作者简介
HeoiJin:立志透过数据看清世界的产品策划,专注爬虫、数据分析、产品策划领域。
万物皆营销 | 资本永不眠 | 数据恒真理
CSDN:https://me.csdn.net/weixin_40679090
目录
系列目录
二次元属性被稀释,B站还剩什么?
- 上篇—爬虫篇:爬取B站30日榜单(包括全站榜和各分区榜单)
- 下篇—对比分析及可视化篇:对爬取到的数据进行对比分析和可视化
- 番外篇—相关性分析篇:对用户行为,排行榜综合得分算法进行相关性分析
本篇目录
一、前言
二、项目特色
三、项目准备
四、问题定义
五、数据分析实战
六、本篇小结
一、前言
本篇章为《二次元属性被稀释,B站还剩什么?》系列篇的下篇。在上篇当中我们已经完成了数据的采集,那么本篇将着重对采集到的数据进行对比分析及可视化。
谈及B站变化情况,仅有我们采集到的2020年01月16日 - 2020年02月16日的排行榜数是不够的,因此本篇还将引用“DT财经”2019年发布的《数据解读 | 我们研究了B站,发现它很不“二次元”》中的数据进行对比分析。
PS:本文字数较多,阅读结论可直跳至本篇小结。
二、项目特色
- 利用pandas库对数据进行分类聚合
- 利用pyecharts和帆某的Bi软件对数据进行可视化实战
- 结合DT财经的数据对B站2019和2020的数据进行比较分析
可能会有小伙伴在这里就想吐槽了:这篇不是实战干货文章吗?为什么就用起了Bi软件呀,这没啥“技术含量”呀!
要回答这个问题,就不得不把我的愿景搬出来说一说:“透过数据看清世界”。所以看清世界是目标,是问题,数据是路径,是方法。写代码的目的不是写代码,而是要解决实际的问题。使用更简便的方法和工具解决问题,才是符合效益的事情。才不是因为我偷懒。
三、项目准备
- 语言:Python 3.7
- IDE : Pycharm
- 浏览器: Chrome
- 插件:ChromeDriver
- 库: Pandas、pyecahrts、snapshot_selenium
- 其他: Bi软件
四、问题定义
4.1 关键词定义
在进行分析前,要先确认什么是二次元和三次元,具体通过什么标准进行划分。
根据萌娘百科的解析,「二次元」一词来自于日语「二次元(にじげん)」,本义为「二维」,引申为「在纸面、屏幕等平面上展示的动画、游戏等作品中角色」。「三次元(さんじげん)」也被引申用来指现实中的人物1
而维基百科对次元的分层则为:
二次元:动画(Animations即ACG的A)、漫画(Comics即ACG的C)、游戏(Games即ACG的G)。
三次元:现实世界。2
即在爬取的所有分区当中,可以明显归类为二/三次元的分区分别是:
二次元:动画、国创相关、游戏
三次元:科技、数码、生活、时尚、娱乐
其余的鬼畜、舞蹈、音乐、影视则因为兼备二次元和三次元的属性,定义为2.5次元滑稽
4.2 确立目标
完成对分区进行属性划分之后,就可以开始确立研究目标:
- 分析B站综合评分前100中,什么分区是占比最多,用户在不同分区的行为情况如何。
- 分析B站各分区情况,找出各分区的播放量情况及用户在各分区的行为情况
- 分析热门标签变化
- 针对B站变化,洞悉背后的行为和心理本质
5、数据分析实战
5.1 数据预清洗
在进入正式的分析之前,先来了解下抓取到的数据情况是怎么样,对数据结构有了解之后,才能更清晰更有逻辑地对数据进行做分类聚合。
import pandas as pd
df=pd.read_csv('bilibili.csv')
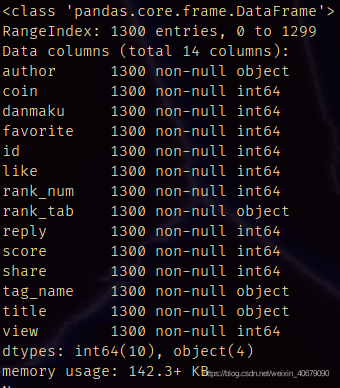
print(df.info())
通过数据的结果可以看到,采集到的一共有14列,1300行,没有缺失值。但要注意的是,rank_tab中有一个全站榜的数据,而全站榜又是由分区名列前茅的视频组成的,因此这里要先把全站榜排除在外,避免重复计算。
#波浪线~表示不选取该部分
df_without_all=df[~df['rank_tab'].isin(['全站'])]
这里通过布尔值判定将rank_tab中包含“全站”这个元素的整行排除,得到一个14列,1200行的dataframe,命名为df_without_all,后续将多次提及该dataframe。简单一步,完成预清洗。
这里各位可能会有个疑问,既然不需要全站榜的数据,那么在编写爬虫的时候,就把全站榜的url剔除就好了。
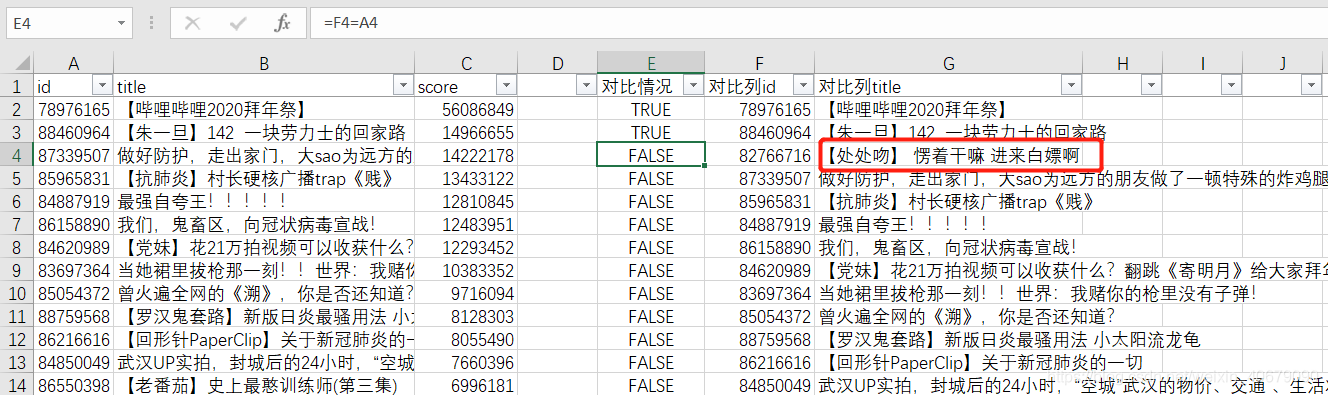
这里其实有个小彩蛋,通过综合评分的前100与全站榜的前100对比发现,全站榜的排名并不是完全按综合评分来计算的。
从对比情况列的布尔值可以看出,第三名开始左右两边的id就不相等了,查看回《【处处吻】…》的综合评分,明显高于全站榜排行第三的《做好防护…》。
看来全站榜这种兵家必争的流量入口还是有套路在的呀
扯远了,回到数据分析的实战,下面将展示实战的解析与现象的分析环节。

5.2全站综合评分top100系列
5.2.1各分区占比情况可视化
数据处理步骤:
- 对预处理好的df_without_all按照综合评分进行降序排序
- 对DataFrame进行切片处理,获取前100项
- 获取分区名列(columns=‘rank_tab’)
- 统计每个分区出现的次数
- 返回处理好的数据
def count_genre_top100(df):
genres_rank_Series=df.sort_values(by='score',ascending=False)[:100]['rank_tab']
#使用value_counts()方法快速求出各分区出现的次数
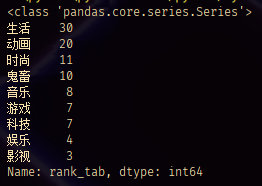
geners_rank_count=genres_rank_Series.value_counts()
print(type(geners_rank_count))
print(geners_rank_count)
return geners_rank_count
#执行count_genre_top100方法
count_genre=count_genre_top100(df_without_all)
.value_counts()方法的详细思路会放到热门标签环节讲解。通过.value_counts()方法,得到一个index为分区名,values为频次的Series类型。
接下来就是对这个数据进行可视化处理。在这了使用pyecahrts的玫瑰图。相比于Excel或者帆某的Bi软件,pyecahrts的玫瑰图制作非常友好,而且颜值方面也不错。
def pie_rosrtype(df):
c=(
Pie()
.add(
'',
#添加数据,数据类型结构:[['生活', 30], ['动画', 20]]
[list(z) for z in zip(df.index,df)],
radius=['30%','75%'],
center=['50%','50%'],
rosetype="radius",
)
.set_global_opts(title_opts=opts.TitleOpts(title='top100分类占比'))
#设置标签,展现形式为 标签:数值
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c}"))
)
return c
pie=pie_rosrtype(count_genre)
pie