目录:
1. Visdrone2018数据集的介绍及下载;
2. Visdrone2018数据集标签格式转换;
3. YoloV3算法模型代码的调整以及模型的训练;
4. 总结;
(按照VOC格式生成的图片XML文件有需要的可留言)
前言:
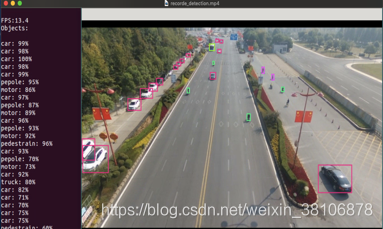
学渣的生活就是拿着各种数据集在算法上各种训练、各种玩……当然,个人觉得还是有意思的,在你有一台Bebop2无人机的情况下,结合本人前面的博客,搭建一个无人机实时目标检测平台,再配合这个检测模型,还是相对有点意思的。先看一下训练后模型的检测效果吧,无人机实时传输回来的图像在工作站上实时的检测效果(在视频上测试的,照片为截图),你再决定是不是要看本篇博客接下来的内容。要是觉得效果不是你想要的,你就不会浪费时间了…………为什么要去掉检测框的名字,是因为有名字,整个检测的画面好难看,至于怎么去掉检测框的名字,只需要屏蔽image.c代码中
draw_label(im, top + width, left, label, rgb)
函数即可!
(视频观看链接:https://www.youtube.com/watch?v=5EITG1rbAHc&t=36s
B站:https://www.bilibili.com/video/av54517585?from=search&seid=11504153865247579114)
一.Visdrone2018数据集的介绍及下载
1.数据集的介绍:http://www.aiskyeye.com/views/index
2.数据下载的主页:http://www.aiskyeye.com/my/downloadD
3.在本次训练中,用到了Task1:Object Detection in Images的两部分实验数据:
Trainset(1.44GB)、Valset(0.07GB) 数据分别可通过百度云和google云下载;
4.数据下载好后解压放在同一文件夹内,以便后面的步骤使用;
二.Visdrone2018数据集标签格式转换
在该部分,实验中通过代码将Visdrone数据集标签格式转换至Darknet所需要的格式;
该部分代码,需要运行两次,放在两部分实验数据集(Train、Val)的目录下,分别运行即可;
运行后,每个文件夹里面会生成image.txt文件。(为了后面更加容易区分训练和验证的数据,在运行代码时可以修改改文件的名字,例如:train.txt、val.txt)
代码如下:(脚本参考来源于github,若有侵权,将及时删除!感谢每一位开源分享的大神!)
import os
from pathlib import Path
from PIL import Image
import csv
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[2] / 2) * dw
y = (box[1] + box[3] / 2) * dh
w = box[2] * dw
h = box[3] * dh
return (x, y, w, h)
wd = os.getcwd()
if not os.path.exists('labels'):
os.makedirs('labels')
train_file = 'images.txt'
train_file_txt = ''
anns = os.listdir('annotations')
for ann in anns:
ans = ''
outpath = wd + '/labels/' + ann
if ann[-3:] != 'txt':
continue
with Image.open(wd + '/images/' + ann[:-3] + 'jpg') as Img:
img_size = Img.size
with open(wd + '/annotations/' + ann, newline='') as csvfile:
spamreader = csv.reader(csvfile)
for row in spamreader:
if row[4] == '0':
continue
bb = convert(img_size, tuple(map(int, row[:4])))
ans = ans + str(int(row[5])-1) + ' ' + ' '.join(str(a) for a in bb) + '\n'
with open(outpath, 'w') as outfile:
outfile.write(ans)
train_file_txt = train_file_txt + wd + '/images/' + ann[:-3] + 'jpg\n'
with open(train_file, 'w') as outfile:
outfile.write(train_file_txt)
三.YoloV3算法模型代码的调整以及模型的训练
1.创建visdrone.data文件(按照如下方式修改)
classes= 10
train = /path/to/visdrone_train_dataset/images.txt
valid = /path/to/visdrone_val_dataset/images.txt
names = data/visdrone.names
backup = backup
2.修改yolov3-voc.cfg文件
修改三处:(random参数可根据自己电脑GPU性能调整)
(第一部分)
[convolutional]
size=1
stride=1
pad=1
filters=45 ##255 f=3*(class+5)
activation=linear
[yolo]
mask = 6,7,8
achors=10,13, 16,30, 33,23, 30,61, 62, 45, 50.119, 116,90, 156,198, 373,326
classes=10 ##80
num=9
jitter=.3
ignore_thresh=.7
truth_thresh=1
random=1
(第二部分)
[convolutional]
size=1
stride=1
pad=1
filters=45 ##255 f=3*(class+5)
activation=linear
[yolo]
mask = 3,4,5
achors=10,13, 16,30, 33,23, 30,61, 62, 45, 50.119, 116,90, 156,198, 373,326
classes=10 ##80
num=9
jitter=.3
ignore_thresh=.7
truth_thresh=1
random=1
(第三部分)
[convolutional]
size=1
stride=1
pad=1
filters=45 ##255 f=3*(class+5)
activation=linear
[yolo]
mask = 0,1,2
achors=10,13, 16,30, 33,23, 30,61, 62, 45, 50.119, 116,90, 156,198, 373,326
classes=10 ##80
num=9
jitter=.3
ignore_thresh=.7
truth_thresh=1
random=1
3.修改.names文件
阅读Visdrone官方.md文件可知道共计10类目标,visdrone.names:
pedestrian
people
bicycle
car
van
truck
tricycle
awning-tricycle
bus
motor
4.模型Train起来(用的是darknet53.conv.74这个pretrain_model)
./darknet detector train cfg/visdrone.data cfg/yolov3-voc-visdrone.cfg darknet53.conv.74
注:若你有需求将txt转为xml
将visdrone数据集的txt标签装换为voc格式的xml的脚本在这篇博客上,博客底部有数据集下载的baidu网盘地址:
https://blog.csdn.net/weixin_38106878/article/details/105580678
四.总结
最终,模型在一块1060显卡上迭代了50200次,大概花费了四天左右的时间,得到了最终的模型。对了,最终的loss没有很理想的收敛下来,貌似记的是在15的样子,不知道是不是数据太复杂了,还是迭代的次数不够。要是你们能够更好的收敛,欢迎交流!!**若需要数据的可通过本人百度网盘分享!
本篇博客若有不足,请多多谅解,互相学习,互相进步~未来会做更多相关的算法的实验!(预计下一篇博客的内容:改进YOLO网络框架来实现更加高效的检测(实验已经做完,有时间就把博客写上来!))**
最后再来一张检测结果的截图!!