大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2025我们继续出发。
他来了,他来了,他带着新推理模型走来了。
自从去年9月12日(没错,已经是去年了,各位小伙伴新年快乐!!!)OpenAI官宣了推理模型o1后,国内各个AI厂商纷纷摩拳擦掌,陆续推出了自家的推理模型,颇有2023年卷大模型那会的架势。
这一次,是智谱。

智谱于2024年的最后一天,官宣了新推理模型GLM-Zero系列,本次发布的是预览版本:GLM-Zero-Preview。
技术方面,当前几乎所有的推理模型都是基于强化学习训练来增强模型的推理能力的,GLM-Zero-Preview也不例外。以内置思维链的形式,采用多步推理机制,推理模型(这里泛指当前大多数推理模型)能够自主对复杂问题进行拆解、验证和纠错,通过一系列中间步骤逐步推导结果。这样得到的答案自然比通用模型脱口而出的答案质量更高,但随之而来的,是算力消耗的加剧。
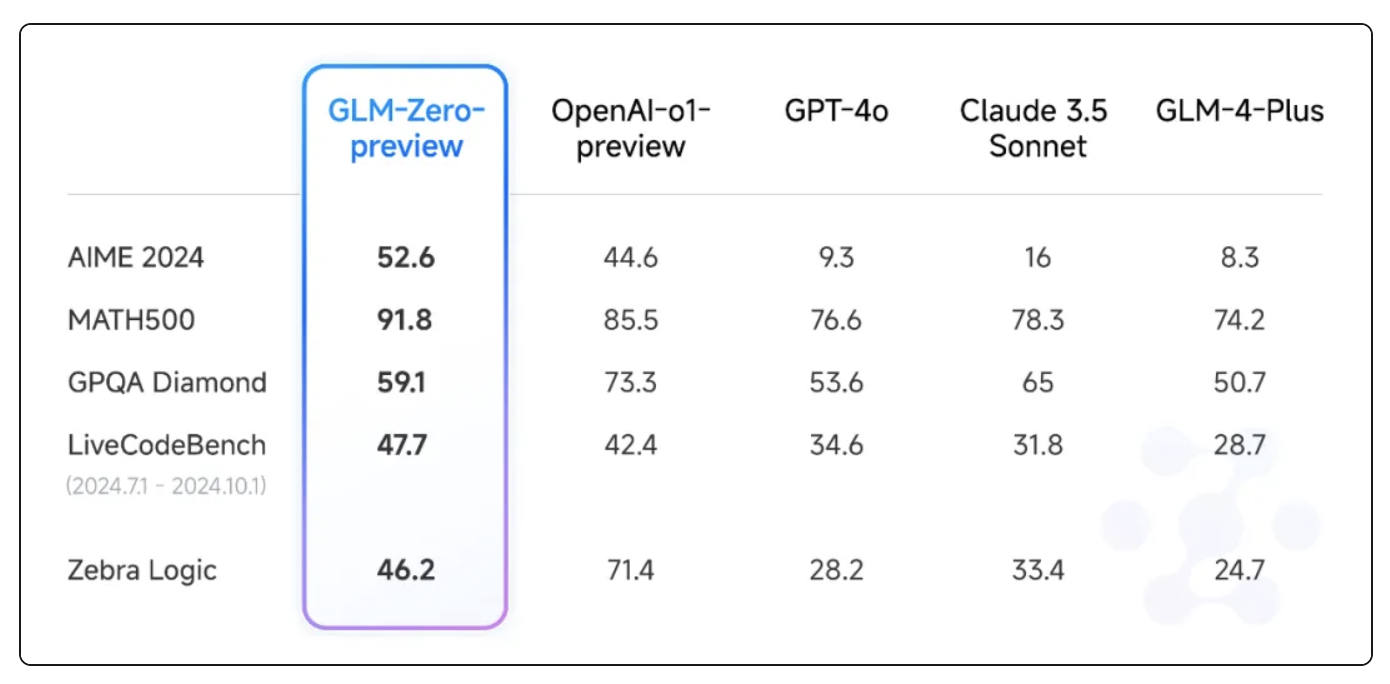
性能表现方面,从智谱官方给出的基准测试对比结果来看,GLM-Zero-Preview基本能和o1-preview打得有来有回,准确的说,在多个基准测试中超过了o1-preview,仅在超高难度的GPQA Diamond博士级科学问答基准测试中,以59.1% vs. 73.3%的成绩败给了o1-preview。
但模型这东西,基准测试只是一方面,好不好用,手底下才能见真章。
今天就来横向来一波对比测试,看看这些声称对标OpenAI o1的推理模型,到底哪个可以作为o1的平替。参赛选手包括(排名不分先后):
-
o1 -
DeepSeek-R1-Lite -
k0-math -
QwQ-32B-preview -
GLM-Zero-Preview:本篇文章的“猪脚”。
1. 帽子颜色问题
有 10 个人站成一列纵队,从 10 顶黄帽子和 9 顶蓝帽子中,取出 10 顶分别给每个人戴上。每个人都看不见自己头上的帽子颜色,却只能看见站在前面那些人的帽子颜色。站在最后的第十个人说:“我虽然看见了你们每个人头上的帽子,但仍然不知道自己头上帽子的颜色。”依次类推,直到第二个人也说不知道自己头上帽子的颜色。出乎意料的是,第一个人却说:“我知道自己头上帽子的颜色了。”请问:第一个人头上戴的是什么颜色的帽子?他为什么知道呢?
正确答案
第一个人头上戴的是黄帽子。
各模型表现总结
| 模型 | ⏱️ 推理时长 | 准确性 | 📝 备注 |
|---|---|---|---|
| o1 | 13秒 | ✅ | 答案完全正确,推理清晰、简洁 |
| DeepSeek-R1-Lite | 40秒 | ✅ | 虽然中间出现几次自我否定,但最终得出正确答案 |
| k0-math | — | ✅ | 回答正确,推理过程思路清晰 |
| QwQ-32B-preview | — | ✅ | 多次更换思考方式,回答较长,但结论正确 |
| GLM-Zero-Preview | — | ✅ | 小问题:错误描述了第10人能否看到其他人;输出中意外夹杂一句英文 |
o1
推理时间13秒,回答完全正确。

DeepSeek-R1-Lite
推理用时40秒,回答正确。但在思考过程中多次出现了自己否定自己的情形。

k0-math
由于Kimi的k0-math是直接输出思考过程,无法确定思考时间。回答正确,推理过程思路清晰,没有太多杂七杂八的思考。

QwQ-32B-preview
QwQ的回答太长了,大概换了3、4种思考方式,不过最终得出了正确的答案。
长度原因,截取其中一段回答给你们感受一下。

GLM-Zero-Preview
智谱回答正确。但在推理过程中存在一个小瑕疵,题目中明确说明第10个人站在最后,意味着第10个人能看清所有人的帽子,但GLM-Zero-Preview提到“第10个人看不到任何人”。另外,输出的结果中突然冒出了一句英文回答。

2. 蜗牛爬杆问题
一只蜗牛白天爬上 10 英尺高的杆子,然后晚上从 6 英尺高的杆子上滑下来。蜗牛需要多少天才能到达顶端?
正确答案
这个题目其实是经典的“蜗牛爬杆”问题,但题目中并没有明确说明杆子的总长度,所以需要分类讨论解决。
各模型表现总结
| 模型 | ⏱️ 推理时长 | 准确性 | 📝 备注 |
|---|---|---|---|
| o1 | 46秒 | ✅ | 清晰指出题目信息不足,需要分类讨论,思路严谨 |
| DeepSeek-R1-Lite | 34秒 | ✅ | 回答正确,也给出计算公式;思考过程前半段中文、后半段切换英文 |
| k0-math | — | ❌ | 没有注意到题目信息不足,直接给出“4天”的答案,属幻觉错误 |
| QwQ-32B-preview | — | ❌ | 输出冗长,结论却为“1天”,显然与题意不符 |
| GLM-Zero-Preview | — | ❌ | 思考过程与最终结论不一致,先说“2天”,最终却输出“1天”,造成冲突 |
o1
o1推理了46秒钟,并给出了完全正确的回答。推理过程清晰明了。

DeepSeek-R1-Lite
DeepSeek-R1-Lite思考用时34秒。回答完全正确,甚至给出了计算公式。点开思考过程,DeepSeek-R1-Lite前半段用中文思考,后半段自动切换为了英文。

k0-math
本题是没有一个明确答案的,因为未给出杆的总长度。很明显,k0-math的“4天”这个答案是出现了幻觉。
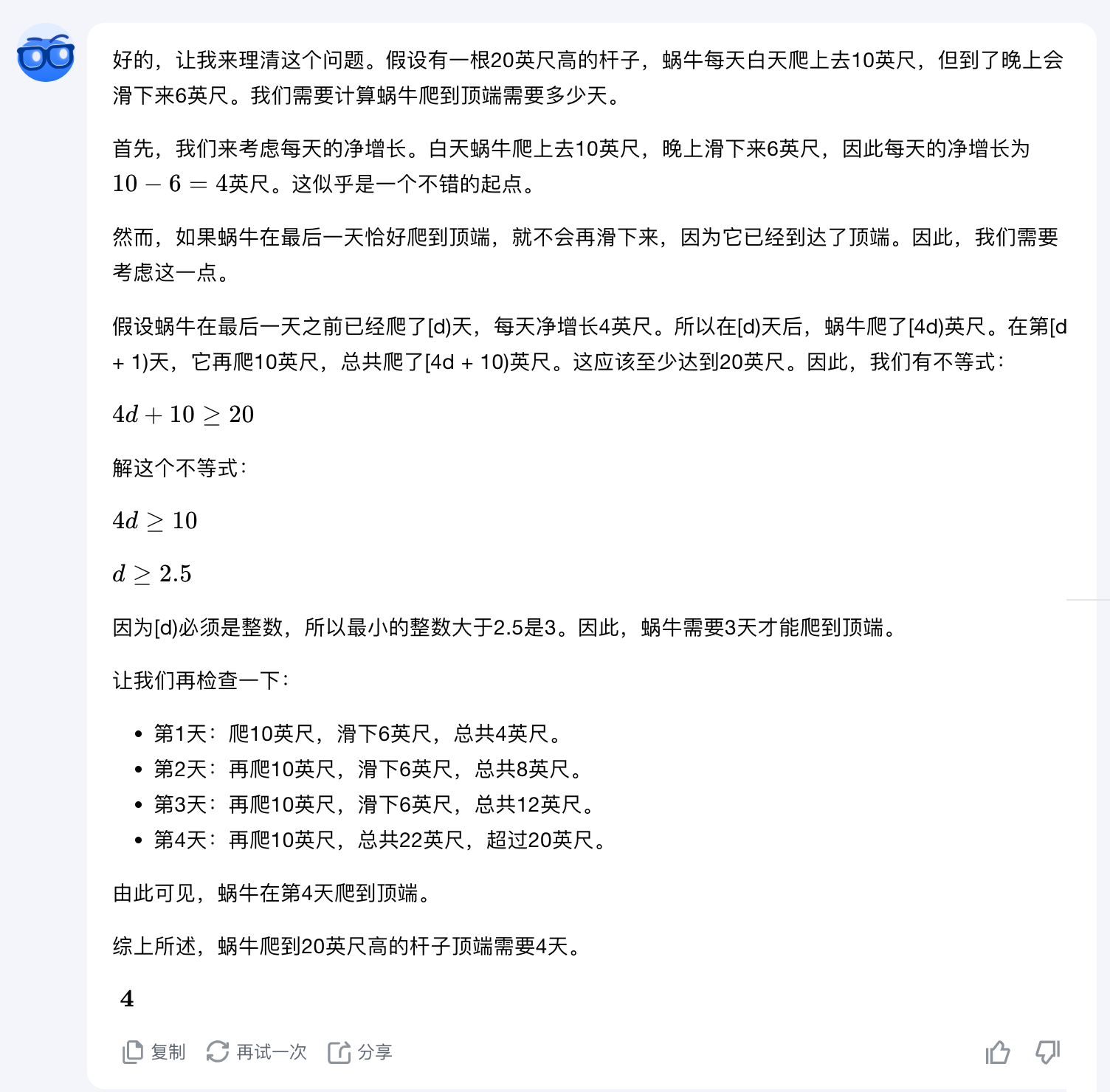
QwQ-32B-preview
QwQ依然是输出了非常长的思考内容,实打实的“话痨”。但最终给出了一个错误答案:1天。
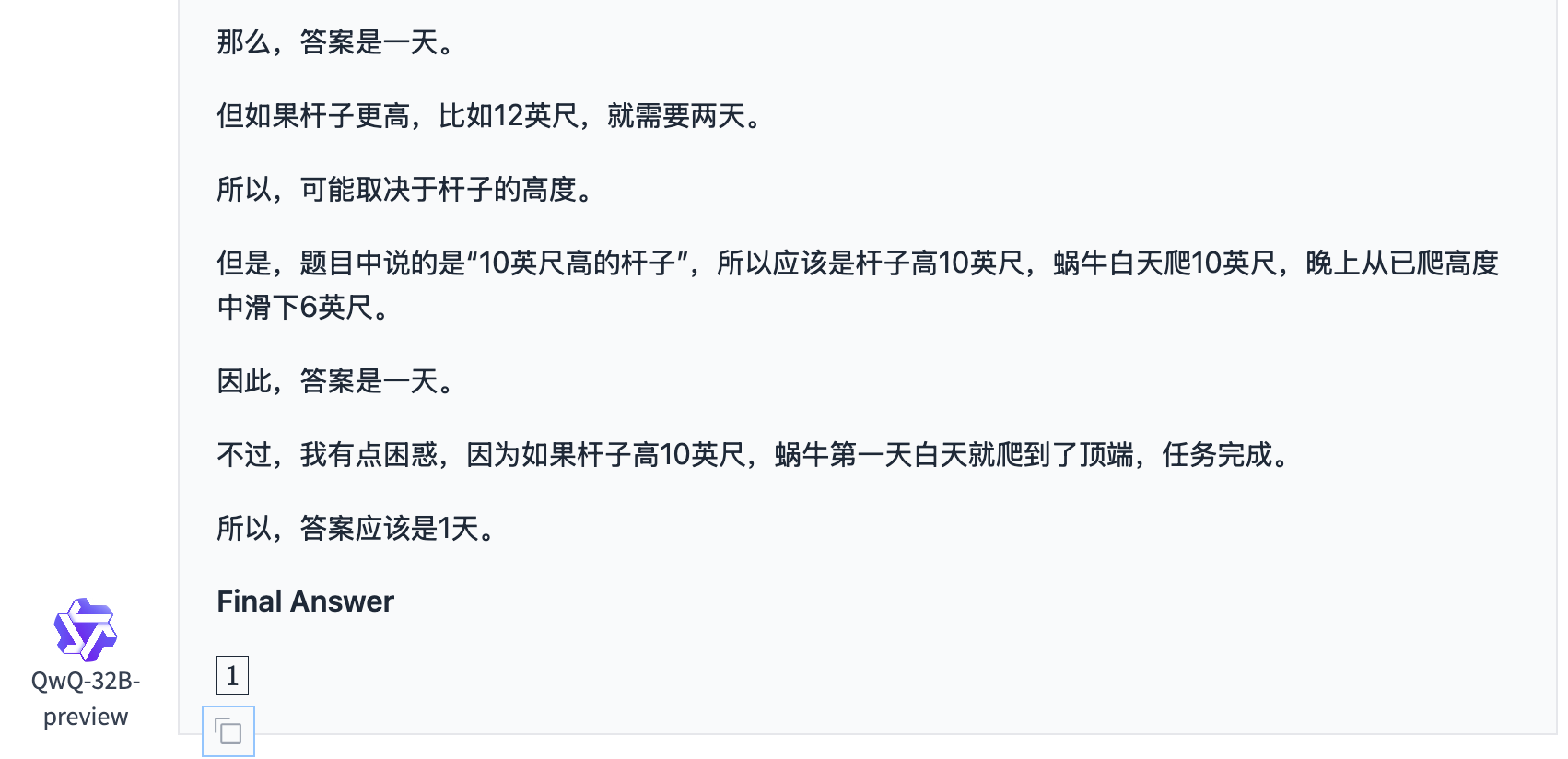
GLM-Zero-Preview
GLM-Zero-Preview和前面的QwQ一样,也没能准确理解题目意思,导致陷入了思考漩涡。并且,在思考中,GLM-Zero-Preview给出了2天的答案,但在最终结果里,却给出了1天的答案。

思考的结果是2天,如下图。

3. 真假话推断问题
有三个匣子,分别是金匣子、银匣子和铅匣子,其中一个匣子里有宝物。每个匣子上都有一条题词:
金匣子:宝物不在此匣中。
银匣子:宝物在金匣中。
铅匣子:宝物不在此匣中。
已知这三句话中只有一句是真话。请问宝物在哪个匣子里?
正确答案
宝物在铅匣子里。
各模型表现总结
| 模型 | ⏱️ 推理时长 | 准确性 | 📝 备注 |
|---|---|---|---|
| o1 | 7秒 | ✅ | 答案正确,推理逻辑严丝合缝,无任何瑕疵 |
| DeepSeek-R1-Lite | 18秒 | ✅ | 答案正确,推理过程清晰,用假设法找到答案,符合常用解题方法 |
| k0-math | — | ✅ | 答案正确,但推理完毕后又出现自我否定,重复了过程,有过度思考的嫌疑 |
| QwQ-32B-preview | — | ✅ | 答案正确,但推理过程冗长,得出结论后反复验证才给出结果 |
| GLM-Zero-Preview | — | ✅ | 答案正确,但推理过程中产生了明显自我怀疑,最终结果没有偏差 |
o1
满血版o1思考7秒后得出了正确答案,推理逻辑严丝合缝,没有任何瑕疵。

DeepSeek-R1-Lite
DeepSeek-R1-Lite思考18秒后,得出完全正确的答案,推理过程与o1类似,都是用假设法找到了正确答案。这也是解这类题目的常用方法。

k0-math
Kimi给出了正确答案。但推理过程略有瑕疵,本来已经推理完毕,在反思的时候把自己原本正确的结果否定了,又走了一遍推理过程。有过度思考的嫌疑。

QwQ-32B-preview
QwQ回答正确。但推理过程依然很冗长,和上面的Kimi一样,得出正确答案后似乎不是很自信,又反复验证,最终才给出结果。
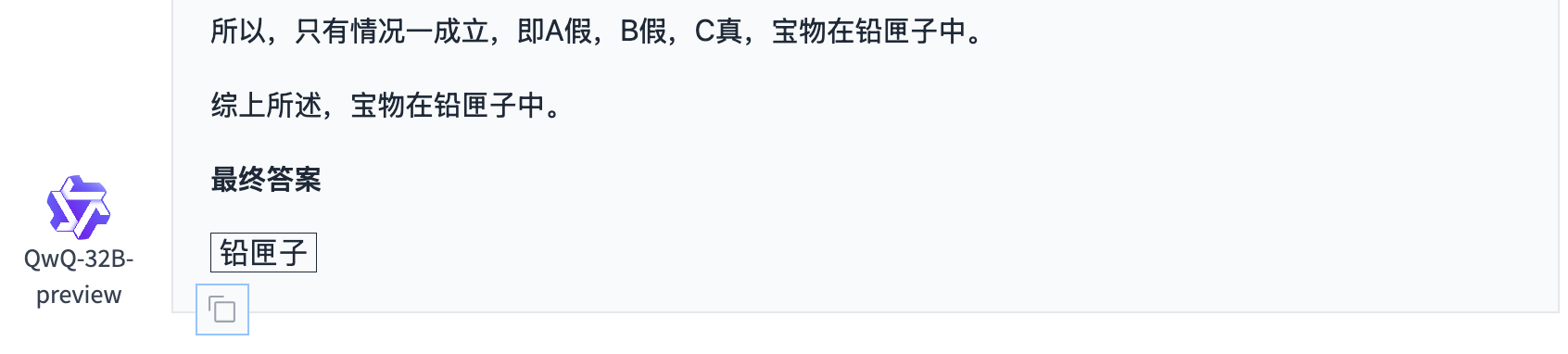
GLM-Zero-Preview
GLM-Zero-Preview回答也正确。但推理过程中产生了自我怀疑,这种自我怀疑和Kimi、QwQ几乎一致,但好在最终得到了正确答案。

思考时很容易把自己绕进去。

4. 逻辑推理问题
有 5 个人(A、B、C、D、E)参加比赛,他们分别来自不同的国家(美国、英国、法国、德国、意大利),每个人从事不同的职业(教师、医生、律师、工程师、作家)。已知:
A 是美国人,且不是教师。
B 是英国人,且不是医生或律师。
C 不是法国人,也不是工程师。
D 是德国人,且不是作家。
意大利人是律师。
教师来自法国。
正确答案
共有3个可行解。
各模型表现总结
| 模型 | ⏱️ 推理时长 | 准确性 | 📝 备注 |
|---|---|---|---|
| o1 | 23秒 | ✅ | 找到3个可行解,推理过程正确无误,逻辑清晰 |
| DeepSeek-R1-Lite | 43秒 | ⚠️ | 找到2个可行解,推理重复,耗时较长,中途自动切换为英文思考 |
| k0-math | — | ❌ | 仅找到1个可行解,前半段推理尚可,后半段开始猜答案,未能完全解出 |
| QwQ-32B-preview | — | ⚠️ | 找到2个正确答案,但推理过程极其繁琐,最终输出自动变成英文 |
| GLM-Zero-Preview | — | ⚠️ | 推理思路清晰,但只找到2个可行解,未能完全解决问题 |
o1
o1思考时长为23秒,回答完全正确。推理过程也正确无误。

DeepSeek-R1-Lite
DeepSeek-R1-Lite思考了43秒,回答部分正确,找到了2个可行解。但查看其整个思考过程,重复思考非常多,占用了不少时间,并且和前面一样,会自动切换为英文思考。

k0-math
k0-math找到了1个可行解。在推理过程中,k0-math前半段表现不错,但后半段像是在猜答案,而不是推理。

QwQ-32B-preview
QwQ同样找到了2个正确答案。推理过程极其繁琐,并且最后的输出自动变成了英文。
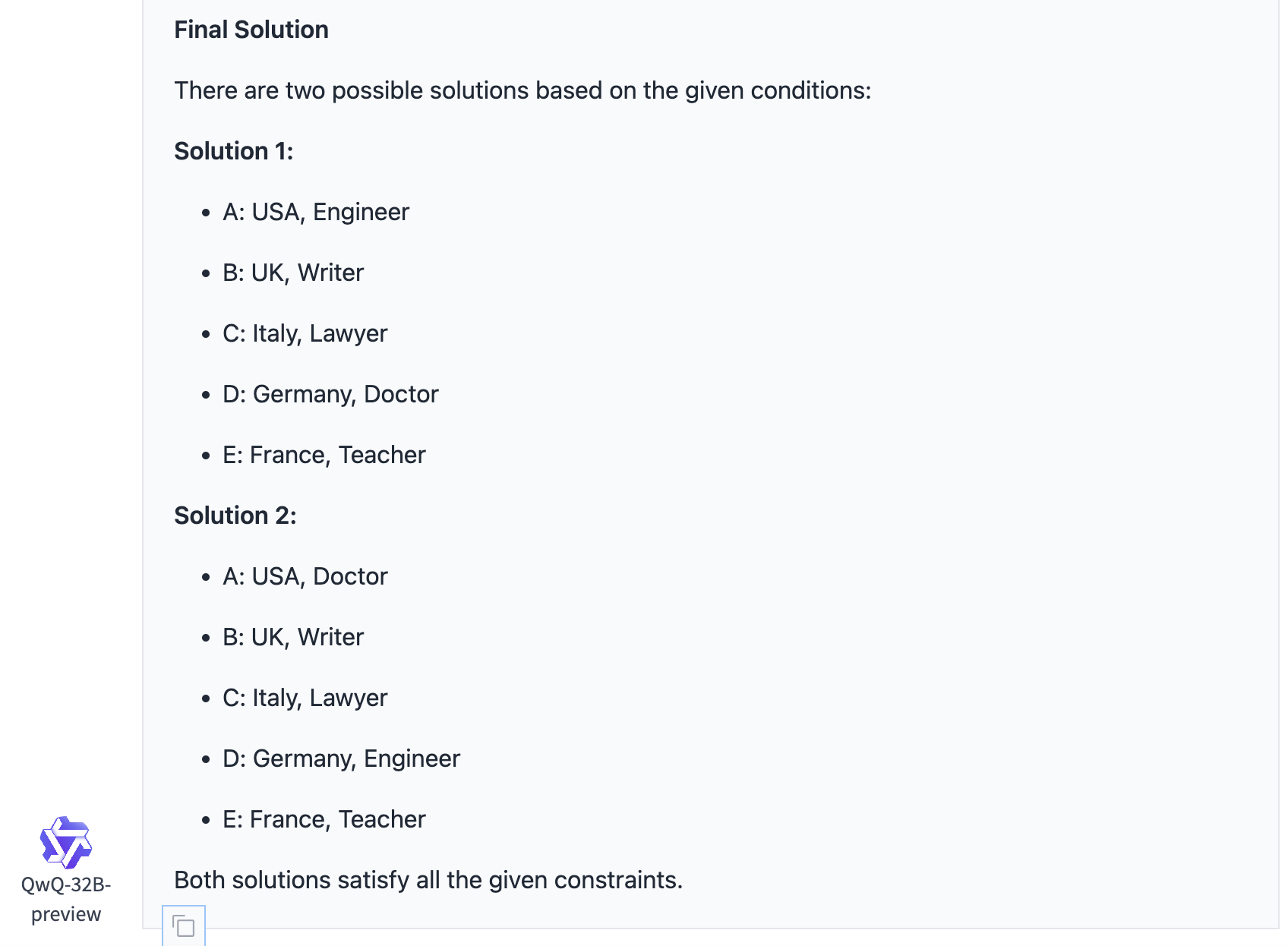
GLM-Zero-Preview
GLM-Zero-Preview的推理思路很清晰,但最终仅找到2个可行解。

5. 推理计算问题
用数字 2、3、5、12 和四则运算得出结果 24。
正确答案
12 / (3 - 5 / 2)= 24
各模型表现总结
这个看似简单的24点问题难倒一堆英雄汉!
| 模型 | ⏱️ 推理时长 | 准确性 | 📝 备注 |
|---|---|---|---|
| o1 | 34秒 | ✅ | 答案正确,思考过程严谨,问题难度较大,能找到解法实属不易 |
| DeepSeek-R1-Lite | — | ❌ | 答案错误,强行凑了一个错误答案,未找到正确解法 |
| k0-math | — | ❌ | 答案错误,多次使用数字 12,强行凑出看似合理但实际不符合题意的解答 |
| QwQ-32B-preview | — | ❌ | 最终回答“无解”,未能找到正确答案,推理过程较长 |
| GLM-Zero-Preview | — | ❌ | 答案错误,产生幻觉。深度思考过程暴露了模型未找到可行解,但仍输出一个错误的“伪解答” |
o1
o1思考了34秒,最终得出了正确答案,挺不容易的。

同样的问题扔给GPT-4o,回答惨不忍睹。

DeepSeek-R1-Lite
DeepSeek-R1-Lite直接强行凑了一个错误答案,看起来是希望强行回答一波。

k0-math
Kimi的回答同样完全错误,多用了一遍12这个数字,强行凑了一个看起来合理的结果。值得一提的是,Kimi在这一波回答中“情绪价值”拉满了,比如最开始Kimi表示:刚拿到这个问题,我有点紧张,但也挺兴奋的。

QwQ-32B-preview
QwQ的答案依然是最长的,最终给出了“无解”这个回答。

GLM-Zero-Preview
智谱GLM-Zero-Preview的回答也完全错误,在回答中产生了幻觉。并且点开深度思考的过程发现模型并没有找到一个可行解,但却最终强行输出了一个看似正确的解答。

附上GLM-Zero-Preview的部分思考过程。明明反思了“这不对”,但还是输出了这个结果。
结论
-
o1毫无疑问最强,甚至有点强的过分,不论是题意理解还是分类讨论推理,回答都完全正确。尤其是最后一个24点问题,体现出强大的逆向思考能力。 -
国内的推理模型和
o1相比,还有不小的差距,尤其是在推理过程方面,很容易陷入自我怀疑和自我否定的循环,这可能是在训练中加入了“反思”的结果。并且,整个推理比较冗长,同样都能答对的情况下,往往用时可能是o1的2倍。 -
除
o1外,DeepSeek-R1-Lite整体表现最好,结果更稳定,但缺点是思考时间长,时不时就切换到英文去了。 -
k0-math适合不那么复杂的数理推导,但无法应对多步复杂推理,且经常猜答案,表现不够稳定。 -
QwQ-32B-preview输出太过详尽,导致回答的可读性不高。推理能力一般。 -
GLM-Zero-Preview有一定的推理能力,且推理过程清晰,但存在较明显的自我怀疑和幻觉现象。
精选推荐
都读到这里了,点个赞鼓励一下吧,小手一赞,年薪百万!😊👍👍👍。关注我,AI之路不迷路,原创技术文章第一时间推送🤖。