深度学习
Author:louwill
Machine Learning Lab
本文对深度学习两种模型部署方式进行总结和梳理。一种是基于web服务端的模型部署,一种是基于C++软件集成的方式进行部署。
基于web服务端的模型部署,主要是通过REST API的形式来提供接口方便调用。而基于C++的深度学习模型部署,主要是通过深度学习框架的C++前端版本,将模型集成到软件服务中。
本文分别对上述两种模型部署方式进行流程梳理,并分别举例进行说明。
1. 基于web端的模型部署
1.1 web服务与技术框架
下面以ResNet50预训练模型为例,旨在展示一个轻量级的深度学习模型部署,写一个较为简单的图像分类的REST API。主要技术框架为Keras+Flask+Redis。其中Keras作为模型框架、Flask作为后端Web框架、Redis则是方便以键值形式存储图像的数据库。各主要package版本:
tensorflow 1.14keras 2.2.4flask 1.1.1redis 3.3.8先简单说一下Web服务,一个Web应用的本质无非就是客户端发送一个HTTP请求,然后服务器收到请求后生成一个HTML文档作为响应返回给客户端的过程。在部署深度学习模型时,大多时候我们不需要搞一个前端页面出来,一般是以REST API的形式提供给开发调用。那么什么是API呢?很简单,如果一个URL返回的不是HTML,而是机器能直接解析的数据,这样的一个URL就可以看作是一个API。
先开启Redis服务:
redis-server1.2 服务配置
定义一些配置参数:
IMAGE_WIDTH = 224IMAGE_HEIGHT = 224IMAGE_CHANS = 3IMAGE_DTYPE = "float32"IMAGE_QUEUE = "image_queue"BATCH_SIZE = 32SERVER_SLEEP = 0.25CLIENT_SLEEP = 0.25指定输入图像大小、类型、batch_size大小以及Redis图像队列名称。
然后创建Flask对象实例,建立Redis数据库连接:
app = flask.Flask(__name__)db = redis.StrictRedis(host="localhost", port=6379, db=0)model = None因为图像数据作为numpy数组不能直接存储到Redis中,所以图像存入到数据库之前需要将其序列化编码,从数据库取出时再将其反序列化解码即可。分别定义编码和解码函数:
def base64_encode_image(img): return base64.b64encode(img).decode("utf-8")def base64_decode_image(img, dtype, shape): if sys.version_info.major == 3: img = bytes(img, encoding="utf-8") img = np.frombuffer(base64.decodebytes(img), dtype=dtype) img = img.reshape(shape) return img另外待预测图像还需要进行简单的预处理,定义预处理函数如下:
def prepare_image(image, target): # if the image mode is not RGB, convert it if image.mode != "RGB": image = image.convert("RGB") # resize the input image and preprocess it image = image.resize(target) image = img_to_array(image) # expand image as one batch like shape (1, c, w, h) image = np.expand_dims(image, axis=0) image = imagenet_utils.preprocess_input(image) # return the processed image return image1.3 预测接口定义
准备工作完毕之后,接下来就是主要的两大部分:模型预测部分和app后端响应部分。先定义模型预测函数如下:
def classify_process(): # 导入模型 print("* Loading model...") model = ResNet50(weights="imagenet") print("* Model loaded") while True: # 从数据库中创建预测图像队列 queue = db.lrange(IMAGE_QUEUE, 0, BATCH_SIZE - 1) imageIDs = [] batch = None # 遍历队列 for q in queue: # 获取队列中的图像并反序列化解码 q = json.loads(q.decode("utf-8")) image = base64_decode_image(q["image"], IMAGE_DTYPE, (1, IMAGE_HEIGHT, IMAGE_WIDTH, IMAGE_CHANS)) # 检查batch列表是否为空 if batch is None: batch = image # 合并batch else: batch = np.vstack([batch, image]) # 更新图像ID imageIDs.append(q["id"]) if len(imageIDs) > 0: print("* Batch size: {}".format(batch.shape)) preds = model.predict(batch) results = imagenet_utils.decode_predictions(preds) # 遍历图像ID和预测结果并打印 for (imageID, resultSet) in zip(imageIDs, results): # initialize the list of output predictions output = [] # loop over the results and add them to the list of # output predictions for (imagenetID, label, prob) in resultSet: r = {"label": label, "probability": float(prob)} output.append(r) # 保存结果到数据库 db.set(imageID, json.dumps(output)) # 从队列中删除已预测过的图像 db.ltrim(IMAGE_QUEUE, len(imageIDs), -1) time.sleep(SERVER_SLEEP)然后定义app服务:
@app.route("/predict", methods=["POST"])def predict(): # 初始化数据字典 data = {"success": False} # 确保图像上传方式正确 if flask.request.method == "POST": if flask.request.files.get("image"): # 读取图像数据 image = flask.request.files["image"].read() image = Image.open(io.BytesIO(image)) image = prepare_image(image, (IMAGE_WIDTH, IMAGE_HEIGHT)) # 将数组以C语言存储顺序存储 image = image.copy(order="C") # 生成图像ID k = str(uuid.uuid4()) d = {"id": k, "image": base64_encode_image(image)} db.rpush(IMAGE_QUEUE, json.dumps(d)) # 运行服务 while True: # 获取输出结果 output = db.get(k) if output is not None: output = output.decode("utf-8") data["predictions"] = json.loads(output) db.delete(k) break time.sleep(CLIENT_SLEEP) data["success"] = True return flask.jsonify(data)Flask使用Python装饰器在内部自动将请求的URL和目标函数关联了起来,这样方便我们快速搭建一个Web服务。
1.4 接口测试
服务搭建好了之后我们可以用一张图片来测试一下效果:
curl -X POST -F [email protected] 'http://127.0.0.1:5000/predict'模型端的返回:
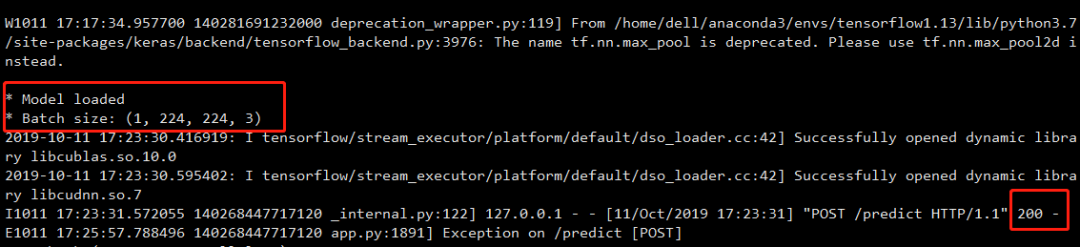
预测结果返回:

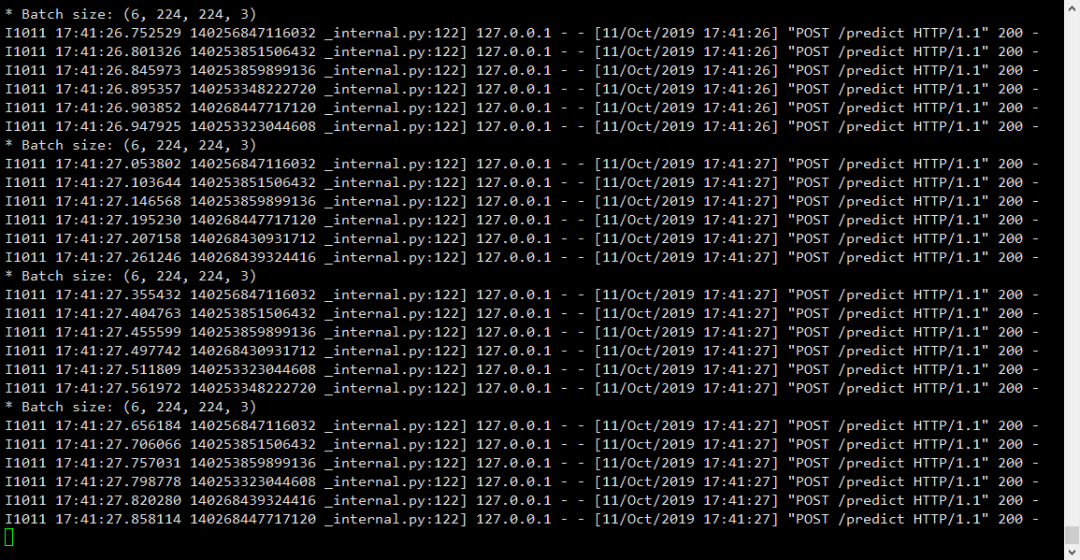
最后我们可以给搭建好的服务进行一个压力测试,看看服务的并发等性能如何,定义一个压测文件stress_test.py 如下:
from threading import Threadimport requestsimport time# 请求的URLKERAS_REST_API_URL = "http://127.0.0.1:5000/predict"# 测试图片IMAGE_PATH = "test.jpg"# 并发数NUM_REQUESTS = 500# 请求间隔SLEEP_COUNT = 0.05def call_predict_endpoint(n): # 上传图像 image = open(IMAGE_PATH, "rb").read() payload = {"image": image} # 提交请求 r = requests.post(KERAS_REST_API_URL, files=payload).json() # 确认请求是否成功 if r["success"]: print("[INFO] thread {} OK".format(n)) else: print("[INFO] thread {} FAILED".format(n))# 多线程进行for i in range(0, NUM_REQUESTS): # 创建线程来调用api t = Thread(target=call_predict_endpoint, args=(i,)) t.daemon = True t.start() time.sleep(SLEEP_COUNT)time.sleep(300)测试效果如下:

2. 基于C++的模型部署
2.1 引言
PyTorch作为一款端到端的深度学习框架,在1.0版本之后已具备较好的生产环境部署条件。除了在web端撰写REST API进行部署之外(参考),软件端的部署也有广泛需求。尤其是最近发布的1.5版本,提供了更为稳定的C++前端API。
工业界与学术界最大的区别在于工业界的模型需要落地部署,学界更多的是关心模型的精度要求,而不太在意模型的部署性能。一般来说,我们用深度学习框架训练出一个模型之后,使用Python就足以实现一个简单的推理演示了。但在生产环境下,Python的可移植性和速度性能远不如C++。所以对于深度学习算法工程师而言,Python通常用来做idea的快速实现以及模型训练,而用C++作为模型的生产工具。目前PyTorch能够完美的将二者结合在一起。实现PyTorch模型部署的核心技术组件就是TorchScript和libtorch。
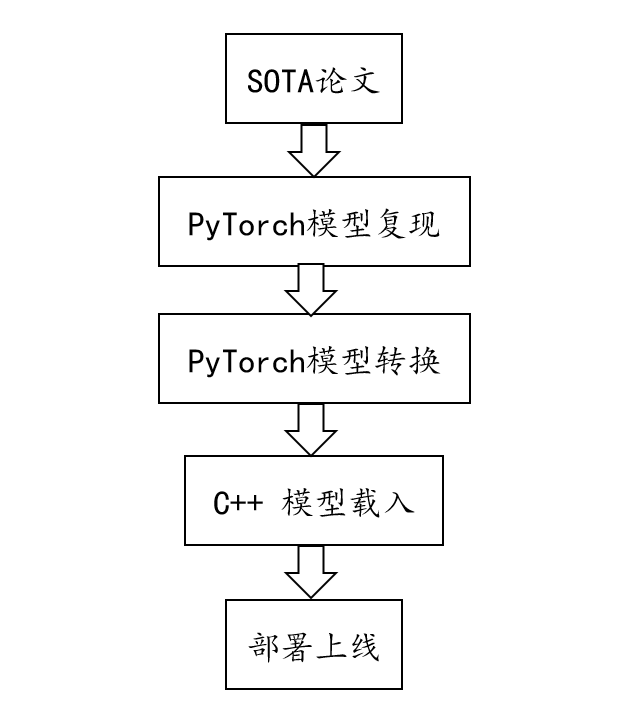
所以基于PyTorch的深度学习算法工程化流程大体如下图所示:
2.2 TorchScript
TorchScript可以视为PyTorch模型的一种中间表示,TorchScript表示的PyTorch模型可以直接在C++中进行读取。PyTorch在1.0版本之后都可以使用TorchScript的方式来构建序列化的模型。TorchScript提供了Tracing和Script两种应用方式。
Tracing应用示例如下:
class MyModel(torch.nn.Module): def __init__(self): super(MyModel, self).__init__() self.linear = torch.nn.Linear(4, 4) def forward(self, x, h): new_h = torch.tanh(self.linear(x) + h) return new_h, new_h# 创建模型实例 my_model = MyModel()# 输入示例x, h = torch.rand(3, 4), torch.rand(3, 4)# torch.jit.trace方法对模型构建TorchScripttraced_model = torch.jit.trace(my_model, (x, h))# 保存转换后的模型traced_model.save('model.pt')在这段代码中,我们先是定义了一个简单模型并创建模型实例,然后给定输入示例,Tracing方法最关键的一步在于使用torch.jit.trace方法对模型进行TorchScript转化。我们可以获得转化后的traced_model对象获得其计算图属性和代码属性。计算图属性:
print(traced_model.graph)graph(%self.1 : __torch__.torch.nn.modules.module.___torch_mangle_1.Module, %input : Float(3, 4), %h : Float(3, 4)): %19 : __torch__.torch.nn.modules.module.Module = prim::GetAttr[name="linear"](%self.1) %21 : Tensor = prim::CallMethod[name="forward"](%19, %input) %12 : int = prim::Constant[value=1]() # /var/lib/jenkins/workspace/beginner_source/Intro_to_TorchScript_tutorial.py:188:0 %13 : Float(3, 4) = aten::add(%21, %h, %12) # /var/lib/jenkins/workspace/beginner_source/Intro_to_TorchScript_tutorial.py:188:0 %14 : Float(3, 4) = aten::tanh(%13) # /var/lib/jenkins/workspace/beginner_source/Intro_to_TorchScript_tutorial.py:188:0 %15 : (Float(3, 4), Float(3, 4)) = prim::TupleConstruct(%14, %14) return (%15)代码属性:
print(traced_cell.code)def forward(self, input: Tensor, h: Tensor) -> Tuple[Tensor, Tensor]: _0 = torch.add((self.linear).forward(input, ), h, alpha=1) _1 = torch.tanh(_0) return (_1, _1)这样我们就可以将整个模型都保存到硬盘上了,并且经过这种方式保存下来的模型可以加载到其他其他语言环境中。
TorchScript的另一种实现方式是Script的方式,可以算是对Tracing方式的一种补充。当模型代码中含有if或者for-loop等控制流程序时,使用Tracing方式是无效的,这时候可以采用Script方式来进行实现TorchScript。实现方法跟Tracing差异不大,关键在于把jit.tracing换成jit.script方法,示例如下。
scripted_model = torch.jit.script(MyModel)scripted_model.save('model.pt')除了Tracing和Script之外,我们也可以混合使用这两种方式,这里不做详述。总之,TorchScript为我们提供了一种表示形式,可以对代码进行编译器优化以提供更有效的执行。
2.3 libtorch
在Python环境下对训练好的模型进行转换之后,我们需要C++环境下的PyTorch来读取模型并进行编译部署。这种C++环境下的PyTorch就是libtorch。因为libtorch通常用来作为PyTorch模型的C++接口,libtorch也称之为PyTorch的C++前端。
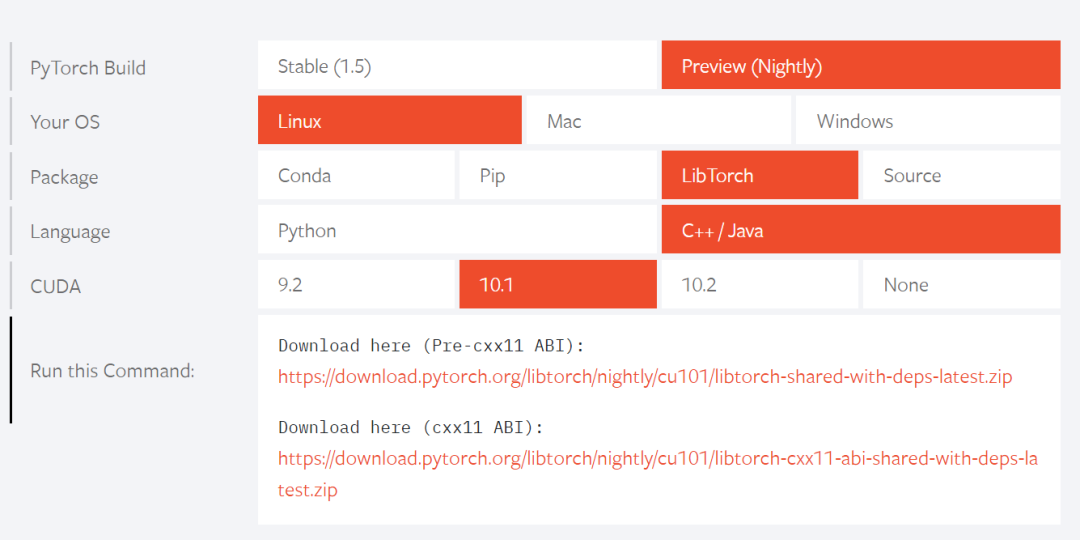
我们可以直接从PyTorch官网下载已经编译好的libtorch安装包,当然也可以下载源码自行进行编译。这里需要注意的是,安装的libtorch版本要与Python环境下的PyTorch版本一致。
安装好libtorch后可简单测试下是否正常。比如我们用TorchScript转换一个预训练模型,示例如下:
import torchimport torchvision.models as modelsvgg16 = models.vgg16()example = torch.rand(1, 3, 224, 224).cuda() model = model.eval()traced_script_module = torch.jit.trace(model, example)output = traced_script_module(torch.ones(1,3,224,224).cuda())traced_script_module.save('vgg16-trace.pt')print(output)输出为:
tensor([[ -0.8301, -35.6095, 12.4716]], device='cuda:0', grad_fn=<AddBackward0>)然后切换到C++环境,编写CmakeLists文件如下:
cmake_minimum_required(VERSION 3.0.0 FATAL_ERROR)project(libtorch_test)find_package(Torch REQUIRED)message(STATUS "Pytorch status:")message(STATUS "libraries: ${TORCH_LIBRARIES}")add_executable(libtorch_test test.cpp)target_link_libraries(libtorch_test "${TORCH_LIBRARIES}")set_property(TARGET libtorch_test PROPERTY CXX_STANDARD 11)继续编写test.cpp代码如下:
#include "torch/script.h"#include "torch/torch.h"#include #include using namespace std;int main(int argc, const char* argv[]){ if (argc != 2) { std::cerr <"usage: example-app \n"; return -1; } // 读取TorchScript转化后的模型 torch::jit::script::Module module; try { module = torch::jit::load(argv[1]); } catch (const c10::Error& e) { std::cerr <"error loading the model\n"; return -1; } module->to(at::kCUDA); assert(module != nullptr); std::cout << "ok\n"; // 构建示例输入 std::vector<:jit::ivalue> inputs; inputs.push_back(torch::ones({1, 3, 224, 224}).to(at::kCUDA)); // 执行模型推理并输出tensor at::Tensor output = module->forward(inputs).toTensor(); std::cout << output.slice(/*dim=*/1, /*start=*/0, /*end=*/5) << '\n';}编译test.cpp并执行,输出如下。对比Python环境下的的运行结果,可以发现基本是一致的,这也说明当前环境下libtorch安装没有问题。
ok-0.8297, -35.6048, 12.4823[Variable[CUDAFloatType]{1,3}]2.4 完整部署流程
通过前面对TorchScript和libtorch的描述,其实我们已经基本将PyTorch的C++部署已经基本讲到了,这里我们再来完整的理一下整个流程。基于C++的PyTorch模型部署流程如下。
第一步:
通过torch.jit.trace方法将PyTorch模型转换为TorchScript,示例如下:
import torchfrom torchvision.models import resnet18model =resnet18()example = torch.rand(1, 3, 224, 224)tracing.traced_script_module = torch.jit.trace(model, example)第二步:
将TorchScript序列化为.pt模型文件。
traced_script_module.save("traced_resnet_model.pt")第三步:
在C++中导入序列化之后的TorchScript模型,为此我们需要分别编写包含调用程序的cpp文件、配置和编译用的CMakeLists.txt文件。CMakeLists.txt文件示例内容如下:
cmake_minimum_required(VERSION 3.0 FATAL_ERROR)project(custom_ops)find_package(Torch REQUIRED)add_executable(example-app example-app.cpp)target_link_libraries(example-app "${TORCH_LIBRARIES}")set_property(TARGET example-app PROPERTY CXX_STANDARD 14)包含模型调用程序的example-app.cpp示例编码如下:
#include // torch头文件.#include #include int main(int argc, const char* argv[]) { if (argc != 2) { std::cerr <"usage: example-app \n"; return -1; } torch::jit::script::Module module; try { // 反序列化:导入TorchScript模型 module = torch::jit::load(argv[1]); } catch (const c10::Error& e) { std::cerr <"error loading the model\n"; return -1; } std::cout << "ok\n";}两个文件编写完成之后便可对其执行编译:
mkdir example_testcd example_testcmake -DCMAKE_PREFIX_PATH=/path/to/libtorch ..cmake --example_test . --config Release第四步:
给example-app.cpp添加模型推理代码并执行:
std::vector<:jit::ivalue> inputs;inputs.push_back(torch::ones({1, 3, 224, 224}));// 执行推理并将模型转化为Tensoroutput = module.forward(inputs).toTensor();std::cout << output.slice(/*dim=*/1, /*start=*/0, /*end=*/5) << '\n';以上便是C++中部署PyTorch模型的全过程,相关教程可参考PyTorch官方:
https://pytorch.org/tutorials/
总结
模型部署对于算法工程师而言非常重要,关系到你的工作能否产生实际价值。相应的也需要大家具备足够的工程能力,比如MySQL、Redis、C++、前端和后端的一些知识和开发技术,需要各位算法工程师都能够基本了解和能够使用。
新书首发《深度学习笔记》

往期精彩:
【深度学习笔记】我的第一本新书出版啦~
喜欢您就点个在看!
