文章目录
1.文章概要
继续学习Python爬虫知识,实现简单的案例,发送每日天气预报
1.1 实现方法
本文使用Python中常用的requests、BeautifulSoup来实现的
1.2 实现代码
以下是本项目全部代码
# author by mofitte
# vx:mofitte
# date 2024年11月20日
from datetime import datetime
import requests
from bs4 import BeautifulSoup
def get_weather():
# 目标URL,这里我选择青海西宁
url = 'https://www.weather.com.cn/weather1d/101150101.shtml'
try:
response = requests.get(url)
response.encoding = 'utf-8'
response.raise_for_status()
# 解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取天气预报信息,这里需要根据实际页面结构来定位元素
# 假设天气预报信息在一个id为"7d"的div标签内
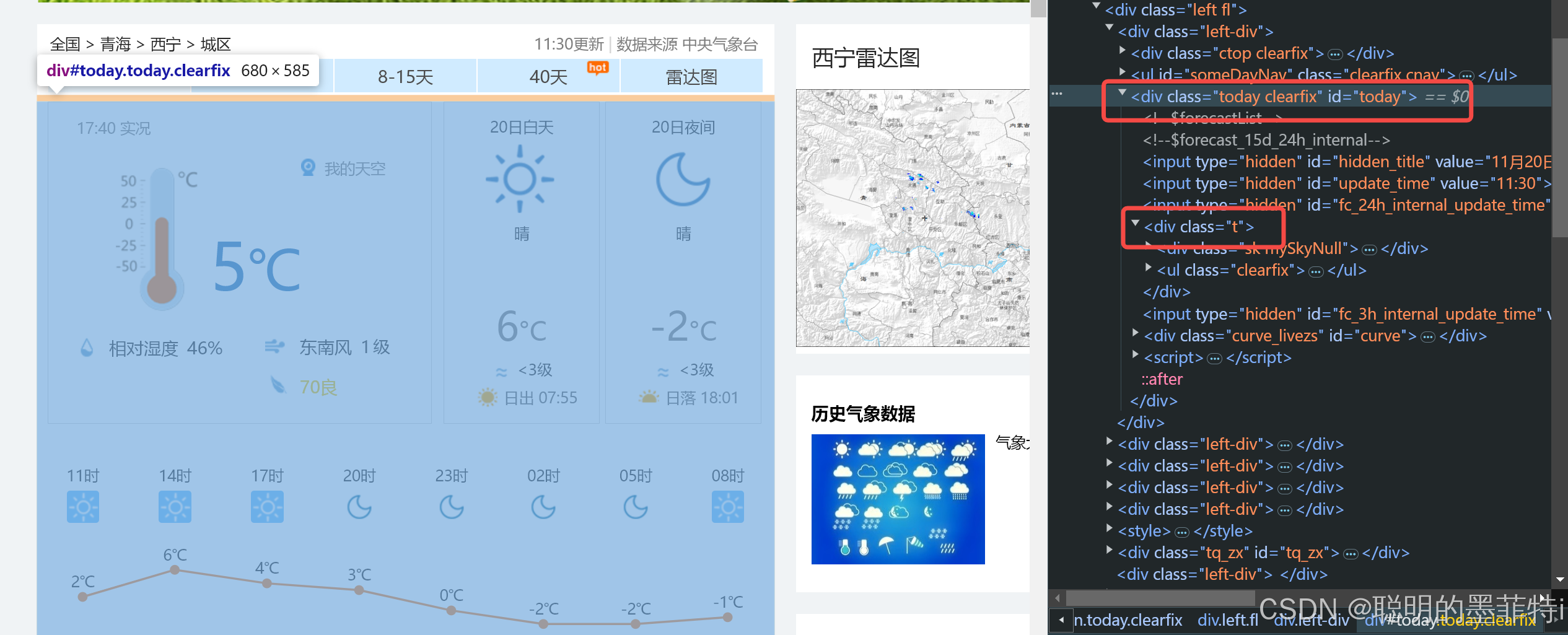
forecast_div = soup.find('div', id='today')
# 检查是否找到了forecast_div
if forecast_div is not None:
# 继续解析forecast_div中的内容,这里需要根据实际结构来编写
# 假设每天的天气预报在一个class为"t clearfix"的div标签内
daily_forecasts = forecast_div.find_all('div', class_='t')
# 打印每天的天气预报信息
for daily_forecast in daily_forecasts:
data = get_today_date() # 获取日期
weather = daily_forecast.find('p', class_='wea').text # 获取天气状况
temperature = daily_forecast.find('p', class_='tem').text.strip() # 获取温度
print(f'今天是:{data}'+f',天气:{weather}'+f',温度:{temperature}')
else:
print("暂未获取到今日天气预报信息。")
except Exception as e:
print(f"解析网页时发生错误:{e}")
def get_today_date():
return datetime.now().strftime("%Y-%m-%d") # 返回当前日期
get_weather()
1.3 最终效果
1.3.1 编辑器内打印显示效果

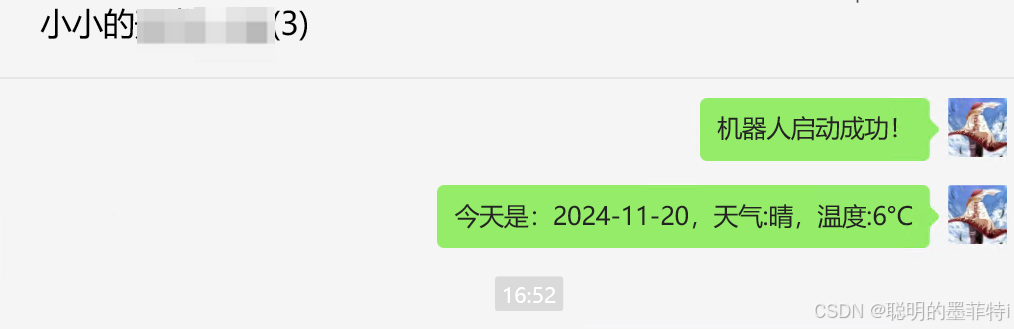
实际应用效果
== 这里我是用力微信机器人,在指定的某个群内定时发布每日天气预报信息==
2.具体讲解
2.1 使用的Python库
1.datetime:时间库;
2.BeautifulSoup: 一个用于解析HTML和XML文档的Python库;
3.requests:一个Python第三方库,用于发送HTTP请求;
2.2 代码说明
2.2.1 获取天气预报信息
def get_weather():
# 目标URL,这里我选择青海西宁,101150101是西宁的代码,这里可以替换为其他城市的信息,详见目标网站源码JS文件
url = 'https://www.weather.com.cn/weather1d/101150101.shtml'
try:
response = requests.get(url)
response.encoding = 'utf-8'
response.raise_for_status()
# 解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取天气预报信息,这里需要根据实际页面结构来定位元素
# 假设天气预报信息在一个id为"7d"的div标签内
forecast_div = soup.find('div', id='today')
# 检查是否找到了forecast_div
if forecast_div is not None:
# 继续解析forecast_div中的内容,这里需要根据实际结构来编写
# 假设每天的天气预报在一个class为"t clearfix"的div标签内
daily_forecasts = forecast_div.find_all('div', class_='t')
# 打印每天的天气预报信息
for daily_forecast in daily_forecasts:
data = get_today_date() # 获取日期
weather = daily_forecast.find('p', class_='wea').text # 获取天气状况
temperature = daily_forecast.find('p', class_='tem').text.strip() # 获取温度
print(f'今天是:{data}'+f',天气:{weather}'+f',温度:{temperature}')
else:
print("暂未获取到今日天气预报信息。")
except Exception as e:
print(f"解析网页时发生错误:{e}")
2.2.2 获取当天日期信息,格式化输出
def get_today_date():
return datetime.now().strftime("%Y-%m-%d") # 返回当前日期
2.2.3 调用函数,输出结果
get_weather() # 调用函数
2.3 过程展示
3 总结
本案例是采用了requests库来简单获取数据,过程还是相对简单的;遇到的难题还是在实际应用中,机器人调用遍历每日天气预报信息问题,最后还是结果了,哈哈哈,继续学习。
看到这里了,我只希望能点个赞,谢谢