内容来自:
How to count tokens with Tiktoken
0. 背景
tiktoken是OpenAI开发的一种BPE分词器。
给定一段文本字符串(例如,“tiktoken is great!”)和一种编码方式(例如,“cl100k_base”),分词器可以将文本字符串切分成一系列的token(例如,[“t”, “ik”, “token”, " is", " great", “!”])。
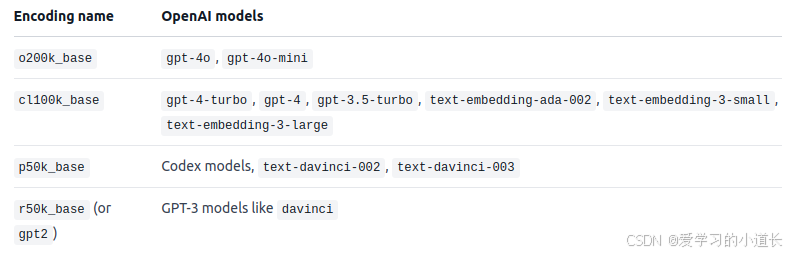
1. 安装 tiktoken
安装
$ pip install tiktoken
更新
$ pip install --upgrade tiktoken
...
Installing collected packages: tiktoken
Attempting uninstall: tiktoken
Found existing installation: tiktoken 0.7.0
Uninstalling tiktoken-0.7.0:
Successfully uninstalled tiktoken-0.7.0
Successfully installed tiktoken-0.8.0
2. 使用
import tiktoken
import os
#第一次运行时,它将需要互联网连接进行下载,所以设置环境代理,后续运行不需要互联网连接。
os.environ["http_proxy"] = "socks5://127.0.0.1:1080"
os.environ["https_proxy"] = "socks5://127.0.0.1:1080"
#按名称加载编码
encoding = tiktoken.get_encoding("cl100k_base")
print(encoding)
#加载给定模型名称的编码
encoding = tiktoken.encoding_for_model("gpt-4")
print(encoding)
#.encode() 方法将字符串转换成一系列代表这些文本的整数 token
encode = encoding.encode("China is great!")
print(encode)
#.decode() 整数 token 列表转化成字符串
print(encoding.decode(encode))
Source_numbers =[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]
print(encoding.decode(Source_numbers))
#.decode()可以应用于单个标记,对于不在 utf-8 边界上的标记,它可能会有损失。
#对于单个标记,.decode_single_token_bytes()安全地将单个整数token转换为它所代表的字节。
print([encoding.decode_single_token_bytes(token) for token in Source_numbers])
输出结果:
<Encoding 'cl100k_base'>
<Encoding 'cl100k_base'>
[23078, 374, 2294, 0]
China is great!
!"#$%&'()*+,-./012345
[b'!', b'"', b'#', b'$', b'%', b'&', b"'", b'(', b')', b'*', b'+', b',', b'-', b'.', b'/', b'0', b'1', b'2', b'3', b'4', b'5']
对比 OpenAI Tokenizer
分割方式:
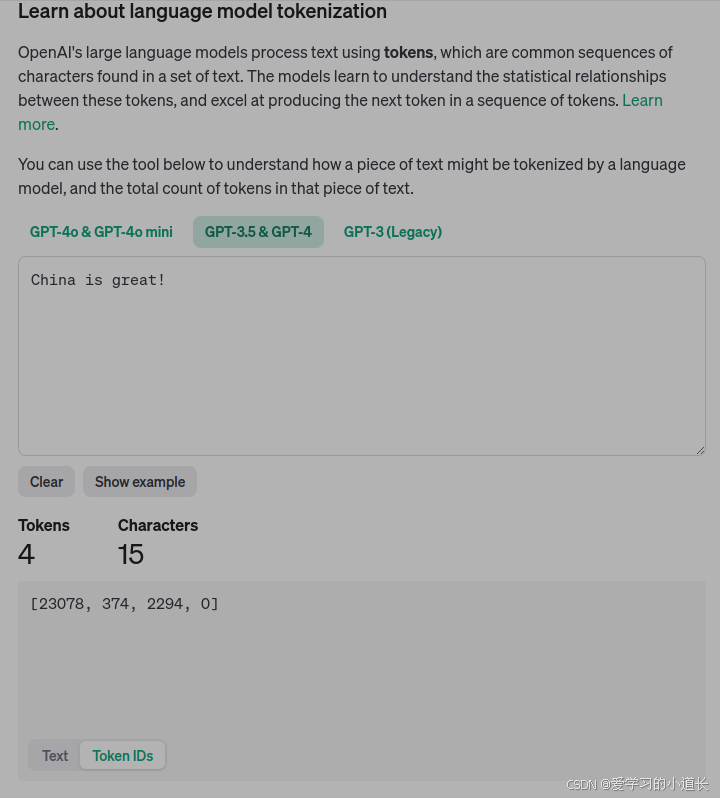
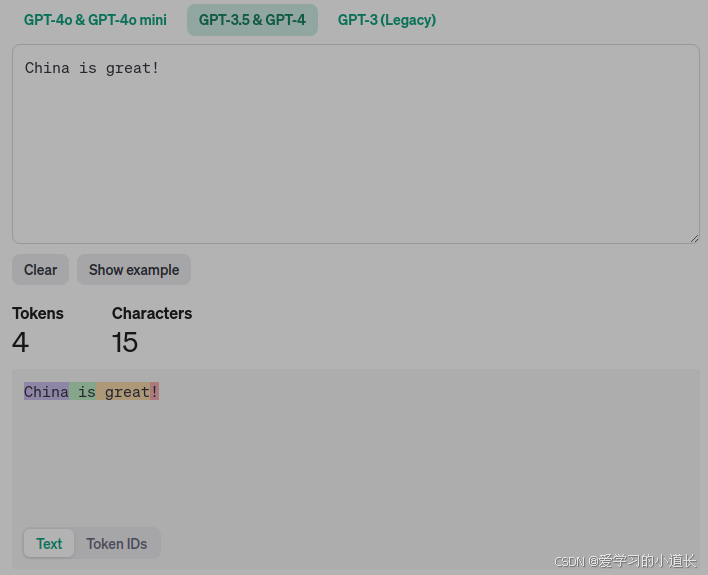
3. 函数
3.1 统计token数量
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""返回文本字符串中的Token数量"""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
num_tokens = num_tokens_from_string("China is great!", "cl100k_base")
print(num_tokens)
输出结果:
4
3.2 比较不同字符串在不同的编码方式下的表现
Encoding_method = ["r50k_base", "p50k_base", "cl100k_base", "o200k_base"]
def compare_encodings(example_string: str) -> None:
print(f'\nExample string: "{example_string}"')
for encoding_name in Encoding_method:
encoding = tiktoken.get_encoding(encoding_name)
token_integers = encoding.encode(example_string)
num_tokens = len(token_integers)
token_bytes = [encoding.decode_single_token_bytes(token) for token in token_integers]
print()
print(f"{encoding_name}: {num_tokens} tokens")
print(f"token integers: {token_integers}")
print(f"token bytes: {token_bytes}")
compare_encodings("3 * 12 = 36")
print("**"*30)
compare_encodings("俄罗斯的首都是莫斯科")
print("**"*30)
compare_encodings("ロシアの首都はモスクワ")
print("**"*30)
compare_encodings("Столицей России является Москва")
输出结果:
Example string: "3 * 12 = 36"
r50k_base: 5 tokens
token integers: [18, 1635, 1105, 796, 4570]
token bytes: [b'3', b' *', b' 12', b' =', b' 36']
p50k_base: 5 tokens
token integers: [18, 1635, 1105, 796, 4570]
token bytes: [b'3', b' *', b' 12', b' =', b' 36']
cl100k_base: 7 tokens
token integers: [18, 353, 220, 717, 284, 220, 1927]
token bytes: [b'3', b' *', b' ', b'12', b' =', b' ', b'36']
o200k_base: 7 tokens
token integers: [18, 425, 220, 899, 314, 220, 2636]
token bytes: [b'3', b' *', b' ', b'12', b' =', b' ', b'36']
************************************************************
Example string: "俄罗斯的首都是莫斯科"
r50k_base: 22 tokens
token integers: [46479, 226, 163, 121, 245, 23877, 107, 21410, 165, 99, 244, 32849, 121, 42468, 164, 236, 104, 23877, 107, 163, 100, 239]
token bytes: [b'\xe4\xbf', b'\x84', b'\xe7', b'\xbd', b'\x97', b'\xe6\x96', b'\xaf', b'\xe7\x9a\x84', b'\xe9', b'\xa6', b'\x96', b'\xe9\x83', b'\xbd', b'\xe6\x98\xaf', b'\xe8', b'\x8e', b'\xab', b'\xe6\x96', b'\xaf', b'\xe7', b'\xa7', b'\x91']
p50k_base: 22 tokens
token integers: [46479, 226, 163, 121, 245, 23877, 107, 21410, 165, 99, 244, 32849, 121, 42468, 164, 236, 104, 23877, 107, 163, 100, 239]
token bytes: [b'\xe4\xbf', b'\x84', b'\xe7', b'\xbd', b'\x97', b'\xe6\x96', b'\xaf', b'\xe7\x9a\x84', b'\xe9', b'\xa6', b'\x96', b'\xe9\x83', b'\xbd', b'\xe6\x98\xaf', b'\xe8', b'\x8e', b'\xab', b'\xe6\x96', b'\xaf', b'\xe7', b'\xa7', b'\x91']
cl100k_base: 16 tokens
token integers: [11743, 226, 15581, 245, 7741, 107, 9554, 61075, 72368, 21043, 164, 236, 104, 7741, 107, 70626]
token bytes: [b'\xe4\xbf', b'\x84', b'\xe7\xbd', b'\x97', b'\xe6\x96', b'\xaf', b'\xe7\x9a\x84', b'\xe9\xa6\x96', b'\xe9\x83\xbd', b'\xe6\x98\xaf', b'\xe8', b'\x8e', b'\xab', b'\xe6\x96', b'\xaf', b'\xe7\xa7\x91']
o200k_base: 7 tokens
token integers: [88920, 1616, 15425, 78710, 116619, 18384, 14552]
token bytes: [b'\xe4\xbf\x84\xe7\xbd\x97\xe6\x96\xaf', b'\xe7\x9a\x84', b'\xe9\xa6\x96', b'\xe9\x83\xbd\xe6\x98\xaf', b'\xe8\x8e\xab', b'\xe6\x96\xaf', b'\xe7\xa7\x91']
************************************************************
Example string: "ロシアの首都はモスクワ"
r50k_base: 13 tokens
token integers: [16253, 15661, 11839, 33426, 99, 244, 32849, 121, 31676, 40361, 8943, 14099, 25589]
token bytes: [b'\xe3\x83\xad', b'\xe3\x82\xb7', b'\xe3\x82\xa2', b'\xe3\x81\xae\xe9', b'\xa6', b'\x96', b'\xe9\x83', b'\xbd', b'\xe3\x81\xaf', b'\xe3\x83\xa2', b'\xe3\x82\xb9', b'\xe3\x82\xaf', b'\xe3\x83\xaf']
p50k_base: 13 tokens
token integers: [16253, 15661, 11839, 33426, 99, 244, 32849, 121, 31676, 40361, 8943, 14099, 25589]
token bytes: [b'\xe3\x83\xad', b'\xe3\x82\xb7', b'\xe3\x82\xa2', b'\xe3\x81\xae\xe9', b'\xa6', b'\x96', b'\xe9\x83', b'\xbd', b'\xe3\x81\xaf', b'\xe3\x83\xa2', b'\xe3\x82\xb9', b'\xe3\x82\xaf', b'\xe3\x83\xaf']
cl100k_base: 13 tokens
token integers: [42634, 57207, 39880, 16144, 61075, 72368, 15682, 2845, 95, 22398, 29220, 2845, 107]
token bytes: [b'\xe3\x83\xad', b'\xe3\x82\xb7', b'\xe3\x82\xa2', b'\xe3\x81\xae', b'\xe9\xa6\x96', b'\xe9\x83\xbd', b'\xe3\x81\xaf', b'\xe3\x83', b'\xa2', b'\xe3\x82\xb9', b'\xe3\x82\xaf', b'\xe3\x83', b'\xaf']
o200k_base: 10 tokens
token integers: [13231, 13668, 10398, 3385, 15425, 12232, 5205, 37938, 130685, 34022]
token bytes: [b'\xe3\x83\xad', b'\xe3\x82\xb7', b'\xe3\x82\xa2', b'\xe3\x81\xae', b'\xe9\xa6\x96', b'\xe9\x83\xbd', b'\xe3\x81\xaf', b'\xe3\x83\xa2', b'\xe3\x82\xb9\xe3\x82\xaf', b'\xe3\x83\xaf']
************************************************************
Example string: "Столицей России является Москва"
r50k_base: 34 tokens
token integers: [140, 94, 20375, 25443, 119, 18849, 141, 228, 16843, 140, 117, 12466, 254, 15166, 21727, 21727, 18849, 18849, 220, 40623, 38857, 30143, 40623, 16843, 20375, 21727, 40623, 12466, 250, 15166, 21727, 31583, 38857, 16142]
token bytes: [b'\xd0', b'\xa1', b'\xd1\x82', b'\xd0\xbe\xd0', b'\xbb', b'\xd0\xb8', b'\xd1', b'\x86', b'\xd0\xb5', b'\xd0', b'\xb9', b' \xd0', b'\xa0', b'\xd0\xbe', b'\xd1\x81', b'\xd1\x81', b'\xd0\xb8', b'\xd0\xb8', b' ', b'\xd1\x8f', b'\xd0\xb2', b'\xd0\xbb', b'\xd1\x8f', b'\xd0\xb5', b'\xd1\x82', b'\xd1\x81', b'\xd1\x8f', b' \xd0', b'\x9c', b'\xd0\xbe', b'\xd1\x81', b'\xd0\xba', b'\xd0\xb2', b'\xd0\xb0']
p50k_base: 34 tokens
token integers: [140, 94, 20375, 25443, 119, 18849, 141, 228, 16843, 140, 117, 12466, 254, 15166, 21727, 21727, 18849, 18849, 220, 40623, 38857, 30143, 40623, 16843, 20375, 21727, 40623, 12466, 250, 15166, 21727, 31583, 38857, 16142]
token bytes: [b'\xd0', b'\xa1', b'\xd1\x82', b'\xd0\xbe\xd0', b'\xbb', b'\xd0\xb8', b'\xd1', b'\x86', b'\xd0\xb5', b'\xd0', b'\xb9', b' \xd0', b'\xa0', b'\xd0\xbe', b'\xd1\x81', b'\xd1\x81', b'\xd0\xb8', b'\xd0\xb8', b' ', b'\xd1\x8f', b'\xd0\xb2', b'\xd0\xbb', b'\xd1\x8f', b'\xd0\xb5', b'\xd1\x82', b'\xd1\x81', b'\xd1\x8f', b' \xd0', b'\x9c', b'\xd0\xbe', b'\xd1\x81', b'\xd0\xba', b'\xd0\xb2', b'\xd0\xb0']
cl100k_base: 17 tokens
token integers: [74598, 7975, 1840, 10589, 21708, 49520, 23630, 2297, 47273, 46410, 5591, 14009, 50819, 45458, 23630, 4898, 94538]
token bytes: [b'\xd0\xa1\xd1\x82', b'\xd0\xbe\xd0\xbb', b'\xd0\xb8', b'\xd1\x86', b'\xd0\xb5\xd0\xb9', b' \xd0\xa0', b'\xd0\xbe\xd1\x81', b'\xd1\x81', b'\xd0\xb8\xd0\xb8', b' \xd1\x8f', b'\xd0\xb2', b'\xd0\xbb\xd1\x8f', b'\xd0\xb5\xd1\x82\xd1\x81\xd1\x8f', b' \xd0\x9c', b'\xd0\xbe\xd1\x81', b'\xd0\xba', b'\xd0\xb2\xd0\xb0']
o200k_base: 6 tokens
token integers: [44098, 1031, 131779, 27358, 24351, 72673]
token bytes: [b'\xd0\xa1\xd1\x82', b'\xd0\xbe\xd0\xbb', b'\xd0\xb8\xd1\x86\xd0\xb5\xd0\xb9', b' \xd0\xa0\xd0\xbe\xd1\x81\xd1\x81\xd0\xb8\xd0\xb8', b' \xd1\x8f\xd0\xb2\xd0\xbb\xd1\x8f\xd0\xb5\xd1\x82\xd1\x81\xd1\x8f', b' \xd0\x9c\xd0\xbe\xd1\x81\xd0\xba\xd0\xb2\xd0\xb0']
3.3 计算调用chat completions API 的token数量
import os
import httpx
import tiktoken
from openai import OpenAI
API_KEY = os.getenv("API_KEY")
BASE_URL = "https://api.deepbricks.ai/v1/"
# 设置代理服务器
proxy_url = 'socks5://127.0.0.1:1080'
# 创建一个 HTTPX 客户端并配置代理
proxy_client = httpx.Client(proxies={
"http://": proxy_url,
"https://": proxy_url,
})
def num_tokens_from_messages(messages, model="gpt-4o-mini"):
"""Return the number of tokens used by a list of messages."""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
print("Warning: model not found. Using o200k_base encoding.")
encoding = tiktoken.get_encoding("o200k_base")
# 针对不同的模型设置token数量
if model in {
"gpt-3.5-turbo-0125",
"gpt-4-0314",
"gpt-4-32k-0314",
"gpt-4-0613",
"gpt-4-32k-0613",
"gpt-4o-mini-2024-07-18",
"gpt-4o-2024-08-06"
}:
tokens_per_message = 3
tokens_per_name = 1
elif "gpt-3.5-turbo" in model:
print("Warning: gpt-3.5-turbo may update over time. Returning num tokens assuming gpt-3.5-turbo-0125.")
return num_tokens_from_messages(messages, model="gpt-3.5-turbo-0125")
elif "gpt-4o-mini" in model:
print("Warning: gpt-4o-mini may update over time. Returning num tokens assuming gpt-4o-mini-2024-07-18.")
return num_tokens_from_messages(messages, model="gpt-4o-mini-2024-07-18")
elif "gpt-4o" in model:
print("Warning: gpt-4o and gpt-4o-mini may update over time. Returning num tokens assuming gpt-4o-2024-08-06.")
return num_tokens_from_messages(messages, model="gpt-4o-2024-08-06")
elif "gpt-4" in model:
print("Warning: gpt-4 may update over time. Returning num tokens assuming gpt-4-0613.")
return num_tokens_from_messages(messages, model="gpt-4-0613")
else:
raise NotImplementedError(
f"""num_tokens_from_messages() is not implemented for model {model}."""
)
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
num_tokens += 3 # every reply is primed with <|start|>assistant<|message|>
return num_tokens
client = OpenAI(api_key=API_KEY, base_url=BASE_URL,http_client=proxy_client)
example_messages = [
{
"role": "system",
"content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English.",
},
{
"role": "system",
"name": "example_user",
"content": "New synergies will help drive top-line growth.",
},
{
"role": "system",
"name": "example_assistant",
"content": "Things working well together will increase revenue.",
},
{
"role": "system",
"name": "example_user",
"content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage.",
},
{
"role": "system",
"name": "example_assistant",
"content": "Let's talk later when we're less busy about how to do better.",
},
{
"role": "user",
"content": "This late pivot means we don't have time to boil the ocean for the client deliverable.",
},
]
for model in [
"gpt-3.5-turbo",
"gpt-4o",
"gpt-4o-mini"
]:
print(model)
print("1. Example token count from the function defined above ...")
print(f"{num_tokens_from_messages(example_messages, model)} prompt tokens counted by num_tokens_from_messages().")
print("2. Example token count from the OpenAI API...")
completion = client.chat.completions.create(
model=model,
messages=example_messages,
temperature=0,
max_tokens=1, # we're only counting input tokens here, so let's not waste tokens on the output
)
print(f'{completion.usage.prompt_tokens} prompt tokens counted by the OpenAI API.')
print()
输出结果:
gpt-3.5-turbo
1. Example token count from the function defined above ...
Warning: gpt-3.5-turbo may update over time. Returning num tokens assuming gpt-3.5-turbo-0125.
129 prompt tokens counted by num_tokens_from_messages().
2. Example token count from the OpenAI API...
129 prompt tokens counted by the OpenAI API.
gpt-4o
1. Example token count from the function defined above ...
Warning: gpt-4o and gpt-4o-mini may update over time. Returning num tokens assuming gpt-4o-2024-08-06.
124 prompt tokens counted by num_tokens_from_messages().
2. Example token count from the OpenAI API...
95 prompt tokens counted by the OpenAI API.
gpt-4o-mini
1. Example token count from the function defined above ...
Warning: gpt-4o-mini may update over time. Returning num tokens assuming gpt-4o-mini-2024-07-18.
124 prompt tokens counted by num_tokens_from_messages().
2. Example token count from the OpenAI API...
124 prompt tokens counted by the OpenAI API.
3.4 计算调用 chat completions with tool 的token数量
import os
import httpx
import tiktoken
from openai import OpenAI
API_KEY = os.getenv("API_KEY")
BASE_URL = "https://api.deepbricks.ai/v1/"
proxy_url = 'socks5://127.0.0.1:1080'
proxy_client = httpx.Client(proxies={
"http://": proxy_url,
"https://": proxy_url,
})
client = OpenAI(api_key=API_KEY, base_url=BASE_URL,http_client=proxy_client)
def num_tokens_from_messages(messages, model="gpt-4o-mini"):
"""Return the number of tokens used by a list of messages."""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
print("Warning: model not found. Using o200k_base encoding.")
encoding = tiktoken.get_encoding("o200k_base")
# 针对不同的模型设置token数量
if model in {
"gpt-3.5-turbo-0125",
"gpt-4-0314",
"gpt-4-32k-0314",
"gpt-4-0613",
"gpt-4-32k-0613",
"gpt-4o-mini-2024-07-18",
"gpt-4o-2024-08-06"
}:
tokens_per_message = 3
tokens_per_name = 1
elif "gpt-3.5-turbo" in model:
print("Warning: gpt-3.5-turbo may update over time. Returning num tokens assuming gpt-3.5-turbo-0125.")
return num_tokens_from_messages(messages, model="gpt-3.5-turbo-0125")
elif "gpt-4o-mini" in model:
print("Warning: gpt-4o-mini may update over time. Returning num tokens assuming gpt-4o-mini-2024-07-18.")
return num_tokens_from_messages(messages, model="gpt-4o-mini-2024-07-18")
elif "gpt-4o" in model:
print("Warning: gpt-4o and gpt-4o-mini may update over time. Returning num tokens assuming gpt-4o-2024-08-06.")
return num_tokens_from_messages(messages, model="gpt-4o-2024-08-06")
elif "gpt-4" in model:
print("Warning: gpt-4 may update over time. Returning num tokens assuming gpt-4-0613.")
return num_tokens_from_messages(messages, model="gpt-4-0613")
else:
raise NotImplementedError(
f"""num_tokens_from_messages() is not implemented for model {model}."""
)
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
num_tokens += 3 # every reply is primed with <|start|>assistant<|message|>
return num_tokens
def num_tokens_for_tools(functions, messages, model):
# Initialize function settings to 0
func_init = 0
prop_init = 0
prop_key = 0
enum_init = 0
enum_item = 0
func_end = 0
if model in [
"gpt-4o",
"gpt-4o-mini"
]:
# Set function settings for the above models
func_init = 7
prop_init = 3
prop_key = 3
enum_init = -3
enum_item = 3
func_end = 12
elif model in [
"gpt-3.5-turbo",
"gpt-4"
]:
# Set function settings for the above models
func_init = 10
prop_init = 3
prop_key = 3
enum_init = -3
enum_item = 3
func_end = 12
else:
raise NotImplementedError(
f"""num_tokens_for_tools() is not implemented for model {model}."""
)
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
print("Warning: model not found. Using o200k_base encoding.")
encoding = tiktoken.get_encoding("o200k_base")
func_token_count = 0
if len(functions) > 0:
for f in functions:
func_token_count += func_init # Add tokens for start of each function
function = f["function"]
f_name = function["name"]
f_desc = function["description"]
if f_desc.endswith("."):
f_desc = f_desc[:-1]
line = f_name + ":" + f_desc
func_token_count += len(encoding.encode(line)) # Add tokens for set name and description
if len(function["parameters"]["properties"]) > 0:
func_token_count += prop_init # Add tokens for start of each property
for key in list(function["parameters"]["properties"].keys()):
func_token_count += prop_key # Add tokens for each set property
p_name = key
p_type = function["parameters"]["properties"][key]["type"]
p_desc = function["parameters"]["properties"][key]["description"]
if "enum" in function["parameters"]["properties"][key].keys():
func_token_count += enum_init # Add tokens if property has enum list
for item in function["parameters"]["properties"][key]["enum"]:
func_token_count += enum_item
func_token_count += len(encoding.encode(item))
if p_desc.endswith("."):
p_desc = p_desc[:-1]
line = f"{p_name}:{p_type}:{p_desc}"
func_token_count += len(encoding.encode(line))
func_token_count += func_end
messages_token_count = num_tokens_from_messages(messages, model)
total_tokens = messages_token_count + func_token_count
return total_tokens
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string",
"description": "The unit of temperature to return",
"enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
}
}
]
example_messages = [
{
"role": "system",
"content": "You are a helpful assistant that can answer to questions about the weather.",
},
{
"role": "user",
"content": "What's the weather like in San Francisco?",
},
]
for model in [
"gpt-3.5-turbo",
"gpt-4o",
"gpt-4o-mini"
]:
print(model)
# example token count from the function defined above
print(f"{num_tokens_for_tools(tools, example_messages, model)} prompt tokens counted by num_tokens_for_tools().")
# example token count from the OpenAI API
response = client.chat.completions.create(model=model,
messages=example_messages,
tools=tools,
temperature=0)
print(f'{response.usage.prompt_tokens} prompt tokens counted by the OpenAI API.')
print()
输出结果:
gpt-3.5-turbo
Warning: gpt-3.5-turbo may update over time. Returning num tokens assuming gpt-3.5-turbo-0125.
105 prompt tokens counted by num_tokens_for_tools().
105 prompt tokens counted by the OpenAI API.
gpt-4o
Warning: gpt-4o and gpt-4o-mini may update over time. Returning num tokens assuming gpt-4o-2024-08-06.
101 prompt tokens counted by num_tokens_for_tools().
101 prompt tokens counted by the OpenAI API.
gpt-4o-mini
Warning: gpt-4o-mini may update over time. Returning num tokens assuming gpt-4o-mini-2024-07-18.
101 prompt tokens counted by num_tokens_for_tools().
101 prompt tokens counted by the OpenAI API.