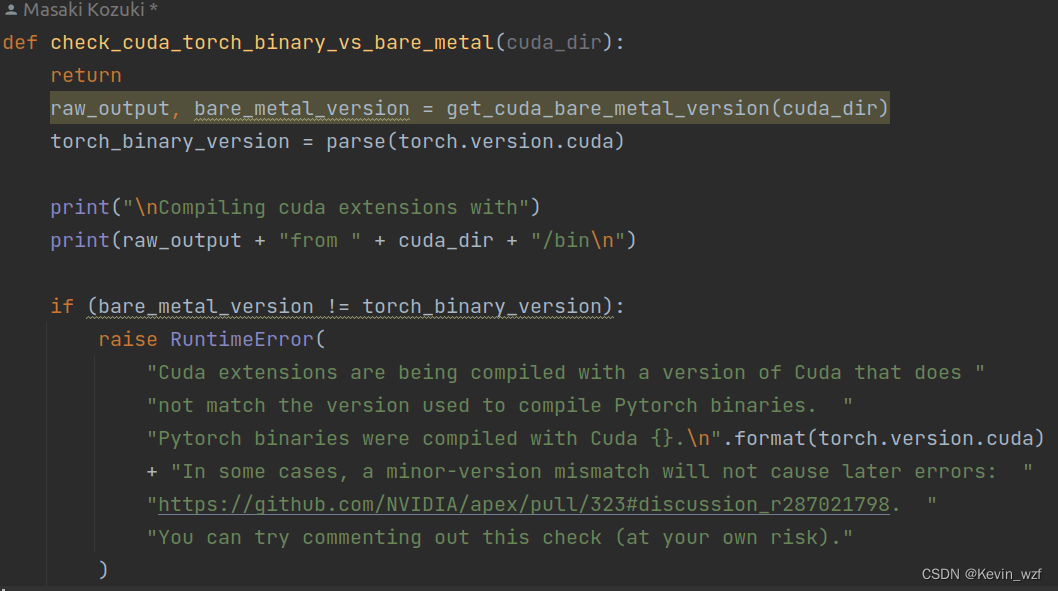
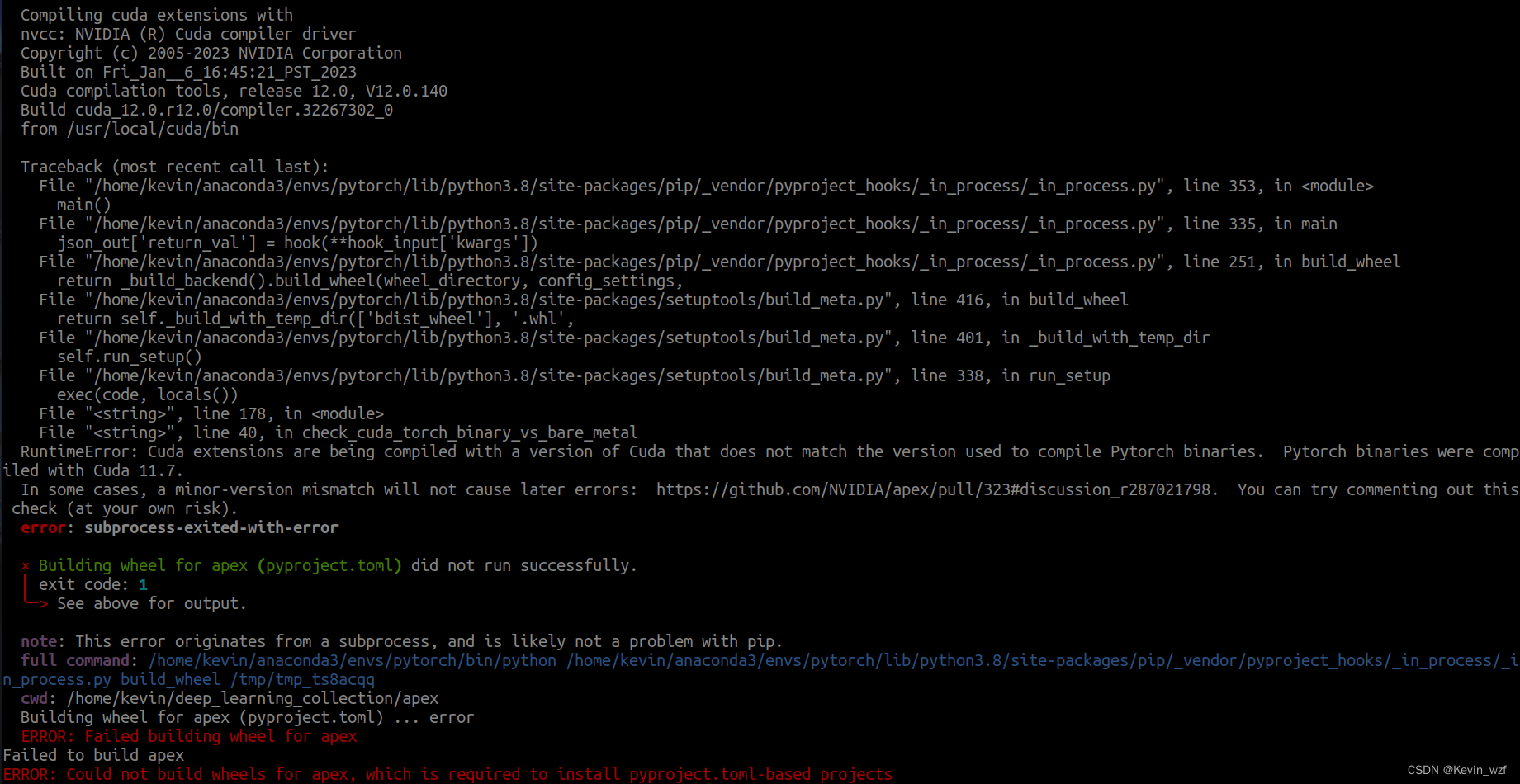
2.3 安装 pycocotools
pip3 install cython; pip3 install 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
三、YOLOX模型训练
1.训练自己的数据集
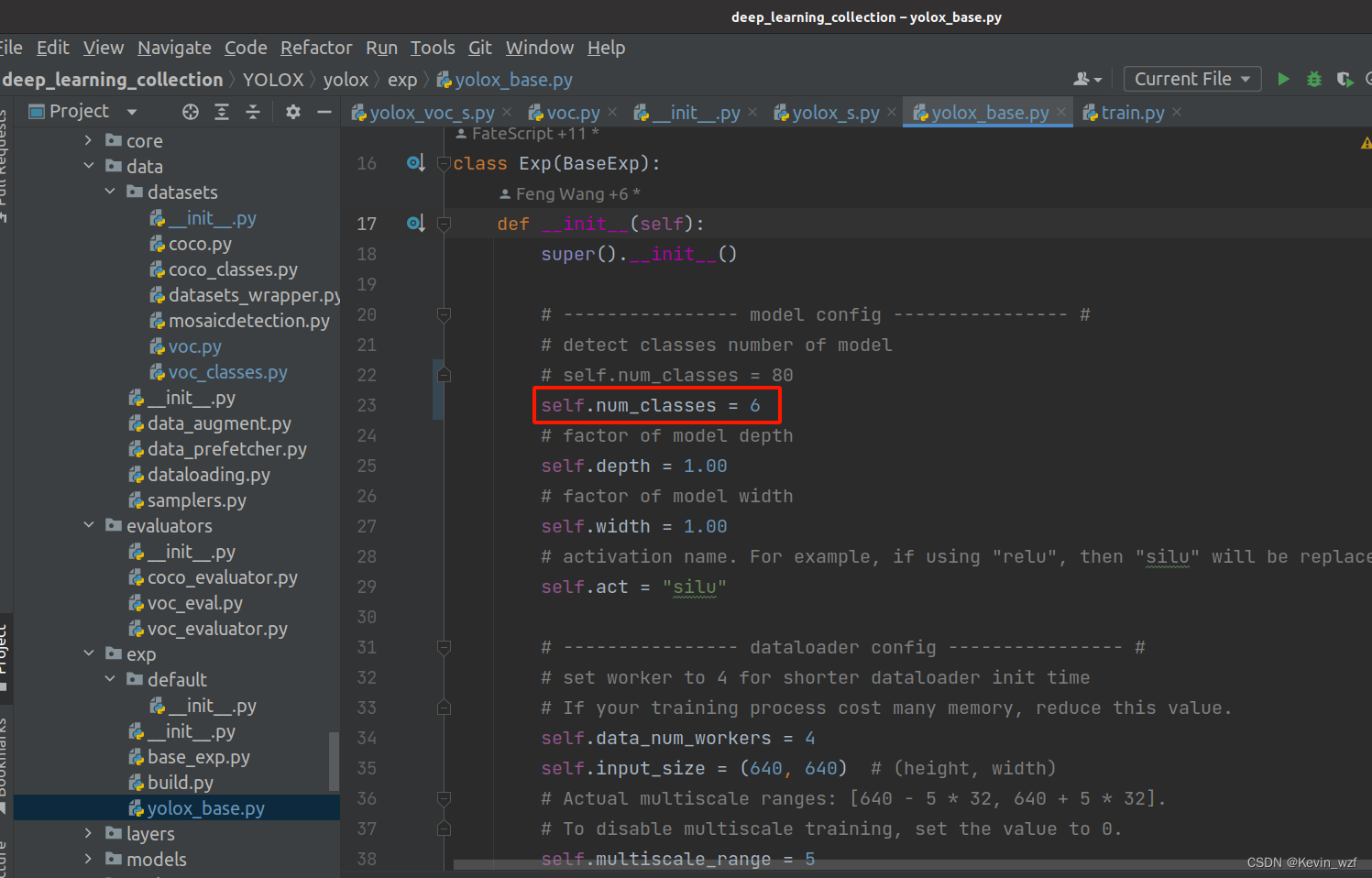
官网是提供了一个训练自己的数据教程,它也是基于VOC的那个脚本来修改,完整的基础类是在YOLOX/yolox/exp/yolox_base.py中,可以根据自己情况来继承使用。
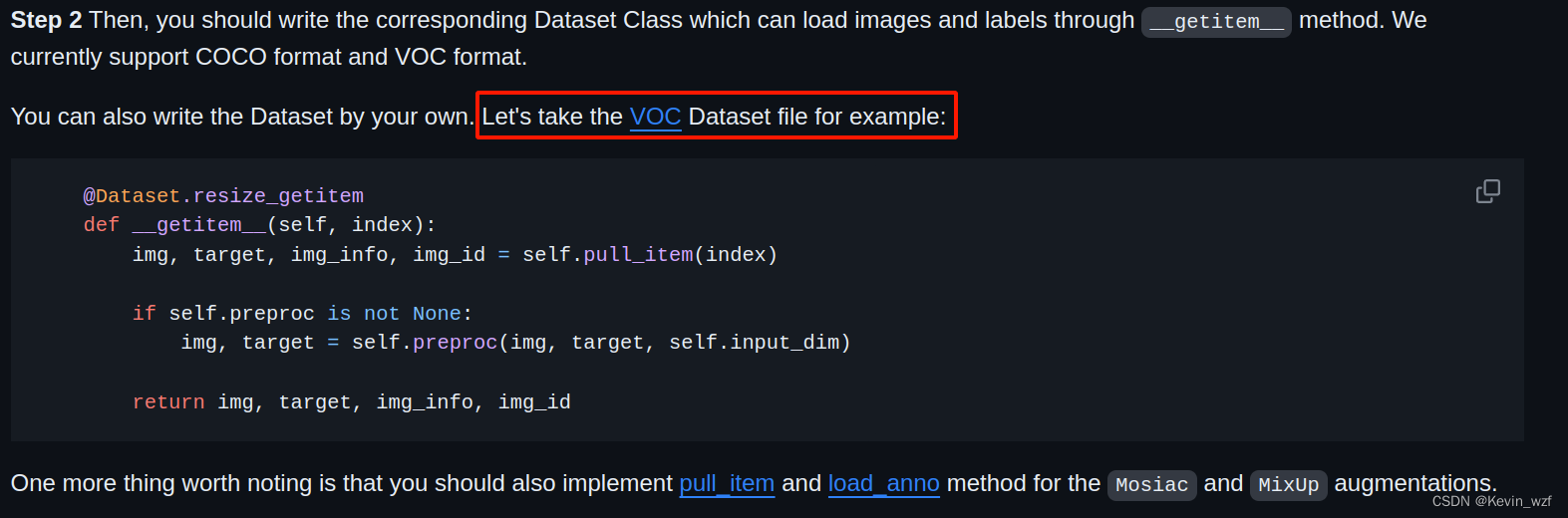
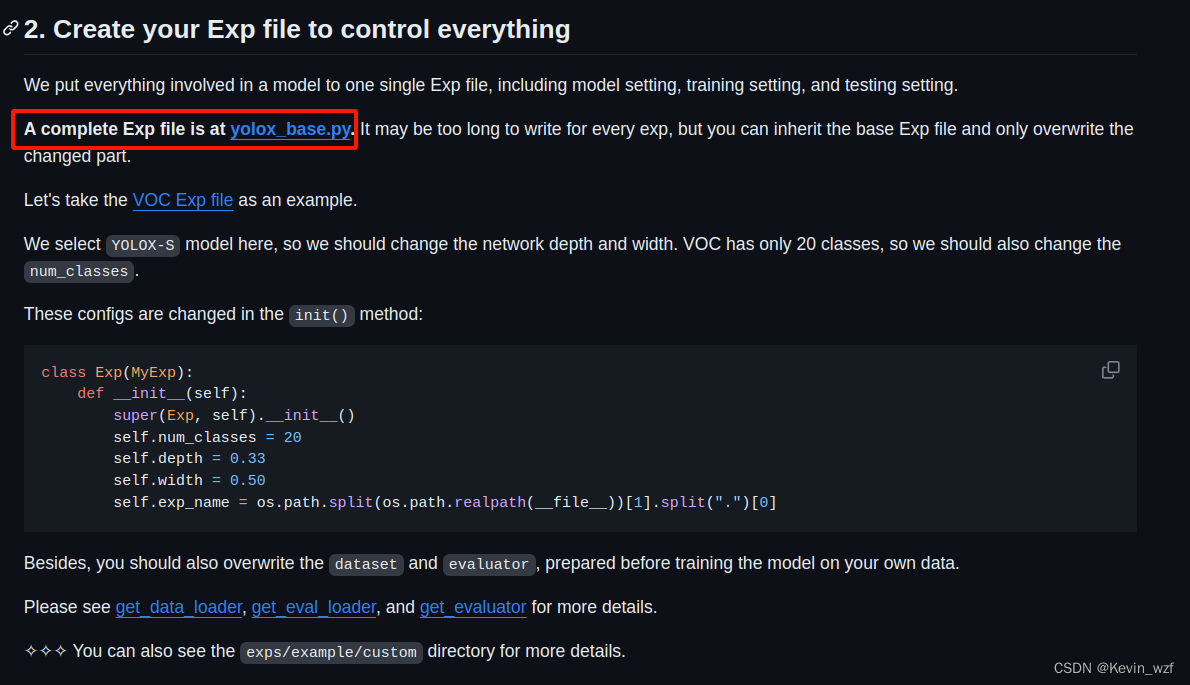
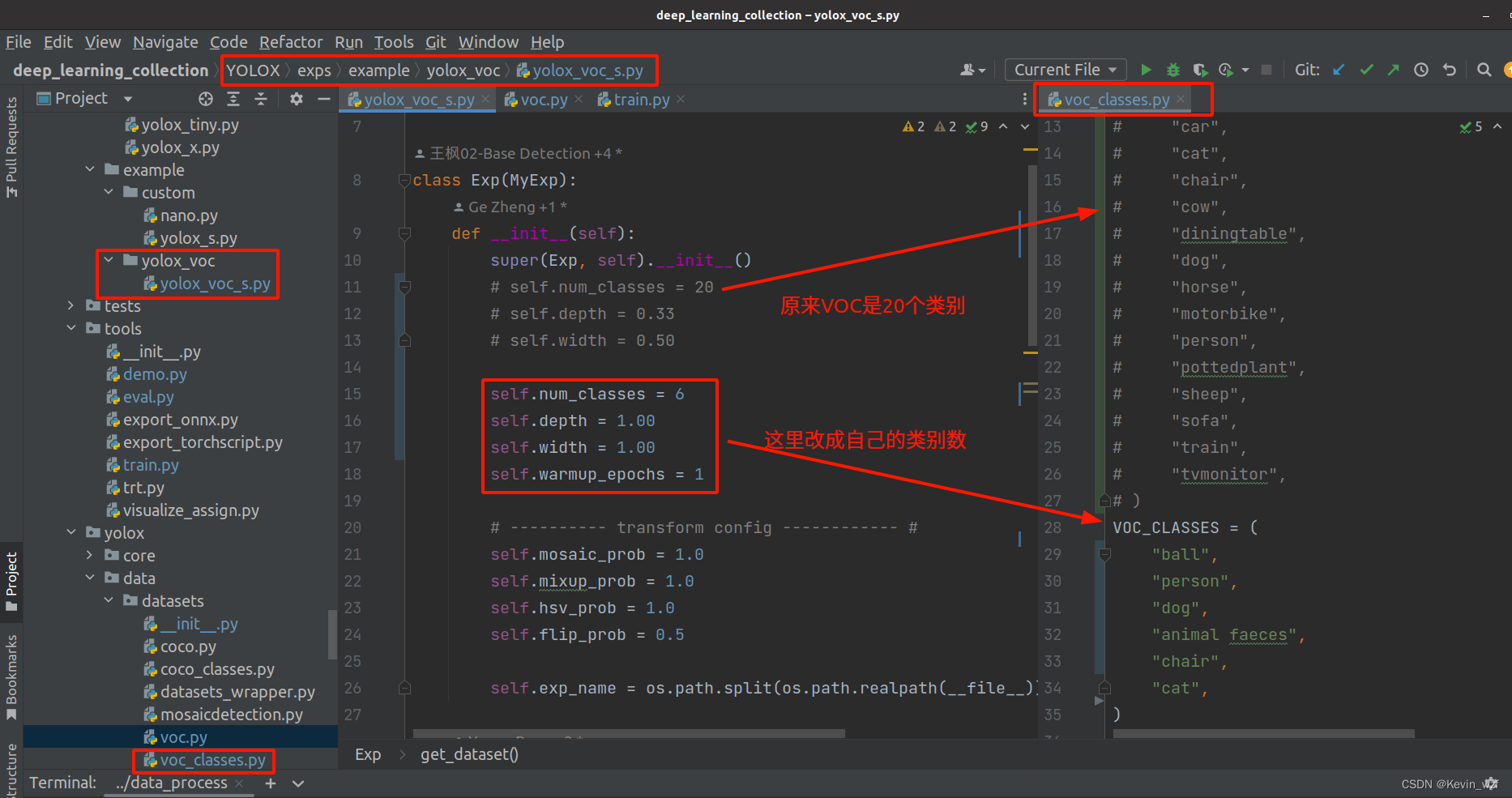
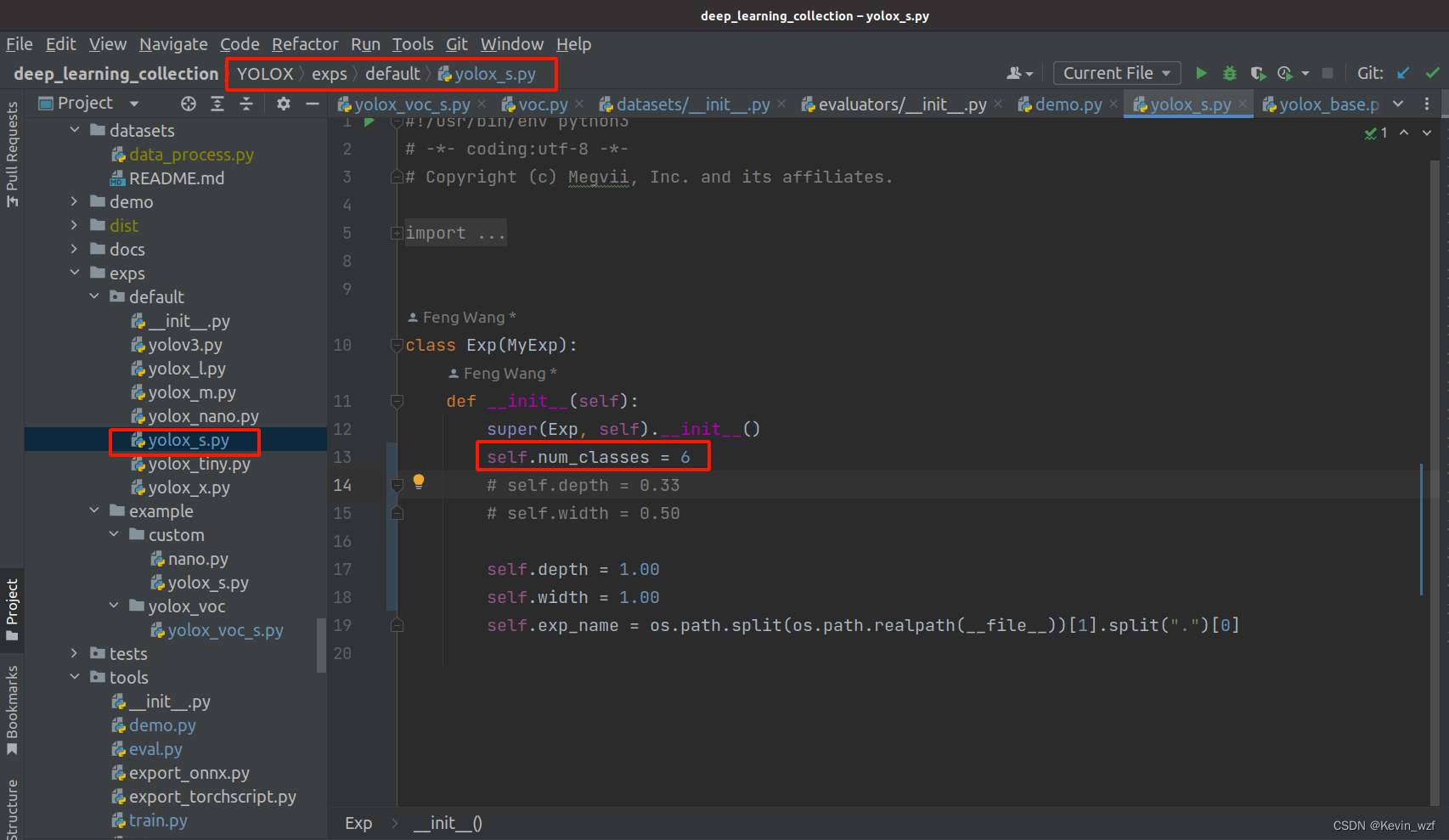
2.修改对应参数文件
(修改类别和数据集的路径)
YOLOX/exps/example/yolox_voc/yolox_voc_s.py 和
YOLOX/exps/default/yolox_s.py
YOLOX/yolox/exp/yolox_base.py
--------------------------------------------------------------------------------------------------------------
(修改类别名)
YOLOX/yolox/data/datasets/voc_classes.py
--------------------------------------------------------------------------------------------------------------
(导入对应包)
YOLOX/yolox/data/datasets/__init__.py

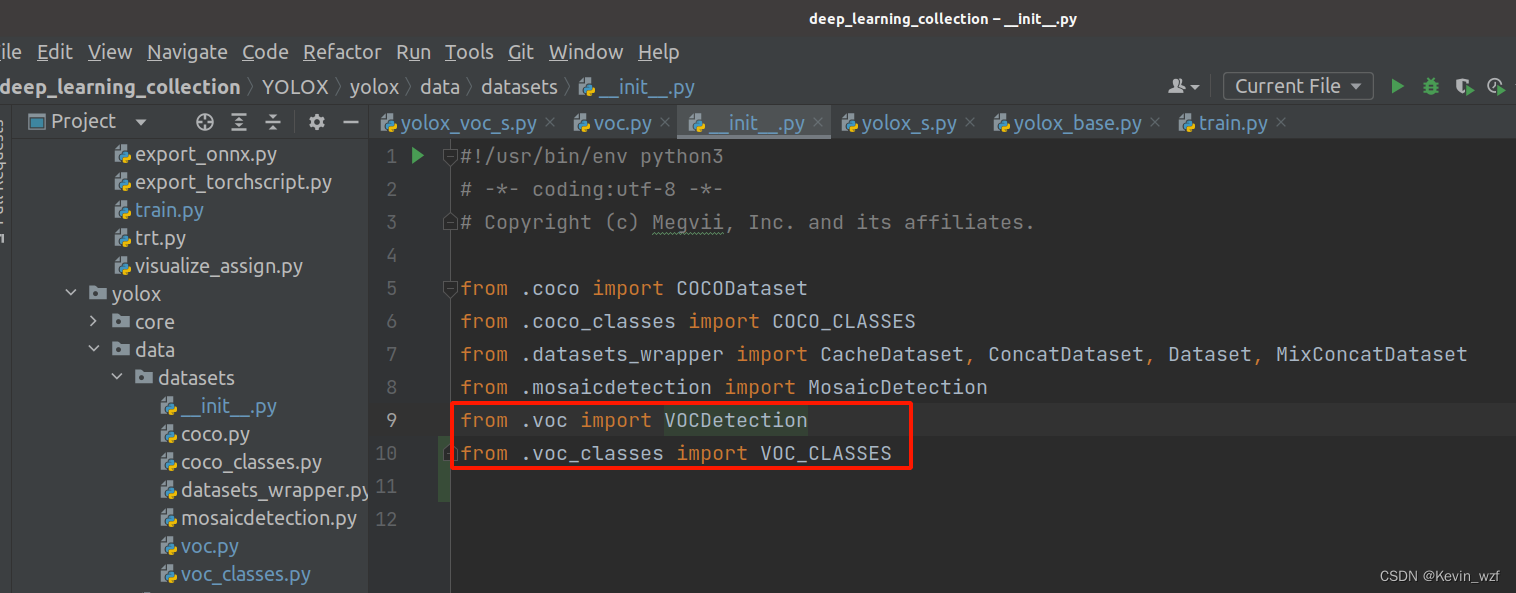
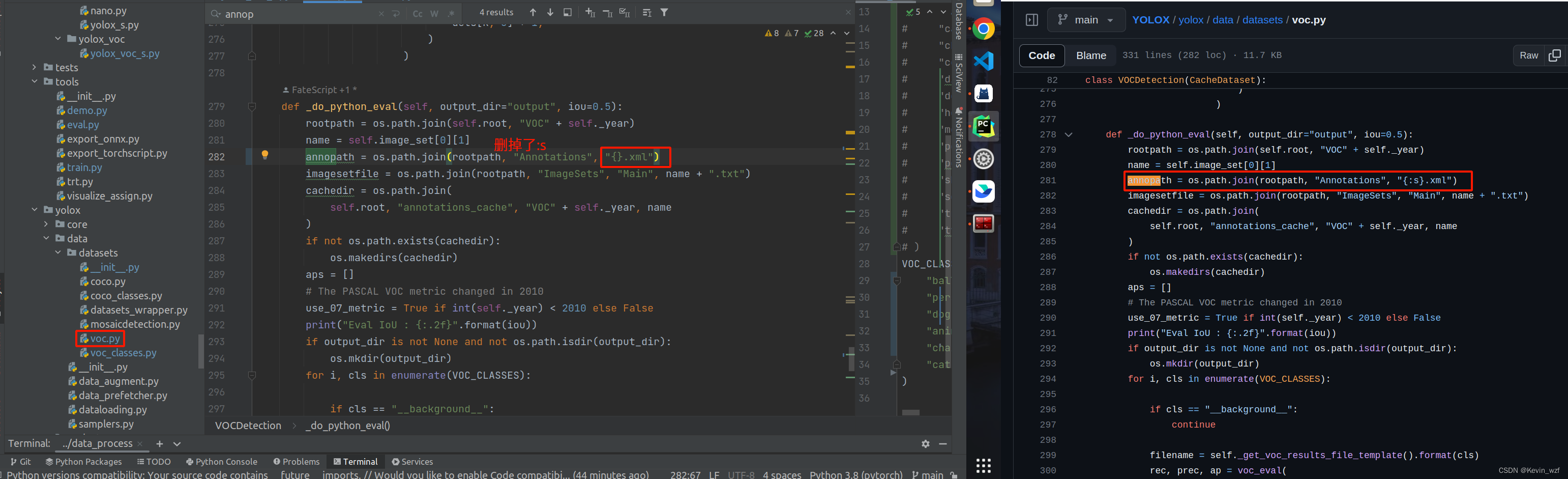
3.修改训练配置文件
我忘了当时是报了哪个错误,我就在YOLOX/tools/train.py增加了以下代码,可以了。
# 检查args.opts是否为偶数长度
if len(args.opts) % 2 != 0:
raise ValueError("args.opts长度必须是偶数")
# 将args.opts列表转换为字典
cfg_dict = dict(args.opts)
# 将字典转换为键值对列表
cfg_list = list(cfg_dict.items())
exp.merge(args.opts)
check_exp_value(exp)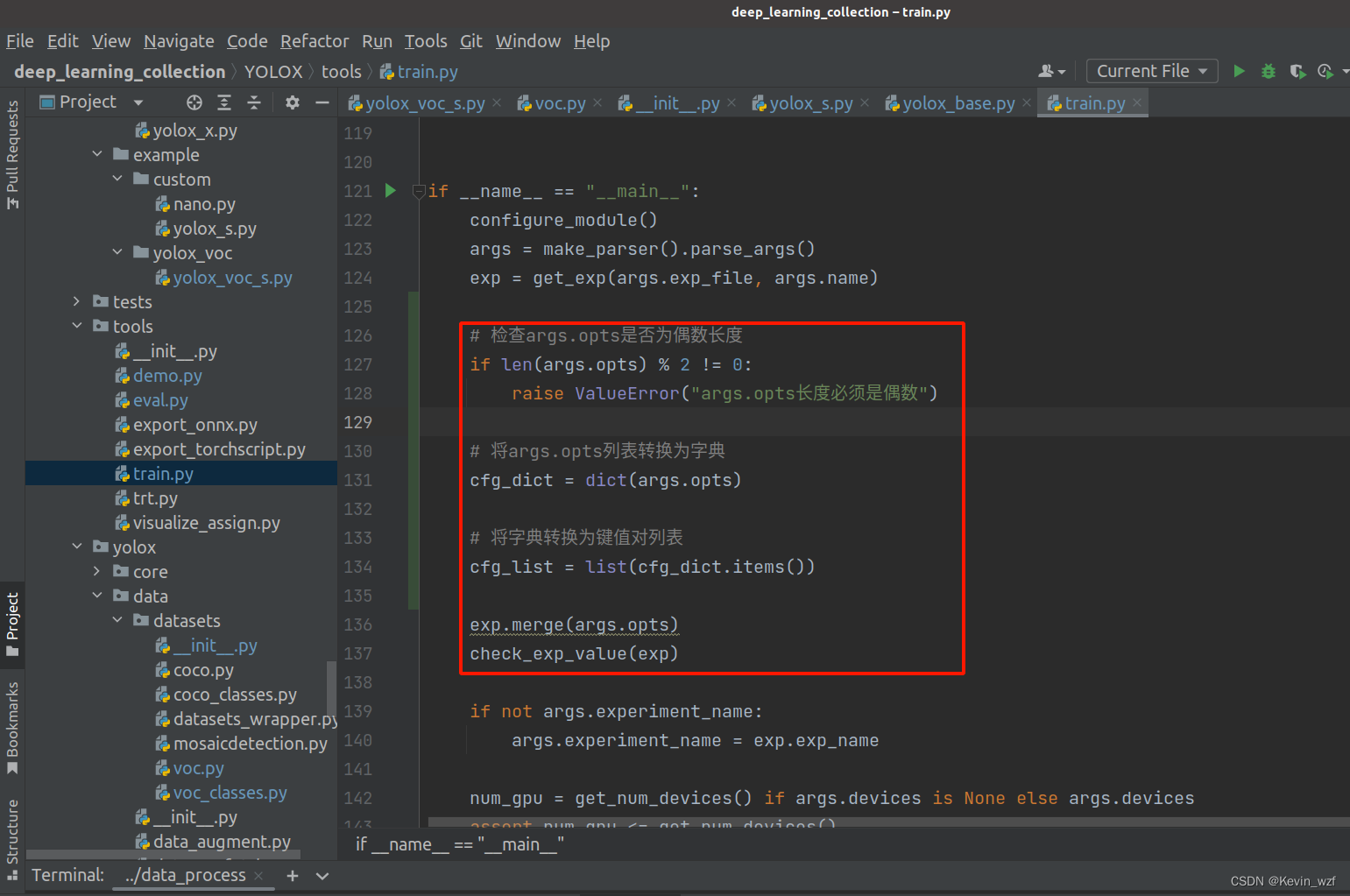
PS:训练的时候,根据自己的显卡和内存情况配置,我只有1张RTX3060(6G独显),device是1,我的笔记本电脑是16G内存,bath_size太高,显存也爆了,最好是以4的倍数,从4开始调大尝试。

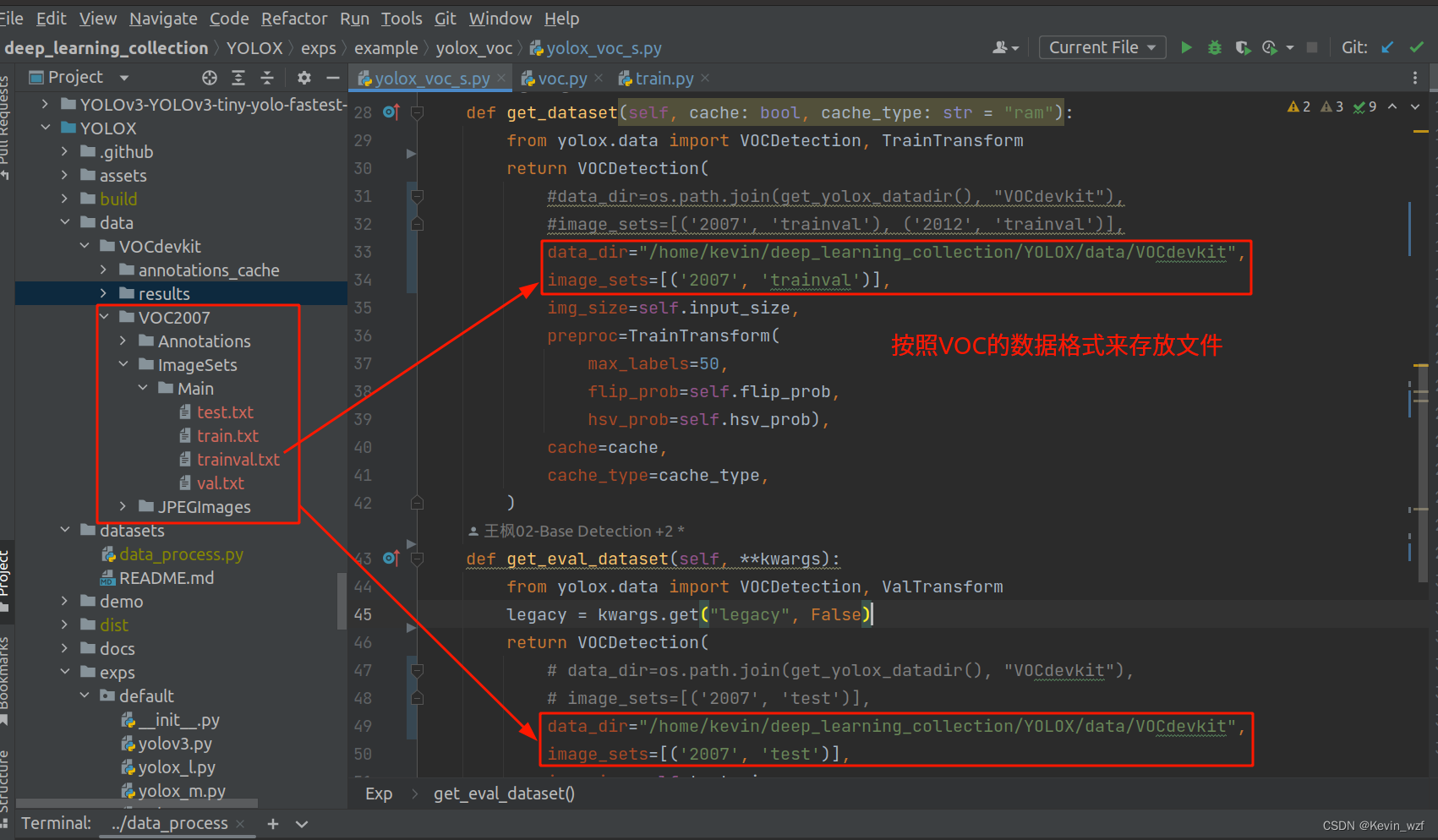
4.数据集缓存问题(一个小坑)
PS: 注意训练的时候,如果第一次数据训练正常的时候,代码是会自动保存一个数据缓存。如果在同一个文件夹中,数据集和数据类别更改了,记得要删除这个cache的数据缓存,否则会在训练10个epoch时候进行eval验证的时候,会加载上一次的数据缓存,导致标签类别不一致!!!
因为当时我多次确认了自己的文件标注数据和图片是一一对应,类别也是一致的,但是每训练到第10次,准备eval验证就报错,我仔细根据代码报错的地方,加了打印,debug调试,找出问题原因。这个代码是在YOLOX/yolox/evaluators/voc_eval.py

错误如下:
2024-03-22 17:18:37.039 | INFO | yolox.core.trainer:after_train:195 - Training of experiment is done and the best AP is 0.00
2024-03-22 17:18:37.040 | ERROR | yolox.core.launch:launch:98 - An error has been caught in function 'launch', process 'MainProcess' (60414), thread 'MainThread' (140462385472704):
Traceback (most recent call last):
File "tools/train.py", line 149, in <module>
launch(
└ <function launch at 0x7fbf2efc5550>
> File "/home/kevin/deep_learning_collection/YOLOX/yolox/core/launch.py", line 98, in launch
main_func(*args)
│ └ (╒═══════════════════╤═══════════════════════════════════════════════════════════════════════════════════════════════════════...
└ <function main at 0x7fbf225f8790>
File "tools/train.py", line 118, in main
trainer.train()
│ └ <function Trainer.train at 0x7fbf21ebd1f0>
└ <yolox.core.trainer.Trainer object at 0x7fbf21ec28e0>
File "/home/kevin/deep_learning_collection/YOLOX/yolox/core/trainer.py", line 76, in train
self.train_in_epoch()
│ └ <function Trainer.train_in_epoch at 0x7fbf21ebd9d0>
└ <yolox.core.trainer.Trainer object at 0x7fbf21ec28e0>
File "/home/kevin/deep_learning_collection/YOLOX/yolox/core/trainer.py", line 86, in train_in_epoch
self.after_epoch()
│ └ <function Trainer.after_epoch at 0x7fbf21ebdd30>
└ <yolox.core.trainer.Trainer object at 0x7fbf21ec28e0>
File "/home/kevin/deep_learning_collection/YOLOX/yolox/core/trainer.py", line 222, in after_epoch
self.evaluate_and_save_model()
│ └ <function Trainer.evaluate_and_save_model at 0x7fbf21ebc040>
└ <yolox.core.trainer.Trainer object at 0x7fbf21ec28e0>
File "/home/kevin/deep_learning_collection/YOLOX/yolox/core/trainer.py", line 336, in evaluate_and_save_model
(ap50_95, ap50, summary), predictions = self.exp.eval(
│ │ └ <function Exp.eval at 0x7fbf21ebd940>
│ └ ╒═══════════════════╤════════════════════════════════════════════════════════════════════════════════════════════════════════...
└ <yolox.core.trainer.Trainer object at 0x7fbf21ec28e0>
File "/home/kevin/deep_learning_collection/YOLOX/yolox/exp/yolox_base.py", line 360, in eval
return evaluator.evaluate(model, is_distributed, half, return_outputs=return_outputs)
│ │ │ │ │ └ True
│ │ │ │ └ False
│ │ │ └ False
│ │ └ YOLOX(
│ │ (backbone): YOLOPAFPN(
│ │ (backbone): CSPDarknet(
│ │ (stem): Focus(
│ │ (conv): BaseConv(
│ │ (conv): ...
│ └ <function VOCEvaluator.evaluate at 0x7fbf21f2d8b0>
└ <yolox.evaluators.voc_evaluator.VOCEvaluator object at 0x7fbf5314a340>
File "/home/kevin/deep_learning_collection/YOLOX/yolox/evaluators/voc_evaluator.py", line 114, in evaluate
eval_results = self.evaluate_prediction(data_list, statistics)
│ │ │ └ tensor([ 31.7915, 1.2681, 708.0000], device='cuda:0')
│ │ └ {0: (tensor([[129.4546, 42.2768, 285.0400, 295.8495],
│ │ [134.9154, 92.1314, 231.9817, 279.4315],
│ │ [172.1964, ...
│ └ <function VOCEvaluator.evaluate_prediction at 0x7fbf21f2d9d0>
└ <yolox.evaluators.voc_evaluator.VOCEvaluator object at 0x7fbf5314a340>
File "/home/kevin/deep_learning_collection/YOLOX/yolox/evaluators/voc_evaluator.py", line 186, in evaluate_prediction
mAP50, mAP70 = self.dataloader.dataset.evaluate_detections(all_boxes, tempdir)
│ │ │ │ │ └ '/tmp/tmp7z16ebil'
│ │ │ │ └ [[array([[1.91965591e+02, 2.85497398e+01, 2.90244629e+02, 1.22725464e+02,
│ │ │ │ 1.64800957e-02]], dtype=float32), array([],...
│ │ │ └ <function VOCDetection.evaluate_detections at 0x7fbf21f323a0>
│ │ └ <yolox.data.datasets.voc.VOCDetection object at 0x7fbf53c263a0>
│ └ <torch.utils.data.dataloader.DataLoader object at 0x7fbf531cda60>
└ <yolox.evaluators.voc_evaluator.VOCEvaluator object at 0x7fbf5314a340>
File "/home/kevin/deep_learning_collection/YOLOX/yolox/data/datasets/voc.py", line 241, in evaluate_detections
mAP = self._do_python_eval(output_dir, iou)
│ │ │ └ 0.5
│ │ └ '/tmp/tmp7z16ebil'
│ └ <function VOCDetection._do_python_eval at 0x7fbf21f32550>
└ <yolox.data.datasets.voc.VOCDetection object at 0x7fbf53c263a0>
File "/home/kevin/deep_learning_collection/YOLOX/yolox/data/datasets/voc.py", line 306, in _do_python_eval
rec, prec, ap = voc_eval(
└ <function voc_eval at 0x7fbf21f2daf0>
File "/home/kevin/deep_learning_collection/YOLOX/yolox/evaluators/voc_eval.py", line 108, in voc_eval
R = [obj for obj in recs[imagename] if obj["name"] == classname]
│ │ └ 'ball'
│ └ 'mushroom_1244'
└ {'squirrel_377': [{'name': 'squirrel', 'pose': 'Unspecified', 'truncated': 1, 'difficult': 0, 'bbox': [1, 95, 268, 317]}], 's...
KeyError: 'mushroom_1244'5.调训练参数
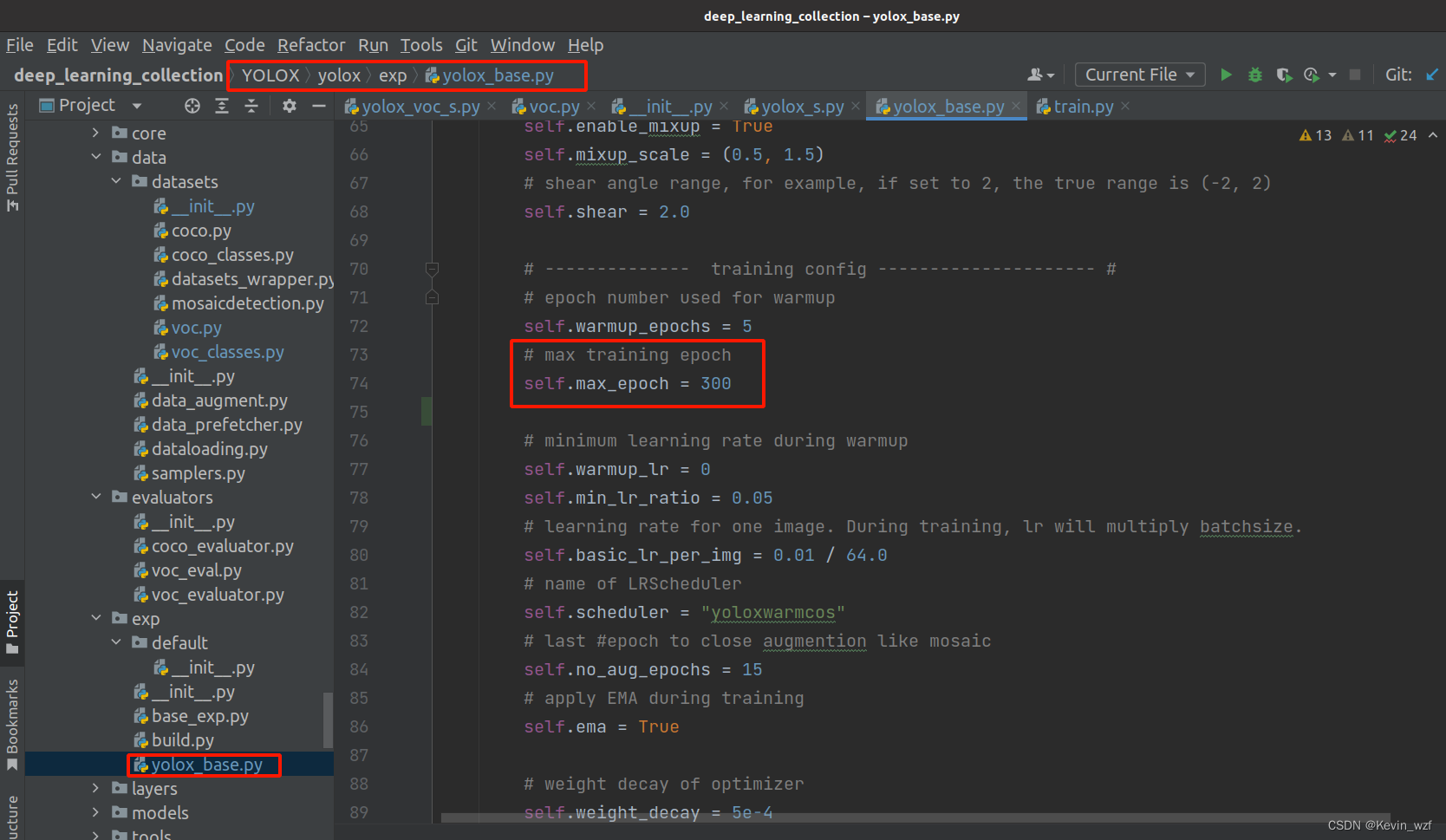
如果想要防止更早的过拟合,可以降低训练max_epoch和降低学习率,我是在YOLOX/yolox/exp/yolox_base.py中修改了max_epoch=300
python tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 1 -b 8 --fp16 yolox_s.pth最后就可以愉快训练了
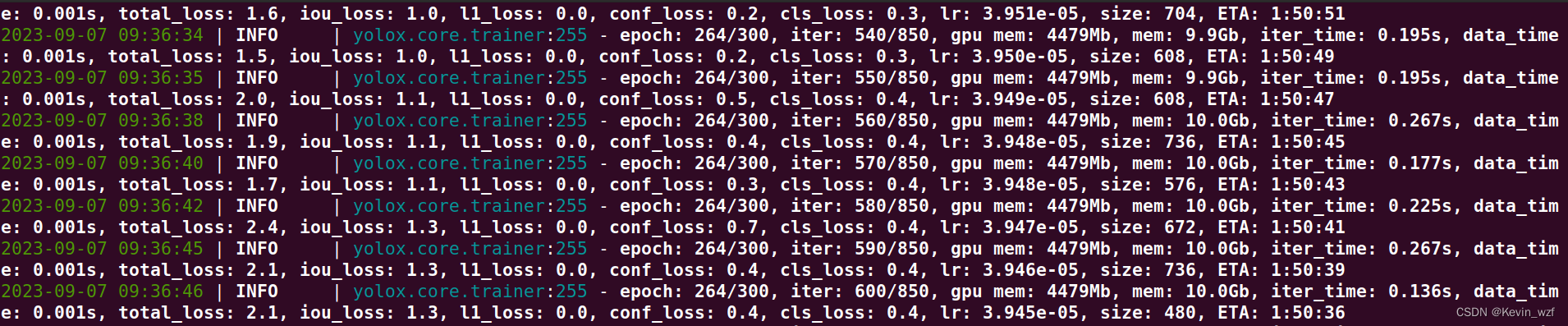
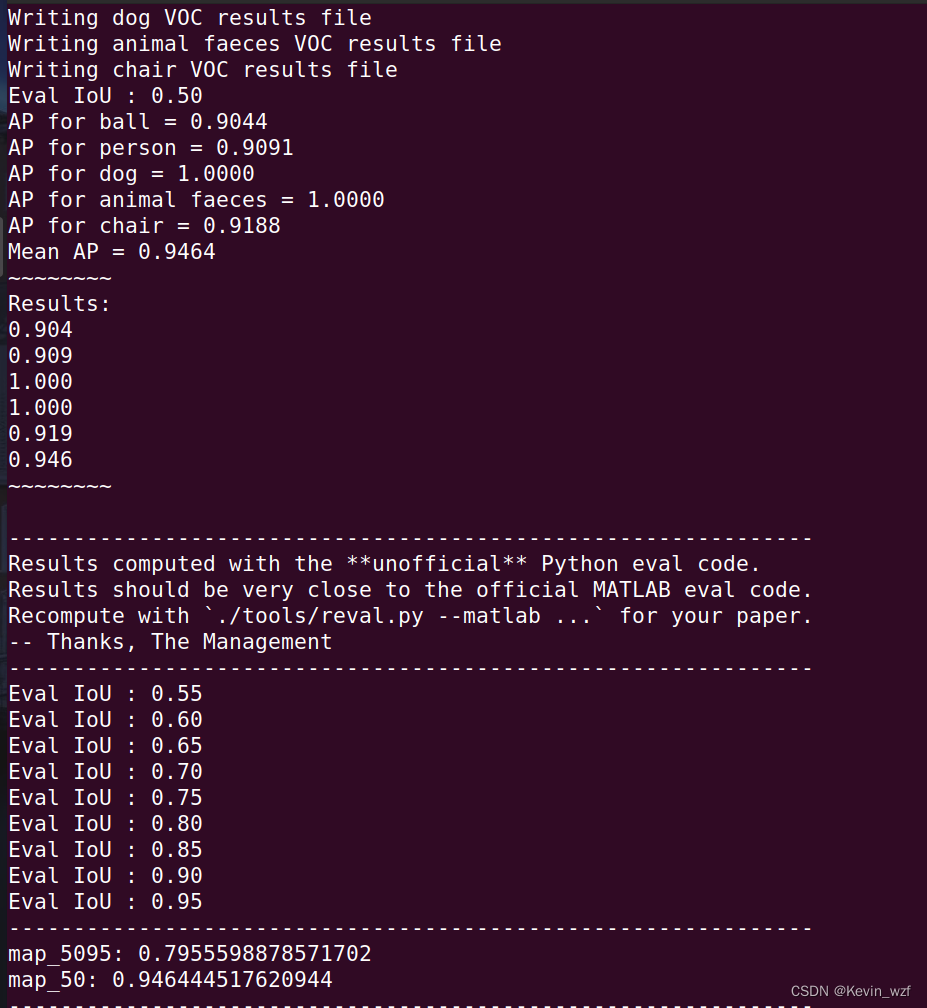

四、YOLOX模型测试验证
经历愉快训练后,准备验证测试,官网是提供了以下两种验证方式,但是要用自己训练出来的模型验证,就只能用-f,不是-n,
python3 tools/demo.py image -f exps/example/yolox_voc/yolox_voc_s.py -c /yolox_voc_s/best_ckpt.pth --path /your_path/JPEGImages/ --conf 0.3 --nms 0.5 --tsize 640 --save_result --device gpu(就是方式三),后面参考issue的解决方法可以了,才发现自己踩了一个大坑!!!自己代码水平有限,所以呵呵。。。折腾了半天。
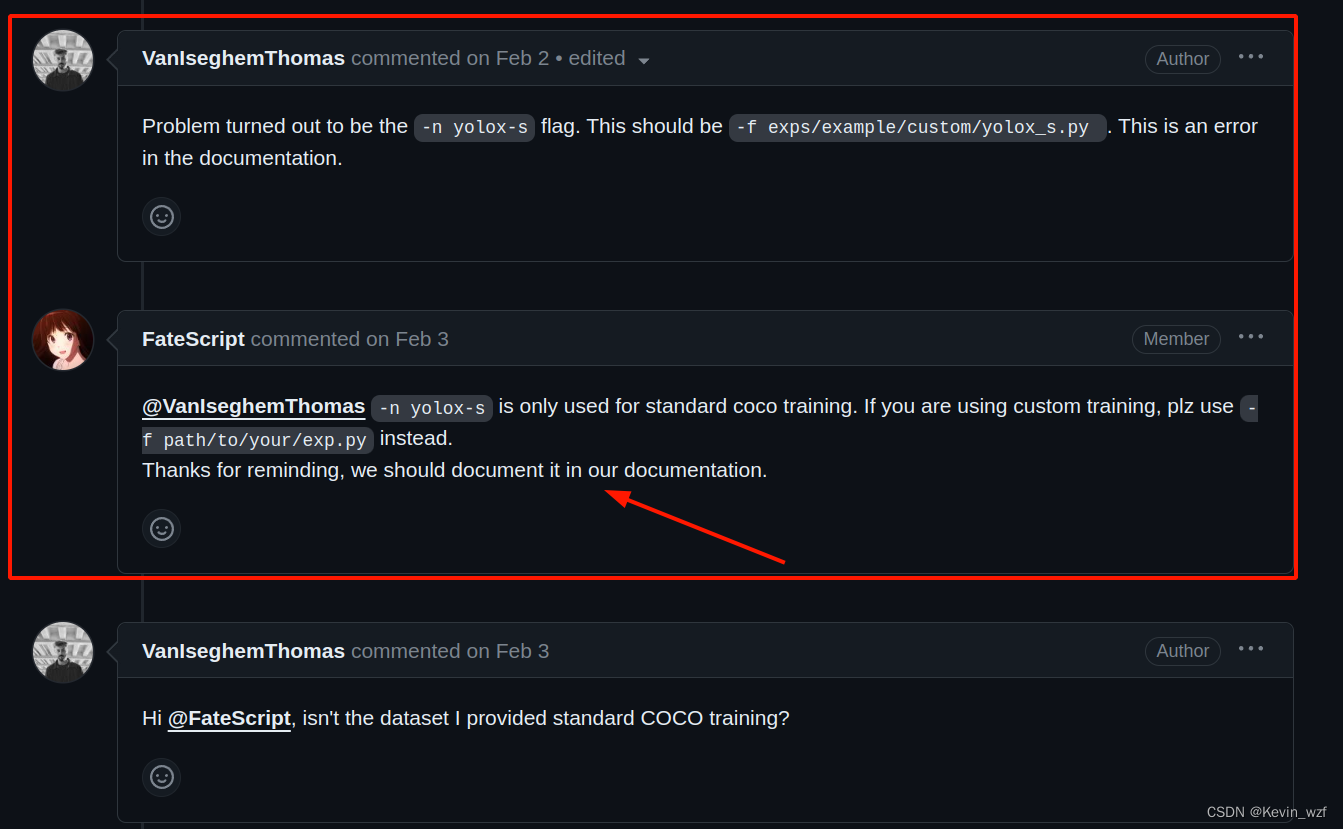
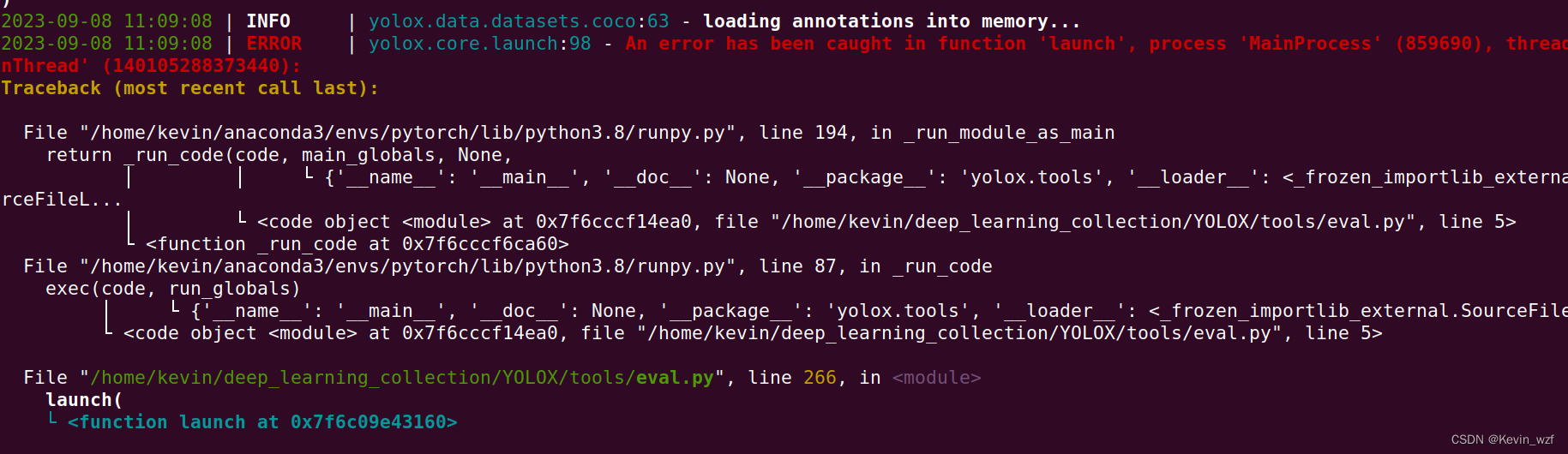
方式一:
python3 -m yolox.tools.eval -n yolox-s -c YOLOX_outputs/yolox_voc_s/best_ckpt.pth -b 1 -d 1 --conf 0.3 --nms 0.5 --tsize 640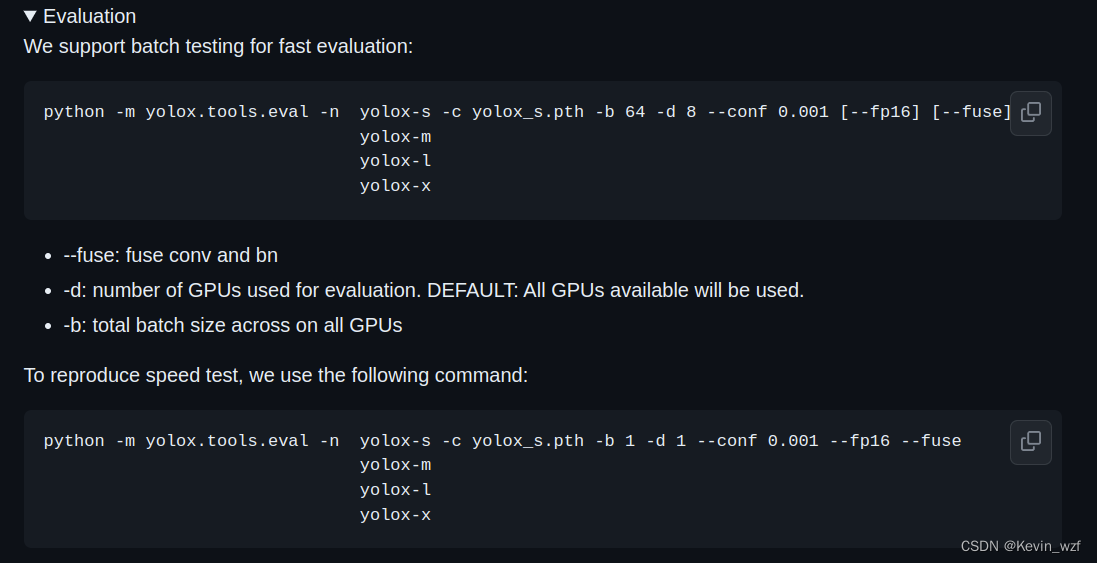
报错:

方式二:
python tools/demo.py image -n yolox-s -c YOLOX_outputs/yolox_voc_s/best_ckpt.pth --path assets/test/ball_400.jpg --conf 0.3 --nms 0.5 --tsize 640 --save_result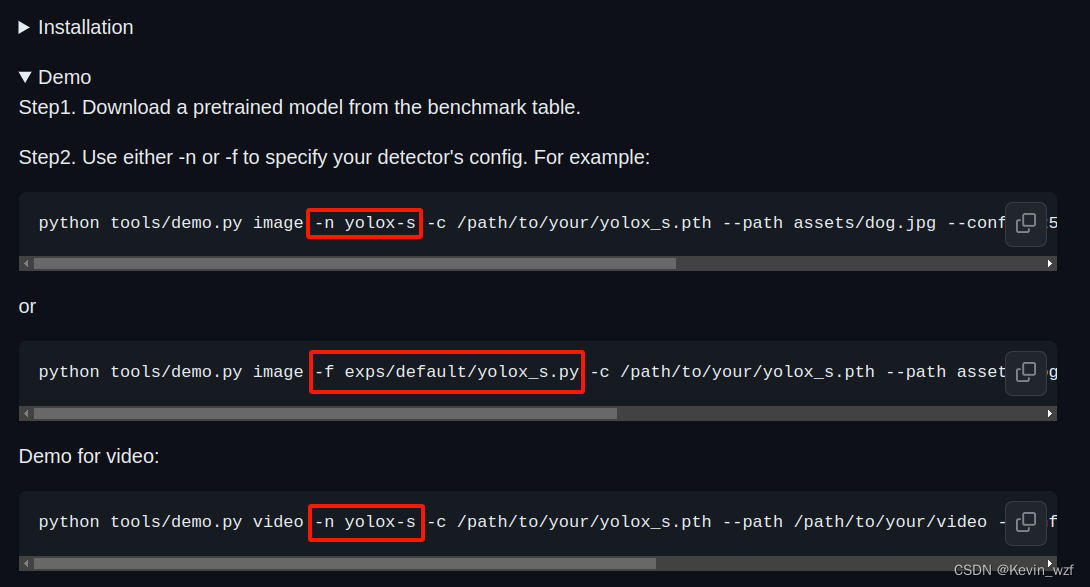
报错:
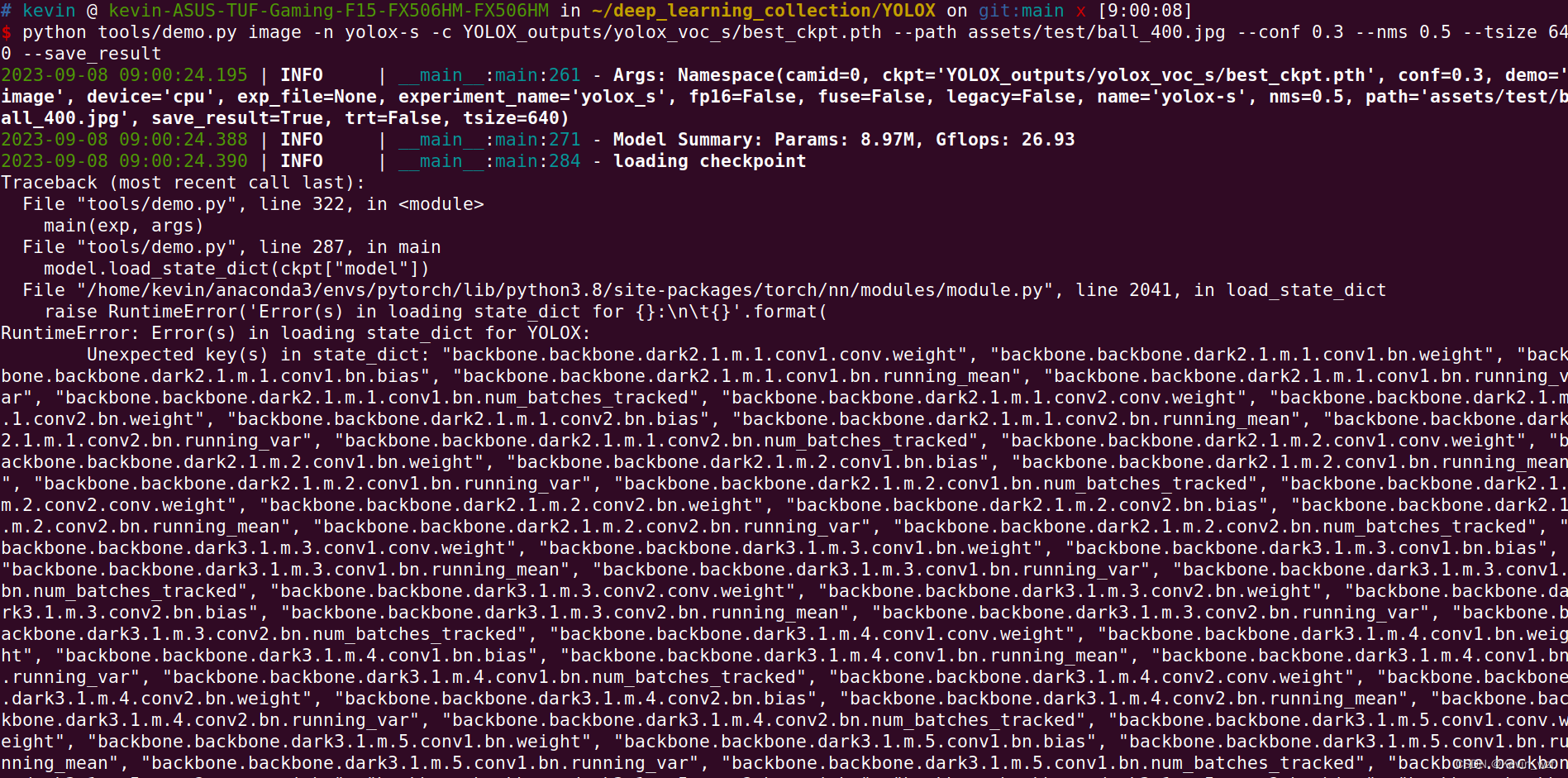
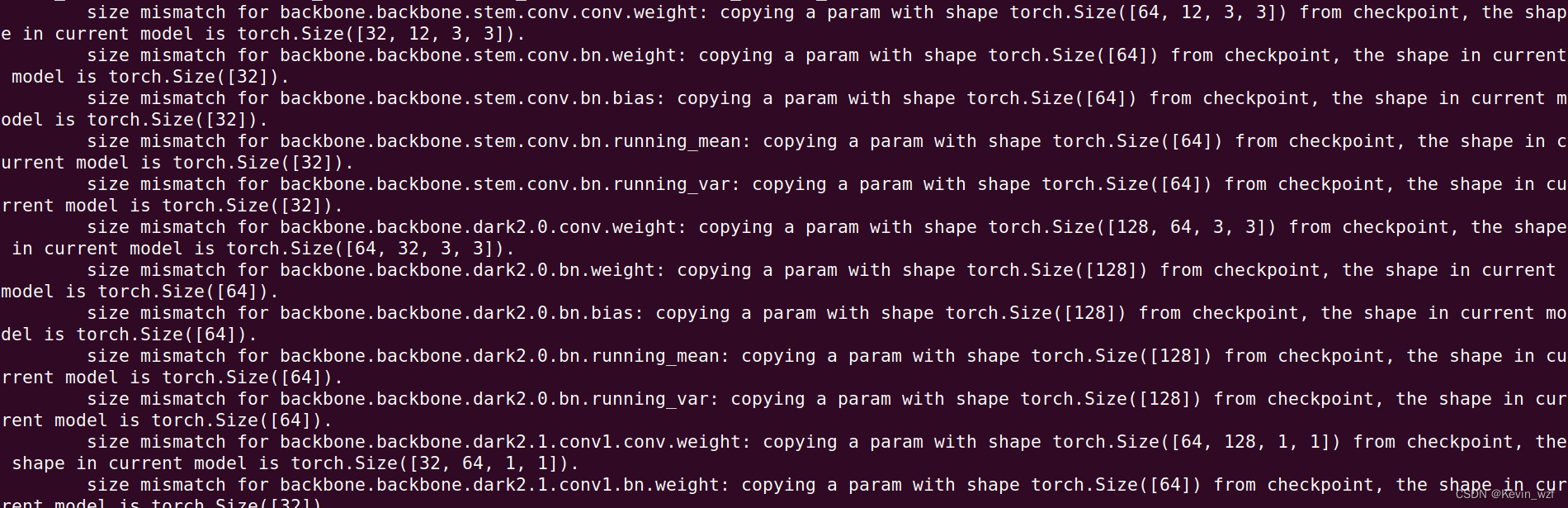
方式三:
python3 tools/demo.py image -f exps/example/yolox_voc/yolox_voc_s.py -c /yolox_voc_s/best_ckpt.pth --path /home/kevin/deep_learning_collection/v831_yolo/data/custom_2/JPEGImages/ --conf 0.3 --nms 0.5 --tsize 640 --save_result --device gpu
五、改造YOLOX/tools/demo.py实现自动标注
过五关斩六将,重点来了,现在把训练出来的模型预测图片可以了,我们就在预测的代码做一些“手脚”,我在class Predictor(object)增加一个save_xml方法 ,修改了image_demo方法,这里有些关键点提醒一下,因为原作者代码是直接输出目标物体类别,检测框bbox的信息,预测分数score。其中,box[0]、box[1]分别是检测框左上角坐标的Xmin、Ymin,box[2]、box[3]分别是检测框右下角坐标的Xmax、Ymax。我这边还要确保预测图片物体是否被边界截断,因此我在代码中增加了一个判断目标物体bbox坐标是否在图像范围内

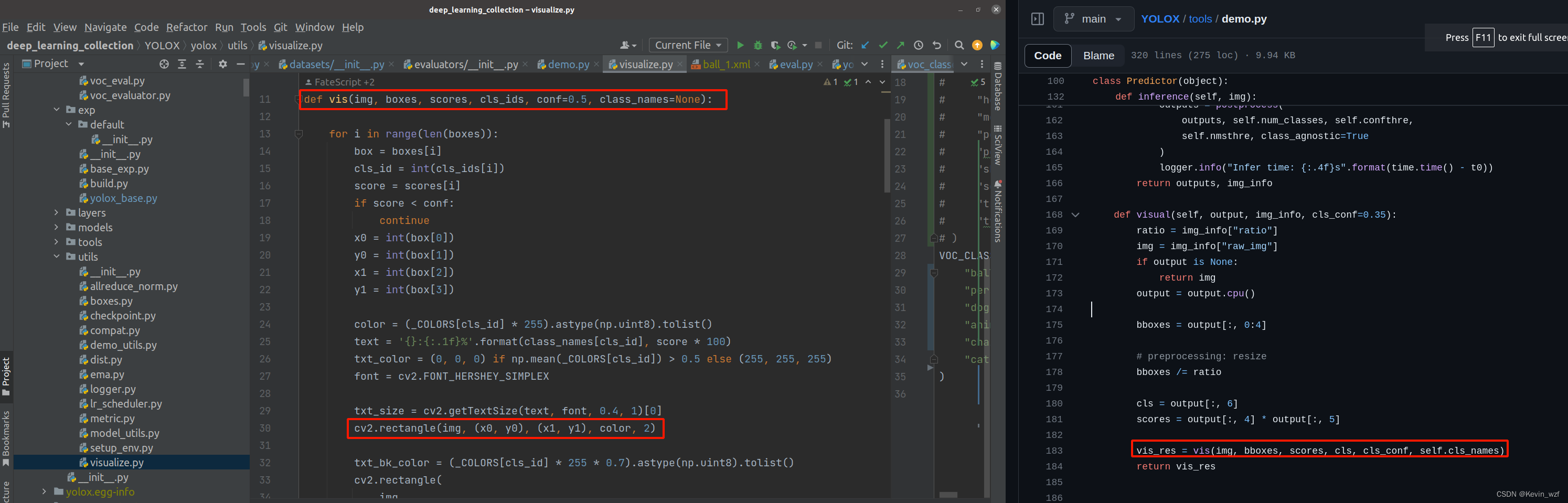
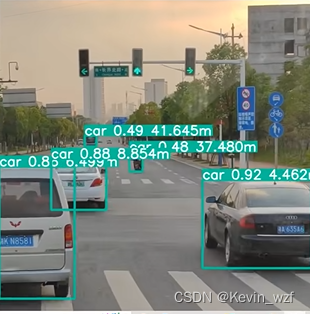
如下图所示,检测物体是否被截断,我个人理解就是会出现以下几种可能性,如果有遗漏或错误可以在评论区留言。
可能性1:左上角顶点坐标里,Xmin坐标<=a 或 Ymin坐标<=a(如下示意图红色框+蓝色框)
可能性2:右下角顶点坐标里,图片宽度width与Xmax坐标之差<=a 或 图片高度heigth与Ymax坐标之差<=a (如下示意图绿色框+蓝色框)
(当然这里a是可以根据个人情况设置,我在代码设置a为2)
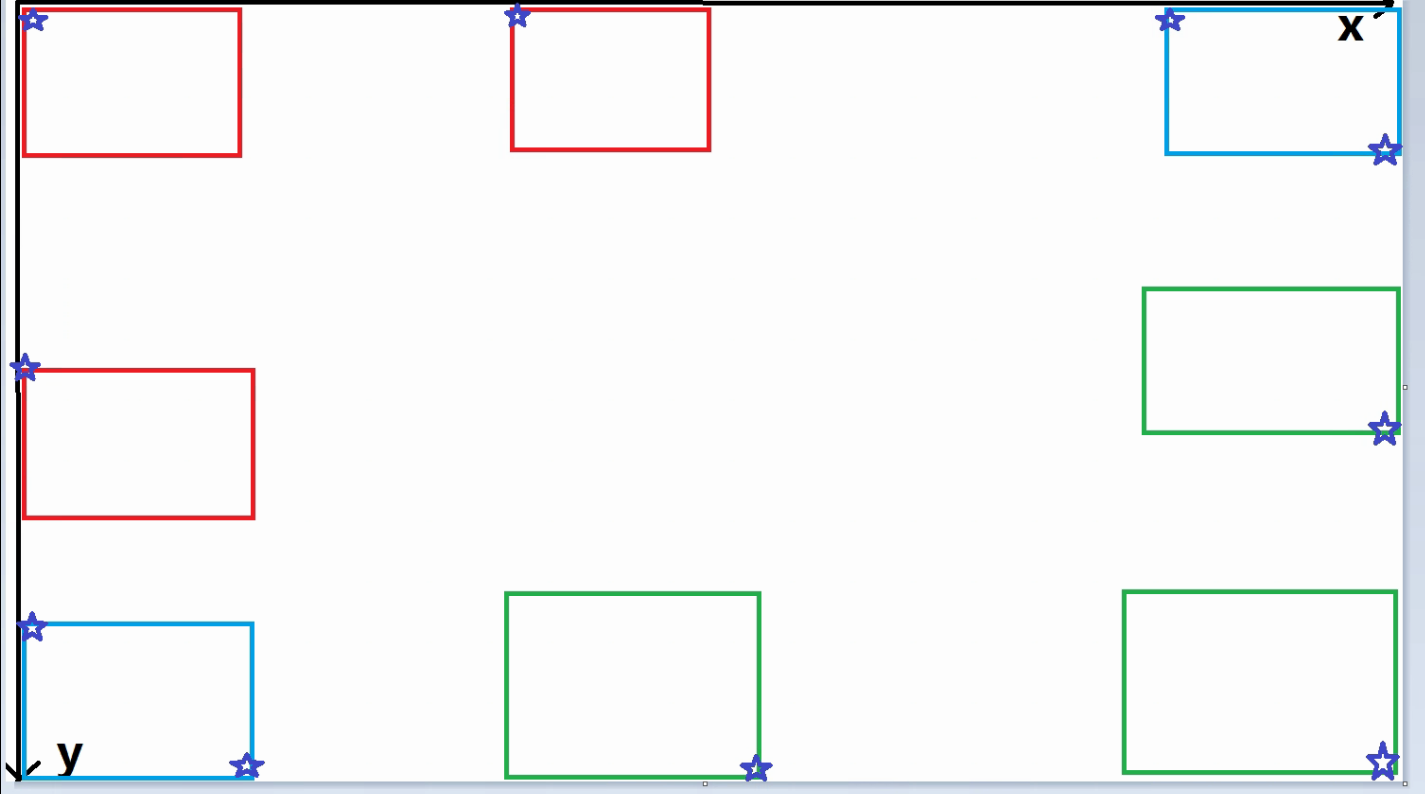
可能性3:图片宽度width与目标框宽度之差<=a 或 图片高度heigth与目标框高度之差<=a,我默认是标注异常,因为这个标注框占图片比例比较大,对训练有影响,所以我在程序上筛选排除掉异常标注的图片
目标框宽度=Xmax-Xmin,即(bbox[2]-bbox[0])
目标框高度=Ymax-Ymin,即(bbox[3]-bbox[1])
(当然这里a是可以根据个人情况设置,我在代码设置a为10)

同时我也加载一些不含目标物体的背景图,以验证自己训练的模型是否会出现误识别,把预测出来的图片分了2个类别文件夹存放,具体看以下代码注释。
def save_xml(self, output, img_info, save_path):
root = ET.Element("annotation")
folder = ET.SubElement(root, "folder")
folder.text = "JPEGImages"
filename = ET.SubElement(root, "filename")
filename.text = img_info["file_name"]
path = ET.SubElement(root, "path")
path.text = "/home/kevin/deep_learning_collection/v831_yolo/data/custom/JPEGImages/"+img_info["file_name"]
source = ET.SubElement(root, "source")
database = ET.SubElement(source, "database")
database.text = "Unknown"
size = ET.SubElement(root, "size")
width = ET.SubElement(size, "width")
width.text = str(img_info["width"])
height = ET.SubElement(size, "height")
height.text = str(img_info["height"])
segmented = ET.SubElement(root, "segmented")
segmented.text = str(int(0))
# 当检测图片,不存在目标物体,提前结束函数
if output is None:
dom = xml.dom.minidom.parseString(ET.tostring(root, encoding="utf-8"))
with open(save_path, "w") as f:
f.write(dom.toprettyxml(indent=" ")[len('<?xml version="1.0" ?>\n'):])
return
for bbox in output:
if bbox is not None:
# 当目标物体检测框宽度与图片宽度之差或检测框高度与图片高度之差不大于10.则为标注异常,不生成该目标物标签
if img_info["width"]-(bbox[2]-bbox[0])<=10 or img_info["height"]-(bbox[3]-bbox[1])<=10:
continue
obj = ET.SubElement(root, "object")
name = ET.SubElement(obj, "name")
name.text = self.cls_names[int(bbox[6])]
pose = ET.SubElement(obj, "pose")
pose.text = "Unspecified"
# 指示目标物体是否被图像边界截断
if bbox[0]<=2 or bbox[1]<=2 or (img_info["width"]-bbox[2])<=2 or (img_info["height"]-bbox[3])<=2:
truncated = 1
else:
truncated = 0
truncated_elem = ET.SubElement(obj, "truncated")
truncated_elem.text = str(int(truncated))
# 目标物体的遮挡、模糊、形状变形等困难识别情况
pose = ET.SubElement(obj, "difficult")
pose.text = str(int(0))
bndbox = ET.SubElement(obj, "bndbox")
xmin = ET.SubElement(bndbox, "xmin")
xmin.text = str(int(bbox[0]))
ymin = ET.SubElement(bndbox, "ymin")
ymin.text = str(int(bbox[1]))
xmax = ET.SubElement(bndbox, "xmax")
xmax.text = str(int(bbox[2]))
ymax = ET.SubElement(bndbox, "ymax")
ymax.text = str(int(bbox[3]))
dom = xml.dom.minidom.parseString(ET.tostring(root, encoding="utf-8"))
with open(save_path, "w") as f:
f.write(dom.toprettyxml(indent=" ")[len('<?xml version="1.0" ?>\n'):]
def image_demo(predictor, vis_folder, path, current_time, save_result):
if os.path.isdir(path):
files = get_image_list(path)
else:
files = [path]
files.sort()
for image_name in files:
outputs, img_info = predictor.inference(image_name)
result_image = predictor.visual(outputs[0], img_info, predictor.confthre)
if save_result:
save_folder = os.path.join(
vis_folder, time.strftime("%Y_%m_%d_%H_%M_%S", current_time)
)
JPEGImages_folder = os.path.join(save_folder, "JPEGImages")
os.makedirs(JPEGImages_folder, exist_ok=True)
save_file_path = os.path.join(JPEGImages_folder, os.path.basename(image_name))
logger.info("Saving detection result in {}".format(save_file_path))
cv2.imwrite(save_file_path, result_image)
# 当检测图片,不存在目标物体,另外存放到指定文件夹
none_output_file = os.path.join(save_folder, "none_output.txt")
none_output_folder = os.path.join(save_folder, "none_output")
os.makedirs(none_output_folder, exist_ok=True)
none_output_file_path = os.path.join(none_output_folder, os.path.basename(image_name))
if outputs[0] is None:
cv2.imwrite(none_output_file_path, result_image)
# 把没有结果输出的文件输出到一个txt文件,进行二次排查
with open(none_output_file, 'a') as f:
f.write(img_info["file_name"] + '\n')
# Save XML file
Annotations_folder = os.path.join(save_folder, "Annotations")
os.makedirs(Annotations_folder, exist_ok=True)
xml_file_name = os.path.splitext(os.path.basename(image_name))[0] + ".xml"
xml_file_path = os.path.join(Annotations_folder, xml_file_name)
predictor.save_xml(outputs[0], img_info, xml_file_path)
ch = cv2.waitKey(0)
if ch == 27 or ch == ord("q") or ch == ord("Q"):
break
最后就是把这些输出的信息封装成一个方法,转成xml格式文件,这样就可以完成“自动标注”(用自己的训练的模型预测所有图片)
<annotation>
<folder>JPEGImages</folder>
<filename>ball_1.jpg</filename>
<path>/home/kevin/deep_learning_collection/v831_yolo/data/custom/JPEGImages/ball_1.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>640</width>
<height>480</height>
</size>
<segmented>0</segmented>
<object>
<name>ball</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>31</xmin>
<ymin>242</ymin>
<xmax>245</xmax>
<ymax>437</ymax>
</bndbox>
</object>
</annotation>
六、致谢
本文章也是参考了以下博客,感谢大佬们的分享。YOLOX训练自己的数据集(包含自己数据集,预训练模型,代码公开),踩扁很多细节坑全部补充
最后,十分感谢github社区开源的YOLOX代码,以及旷视团队和Dr. Jian Sun的无私贡献,在这里向前辈们致敬。因为我平时工作比较忙,之前一直忙项目,耽搁了这件事,趁今天周末有空就赶紧写完,希望能抛砖引玉,与君共勉,一起推动AI的发展。
我把修改后的代码放在下方的链接,大家可以根据自己的情况修改,如果能帮到大家,希望给个star,Thank you so much!