## 使用Flink接收kafka数据,处理后发送到新topic
首先先下载kafka的linux版本,可以搜索阿里云的镜像进行下载,速度很快
http://mirrors.aliyun.com/apache/kafka/
安装过程可自行搜索。。。
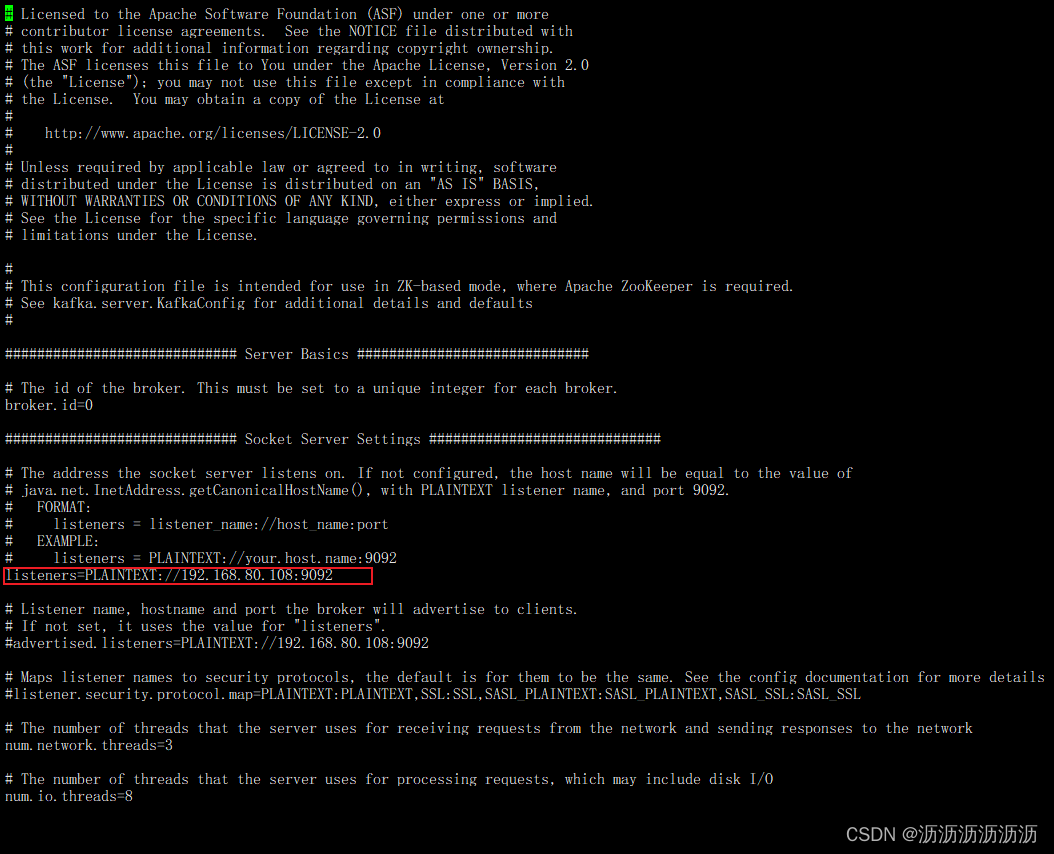
注意,安装号kafka后需要修改配置文件
vi kafka的安装目录/config/server.properties
将文件中的listeners注释去掉,并修改值为你虚拟机的ip,如下图
然后启动kafka,这里要切换到bin目录下
sh kafka-server-start.sh -daemon ../config/server.properties
启动完可以切换到logs目录下查看日志
再打开两个shell页面,分别为生产和消费使用
vi server.log
启动生产者服务,bin目录下
./kafka-console-producer.sh --topic 自定义topic名称 --bootstrap-server 你虚拟机ip:9092

启动消费者服务,bin目录下
./kafka-console-consumer.sh --topic 自定义topic名称 --bootstrap-server 你虚拟机ip:9092
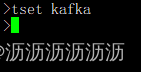
然后尝试在生成者输入字符,回车发送
消费者可以收到消息,kafka安装完成,如果没有收到可以检查topic是否一致,ip是否正确
下面引入flink相关依赖

<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.19.0</flink.version>
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.12</scala.binary.version>
<maven.compiler.source>${target.java.version}</maven.compiler.source>
<maven.compiler.target>${target.java.version}</maven.compiler.target>
<log4j.version>2.17.1</log4j.version>
</properties>
<repositories>
<repository>
<id>apache.snapshots</id>
<name>Apache Development Snapshot Repository</name>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<!-- Apache Flink依赖项 -->
<!-- 之所以提供这些依赖项,是因为它们不应该打包到JAR文件中. -->
<dependency>
<!--Table API + DataStream-->
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!--JDBC连接器-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>1.16.0</version>
</dependency>
<!-- 在这里添加连接器依赖项。它们必须在默认作用域(编译)中。 -->
<dependency>
<!--kafka连接器-->
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.16.0</version>
</dependency>
<!-- 添加日志框架,以便在IDE中运行时生成控制台输出. -->
<!-- 默认情况下,这些依赖项从应用程序JAR中排除. -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
<scope>compile</scope>
</dependency>
</dependencies>
构建时会提示找不到类,在idea中勾选如图选项,或者在pom文件中修改scope的值为compile
下来开始写代码
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行数
env.setParallelism(4);
// 每10000毫秒进行一次checkpoint
env.enableCheckpointing(10000);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 设置 Kafka 消费者属性
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "ip");
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink-consumer-group");
properties.setProperty("key.deserializer", StringDeserializer.class.getName());
properties.setProperty("value.deserializer", StringDeserializer.class.getName());
// 创建Kafka消费者,将消费者添加到流
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("你设定的topic", new SimpleStringSchema(), properties);
//设置只读取最新数据
consumer.setStartFromLatest();
//添加数据源
DataStreamSource<String> source = env.addSource(consumer);
source.print();
DataStream<String> mappedStream = source.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value.toUpperCase(); //进行数据治理 例如,将值转换为大写
}
});
//创建一个Flink生产者,将处理过的数据发回去
mappedStream.addSink(new FlinkKafkaProducer<>("新的topic", new SimpleStringSchema(), properties));
env.execute("Flink Kafka Integration");
上面这种构建kafka数据源的方式官方显示已经过时,有另一种构建方式
KafkaSource<String> source = KafkaSource.<String>builder()
.setTopics("test")
.setGroupId("test-consumer-group")
.setBootstrapServers("ip:9092")
.setStartingOffsets(OffsetsInitializer.latest()) //消费最新数据
.setValueOnlyDeserializer(new SimpleStringSchema()).build();
DataStream<String> dataStream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
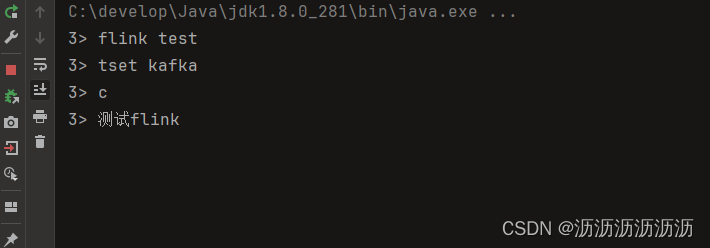
然后运行代码,在生产者生产一条数据进行查看
生产者
查看代码控制台
最后运行新的消费者,消费处理后的数据,只需修改topic
可以看到,flink英文变成了大写,简单接入完成