论文全名:Real-Time MDNet(RT-MDNet)
论文摘自ECCV 2018,由Ilchae Jung(Github网址)、Jeany Son、Mooyeol Baek、Bohyung Han撰写,
作者(与MDNet作者属同一个导师)来自韩国浦项理工大学。
摘要
提出基于MDNet的快速且准确跟踪算法
(1)通过感受野的高分辨特征图来区分目标和背景,通过改进RoIAlign加速特征提取,
(2)在嵌入空间中,通过mutli-task损失有效地区分目标,对具有相似语义的目标加入了具有辨别力的参数。
结果:与MDNet相比速度提高了25倍,精度几乎相同。
1 前言
提出问题:
【1】MDNet缺陷:(1)在时间和空间方面具有很高的计算复杂度。(2)对潜在目标没有进行模型提取优化。
【2】目前避免冗余方法的缺陷:(1)Fast R-CNN:在网络特征映射中使用RoIPooling,但特征映射粗略量化,导致定位差(2)Mask R-CNN:RoIAlign(基于双线性插值)在RoI尺寸很大的情况下会丢失对目标有用的localization。
【3】CNN的缺陷:对类内对象差异不敏感。
解决方法:
提出基于MDNet的RT-MDNet算法:
(1)对于前面的全卷积特征映射,用RoIAlign层(mask R-CNN)提取对象表示:构建高分辨率特征图,扩大每个激活的感受野。
(2)在预训练阶段引入嵌入损失,并聚合到原MDNet中二分类损失中。
主要贡献:
•提出一种MDNet和Fast R-CNN跟踪算法:用改进的RoIAlign来从特征图中提取目标候选,并改善目标定位。
•学习一个嵌入空间来区分跨多个域的具有相似语义信息的目标。
•与MDNet相比速度提高了25倍,精度几乎相同。
2 相关工作
【1】相关算法思想
基于深度网络的相关滤波算法(精度高,但速度慢):C-COT、ECO、HCF、CREST、MCPF;
基于CNN的跟踪算法(精度不高,但速度快):GOTURN(Siamese-fc的另一版本)、Siamese-fc、EAST。
滤波器特征进行了Hand-crafted(精度高且速度快):BACF(通过更多的背景来学习相关滤波器)、PTAV(使用FDSST进行跟踪,并与Siamese深度网络进行检测验证)、ECO(集成多分辨率深度特征)
【2】提出问题
区分了目标与背景,但对相似目标却不敏感:MDNet、Siamese-fc、CFNet、CFCF(VOT2107性能No.1)。
【3】为了解决【2】中的问题:
R-CNN(提取特征复杂度高)----->Fast R-CNN(提出RoIPooling但由于粗特征导致定位差)----->mask R-CNN(提出RoIAlign,使用双线性插值近似特征,实现定位)
3 网络架构
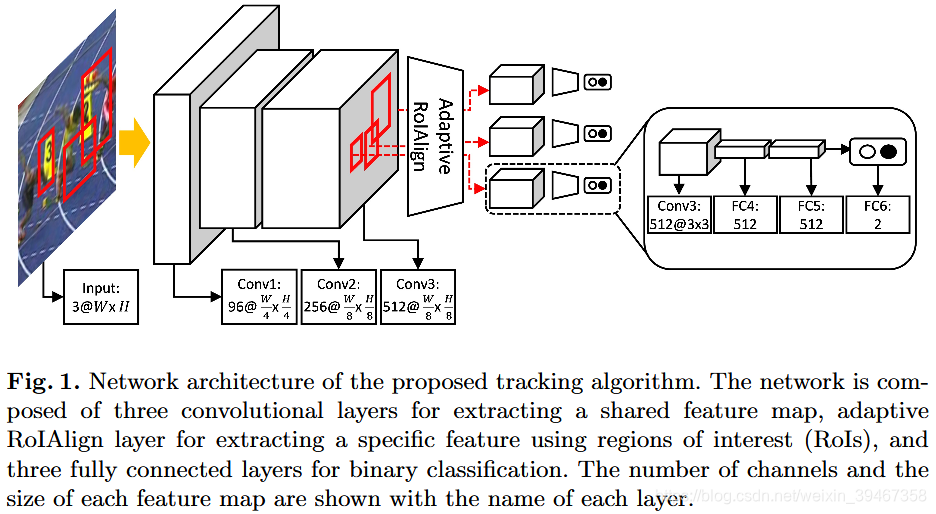
输入:3x107x107图像 + 一组proposal边界框
整体过程:
【1】网络通过单个前向传递计算图像的共享特征,然后用自适应RoIAlign提取出每个RoI的CNN特征(效果:提高特征质量,降低计算复杂度)
【2】将计算的每个特征送入全连接层(区分目标与背景),然后送入FC6层(归一化交叉熵损失的二分类),其中,微调使用初始帧的目标框。
对于【1】:自适应RoIAlign
问题:(1)原始RoIAlign提取的特征较粗略,需要构建一个具有高分辨率和丰富语义信息的特征映射。(2)普通RoIAlign仅利用特征映射中周围的grid点来计算插值
方法:
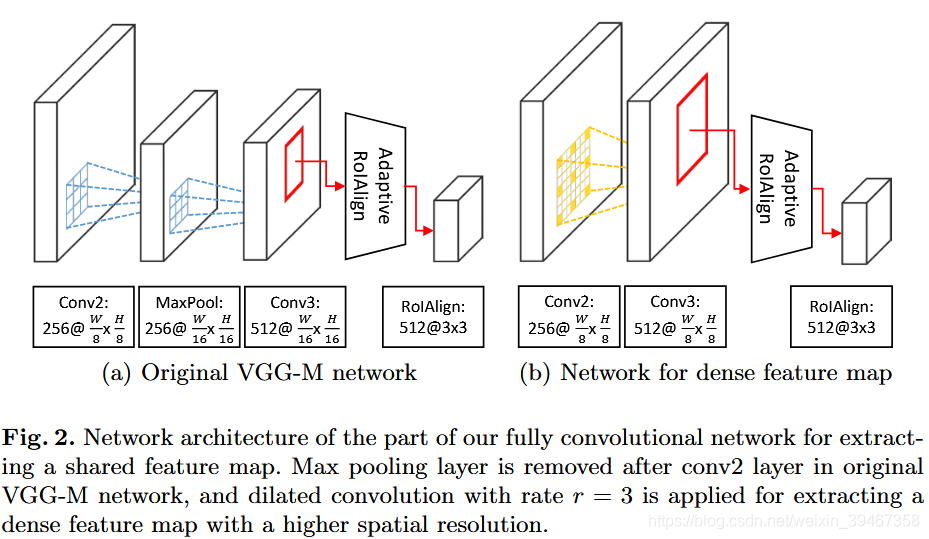
(1)如图2所示,作者将原VGG-M中conv2层后面的最大池化层移除,在conv3层中以速率r = 3来扩张卷积,
(2)在自适应RoIAlign层使用双线性插值(大小由RoI决定:,其中
为conv3层后RoI的宽度,
为RoIAlign层后RoI的宽度,[·]是舍入算子)计算,生成512x7x7的特征图,最后再经过一个最大池化层生成512x3x3的特征图。
效果:送入自适应RoIAlign时,特征图放大了两倍(提取高分辨率的特征),提高特征的质量
对于【2】:判别嵌入
问题:MDNet仅区分不同域中的目标和背景(CNN的分类特性),却无法区分其具有相似语义信息的前景目标
方法:
(1)提出嵌入损失:在共享特征空间中,不同域中的目标嵌入时互相远离。学习看不见的目标的判别表示。
(2)提出损失约束:将多个视频中的前景对象嵌入进去。
具体思想:
FC6输入:d-domain中的输入图像和边界框R
FC6输出:
(1)分数,其中,
为d-domain中2D二分类得分,D是训练集中的domain数(ImageNet2015随机抽取的100个视频)。
(2)归一化函数定义为:(对比domain中目标与背景的二分类得分),
(对比所有domain中判别正样本得分)。
(3)在第k次迭代中(网络更新与否取决于),
损失项:(二分类损失)与
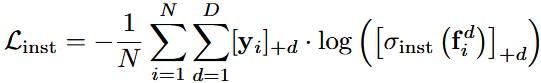
其中,(求余运算);
为GT的0-1二分类编码;
=1表示在d-domain中边界框
为c类别,否则为0;
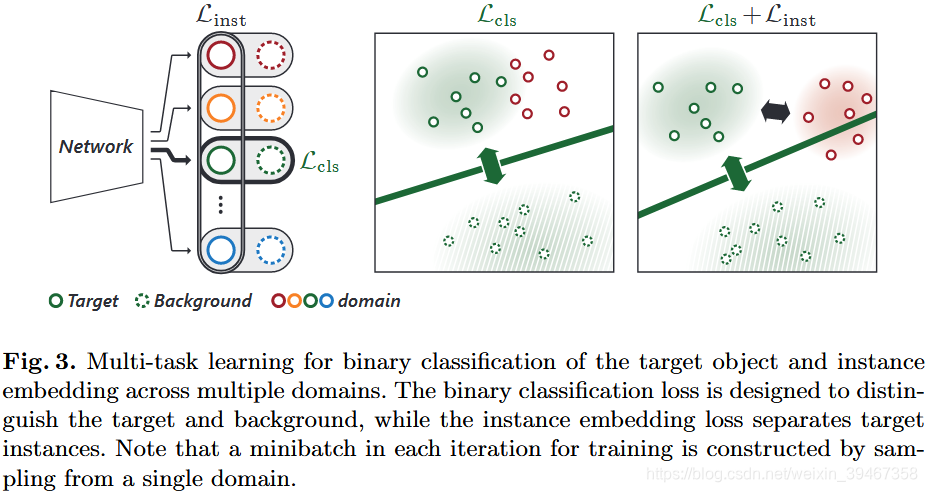
其他颜色代表其他的domain中的目标样本
(4)定义损失函数:,
其中α是控制两个损失项之间平衡的超参数(设为0.1),与MDNet相同,作者在每次迭代中只处理一个domain。
4 跟踪测试
跟踪算法的管道几乎与MDNet [1]相同。全连接层(fc4-6):(1)对于初始帧,进行微调;(2)对于后续帧,在线更新,同时修复卷积层。
【1】实施过程:输入第t帧时,通过之前帧的高斯分布生成一组样本,得到最高分数:
,与MDNet在线跟踪相同,
为第t帧的第i个样本的正分数,不同的是,这里的函数为三维空间上的计算(平移缩放)。
【2】对边界框回归:利用初始帧RoIs提取的特征训练线性回归器(与MDNet边界框回归相同),在后续帧中,如果
,则通过之前的回归器调整目标区域。
【3】模型更新:与MDNet相同,执行Long-term update+Short-term update。(训练时,在多次迭代中累积后向传递的渐变:设定每50次迭代更新模型)(测试时,每10帧进行一次Long-term update)
【4】提取负样本:与MDNet提取负样本相同,采用难分负样本挖掘思想:通过在每次迭代时使用32个正样本和96个负样本(从1024个负样本中选择最好的96个负样本)组成的小样本来测试。
【5】具体细节:
(1)初始化:
conv1-3的权重:用ImageNet2015训练的VGG-M网络;全连接的层随机初始化。最后一个卷积层中感受野大小等于75×75。
(2)训练数据(ImageNet2015中近4500个视频):
训练:对于视频的每次迭代,随机取8帧,从每帧中取32个正样本(IOU0.7)和96个负样本(IOU
0.5),组成一个小批量样本(256个正样本和768个负样本)
测试:(与MDNet相同)对于初始帧,取500个正样本(IOU0.7)和5000个负样本(IOU
0.5);对于后续帧(将之前所有帧用于在线更新),取50个正样本(IOU
0.7)和200个负样本(IOU
0.3)
(3)网络:
训练:采用随机梯度下降(SGD)方法进行训练,需要1000次迭代,学习率为0.0001
测试:对初始帧50次迭代,对后续帧为15次迭代,学习率为0.0003,注意,fc6的学习率fc4-5的10倍(与MDNet测试类似)。
动量(0.9)和权重衰减(0.0005)。注意:保留特征表示(而非图像信息)以节省时间和内存
(4)平台:
PyTorch,3.60 GHz Intel Core I7-6850K + NVIDIA Titan Xp Pascal GPU。
5 实验
训练集:ImageNet2015(MDNet、MDNet+IEL、RT-MDNet)
评估数据集:OTB2015,UAV123(2016),TempleColor(2015)
评估标准:OPE
评估指标:中心位置误差和边界框重叠率。
算法比较:
| 实时(在图中用实线表示) | Ours | ||||||||||
| ECO | MDNet | MDNet + IEL | SRDCF | C-COT | ECO -HC | BACF | PTAV | CFNet | SiamFC | DSST | RT-MDNet |
| MDNet +判别嵌入 | ECO +hand-crafted +HOG+color | ||||||||||
【1】OTB2015
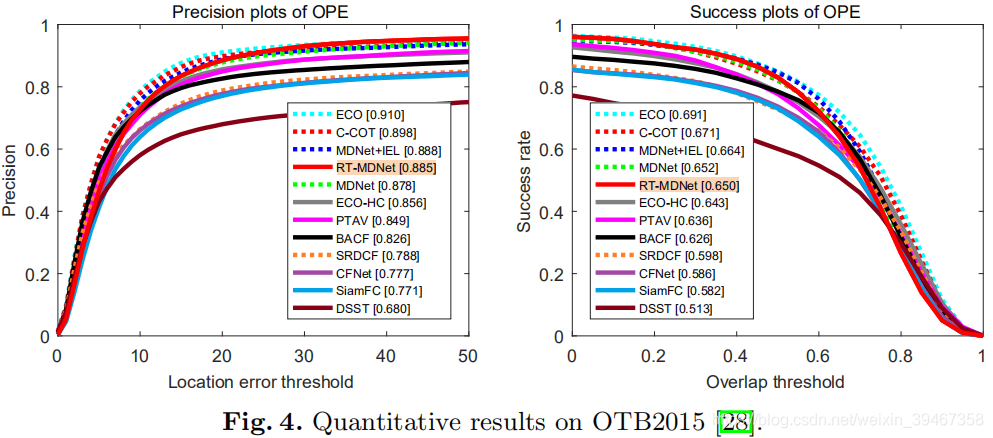
准确性稍差原因:基于CNN的跟踪器的固有缺点;RoIAlign在高精度区域的目标定位的局限性。

46:平均FPS;
52:除初始帧外的平均FPS
缺陷:对遮挡、突然大的运动和平面外旋转性能不佳。
【2】TempleColor2015
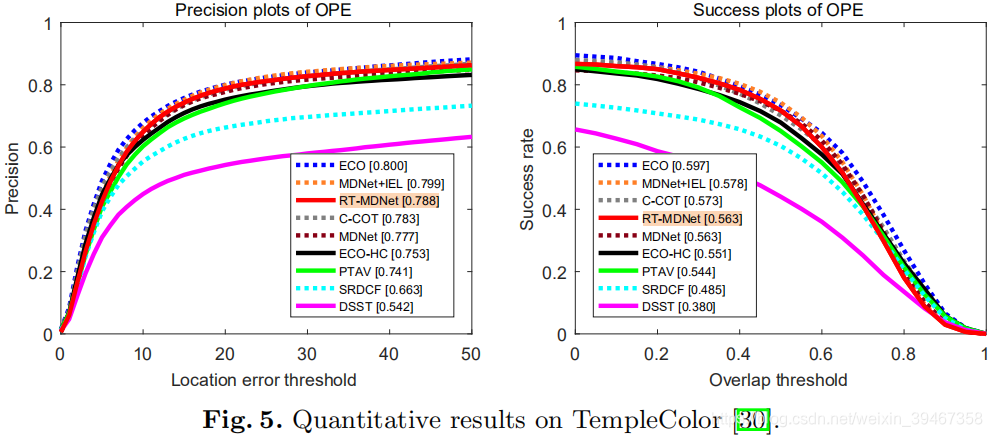
【3】UAV123-2016
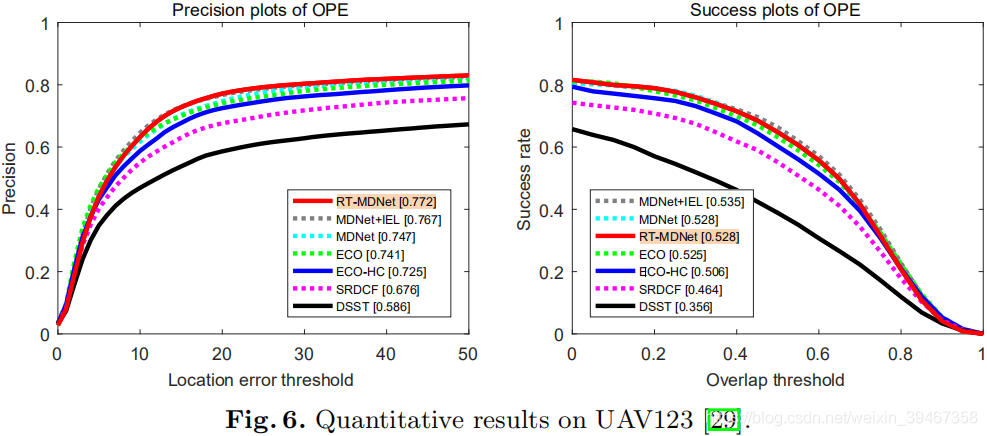
* RT-MDNet 消融研究
训练集:VOT2013,VOT2014和VOT2015
测试集:OTB2015

denseFM:密集特征映射
