【前言】
本次分析的数据来源:
Baby Goods Info Data-数据集-阿里云天池tianchi.aliyun.com
本次分析的过程如下,一共分为5大步骤:
明确问题→理解数据→数据清洗→数据分析或构建模型→数据可视化;
【一】明确问题
在开始分析之前,必须要先明确分析的目标是什么,才能便于我们去选择分析的维度和方法;
这份数据集是关于婴儿用品的购买的情况,由两份表组成,分别是“用户购买商品的数据”和“用户(婴儿)情况”;
我希望,从这两份数据表中能对一下几个问题进行分析并找出答案:
1、哪种商品的累计销售数量最多?
可用字段:商品一级分类、商品二级分类、购买数量;
2、季度的差异会对用户的购买力有影响吗?
可用字段:购买时间、购买数量;
3、用户的年龄段分布是怎么样的,什么年龄段的用户购买商品的数量最多?
(什么年龄的客户消费力最强)
可用字段:购买时间、出生日期、购买数量、商品一级分类、商品二级分类;
4、不同性别婴儿对商品的购买偏好对比;
可用字段:性别、购买数量;
【二】理解数据
两份数据表中出现的如下字段:
1、用户购买商品的数据表(下称表1):
user_id:用户id;
auction_id:物品编号(item_id);
day:购买时间;
cat_id: 商品二级分类;
cat1: 商品一级分类;
property:商品属性;
buy_mount:购买数量;
2、用户(婴儿)情况表(下称表2)
user_id:用户id;
birthday:出生日期;
gender:性别;(0女性;1男性;2未知的性别)
3、为了便于对表格进行观察和操作,把表格的列宽调整为15。
【三】用EXCEl对数据进行清洗
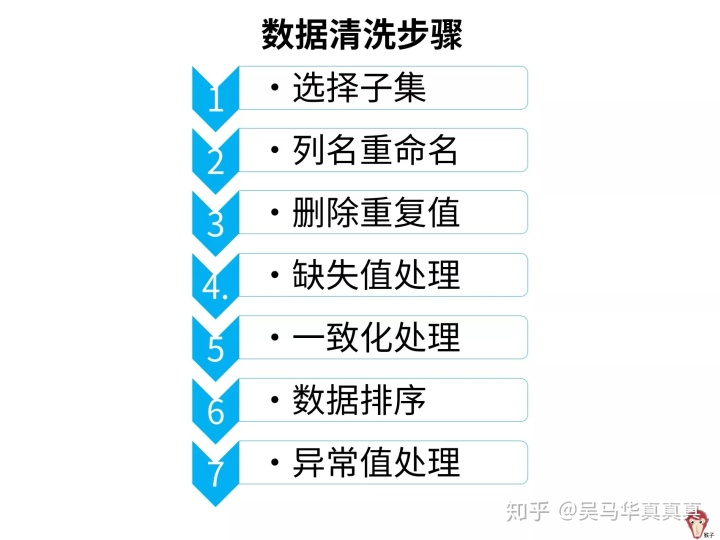
1、选择子集
(1)通过观察,识别出“用户ID”这一列是两份表格中的关键字段;
(2)将表格中用不上的“列”隐藏掉,避免表格中含有过多杂乱的信息,如表一中的“商品属性”“商品编号”,表二中无需要隐藏的字段信息。
2、把英文的的列名称改成中文的,便于自己使用。
3、删除重复值
表一:
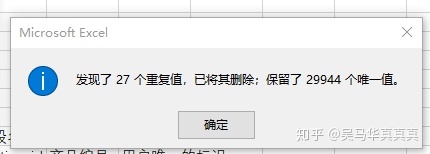
表二没有发现重复值。
4、缺失值处理
两个表格中,“用户ID”是识别用户的唯一值,所以,以“用户ID”该列数据量的作为整个表格寻找缺失值的基数。
得到表一“用户ID”列共有29945个数据,表中的其他列与之对比后,并无发现有缺失值,表二亦无缺失值。
如有缺失值,可使用以下办法进行处理:
(1)通过定位的功能查找表格中的空值(如要快速填充空值,待定位出空值后,输入“=需要填写的值,同时按下CTRL+ENTER”)
(2)删除缺失位置;
(3)用平均值代替缺失值;
(4)用统计模型计算出值来代替这个缺失值;
5、对数据列中的值进行统一化处理
两个表格中,需要对日期和出生日期进行统一的格式处理,便于稍后通过用户的出生日期及购买时间使用DATEDIF函数计算出用户的年龄;再用IF函数将婴儿用户的性别从数字转换成中文。
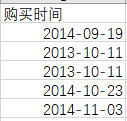
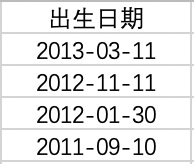
(1)对日期的一致化处理
→处理前:

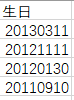
→处理方法:①通过“分列”功能,将日期处理第一次;②处理后的日期仍不是我最想要的整齐度,于是拉黑日期列,右键选中“单元格格式”--“自定义”--"yyyy-mm-dd",最终如下图所示。
→处理后:
(2)对婴儿用户性别的一致化处理
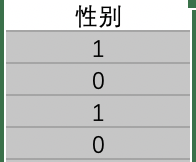
将性别从数字(0、1、2)统一转换为女、男、未知性别。
→原始
→使用公式[ =IF(目标单元格=2,"未知性别",IF(目标单元格=1,"男","女")) ]
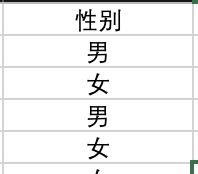
→最后将转换成中文的这一列复制--粘贴成值,再把原数字性别那一列删除。
6、对数据进行排序,发现异常值、处理异常值
对表一的“购买数量”进行排序:
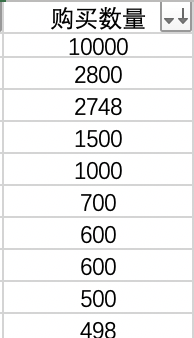
排序后发现,第一行的数据过大,判定为异常值,将其删除;
【四】对数据进行分析
以上是花了过半的时间对数据进行认识、理解、清洗,现在可以对数据进行剖析了。
1、对数据进行透视来解答问题;
第一个问题 → 哪种商品的累计销售数量最多?
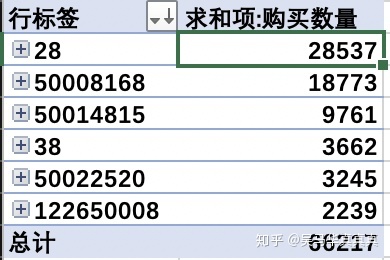
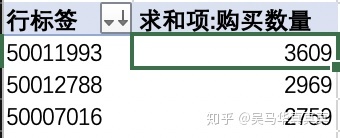
由此可见,一级分类28的销量最好,共卖出了28537份,二级分类商品销量最好的则是一级分类类别50022520下面的50011993,共卖出3609份。
第二个问题 → 季度的差异会对用户的购买力有影响吗?
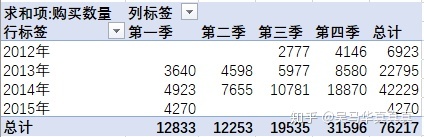
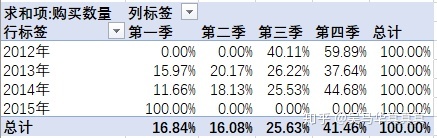
由此可见,第四季度的累计销量是最好的。
第三个问题 → 用户的年龄段分布是怎么样的,什么年龄段的用户购买商品的数量最多?
(什么年龄的客户消费力最强)
首先,先把表一的内容,用VLOOKUP函数跨表联动至表二中,再通过婴儿生日日期及购买时间来用DATEDIF函数(注意:函数中,结束时间>初始时间)计算婴儿用户的年龄。
通过观察,能够发现表格中“婴儿年龄”这一列的数据由错误值(N/A)以及“0”,对数据进行理解后,把错误值和“0”的表述更改为“未出生”、“不到1周岁”。
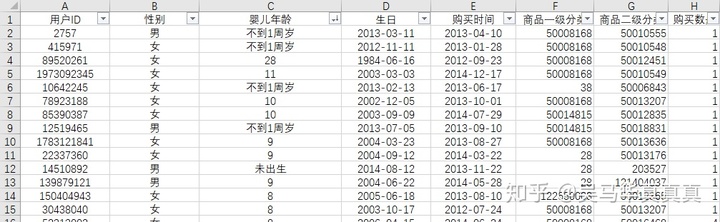
再对数据进行排序,判定“28”这个数值属于异常值,将其删除。
对数据表按需求进行透视:
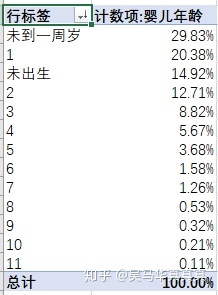
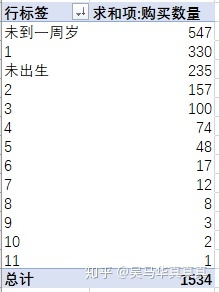
由此可见,“未到一周岁”这个年龄段的用户人数最多,购货数量也是最多的。
第四个问题 → 不同性别婴儿对商品的购买偏好对比;
在第三问的基础上,直接能够构建出需要的透视表:
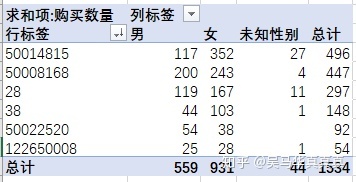
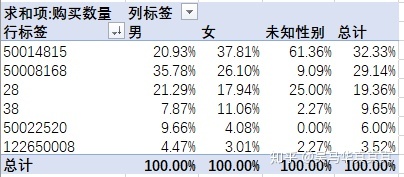
由此可见,男性婴儿用户对于50008168商品的购买量最多,而女性婴儿用户则对于50014815商品的购买量最多。总体来讲,50014815商品被购买的数量最多。