1.论文阅读:
摘要:
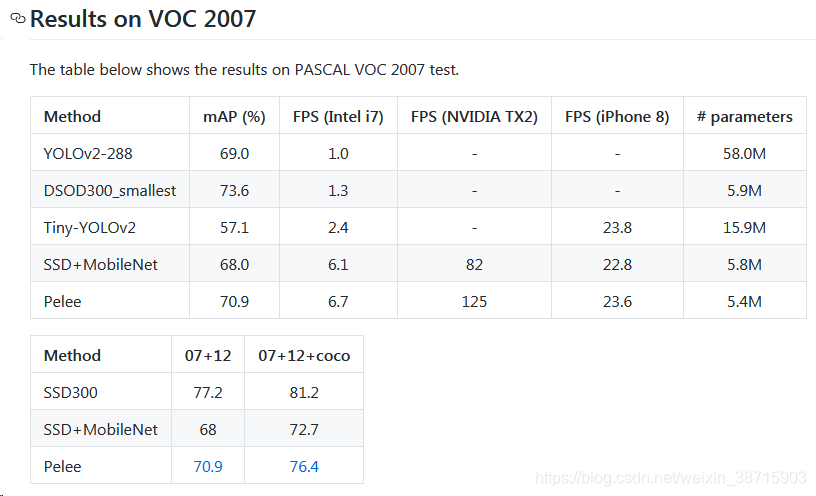
- VOC 2007:76.4%;MS coco:22.4%
- 速度:iPhone8的速度为23.6 fps,Nvidia TX2的速度为125 fps。
引言:
【MobileNet、ShuffleNet、MobileNet v2等相继被提出,这些模型都过度依赖于depthwise卷积,而深度可分离卷积缺乏高效实现】
本文主要工作:
1.提出了一种用于移动设备端的网络架构:PeleeNet——是Densenet的变体
【遵循了Desenet的连接模式和一些关键性的设计原则;能够满足对内存和计算预算的限制】
特点如下:
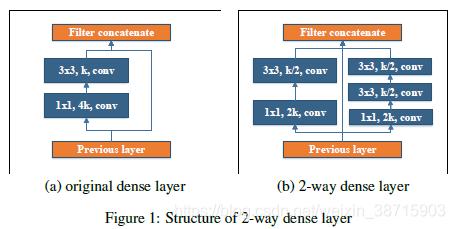
- Two-Way Dense Layer:
如下图所示,受GoogLeNet启发,使用2-way dense layer来获得不同尺度的感受野。
| One way 使用1个3X3的卷积 |
| The other way使用两个堆叠的3X3卷积层来学习大目标的visual patterns |
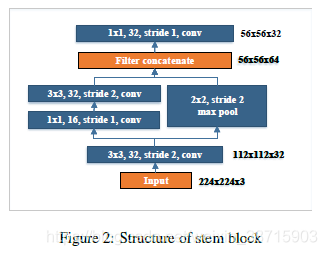
- Stem Block:
如下图所示,受Inception-v4和DSOD的启发,提出一种低成本的stem block。
| 用于第一个dense layer之前提取特征 |
| 能够提升特征表达能力,且没有增加太多的计算成本 |
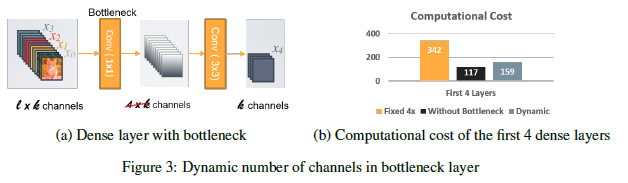
- Dynamic Number of Channels in Bottleneck Layer:
| bottleneck中的通道数量根据输入feature map的形状而变化,并不是像Densenet中直接扩大4倍 |
| 实验结果表明,与原有的Densenet结构相比,该方法可以节省28.5%的计算成本,对计算精度影响较小。 |
- Transition Layer without Compression:在PeleeNet中,过渡层不会进行通道数量的压缩。
- Composite Function:使用"Conv-BN-ReLU"(后激活),而不是想DenseNet那样进行预激活。后激活的好处是,在做inference阶段,可以将所有的BN层与卷积层合并,可以大幅提高计算速度。为了弥补后激活对精度降低的影响,PeleeNet在设计时尽可能“浅而宽”。并且在最后一个dense block之后添加了1*1卷积层以获得更高级的特征。
2.结合PeleeNet对SSD进行改进,提出了Pelee:
- Feature Map Selection :检测模型中有5组不同尺度的特征图——19*19、10*10、5*5、3*3、1*1;为了降低计算成本不选择38*38的尺度
- Residual Prediction Block :设计ResBlock产生用于预测的feature map
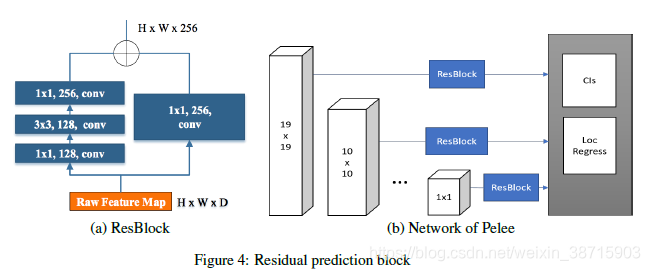
- Small Convolutional Kernel for Prediction:ResBlock 使得能够应用1X1的卷积来进行预测分类得分和回归偏移量;精度与使用3X3卷积模型几乎一致,但能够降低21.5%的计算成本。
PELEENET:一种高效的特征提取网络
1.结构:
如表1所示,首先通过stem block[快速提取特征],然后通过4个由dense layers和1个Transition layer组成的stage[除了stage4以外,其他3个stage最后部分都使用了stride=2的平均池化],最后通过1X1卷积层以及全局平均池化做分类检测输出。
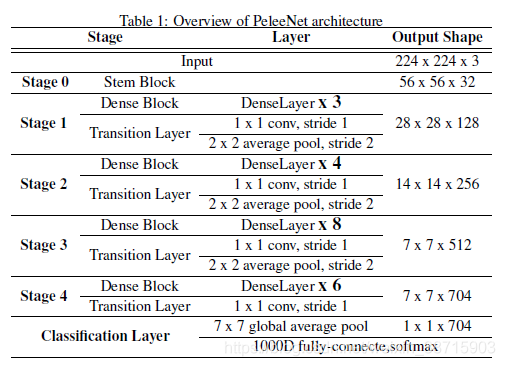
之后用可视化工具看了pelee的网络结构超级有规律
2.训练:
有训练SSD安装的caffe,所以只需要把pelee复制到caffe-ssd的examples文件夹中,生成好lmdb文件
sudo python train_voc.py最后结果:
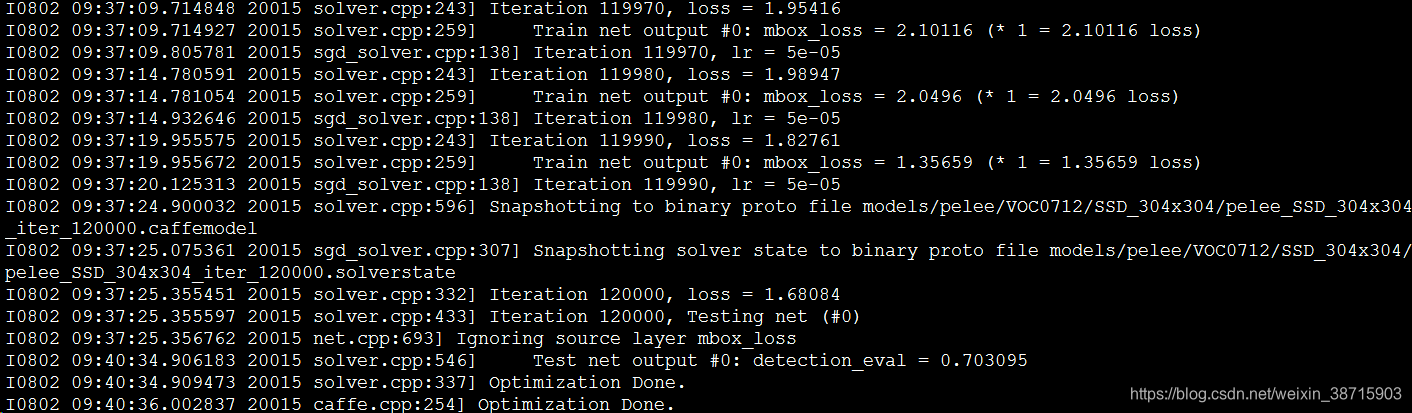
对比一下结果差了0.6%