北京智源人工智能研究院联合上海交通大学、中国人民大学、北京大学和北京邮电大学等高校推出了一款名为Video-XL的超长视频理解大模型。这款模型是多模态大模型核心能力的重要展示,也是向通用人工智能(AGI)迈进的关键步骤。与现有多模态大模型相比,Video-XL在处理超过10分钟的长视频时,展现了更优的性能和效率。
Video-XL利用语言模型(LLM)的原生能力,对长视觉序列进行压缩,保留了短视频理解的能力,并在长视频理解上显示出了卓越的泛化能力。该模型在多个主流长视频理解基准评测的多项任务中均排名第一。Video-XL在效率与性能之间实现了良好平衡,仅需一块80G显存的显卡即可处理2048帧输入,对小时级长度视频进行采样,并在视频“海中捞针”任务中取得了接近95%的准确率。

Video-XL有望在电影摘要、视频异常检测、广告植入检测等应用场景中展现广泛的应用价值,成为长视频理解的得力助手。该模型的推出,标志着长视频理解技术在效率和准确性上迈出了重要一步,为未来长视频内容的自动化处理和分析提供了强有力的技术支持。
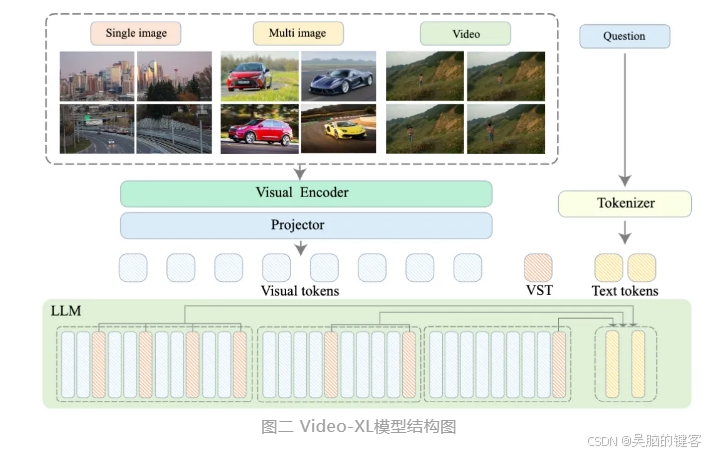
目前,Video-XL的模型代码已经开源,以促进全球多模态视频理解研究社区的合作和技术共享。
论文标题:Video-XL: Extra-Long Vision Language Model for Hour-Scale Video Understanding
论文链接:https://arxiv.org/abs/2409.14485
模型链接:https://huggingface.co/sy1998/Video_XL
项目链接:https://github.com/VectorSpaceLab/Video-XL