导读
- 文章首发于微信公众号【码猿技术专栏】
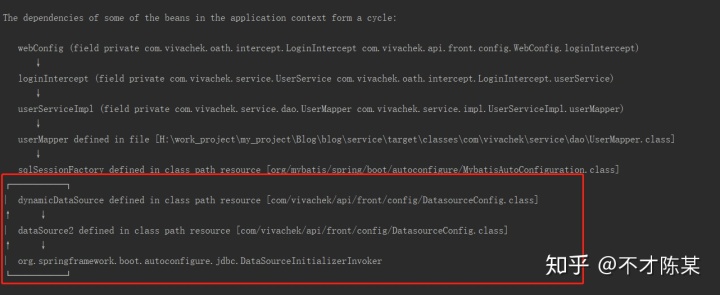
- 提到了一个坑就是动态数据源添加@Primary接口就会造成循环依赖异常,如下图:
- 这个就是典型的构造器依赖,详情请看上面两篇文章,这里不再详细赘述了。本篇文章将会从源码深入解析Spring是如何解决循环依赖的?为什么不能解决构造器的循环依赖?
什么是循环依赖
- 简单的说就是A依赖B,B依赖C,C依赖A这样就构成了循环依赖。
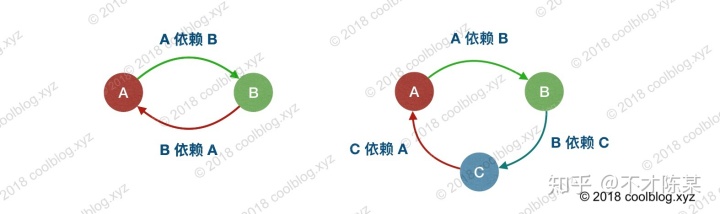
- 循环依赖分为构造器依赖和属性依赖,众所周知的是Spring能够解决属性的循环依赖(set注入)。下文将从源码角度分析Spring是如何解决属性的循环依赖。
思路
- 如何解决循环依赖,Spring主要的思路就是依据三级缓存,在实例化A时调用doGetBean,发现A依赖的B的实例,此时调用doGetBean去实例B,实例化的B的时候发现又依赖A,如果不解决这个循环依赖的话此时的doGetBean将会无限循环下去,导致内存溢出,程序奔溃。spring引用了一个早期对象,并且把这个"早期引用"并将其注入到容器中,让B先完成实例化,此时A就获取B的引用,完成实例化。
三级缓存
- Spring能够轻松的解决属性的循环依赖正式用到了三级缓存,在AbstractBeanFactory中有详细的注释。
/**一级缓存,用于存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用*/
- 一级缓存:singletonObjects,存放完全实例化属性赋值完成的Bean,直接可以使用。
- 二级缓存:earlySingletonObjects,存放早期Bean的引用,尚未属性装配的Bean
- 三级缓存:singletonFactories,三级缓存,存放实例化完成的Bean工厂。
开撸
- 先上一张流程图看看Spring是如何解决循环依赖的
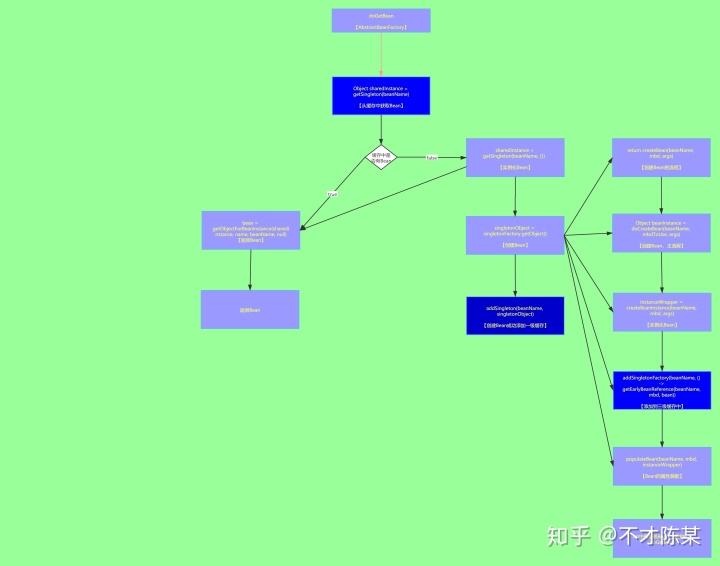
- 上图标记蓝色的部分都是涉及到三级缓存的操作,下面我们一个一个方法解析
【1】 getSingleton(beanName):源码如下:
//查询缓存
- 从源码可以得知,doGetBean最初是查询缓存,一二三级缓存全部查询,如果三级缓存存在则将Bean早期引用存放在二级缓存中并移除三级缓存。(升级为二级缓存)
【2】addSingletonFactory:源码如下
- 从源码得知,Bean在实例化完成之后会直接将未装配的Bean工厂存放在三级缓存中,并且移除二级缓存
【3】addSingleton:源码如下:
//获取单例对象的方法,DefaultSingletonBeanRegistry#getSingleton
- 总之一句话,Bean添加到一级缓存,移除二三级缓存。
扩展
【1】为什么Spring不能解决构造器的循环依赖?
- 从流程图应该不难看出来,在Bean调用构造器实例化之前,一二三级缓存并没有Bean的任何相关信息,在实例化之后才放入三级缓存中,因此当getBean的时候缓存并没有命中,这样就抛出了循环依赖的异常了。
【2】为什么多实例Bean不能解决循环依赖?
- 多实例Bean是每次创建都会调用doGetBean方法,根本没有使用一二三级缓存,肯定不能解决循环依赖。
总结
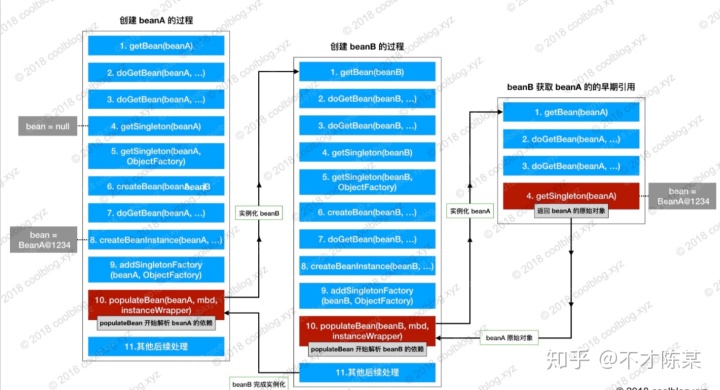
- 根据以上的分析,大概清楚了Spring是如何解决循环依赖的。假设A依赖B,B依赖A(注意:这里是set属性依赖)分以下步骤执行:
- A依次执行doGetBean、查询缓存、createBean创建实例,实例化完成放入三级缓存singletonFactories中,接着执行populateBean方法装配属性,但是发现有一个属性是B的对象。
- 因此再次调用doGetBean方法创建B的实例,依次执行doGetBean、查询缓存、createBean创建实例,实例化完成之后放入三级缓存singletonFactories中,执行populateBean装配属性,但是此时发现有一个属性是A对象。
- 因此再次调用doGetBean创建A的实例,但是执行到getSingleton查询缓存的时候,从三级缓存中查询到了A的实例(早期引用,未完成属性装配),此时直接返回A,不用执行后续的流程创建A了,那么B就完成了属性装配,此时是一个完整的对象放入到一级缓存singletonObjects中。
- B创建完成了,则A自然完成了属性装配,也创建完成放入了一级缓存singletonObjects中。
- Spring三级缓存的应用完美的解决了循环依赖的问题,下面是循环依赖的解决流程图。