拿到数据之后该怎么分析?
此文章将通过实战项目,分享一些最重要的数据分析方法。
数据来源:
https://www.kaggle.com/jessemostipak/hotel-booking-demandwww.kaggle.com知识点:
- 使用sklearn中的LogisticRegression进行建模
- 使用sklearn.neighbors中的KNeighborClassifier进行建模
- 将分类数据转化为量化数据的三种方法,get_dummies,replace,sklearn.Preprocessing.LabelEncoder
- 检测模型准确度的两种方法:ConfusionMatrix,accuracy_score
- 使用seaborn中的countplot;barplot;violinplot进行可视化
分析过程:
导入库和数据
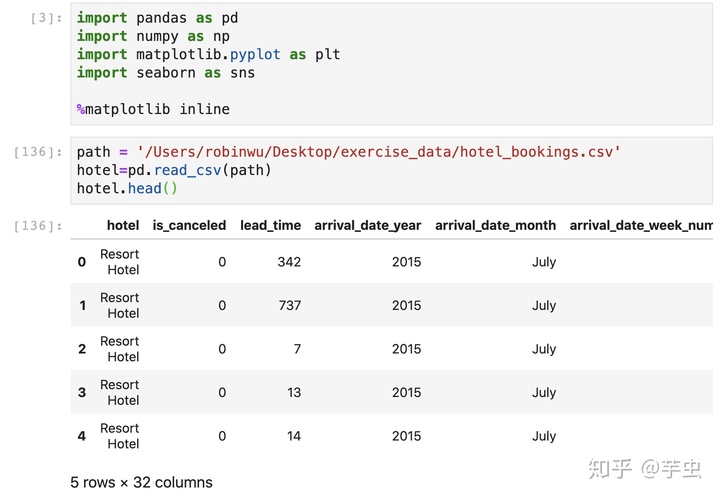
查看数据基本信息:

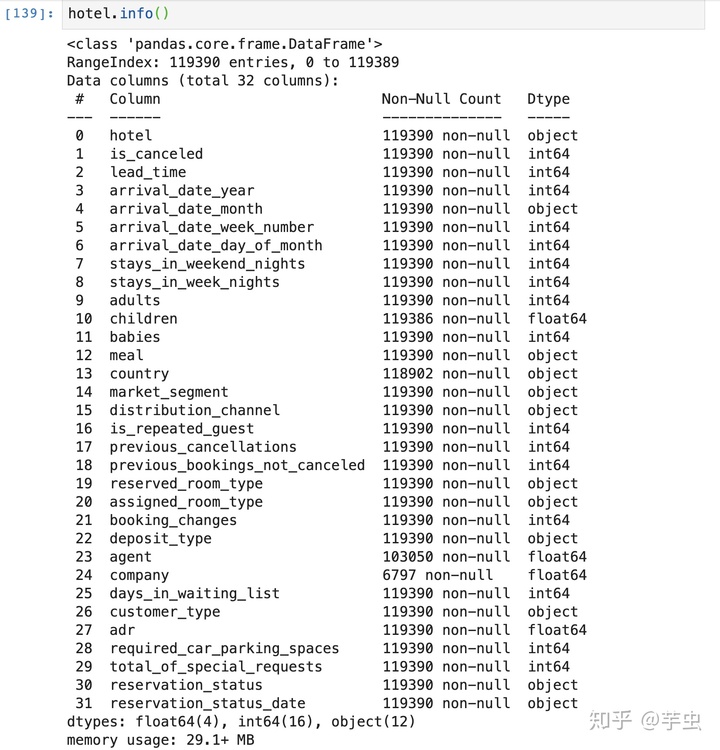
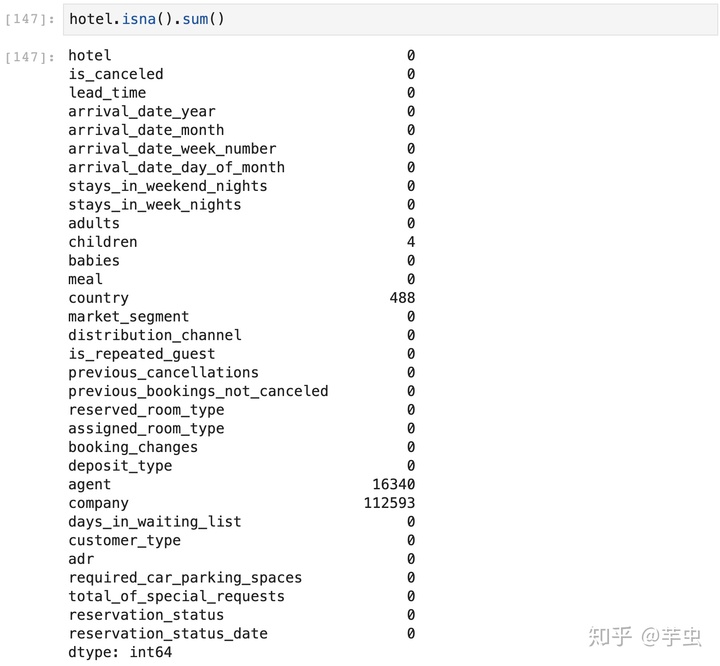
存在空值的解决办法:
- 将空值替换「df['country']=df['country'].replace(np.nan,'PRT')」「df['children']=df['children'].replace(np.nan,'0'),若将空值替换为文字0,为了进行回归分析,需要将其数据类型替换为数值型 df['children']=df['children'].astype('int') 」。
- 删除包含空值的列「hotel.drop['col1','col2']」
- 删除包含空值的行「hotel=hotel.dropna( )」
对于空值过多的列,可以选择删除整列。(如果该列数据在分析中可以被舍弃)
此处选择执行:
hotel=hotel.drop(['country','agent','company'],axis=1)#删除空值过多的列对于空值较少的列,如此处的'children'列,可以选择删除包含空值的行,或者替换其中的空值。
此处选择执行:
hotel=hotel.dropna() #删除有空值的列再次检查空值情况:
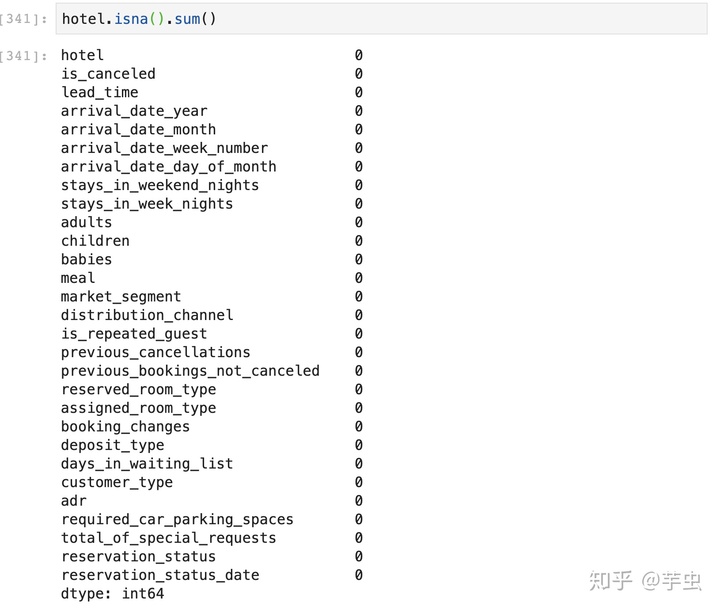
为了进行逻辑回归,处理数据类型为object的列
找到数据类型为object的列名:
#方法1
columns_list=list(hotel.columns)
cate_list=[]
for i in columns_list:
if hotel[i].dtype == 'object':
cate_list.append(i)
#方法2(人生苦短,我用python)
cate_list=hotel.select_dtypes(include='object').columns方法1会得到一个列表对象,方法2会得到一个index对象,此处执行方法1。
处理数据类型为object的列,一般有三种方法:
1. 使用LabelEncoder 「给每列中的值的一个种类赋予一个整数」
from sklearn.preprocessing import LabelEncoder
le=LabelEncoder()
for i in cate_list:
hotel[i]=let.fit_transform(hotel[i])2. 使用pd.DataFrame.get_dummies()「通过dummy(哑变量:0/1)将categorical features转变为numerical features。如:月份存在12种种类,则将月份列转换为12列,列名分别表示一个月份,1表示为是该月份,0表示为不是该月份」缺点:当cardinality大时,会生成过多的列,导致建模速度降低
hotel=hotel.get_dummies(hotel,prefix=['hotel','arrival_date_month','meal',
'country','market_segment','distribution_channel','reserved_room_type',
'assigned_room_type','deposit_type','customer_type','reservation_status'])3. 使用pd.Series.replace() 「适用于数据种类带有排序意义(如:月份),并且修改列数少的情况」
hotel_data['arrival_date_month'].replace({'January' : '1',
'February' : '2',
'March' : '3',
'April' : '4',
'May' : '5',
'June' : '6',
'July' : '7',
'August' : '8',
'September' : '9',
'October' : '10',
'November' : '11',
'December' : '12'}, inplace=True)此处执行第一种方法:
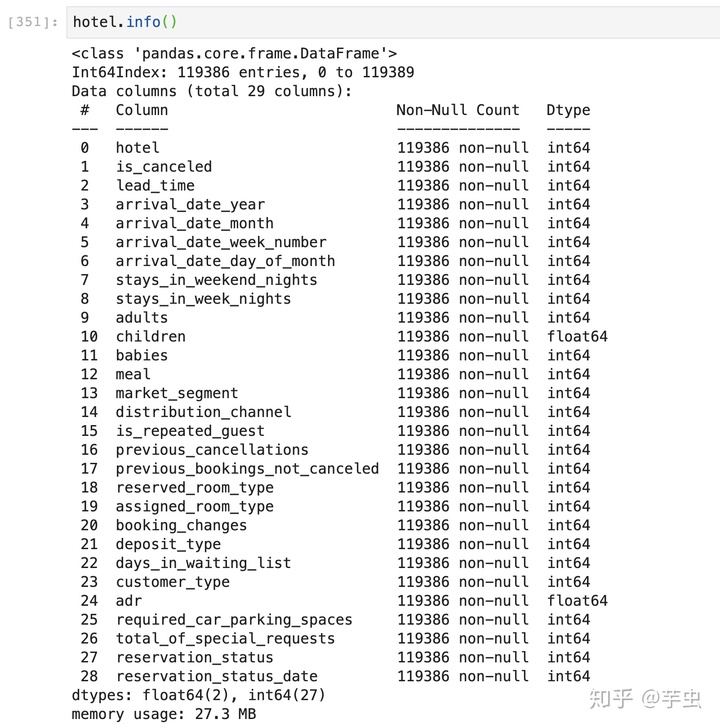
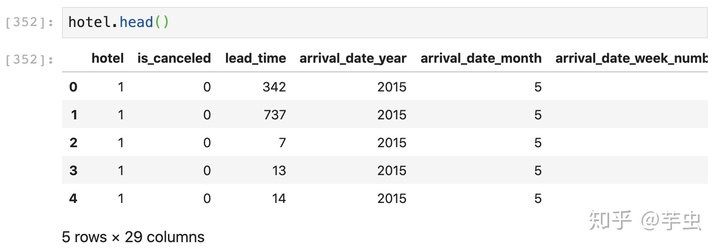
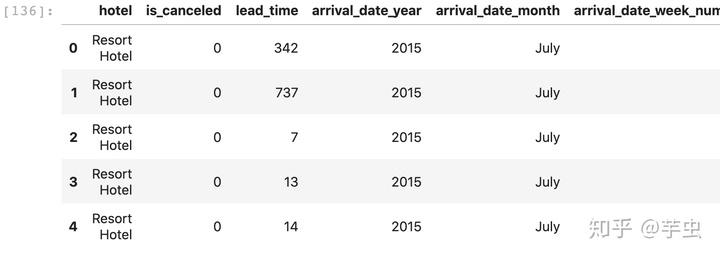
对比转化前后数据可以发现,Resort Hotel -> 1 ; July -> 5 。在这里,七月不一定被转换成7,LabelEncoder不认识月份。 而使用replace法则可以保证每个数字对应的都是相应的月份。
开始建立LogisticRegression模型:
第一步:将数据分为训练组和测试组
y=hotel['hotel'] #y为目标值列,相当于应变量
x=hotel.drop('hotel',axis=1)#x为非目标值列,相当于自变量
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=0,test_size=0.2)
#按照seed 0 进行随机抽取,测试组的数据量为总数据的20%第二步:用数据训练模型
lr=LogisticRegression(max_iter=3000) #创建一个空模型
lr.fit(x_train,y_train) #训练模型
predicted_list=lr.predict(x_test) #用模型预测测试组数据LogisticRegression()中默认的max_iter=100,当数据较多时,可能会报错,显示「/opt/conda/lib/python3.7/site-packages/sklearn/linear_model/_logistic.py:764: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.」
此时可以选择无视,直接用拟合100次的结果来进行分析,也可以通过修改最大拟合次数来增加模型拟合度,不过模型的训练时间也会相应增加。在这里将max_iter修改成3000就不会报错了。如果用max_iter=100得到的结果准确值为75%,拟合次数增加后,模型准确度也增加了。
第三步:查看模型准确度
from sklearn.metrics import accuracy_score
score_1=accuracy_score(y_test,predicted_list)
score_1
开始建立KNeighborsClassifier模型
在使用KNN模型时,我们不确定neighbors的数量取多少能够使模型较好的进行预测,所以我们用For循环来测试各取值的情况:
from sklearn.neighbors import KNeighborsClassifier
accurate_rate_list=[] #创建一个空的列表用于存储模型准确度
for i in range(1,11): #测试取值为1-10的情况
knn=KNeighborsClassifier(n_neighbors=i)
knn.fit(x_train,y_train)
predicted_y=knn.predict(x_test)
scores=accuracy_score(y_test,predicted_y)
accurate_rate_list.append(scores) #将不同值的准确度按照1-10存入该列表中然后对得到的列表用matplotlib.pyplot进行可视化:
import matplotlib.pyplot as plt
plt.plot(range(1,11),accurate_rate_list)
plt.xlabel('Numbers of Neighbors')
plt.ylabel('Accuracy Scores')
plt.show()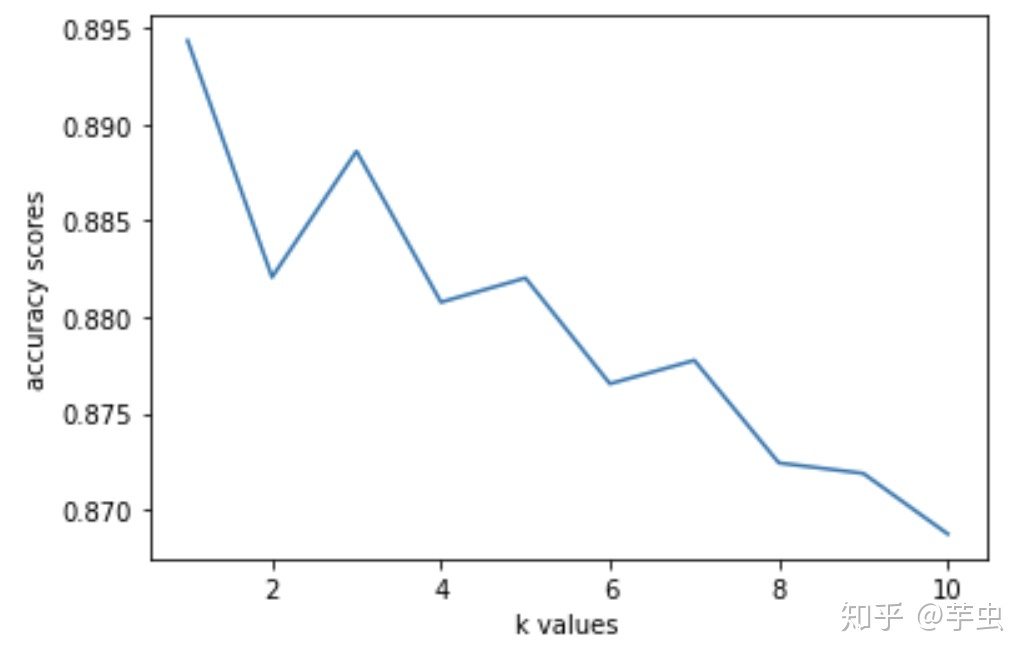

开始建立随机森林模型:
仍然使用相同的训练集和测试集,进行建模:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
rfc=RandomForestClassifier()
rfc.fit(x_train,y_train)查看预测准确度:
pred_2=rfc.predict(x_test)
score_2=accuracy_score(y_test,pred_2)
print(score_2)
可以发现随机森林模型的预测准确度大大优于其余两者。
用Seaborn进行可视化
使用violinplot进行可视化,分析年份和酒店预定取消率的关系图:
plt.figure(figsize=(10,10)) #建立画布
sns.violinplot(x='arrival_date_year', y ='lead_time',
hue="is_canceled", data=hotel, palette="Set1",
bw=0.2, #表示密度函数贴合中心线的程度
cut=2, linewidth=2, iner= 'box', split = True)
sns.despine(left=True) #隐藏左侧数轴
plt.title('Arrival Year vs Lead Time vs Canceled Situation', weight='bold')
plt.xlabel('Year', fontsize=12)
plt.ylabel('Lead Time', fontsize=12)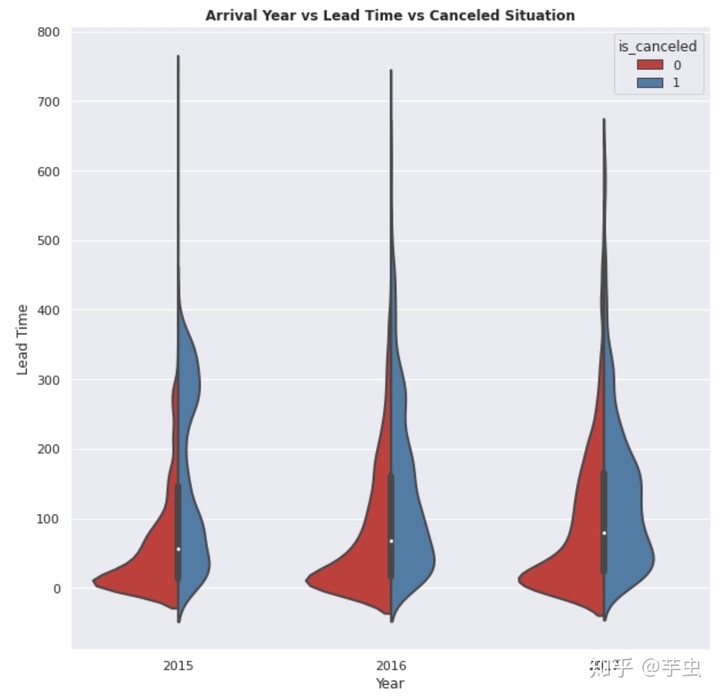
用countplot进行数据可视化
plt.figure(figsize=(15,10))
sns.countplot(x='arrival_date_month', data = hotel,
order=pd.value_counts(hotel['arrival_date_month']).index,)
plt.title('Arrival Month', weight='bold')
plt.xlabel('Month', fontsize=12)
plt.ylabel('Count', fontsize=12)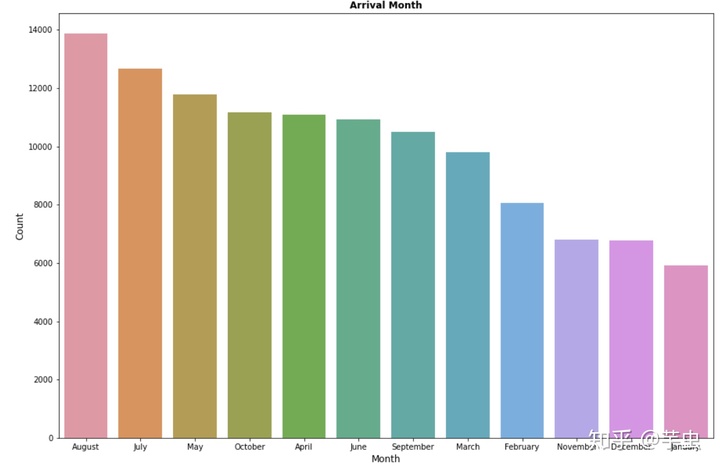
。
。
。
。
。
。