1、示例环境
zookeeper-3.4.9
kafka_2.11
Java_1.8(java 8/11)
Flink1.10
KafKa安装启动可参考文章 Windows10搭建Kafka开发环境
2、创建一个Topic名为“test20201217”的主题
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test202012173、创建producer(生产者),生产主题的消息
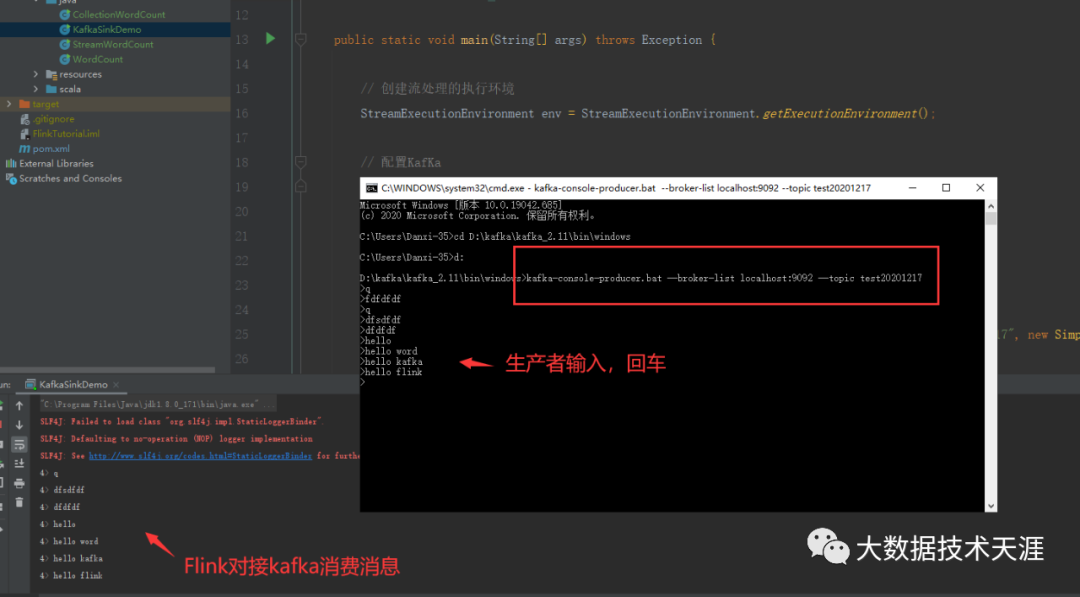
kafka-console-producer.bat --broker-list localhost:9092 --topic test202012174、创建consumer(消费者),消费主题消息
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test202012175、编写Flink从kafka消息队列读取数据代码
5.1、工程中添加pom.xml依赖
org.apache.flinkflink-connector-kafka-0.11_2.121.10.1
org.apache.flinkflink-statebackend-rocksdb_2.121.10.1
org.apache.flinkflink-table-planner_2.121.10.1
org.apache.flinkflink-table-planner-blink_2.121.10.1
org.apache.flinkflink-java1.10.1
org.apache.flinkflink-streaming-java_2.121.10.1
org.apache.flinkflink-clients_2.121.10.15.2、编写代码
public static void main(String[] args) throws Exception {
// 创建流处理的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置KafKa
//配置KafKa和Zookeeper的ip和端口
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("zookeeper.connect", "localhost:2181");
properties.setProperty("group.id", "consumer-group");
//将kafka和zookeeper配置信息加载到Flink的执行环境当中StreamExecutionEnvironment
FlinkKafkaConsumer011 myConsumer = new FlinkKafkaConsumer011("test20201217", new SimpleStringSchema(),
properties);
//添加数据源,此处选用数据流的方式,将KafKa中的数据转换成Flink的DataStream类型
DataStream stream = env.addSource(myConsumer);
//打印输出
stream.print();
//执行Job,Flink执行环境必须要有job的执行步骤,而以上的整个过程就是一个Job
env.execute("kafka sink test");
}在idea启动main函数