常见的统计运算包括求和、平均值、极值,分别用到sum()、mean()、max()、min()
除此以外,还可以获取数值的分布情况、相关系数、创建透视表等
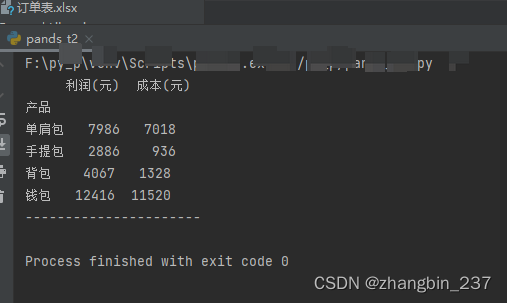
1、求和
pandas模块的sum()函数可以对每一列数据进行求和,如果值是字符串类型,则是拼接起来:
import pandas as pd
dt=pd.read_excel('产品统计表.xlsx',sheet_name=0)
a=dt.sum() #每一列的和
b=dt['利润(元)'].sum() #特定列的和
print(a)
print('----------------------')
print(b)
2、求平均值
用mean()求各列的平均值,但是如果列的类型不是数字类型,该列的运算会报错
import pandas as pd
dt=pd.read_excel('产品统计表.xlsx',sheet_name=0)
a=dt.mean() #每一列的均值
b=dt['利润(元)'].mean() #特定列的均值
print(a)
print('----------------------')
print(b)

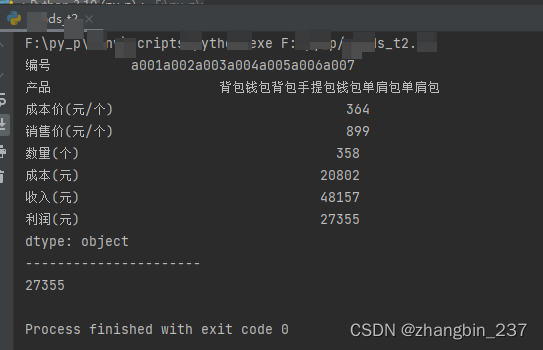
3、求极值
max()、min()求极大值、极小值
import pandas as pd
dt=pd.read_excel('产品统计表.xlsx',sheet_name=0)
a=dt.max() #每一列的最大值
b=dt['利润(元)'].max() #特定列的最大值
print(a)
print('----------------------')
print(b)
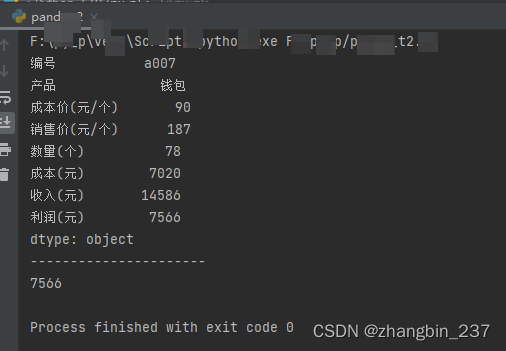
4、数值的分布情况
使用describe()可以案列获取数据表中所有数值的分布情况,包括个数、均值、极值、方差、四分位等:
import pandas as pd
dt=pd.read_excel('产品统计表.xlsx',sheet_name=0)
a=dt.describe() #每一列的汇总数据
b=dt['数量(个)'].describe() #特定列的汇总数据
print(a)
print('----------------------')
print(b)

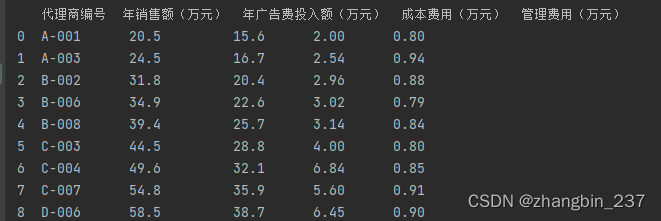
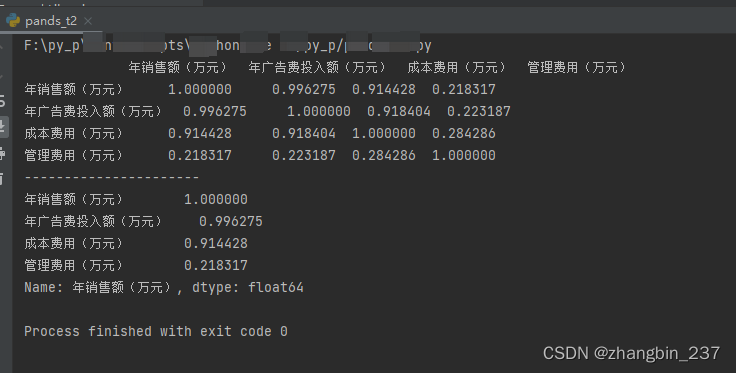
5、相关系数
相关系数通常是用来衡量两个或多个元素之间的相关程度,在pandas中可以用corr()计算相关系数
使用的数据如下:
使用corr()计算相关系数:
import pandas as pd
dt=pd.read_excel('相关性分析.xlsx',sheet_name=0)
a=dt.corr() #所有的相关系数
b=dt.corr()['年销售额(万元)'] #特定列的相关系数
print(a)
print('----------------------')
print(b)
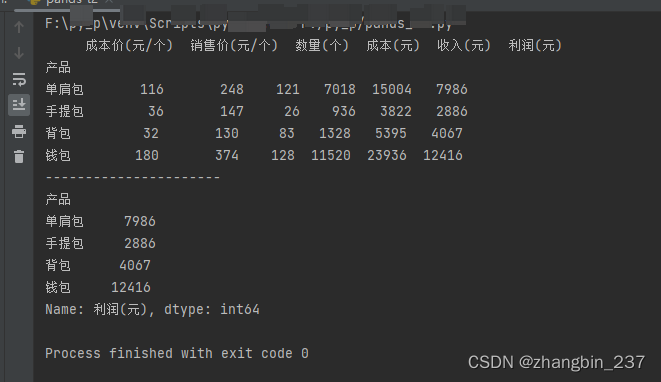
6、分组汇总数据
pandas中的groupby()可以对数据进行分组,分组后返回的是一个DataFrameGroupBy对象,不能直观展示,需要使用统计运算函数展示出来
import pandas as pd
dt=pd.read_excel('产品统计表.xlsx',sheet_name=0)
a=dt.groupby('产品').sum() #所有列的分组求和
print(a)
print('----------------------')
b=dt.groupby('产品')['利润(元)'].sum() #特定列的分组求和
print(b)
7、创建透视表
数据透视表可以对数据表进行快速的分组计算,pivot_table()函数可以实现数据透视表
import pandas as pd
dt=pd.read_excel('产品统计表.xlsx',sheet_name=0)
a=pd.pivot_table(dt,values=['利润(元)','成本(元)'],index='产品',aggfunc='sum')
#函数的参数分别是:求那一列的透视值('利润(元)','成本(元)'),根据那一列分组(产品),统计的方式(sum)
print(a)
print('----------------------')