
现在的机子开数据库也很慢,仿佛跟90年代的机子没什么区别,其中一个原因就是刚启动时数据库要用日志进行一致性检查与恢复。
一致性(Consistence):事务ACID四特性之一,如A转100元给B,这个事务完成后必须是A-100,B+100。ACID分别指Atomicity, Consistency, Isolation和Durability。
一致性检查与恢复时,存在大量的磁盘IO,近些年机械硬盘读写速度并没有很大提升。这时,如果将日志和data存在SSD上,会比存在机械硬盘上速度快,因为一致性检查时恢复毕竟占少数,更多是从外存读数据到内存,SSD读快的优势立马就显现出来了~
经常有朋友i7的处理器仍卡的要死,加了一块SSD后就变得飞起,也是因为对磁盘IO速度的需求大于对CPU性能的要求。制图、渲染视频的同学应该感触颇深,因为图像文件通常很大,内存不足以放下,会产生大量磁盘IO,这种需求下不仅要看GPU性能,还要增大内存,并考虑在SSD上存在work file。
1. 为什么要进行一致性检查?
首先,我们不能接受不一致的出现,比如你往卡里打了1亿元,隔天一查发现没有;其次,系统可能是从某个未完成的事务开始的(如断电、系统崩了导致),这时就需要日志。
事务中断在中间某个操作(crush),要作recovery,这即是一致性要求,也是原子性要求,事务的操作,要么不做,要么全做(atomicity)。
2. 什么时候产生日志
导致不一致的原因是内存更新的data还没来及写到磁盘,设计日志,我们需要先分析可能破坏一致性的事务操作:
定义1 事务的原语操作
input(x):读x的磁盘块进内存
output(x):写x内存块到磁盘
read(x,t):内存中,读x给t。t是次要数据,不重要
write(x,t):内存中,写t给x
可以看出,只有write(x)才可能导致不一致,需要产生日志。
3. 三种日志恢复机制
三种日志恢复机制:Undo日志、Redo日志、Undo/Redo日志。先给出一个三种日志都必须满足的一个定理:
定理1 先写日志(Write Ahead Logging,WAL):ouput(x)将x写回磁盘前,必须先将对应日志写回磁盘。
3.1 Undo日志
(1)write(x)产生<T,x,old-value>,其中T表哪个事务
(2)output(x)前先将<T,x,old-value> flush到磁盘(WAL先写日志)
(3)output()完后再将<Commit,T>日志写到磁盘
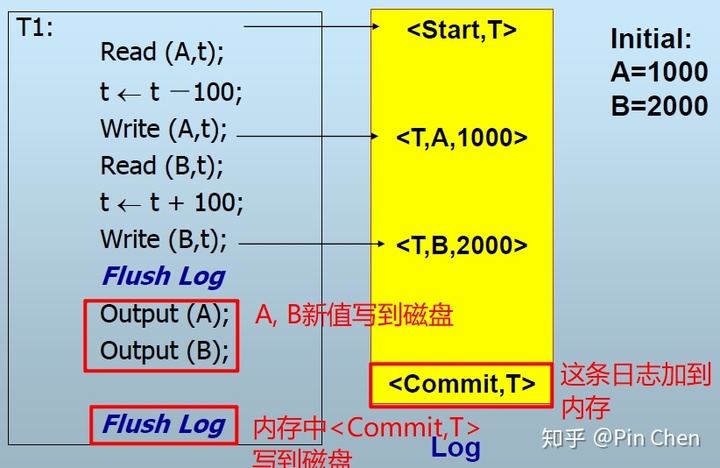
<Start, T>表事务开始,<Commit, T>表事务完成。
恢复算法:

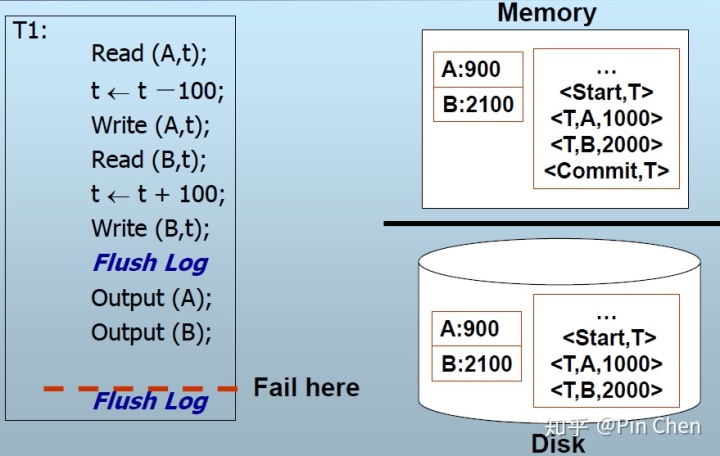
e.g.1
T1在磁盘中无<commit, T1>,撤销到<start, T1>前的一致状态。

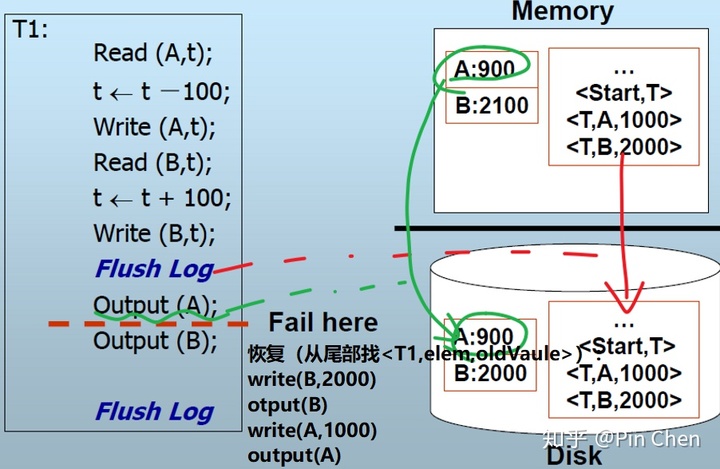
e.g.2 一个很可惜的例子
磁盘中仍无<commit, T1>,全要撤回。
3.2 Redo日志
(1)write(x)产生<T,x,new-value>
(2)同样,output(x)前先将<T,x,new-value> flush到磁盘(WAL先写日志)
(3)不同于Undo日志:output前先产生<commit, T>并写到磁盘,即<commit, T>和前面的<T,x,new-value> 一起写到磁盘
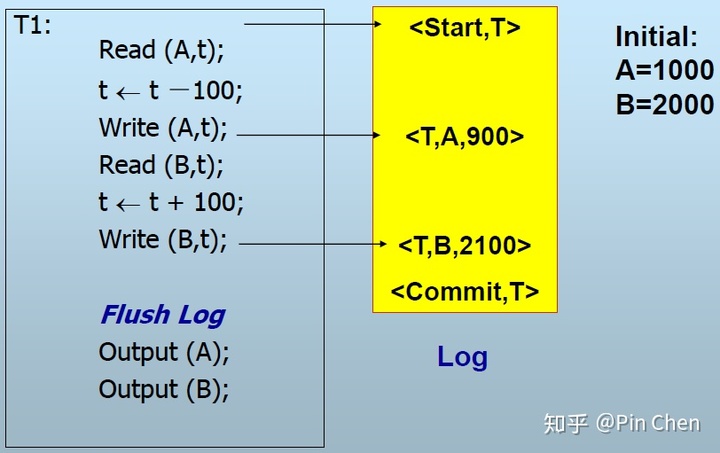
恢复算法:

3.3 Undo日志 vs. Redo日志
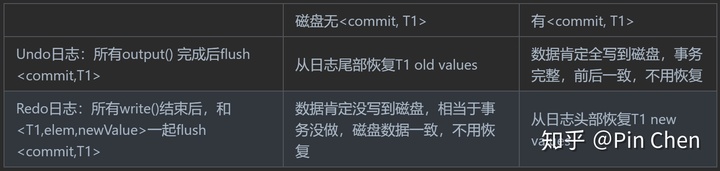
所以,Undo可以write()一个output一个,内存代价小
Redo必须全write()后,再output,内存代价高
但Undo是恢复old values,恢复代价更高,如e.g.2

综合Undo、Redo日志,便产生了Undo/Redo日志。
3.4 Undo/Redo日志
(1)write(x)产生<T,x,v,w>日志,其中v是old value,w是new value
(2)同样,WAL先写日志,output前,先flush所有的<T,x,v,w>日志
(3)<commit,T>output前(同Undo),或所有write后(同Redo)二选一
恢复算法:

先Redo的话,后面的Undo会破坏Redo恢复的new value。
e.g.3

References
[1] Advanced Database Systems,金培权,感谢金老师的教授