Intriguing properties of neural networks
摘要
- 单个high level units与high level units的随机线性组合 没有区别。这说明,是由空间,而不是单个的unit,包含了神经网络高层的语意信息。
- 在很大程度上,输入输出的映射是不连续的。
- Note:给数据添加一点人眼不可察觉的扰动,可以导致网络的预判错误率达到最大。而这个扰动不可以是随意的人为扰动;相同的扰动可以造成不同的模型预判错误。
引言
本文讨论两种DNN违背直觉的性质。
第一点:通过两个实验,发现包含语义信息的是整个空间的激活函数,而不是单个的神经元。
- 前人通过找到最大化激活给定神经元的输入图像,分析该给定神经元的语义信息。
该“寻找最后一个feature layer的单个神经元”方法本文却发现 ϕ ( x ) \phi(x) ϕ(x)的基向量(random projections)与\phi(x)的坐标(coordinate,可看成基向量的随机组合)没有区别。这说明包含语义信息的是整个空间的激活函数,而不是单个的神经元。在向量空间不同的方向代表的词语,带来了丰富的语义上的关联与类比
第二点:给测试集上的图片添加肉眼不可识别的非随机的扰动,会导致不同的NN预判错误。
- adversarial examples会导致不同的NN预判错误。即使是由一个NN生成的一系列adversarial examples,这些adversarial examples依然会导致其他的NN预判错误。
对抗性样本 (adversarial examples) 很容易找到,且似乎与数据集的分布有关,而与神经网络的超参数无关。
Framework
- x ∈ R m x \in \mathbb{R}^m x∈Rm为输入图像
- ϕ ( x ) \phi(x) ϕ(x)为层的激活函数值
-
Units of: ϕ ( x ) \phi(x) ϕ(x)
这个表达式的意思是找到图像x’,使得φ(x)在ei方向的分量最大,也就是说图像x’最突出地反映了ei分量所在的神经元代表的语义特征。找到许多满足式子的x’
x
′
x'
x′为图像。
I
\Iota
I为来自还没有被网络训练过的数据分布中的图像集。
e
i
e_i
ei为第
i
i
i个隐含神经元的自然基向量。
我们的实验发现任意的方向
v
∈
R
n
v\in \mathbb{R}^n
v∈Rn
x
′
=
a
r
g
m
a
x
⏟
x
∈
I
⟨
ϕ
(
x
)
,
e
i
⟩
x'=\underbrace{arg max}_{x\in \Iota} \langle \phi(x),e_i \rangle
x′=x∈I
argmax⟨ϕ(x),ei⟩
这表示:在检查
ϕ
(
x
)
\phi(x)
ϕ(x)的特征的时候应该是指神经网络中,某个神经元表述某个特征的能力,不会比各个神经元的组合的能力弱,自然基向量并不比任意的向量强。另一句话说,这个表达式的意思是找到图像
x
′
x'
x′,使得
ϕ
(
x
)
\phi(x)
ϕ(x)在
e
i
e_i
ei方向的分量最大,也就是说图像
x
′
x'
x′’最突出地反映了
e
i
e_i
ei分量所在的神经元代表的语义特征。找到许多满足式子的
x
′
x'
x′。
- Mnist数据集(把
I
\Iota
I作为测试集)
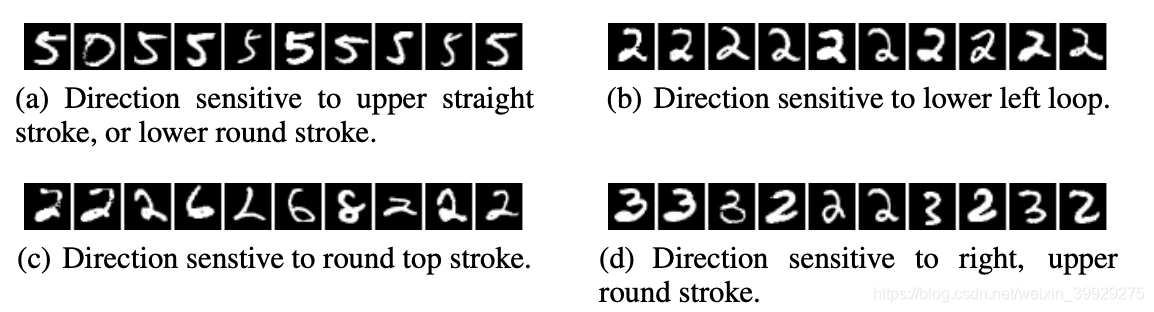
a)对下面弧形的比划敏感的神经元
b)对上面弧形或者下面平直的比划敏感的神经元
c)对左上弧形的比划敏感的神经元
d)对斜角直直的比划敏感的神经元
图1:最大化各个神经元的激活函数的图像。每行的图像都具有相同的语义特征。
a)对上面平直或者下面弧形的比划敏感的方向。
b)对左下圆圈的比划敏感的方向。
c)对上面弧形的比划敏感的方向。
d)对右上弧形的比划敏感的方向。
图2:最大化随机方向的激活函数的图像。每行的图像都具有相同的语义特征。 - AlexNet(把
I
\Iota
I作为验证集)
从以上的实验中,发现这时不再取某个神经元所在的单位方向矢量 e i e_i ei,而是取向量空间里的一个随机单位矢量 v v v,同样找到满足式子的图像集合。作者发现,这样找到的集合同样具有相似的语义特征。如何找到的,实验是如何进行的?


Blind Spots in Neural Networks
- unit-level inspection methods
- Global, network level inspection methods:帮助我们理解已训练的网络中,从输入到输出的映射
Spectral Analysis of Unstability 对不稳定的谱分析
参考 Intriguing properties of neural network(Box-constrained L-BFGS).
利用upper Lipschitz constant约束:给定Lipschitz条件,通过求出Lipschitz常数,根据常数的大小来分析该层的稳定性,常数越大,说明该层结构的改变速度越快,相对稳定性越低
上一节显示了纯监督训练产生的深层网络示例,这些网络对于特殊形式的小扰动而言是不稳定的。对抗性样本独立于它们在网络和训练集上的泛化特性,表明在输入中存在较小的加性扰动(在欧几里得意义上,在最后一层的输出中产生较大的扰动。本节介绍了一种简单的过程,可通过测量每个整流层的光谱来测量和控制网络的附加稳定性。
数学上,
ϕ
(
x
)
\phi(x)
ϕ(x)表示K层的输出
ϕ
(
x
)
=
ϕ
K
(
ϕ
K
−
1
(
.
.
.
ϕ
1
(
x
;
W
1
)
;
W
2
)
.
.
.
;
W
K
)
\phi(x)=\phi_K(\phi_{K-1}(...\phi_1(x;W_1);W_2)...;W_K)
ϕ(x)=ϕK(ϕK−1(...ϕ1(x;W1);W2)...;WK)
其中,
x
x
x表示输入,
W
W
W表示参数,
ϕ
k
\phi_k
ϕk表示
k
−
1
k-1
k−1到
k
k
k层的算符映射。
ϕ ( x ) \phi(x) ϕ(x)的不稳定的原因可以由各层的上李普希茨常数(upper Lipschitz constant)解释。
∀
x
,
r
,
∣
∣
ϕ
k
(
x
;
W
k
)
−
ϕ
k
(
x
+
r
;
W
k
)
∣
∣
≤
L
k
∣
∣
r
∣
∣
\forall x,r, ||\phi_k(x;W_k)-\phi_k(x+r;W_k)||\leq L_k||r||
∀x,r,∣∣ϕk(x;Wk)−ϕk(x+r;Wk)∣∣≤Lk∣∣r∣∣
其中,
L
k
L_k
Lk为上李普希茨常数,且满足
L
k
≤
0
L_k\leq 0
Lk≤0
因此,满足上面不等式的网络,通过迭代也会满足下面的不等式。
∣
∣
ϕ
(
x
)
−
ϕ
(
x
+
r
)
∣
∣
≤
L
∣
∣
r
∣
∣
,
L
=
∏
k
=
1
K
L
k
||\phi(x)-\phi(x+r)||\leq L||r||, L=\prod_{k=1}^{K}L_k
∣∣ϕ(x)−ϕ(x+r)∣∣≤L∣∣r∣∣,L=k=1∏KLk
半-ReLU层(卷积或全连接)的映射可以写成
ϕ
k
(
x
;
W
k
,
b
k
)
=
m
a
x
(
0
,
W
k
x
+
b
k
)
\phi_k(x;W_k,b_k)=max(0,W_kx+b_k)
ϕk(x;Wk,bk)=max(0,Wkx+bk),
其中,
∣
∣
W
∣
∣
||W||
∣∣W∣∣表示W的算子范数。
因为非线性ReLU函数为
ρ
(
x
)
=
m
a
x
(
x
,
0
)
\rho(x)=max(x,0)
ρ(x)=max(x,0)满足
∣
∣
ρ
(
x
)
−
ρ
(
x
+
r
)
∣
∣
≤
∣
∣
r
∣
∣
||\rho(x)-\rho(x+r)||\leq||r||
∣∣ρ(x)−ρ(x+r)∣∣≤∣∣r∣∣,因此说ReLU函数是contractive
∣
∣
ϕ
k
(
x
;
W
k
)
−
ϕ
k
(
x
+
r
;
W
k
)
∣
∣
=
∣
∣
m
a
x
(
0
,
W
k
x
+
b
k
)
−
m
a
x
(
0
,
W
k
(
x
+
r
)
+
b
k
)
∣
∣
≤
∣
∣
W
k
r
∣
∣
≤
∣
∣
W
k
∣
∣
∣
∣
r
∣
∣
||\phi_k(x;W_k)-\phi_k(x+r;W_k)||=||max(0,W_kx+b_k)-max(0,W_k(x+r)+b_k)||\leq||W_kr||\leq||W_k||||r||
∣∣ϕk(x;Wk)−ϕk(x+r;Wk)∣∣=∣∣max(0,Wkx+bk)−max(0,Wk(x+r)+bk)∣∣≤∣∣Wkr∣∣≤∣∣Wk∣∣∣∣r∣∣
那么,就可以得到
L k ≤ ∣ ∣ W k ∣ ∣ L_k\leq||W_k|| Lk≤∣∣Wk∣∣
另一方面,最大池化层也是contractive,所以
∀
x
,
r
,
∣
∣
ϕ
k
(
x
)
−
ϕ
k
(
x
+
r
)
∣
∣
≤
∣
∣
r
∣
∣
\forall x,r, ||\phi_k(x)-\phi_k(x+r)||\leq||r||
∀x,r,∣∣ϕk(x)−ϕk(x+r)∣∣≤∣∣r∣∣
由雅各布矩阵,可以把
ϕ
k
(
x
)
\phi_k(x)
ϕk(x)写成如下形式
ϕ
k
(
x
)
=
x
(
ϵ
+
∣
∣
x
∣
∣
2
)
γ
\phi_k(x)=\frac{x}{(\epsilon+||x||^2)^{\gamma}}
ϕk(x)=(ϵ+∣∣x∣∣2)γx
那么可以验证,
∀
x
,
r
,
∣
∣
ϕ
k
(
x
)
−
ϕ
k
(
x
+
r
)
∣
∣
≤
ϵ
−
γ
∣
∣
r
∣
∣
\forall x,r, ||\phi_k(x)-\phi_k(x+r)||\leq \epsilon^{-\gamma}||r||
∀x,r,∣∣ϕk(x)−ϕk(x+r)∣∣≤ϵ−γ∣∣r∣∣
其中,
γ
∈
[
0.5
,
1
]
\gamma\in[0.5,1]
γ∈[0.5,1]
结果是,可以通过简单地计算每个完全连接和卷积层的==算子范数(operator norm,upper Lipschitz constant)==来获得网络不稳定的保守度量。由于范数是由完全连接矩阵的最大奇异值直接给出的,所以完全连接的情况是微不足道的。
用 W W W表示四维张量,用输入特征 C C C,输出特征 D D D,support N × N N\times N N×N和卷积核 D e l t a Delta Delta作用于卷积层.
W
x
=
{
∑
c
=
1
C
x
c
⋆
w
c
,
d
(
n
1
Δ
,
n
2
Δ
)
;
d
=
1...
,
D
}
W_x=\{\sum_{c=1}^Cx_c\star w_{c,d}(n_1\Delta,n_2\Delta);d=1...,D\}
Wx={c=1∑Cxc⋆wc,d(n1Δ,n2Δ);d=1...,D}
其中,
⋆
\star
⋆为卷积符号
以下看不懂
那么,利用 Parseval’s公式,我们得到
∣
∣
W
∣
∣
=
s
u
p
ξ
∈
[
0
,
N
Δ
−
1
)
2
∣
∣
A
(
ξ
)
∣
∣
||W||=sup_{\xi\in[0,N\Delta^{-1})^2}||A(\xi)||
∣∣W∣∣=supξ∈[0,NΔ−1)2∣∣A(ξ)∣∣
A
(
ξ
)
A(\xi)
A(ξ)可能是度量神经网络不稳定性的一个指标
A
(
ξ
)
A(\xi)
A(ξ)是。。。。。。
D
×
(
C
⋅
Δ
2
)
D\times(C\cdot \Delta^2)
D×(C⋅Δ2)
d
=
1...
D
,
A
(
ξ
)
d
=
(
Δ
−
2
w
c
,
d
^
(
ξ
+
l
⋅
N
⋅
Δ
−
1
)
;
c
=
1...
C
,
l
=
(
0...
Δ
−
1
)
2
)
d=1...D,A(\xi)_d=(\Delta^{-2}\hat{w_{c,d}}(\xi+l\cdot N\cdot \Delta^{-1}); c=1...C,l=(0...\Delta-1)^2)
d=1...D,A(ξ)d=(Δ−2wc,d^(ξ+l⋅N⋅Δ−1);c=1...C,l=(0...Δ−1)2)
到这里是看不懂的
w
c
,
d
^
\hat{w_{c,d}}
wc,d^是
w
c
,
d
w_{c,d}
wc,d的二维傅立叶变化,即
w
c
,
d
^
(
ξ
)
=
∑
u
∈
[
0
,
N
)
2
w
c
,
d
(
u
)
e
−
2
π
i
(
u
,
ξ
)
/
N
2
\hat{w_{c,d}}(\xi)=\sum_{u\in[0,N)^2}w_{c,d}(u)e^{-2\pi i(u,\xi)/N^2}
wc,d^(ξ)=∑u∈[0,N)2wc,d(u)e−2πi(u,ξ)/N2
通过计算各类网络层的约束,发现在该条件下,不稳定性主要是由卷积层和全连接层产生的,全连接层的算子范数可以直接由最大奇异值得到,卷积层作者给出了具体的算法,最终结果如下:
因此,可以采用利普希茨连续条件的上确界来约束网络,从而帮助改善网络的常规错误
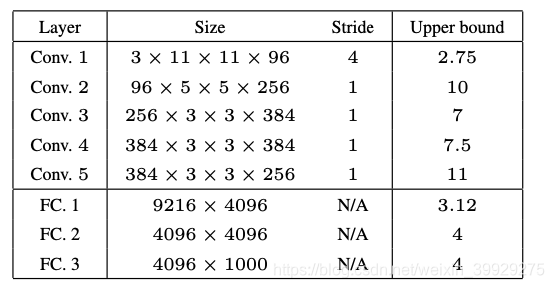
上图显示了使用看不懂从Imagenet classification with deep convolutional neural networks.中计算出的Lipschitz常数上限。它表明不稳定性可以在第一卷积层中立即出现。
这些结果与上一节中构造的盲点的出现是一致的,但是它们并没有试图解释为什么这些对抗性样本会在不同的超参数或训练集中出现。我们强调我们计算上限:大界限不会自动转化为对抗性示例的存在;但是,小范围保证不会出现此类示例。这表明可以对参数进行简单的正则化,包括对每个上限Lipschitz边界进行惩罚,这可能有助于改善网络的泛化误差。
问题
- ϕ k ( x ) = x ( ϵ + ∣ ∣ x ∣ ∣ 2 ) γ \phi_k(x)=\frac{x}{(\epsilon+||x||^2)^{\gamma}} ϕk(x)=(ϵ+∣∣x∣∣2)γx是如何来的?
Intriguing properties of neural networks Page 9
Since its Jacobian is a projection onto a subset of the input coordinates and hence does not expand the gradients. Finally, if ϕ k \phi_k ϕk is a contrast-normalization layer. ϕ k ( x ) = x ( ϵ + ∣ ∣ x ∣ ∣ 2 ) γ \phi_k(x)=\frac{x}{(\epsilon+||x||^2)^{\gamma}} ϕk(x)=(ϵ+∣∣x∣∣2)γx