LRTV:Total-Variation-Regularized Low-Rank Matrix Factorization for Hyperspectral Image Restoration-2016
引言
HSI去噪方法:HSSNR、MWF、high-order rank-1 tensor decomposition等。
尽管TV正则化方法在图像处理方面表现良好,但在去除脉冲噪声方面仍面临一些问题。值得注意的是,TV正则化会对未被脉冲破坏的像素值产生负面影响。
最著名的传统低秩方法之一是主成分分析,它使用正交变换将高光谱图像转换成一组称为主成分的线性不相关变量。不幸的是,这种经典方法有两个主要缺点。一是对离群值(outliers)敏感;然而,HSI经常被异常值所污染,例如条纹、死线、脉冲噪声等。其次,它主要利用光谱波段之间的相关性,忽略了局部邻域像素的空间分段平滑性。RPCA模型解决了第一个问题。
TV Model For HSI Restoration
退化模型(省略加粗): Y = X + S + N Y=X+S+N Y=X+S+N, Y ∈ R M N × p Y\in\mathbb{R}^{MN\times p} Y∈RMN×p,三维情形: u = f + s + N u=f+s+\mathcal{N} u=f+s+N
MAP Restoration Model:HSI恢复模型可以描述为以下约束最小二乘问题 X ^ = arg min X ∈ R m × n { ∥ Y − X ∥ F 2 + τ R ( X ) } \hat{\mathbf{X}}=\underset{\mathbf{X} \in \mathbb{R}^{m \times n}}{\arg \min }\left\{\|\mathbf{Y}-\mathbf{X}\|_{F}^{2}+\tau R(\mathbf{X})\right\} X^=X∈Rm×nargmin{∥Y−X∥F2+τR(X)}
TV-Based HSI Restoration:对于尺寸为 M × N M×N M×N的灰度图像 x x x,各向异性TV范数定义如下 ∥ x ∥ T V = ∑ i = 1 M − 1 ∑ j = 1 N − 1 { ∣ x i , j − x i + 1 , j ∣ + ∣ x i , j − x i , j + 1 ∣ } + ∑ i = 1 M − 1 ∣ x i , N − x i + 1 , N ∣ + ∑ j = 1 N − 1 ∣ x M , j − x M , j + 1 ∣ \begin{aligned} \|x\|_{\mathrm{TV}}=& \sum_{i=1}^{M-1} \sum_{j=1}^{N-1}\left\{\left|x_{i, j}-x_{i+1, j}\right|+\left|x_{i, j}-x_{i, j+1}\right|\right\} \\ &+\sum_{i=1}^{M-1}\left|x_{i, N}-x_{i+1, N}\right|+\sum_{j=1}^{N-1}\left|x_{M, j}-x_{M, j+1}\right| \end{aligned} ∥x∥TV=i=1∑M−1j=1∑N−1{∣xi,j−xi+1,j∣+∣xi,j−xi,j+1∣}+i=1∑M−1∣xi,N−xi+1,N∣+j=1∑N−1∣xM,j−xM,j+1∣
简单的逐波段HSI TV标准定义如下 ∥ X ∥ H T V = ∑ j = 1 p ∥ F X j ∥ T V \|\mathbf{X}\|_{\mathrm{HTV}}=\sum_{j=1}^{p}\left\|\mathcal{F} \mathbf{X}_{j}\right\|_{\mathrm{TV}} ∥X∥HTV=j=1∑p∥FXj∥TV
其中 X j \mathbf{X}_{j} Xj表示HSI的第 j j j个波段向量, F : R M N → R M × N \mathcal{F}:\mathbb{R}^{MN}\rightarrow\mathbb{R}^{M\times N} F:RMN→RM×N,于是HSI恢复模型可以写成如下形式 X ^ = arg min X ∈ R m × n { ∥ Y − X ∥ F 2 + τ ∥ X ∥ H T V } \hat{\mathbf{X}}=\underset{\mathbf{X} \in \mathbb{R}^{m \times n}}{\arg \min }\left\{\|\mathbf{Y}-\mathbf{X}\|_{F}^{2}+\tau \|\mathbf{X}\|_{\mathrm{HTV}}\right\} X^=X∈Rm×nargmin{∥Y−X∥F2+τ∥X∥HTV}
对于一个HSI,它经常被混合噪声破坏,包括高斯噪声和稀疏噪声。在这种情况下,将数据保真度项强加于所有空间是不合适的。如果稀疏噪声候选集用 Ω \Omega Ω表示,则基于TV的HSI恢复模型可以重写如下 X ^ = arg min X ∈ R m × n { ∥ P Ω T ( Y − X ) ∥ F 2 + τ ∥ X ∥ H T V } \hat{\mathbf{X}}=\underset{\mathbf{X} \in \mathbb{R}^{m \times n}}{\arg \min }\left\{\|P_{\Omega^T}(\mathbf{Y}-\mathbf{X})\|_{F}^{2}+\tau \|\mathbf{X}\|_{\mathrm{HTV}}\right\} X^=X∈Rm×nargmin{∥PΩT(Y−X)∥F2+τ∥X∥HTV}
其中 Ω T \Omega^T ΩT为 Ω \Omega Ω的补空间, P Ω T P_{\Omega^T} PΩTis the orthogonal projector onto the span of the matrices vanishing in Ω \Omega Ω(没看懂).
如果稀疏噪声已知,则 X ^ = arg min X ∈ R m × n { ∥ Y − X − S ∥ F 2 + τ ∥ X ∥ H T V } \hat{\mathbf{X}}=\underset{\mathbf{X} \in \mathbb{R}^{m \times n}}{\arg \min }\left\{\|\mathbf{Y}-\mathbf{X}-\mathbf{S}\|_{F}^{2}+\tau \|\mathbf{X}\|_{\mathrm{HTV}}\right\} X^=X∈Rm×nargmin{∥Y−X−S∥F2+τ∥X∥HTV}
通过仔细选择正则化参数 τ \tau τ,上式转化为有约束的TV模型 X ^ = arg min X ∈ R m × n ∥ X ∥ H T V s.t. ∥ Y − X − S ∥ F 2 ≤ ε \hat{\mathbf{X}}=\underset{\mathbf{X} \in \mathbb{R}^{m \times n}}{\arg \min }\|\mathbf{X}\|_{\mathrm{HTV}} \text { s.t. }\|\mathbf{Y}-\mathbf{X}-\mathbf{S}\|_{F}^{2} \leq \varepsilon X^=X∈Rm×nargmin∥X∥HTV s.t. ∥Y−X−S∥F2≤ε
其中 ε ε ε代表高斯噪声的噪声水平。
LRTV For HSI Restoration
左上角是否反了?因为
X
∈
R
M
N
×
p
X\in\mathbb{R}^{MN\times p}
X∈RMN×p.
Low-Rank Matrix Factorization-Based HSI Restoration
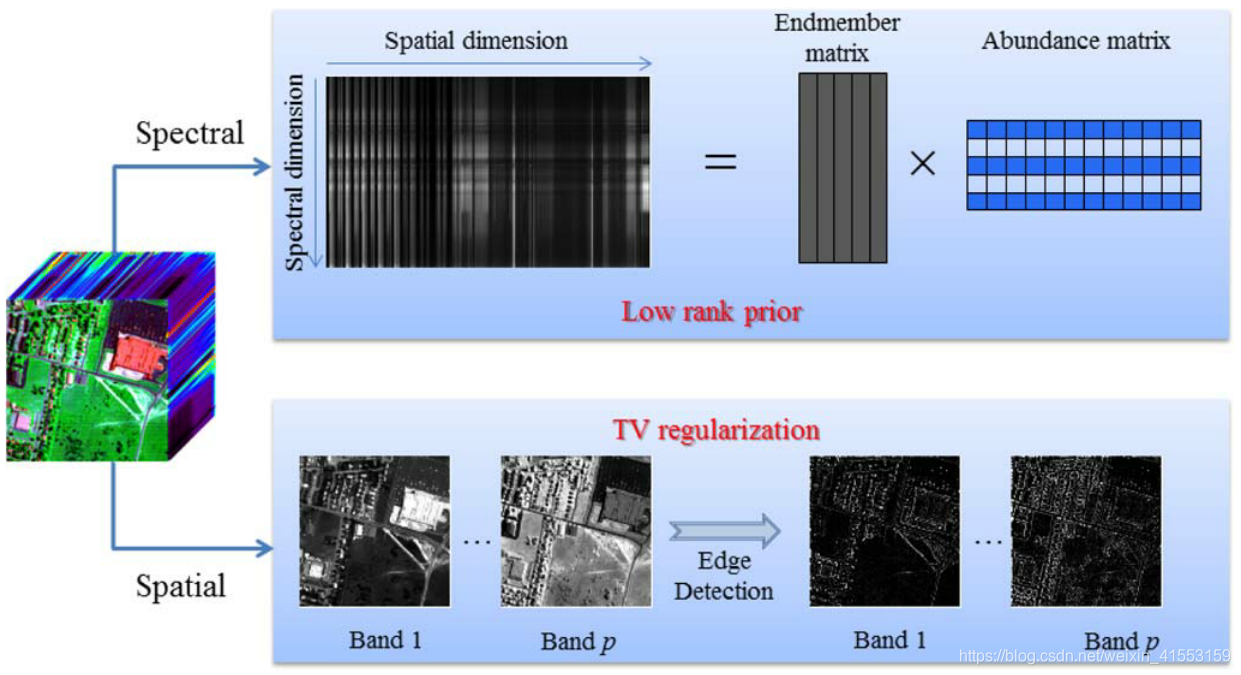
从线性光谱混合模型的角度来看,每个光谱特征(X的行)可以由少量纯光谱端元的线性组合来表示,这启发我们使用低秩矩阵分解来对HSI降级建模 Y = U V + S + N Y=UV+S+N Y=UV+S+N其中 U ∈ R m × r U\in\mathbb{R}^{m\times r} U∈Rm×r为端元矩阵或字典, V ∈ R r × n V\in\mathbb{R}^{r\times n} V∈Rr×n为abundance或系数矩阵, U V UV UV为原始干净图像的低秩矩阵分解, r r r为端元(endmembers)的个数。
在低秩矩阵分解模型中,我们假设 U U U是一个随机字典。矩阵 V V V的系数值也假设是随机分布的。这些假设已被概率矩阵分解和贝叶斯RPCA采纳。
我们假设 U U U和 V V V的每个元素从高斯分布采样,稀疏误差S从拉普拉斯分布采样,噪声G服从高斯分布。从概率的角度来看,我们有以下几点 U i j ∼ N ( 0 , λ u − 1 ) V i j ∼ N ( 0 , λ v − 1 ) S i j ∼ L ( 0 , λ s − 1 ) G i j ∼ N ( 0 , λ g − 1 ) \begin{aligned} \mathbf{U}_{i j} & \sim \mathcal{N}\left(0, \lambda_{u}^{-1}\right) \\ \mathbf{V}_{i j} & \sim \mathcal{N}\left(0, \lambda_{v}^{-1}\right) \\ \mathbf{S}_{i j} & \sim \mathcal{L}\left(0, \lambda_{s}^{-1}\right) \\ \mathbf{G}_{i j} & \sim \mathcal{N}\left(0, \lambda_{g}^{-1}\right) \end{aligned} UijVijSijGij∼N(0,λu−1)∼N(0,λv−1)∼L(0,λs−1)∼N(0,λg−1)
通过将
U
,
V
,
S
U,V,S
U,V,S视为模型参数,
λ
u
,
λ
v
,
λ
s
,
λ
g
\lambda_u,\lambda_v,\lambda_s,\lambda_g
λu,λv,λs,λg为具有固定值的超参数,我们使用贝叶斯估计去寻找
U
,
V
,
S
U,V,S
U,V,S. 根据贝叶斯法则,我们有以下MAP公式(后3个正比式可由https://zhuanlan.zhihu.com/p/75380549推得,第一个正比式不知道怎么推)
p
(
U
,
V
,
S
∣
Y
,
λ
u
,
λ
v
,
λ
s
,
λ
g
)
∝
p
(
Y
∣
U
,
V
,
S
,
λ
g
)
p
(
U
∣
λ
u
)
p
(
V
∣
λ
v
)
p
(
S
∣
λ
s
)
.
p\left(\mathbf{U}, \mathbf{V}, \mathbf{S} \mid \mathbf{Y}, \lambda_{u}, \lambda_{v}, \lambda_{s}, \lambda_{g}\right) \\ \propto p\left(\mathbf{Y} \mid \mathbf{U}, \mathbf{V}, \mathbf{S}, \lambda_{g}\right) p\left(\mathbf{U} \mid \lambda_{u}\right) p\left(\mathbf{V} \mid \lambda_{v}\right) p\left(\mathbf{S} \mid \lambda_{s}\right) .
p(U,V,S∣Y,λu,λv,λs,λg)∝p(Y∣U,V,S,λg)p(U∣λu)p(V∣λv)p(S∣λs).
因此(没看懂) log p ( U , V , S ∣ Y , λ u , λ v , λ s , λ g ) = − λ g 2 ∥ Y − U V − S ∥ F 2 − λ s ∥ S ∥ 1 − λ u 2 ∥ U ∥ F 2 − λ v 2 ∥ V ∥ F 2 − C \log p\left(\mathbf{U}, \mathbf{V}, \mathbf{S} \mid \mathbf{Y}, \lambda_{u}, \lambda_{v}, \lambda_{s}, \lambda_{g}\right)=-\frac{\lambda_{g}}{2}\|\mathbf{Y}-\mathbf{U V}-\mathbf{S}\|_{F}^{2}\\ -\lambda_{s}\|\mathbf{S}\|_{1}-\frac{\lambda_{u}}{2}\|\mathbf{U}\|_{F}^{2}-\frac{\lambda_{v}}{2}\|\mathbf{V}\|_{F}^{2}-C logp(U,V,S∣Y,λu,λv,λs,λg)=−2λg∥Y−UV−S∥F2−λs∥S∥1−2λu∥U∥F2−2λv∥V∥F2−C
其中 C C C为独立于 U , V , S U,V,S U,V,S的常数项,令 λ = λ s / λ g \lambda=\lambda_s/\lambda_g λ=λs/λg, λ u ′ = λ u / λ g \lambda_u'=\lambda_u/\lambda_g λu′=λu/λg, λ v ′ = λ v / λ g \lambda_v'=\lambda_v/\lambda_g λv′=λv/λg,则MAP相当于下面的恢复模型 min U , V , S 1 2 ∥ Y − U V − S ∥ F 2 + λ ∥ S ∥ 1 + λ u ′ 2 ∥ U ∥ F 2 + λ v ′ 2 ∥ V ∥ F 2 ( 1 ) \min _{\mathbf{U}, \mathbf{V}, \mathbf{S}} \frac{1}{2}\|\mathbf{Y}-\mathbf{U V}-\mathbf{S}\|_{F}^{2}+\lambda\|\mathbf{S}\|_{1}+\frac{\lambda_{u}^{\prime}}{2}\|\mathbf{U}\|_{F}^{2}+\frac{\lambda_{v}^{\prime}}{2}\|\mathbf{V}\|_{F}^{2}\quad(1) U,V,Smin21∥Y−UV−S∥F2+λ∥S∥1+2λu′∥U∥F2+2λv′∥V∥F2(1)
然后,我们可以进一步简化低秩矩阵分解模型(1),并在特定条件下推导秩约束的RPCA模型。
引理1:对于任意的矩阵 X ∈ R m × n X\in\mathbb{R}^{m\times n} X∈Rm×n,有 ∥ X ∥ ∗ = min U , V , X = U V 1 2 ( ∥ U ∥ F 2 + ∥ V ∥ F 2 ) \|\mathbf{X}\|_{*}=\min _{\mathbf{U}, \mathbf{V}, \mathbf{X}=\mathbf{U} \mathbf{V}} \frac{1}{2}\left(\|\mathbf{U}\|_{F}^{2}+\|\mathbf{V}\|_{F}^{2}\right) ∥X∥∗=U,V,X=UVmin21(∥U∥F2+∥V∥F2)如果 r a n k ( X ) = r ≤ m i n { m , n } rank(X)=r\leq min\{m,n\} rank(X)=r≤min{m,n},那么上述最小值在因子(factor)分解 X = U V X=UV X=UV时获得,其中 U ∈ R m × r U\in\mathbb{R}^{m\times r} U∈Rm×r, V ∈ R r × n V\in\mathbb{R}^{r\times n} V∈Rr×n.
假设 λ u ′ = λ v ′ = λ 2 \lambda_u'=\lambda_v'=\lambda_2 λu′=λv′=λ2,且秩的上界为 r r r,于是由引理1可知 min U , V , S 1 2 ∥ Y − U V − S ∥ F 2 + λ ∥ S ∥ 1 + λ 2 2 ∥ U ∥ F 2 + λ 2 2 ∥ V ∥ F 2 = min U , V , S 1 2 ∥ Y − U V − S ∥ F 2 + λ ∥ S ∥ 1 + λ 2 ( ∥ U V ∥ ∗ ) = min X , S , rank ( X ) ≤ r 1 2 ∥ Y − X − S ∥ F 2 + λ ∥ S ∥ 1 + λ 2 ( ∥ X ∥ ∗ ) . \begin{aligned} \min _{\mathbf{U}, \mathbf{V}, \mathbf{S}} &\frac{1}{2}\|\mathbf{Y}-\mathbf{U V}-\mathbf{S}\|_{F}^{2}+\lambda\|\mathbf{S}\|_{1}+\frac{\lambda_{2}}{2}\|\mathbf{U}\|_{F}^{2}+\frac{\lambda_{2}}{2}\|\mathbf{V}\|_{F}^{2} \\ &=\min _{\mathbf{U}, \mathbf{V}, \mathbf{S}} \frac{1}{2}\|\mathbf{Y}-\mathbf{U V}-\mathbf{S}\|_{F}^{2}+\lambda\|\mathbf{S}\|_{1}+\lambda_{2}\left(\|\mathbf{U} \mathbf{V}\|_{*}\right) \\ &=\min _{\mathbf{X}, \mathbf{S}, \operatorname{rank}(\mathbf{X}) \leq r} \frac{1}{2}\|\mathbf{Y}-\mathbf{X}-\mathbf{S}\|_{F}^{2}+\lambda\|\mathbf{S}\|_{1}+\lambda_{2}\left(\|\mathbf{X}\|_{*}\right) . \end{aligned} U,V,Smin21∥Y−UV−S∥F2+λ∥S∥1+2λ2∥U∥F2+2λ2∥V∥F2=U,V,Smin21∥Y−UV−S∥F2+λ∥S∥1+λ2(∥UV∥∗)=X,S,rank(X)≤rmin21∥Y−X−S∥F2+λ∥S∥1+λ2(∥X∥∗).
从上式中,我们可以看到低秩矩阵分解恢复模型(1)是秩约束的RPCA模型的拉格朗日形式,如下所示 min X , S ∈ R m × n ∥ X ∥ ∗ + λ ∥ S ∥ 1 s.t. ∥ Y − X − S ∥ F 2 ≤ ε , rank ( X ) ≤ r ( 2 ) \min _{\mathbf{X}, \mathbf{S} \in \mathbb{R}^{m \times n}}\|\mathbf{X}\|_{*}+\lambda\|\mathbf{S}\|_{1} \text { s.t. }\|\mathbf{Y}-\mathbf{X}-\mathbf{S}\|_{F}^{2} \leq \varepsilon, \operatorname{rank}(\mathbf{X}) \leq r\quad(2) X,S∈Rm×nmin∥X∥∗+λ∥S∥1 s.t. ∥Y−X−S∥F2≤ε,rank(X)≤r(2)
其中 ε \varepsilon ε代表噪声方差。由于包含秩约束,秩约束RPCA模型(2)是非凸的,但是它可以通过基于ALM的方法来求解。把模型(2)称为低秩矩阵分解。
The augmented Lagrange multiplier method for exact recovery of corrupted low-rank matrices
LRTV for HSI Restoration
在稀疏噪声的位置随机分布的情况下,这种低秩矩阵分解模型只能从观察到的图像中分离稀疏噪声。也就是说,对于HSI数据,如果条纹位于所有波段中的相同位置,低秩矩阵分解模型(2)将无法检测到这些条纹,并将稀疏噪声视为低秩分量。而TV模型忽略光谱相似性,并且需要预先定义稀疏噪声的值或位置。我们可以执行以下LRTV恢复模型: min X , S ∈ R m × n ∥ X ∥ ∗ + τ ∥ X ∥ H T V + λ ∥ S ∥ 1 s.t. ∥ Y − X − S ∥ F 2 ≤ ε , rank ( X ) ≤ r ( 3 ) \min _{\mathbf{X}, \mathbf{S} \in \mathbb{R}^{m \times n}}\|\mathbf{X}\|_{*}+\tau\|\mathbf{X}\|_{HTV}+\lambda\|\mathbf{S}\|_{1} \\ \text{s.t. }\|\mathbf{Y}-\mathbf{X}-\mathbf{S}\|_{F}^{2} \leq \varepsilon,\text{ } \operatorname{rank}(\mathbf{X}) \leq r\quad(3) X,S∈Rm×nmin∥X∥∗+τ∥X∥HTV+λ∥S∥1s.t. ∥Y−X−S∥F2≤ε, rank(X)≤r(3)
其中 τ \tau τ是用于控制核范数和TV范数之间的折衷的参数, λ λ λ是用于限制稀疏噪声的稀疏性的参数。
Optimization Procedure(比较难)
本文采用了ALM方法解决优化问题(3)。将(3)转化为 min L , X , S ∈ R m × n ∥ L ∥ ∗ + τ ∥ X ∥ H T V + λ ∥ S ∥ 1 s.t. ∥ Y − L − S ∥ F 2 ≤ ε , rank ( L ) ≤ r , L = X \begin{aligned} &\min _{\mathbf{L}, \mathbf{X}, \mathbf{S} \in \mathbb{R}^{m \times n}}\|\mathbf{L}\|_{*}+\tau\|\mathbf{X}\|_{\mathrm{HTV}}+\lambda\|\mathbf{S}\|_{1} \\ &\text { s.t. } \|\mathbf{Y}-\mathbf{L}-\mathbf{S}\|_{F}^{2} \leq \varepsilon, \quad \operatorname{rank}(\mathbf{L}) \leq r, \quad \mathbf{L}=\mathbf{X} \end{aligned} L,X,S∈Rm×nmin∥L∥∗+τ∥X∥HTV+λ∥S∥1 s.t. ∥Y−L−S∥F2≤ε,rank(L)≤r,L=X
这个问题可以通过ALM方法来解决,该方法最小化了以下增广拉格朗日函数 min ℓ ( L , X , S , Λ 1 , Λ 2 ) = min X , S , L , Λ 1 , Λ 2 ∥ L ∥ ∗ + τ ∥ X ∥ H T V + λ ∥ S ∥ 1 + ⟨ Λ 1 , Y − L − S ⟩ + ⟨ Λ 2 , X − L ⟩ + μ 2 ( ∥ Y − L − S ∥ F 2 + ∥ X − L ∥ F 2 ) s.t. rank ( L ) ≤ r \begin{aligned} \min \ell\left(\mathbf{L}, \mathbf{X}, \mathbf{S}, \Lambda_{1}, \Lambda_{2}\right)=& \min _{\mathbf{X}, \mathbf{S}, \mathbf{L}, \Lambda_{1}, \Lambda_{2}}\|\mathbf{L}\|_{*}+\tau\|\mathbf{X}\|_{\mathrm{HTV}}+\lambda\|\mathbf{S}\|_{1} \\ &+\left\langle\Lambda_{1}, \mathbf{Y}-\mathbf{L}-\mathbf{S}\right\rangle+\left\langle\Lambda_{2}, \mathbf{X}-\mathbf{L}\right\rangle \\ &+\frac{\mu}{2}\left(\|\mathbf{Y}-\mathbf{L}-\mathbf{S}\|_{F}^{2}+\|\mathbf{X}-\mathbf{L}\|_{F}^{2}\right) \\ \text { s.t. } & \operatorname{rank}(\mathbf{L}) \leq r \end{aligned} minℓ(L,X,S,Λ1,Λ2)= s.t. X,S,L,Λ1,Λ2min∥L∥∗+τ∥X∥HTV+λ∥S∥1+⟨Λ1,Y−L−S⟩+⟨Λ2,X−L⟩+2μ(∥Y−L−S∥F2+∥X−L∥F2)rank(L)≤r
其中 μ μ μ是惩罚参数, Λ 1 \Lambda_1 Λ1和 Λ 2 \Lambda_2 Λ2是拉格朗日乘子(multipliers)。在一个变量上迭代优化增广拉格朗日函数,同时固定其他变量。具体来说,在第 k + 1 k+1 k+1次迭代中,我们更新变量如下 L ( k + 1 ) = arg min r a n k ( L ) ⩽ r ℓ ( L , X ( k ) , S ( k ) , Λ 1 ( k ) , Λ 2 ( k ) ) ( a ) X ( k + 1 ) = arg min X ℓ ( L ( k + 1 ) , X , S ( k ) , Λ 1 ( k ) , Λ 2 ( k ) ) ( b ) S ( k + 1 ) = arg min S ℓ ( L ( k + 1 ) , X ( k + 1 ) , S , Λ 1 ( k ) , Λ 2 ( k ) ) ( c ) Λ 1 ( k + 1 ) = Λ 1 ( k ) + μ ( Y − L ( k + 1 ) − S ( k + 1 ) ) ( d ) Λ 2 ( k + 1 ) = Λ 2 ( k ) + μ ( X ( k + 1 ) − L ( k + 1 ) ) ( e ) \begin{aligned} \mathbf{L}^{(k+1)}&=\underset{rank\left( \mathbf{L} \right) \leqslant r}{\arg\min} \ell\left(\mathbf{L}, \mathbf{X}^{(k)}, \mathbf{S}^{(k)}, \Lambda_{1}^{(k)}, \Lambda_{2}^{(k)}\right)\quad(a)\\ \mathbf{X}^{(k+1)}&=\underset{\mathbf{X}}{\arg \min } \ell\left(\mathbf{L}^{(k+1)}, \mathbf{X}, \mathbf{S}^{(k)}, \Lambda_{1}^{(k)}, \Lambda_{2}^{(k)}\right)\quad(b)\\ \mathbf{S}^{(k+1)} &=\underset{\mathbf{S}}{\arg \min } \ell\left(\mathbf{L}^{(k+1)}, \mathbf{X}^{(k+1)}, \mathbf{S}, \Lambda_{1}^{(k)}, \Lambda_{2}^{(k)}\right)\quad(c)\\ \Lambda_{1}^{(k+1)} &=\Lambda_{1}^{(k)}+\mu\left(\mathbf{Y}-\mathbf{L}^{(k+1)}-\mathbf{S}^{(k+1)}\right)\quad(d) \\ \Lambda_{2}^{(k+1)} &=\Lambda_{2}^{(k)}+\mu\left(\mathbf{X}^{(k+1)}-\mathbf{L}^{(k+1)}\right)\quad(e) \end{aligned} L(k+1)X(k+1)S(k+1)Λ1(k+1)Λ2(k+1)=rank(L)⩽rargminℓ(L,X(k),S(k),Λ1(k),Λ2(k))(a)=Xargminℓ(L(k+1),X,S(k),Λ1(k),Λ2(k))(b)=Sargminℓ(L(k+1),X(k+1),S,Λ1(k),Λ2(k))(c)=Λ1(k)+μ(Y−L(k+1)−S(k+1))(d)=Λ2(k)+μ(X(k+1)−L(k+1))(e)
优化问题现在被分成三个主要的子问题,如
(
a
)
−
(
c
)
(a)-(c)
(a)−(c)所示。对于
(
a
)
(a)
(a),我们可以推导出(最后一个等式没看懂)
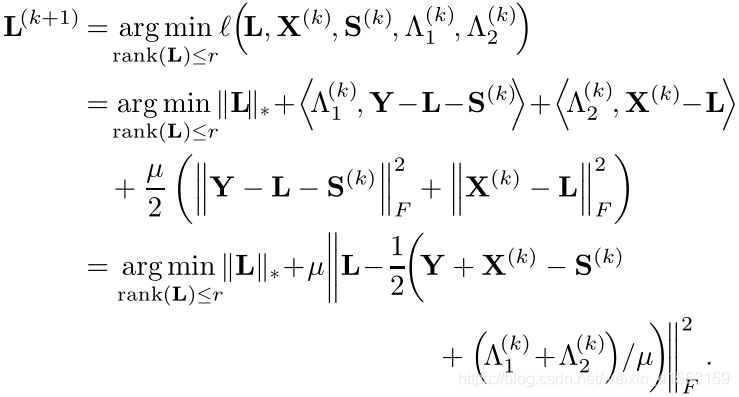
更新 L \mathbf{L} L的步骤可以用下面的引理2来求解。
引理2:矩阵 W ∈ R M N × p \mathbf{W}\in\mathbb{R}^{MN\times p} W∈RMN×p的秩 r r r奇异值分解为 W = U E r V ∗ , E r = diag ( { σ i } 1 ≤ i ≤ r ) \mathbf{W}=U E_{r} V^{*}, E_{r}=\operatorname{diag}\left(\left\{\sigma_{i}\right\}_{1 \leq i \leq r}\right) W=UErV∗,Er=diag({σi}1≤i≤r)
奇异值收缩算子满足 D δ ( W ) = arg min rank ( L ) ≤ r δ ∥ L ∥ ∗ + 1 2 ∥ L − W ∥ F 2 D_{\delta}(\mathbf{W})=\underset{\operatorname{rank}(\mathbf{L}) \leq r }{\argmin} \delta\|\mathbf{L}\|_{*}+\frac{1}{2}\|\mathbf{L}-\mathbf{W}\|_{F}^{2} Dδ(W)=rank(L)≤rargminδ∥L∥∗+21∥L−W∥F2
其中 D δ ( W ) = U D δ ( E r ) V ∗ , D δ ( E r ) = diag { max ( ( σ i − δ ) , 0 ) } D_{\delta}(\mathbf{W})=U D_{\delta}\left(E_{r}\right) V^{*}, D_{\delta}\left(E_{r}\right)=\operatorname{diag}\left\{\max \left(\left(\sigma_{i}-\delta\right), 0\right)\right\} Dδ(W)=UDδ(Er)V∗,Dδ(Er)=diag{max((σi−δ),0)}
通过使用引理2,我们可以容易地获得以下优化结果 L ( k + 1 ) = D 1 ( 2 μ ) ( 1 2 ( Y + X ( k ) − S ( k ) + ( Λ 1 ( k ) + Λ 2 ( k ) ) / μ ) ) \mathbf{L}^{(k+1)}=D_{\frac{1}{(2 \mu)}}\left(\frac{1}{2}\left(\mathbf{Y}+\mathbf{X}^{(k)}-\mathbf{S}^{(k)}+\left(\Lambda_{1}^{(k)}+\Lambda_{2}^{(k)}\right) / \mu\right)\right) L(k+1)=D(2μ)1(21(Y+X(k)−S(k)+(Λ1(k)+Λ2(k))/μ))
对于子问题 ( b ) (b) (b),有 X ( k + 1 ) = arg min X ℓ ( L ( k + 1 ) , X , S ( k ) , Λ 1 ( k ) , Λ 2 ( k ) ) = arg min X τ ∥ X ∥ H T V + ⟨ Λ 2 ( k ) , X − L ( k + 1 ) ⟩ + μ 2 ∥ X − L ( k + 1 ) ∥ F 2 = arg min X τ ∥ X ∥ H T V + μ 2 ∥ X − L ( k + 1 ) + Λ 2 ( k ) μ ∥ F 2 \begin{aligned} \mathbf{X}^{(k+1)}=& \underset{\mathbf{X}}{\arg \min } \ell\left(\mathbf{L}^{(k+1)}, \mathbf{X}, \mathbf{S}^{(k)}, \Lambda_{1}^{(k)}, \Lambda_{2}^{(k)}\right) \\ =& \underset{\mathbf{X}}{\arg \min } \tau\|\mathbf{X}\|_{\mathrm{HTV}}+\left\langle\Lambda_{2}^{(k)}, \mathbf{X}-\mathbf{L}^{(k+1)}\right\rangle \\ &+\frac{\mu}{2}\left\|\mathbf{X}-\mathbf{L}^{(k+1)}\right\|_{F}^{2} \\ =& \arg \min _{\mathbf{X}} \tau\|\mathbf{X}\|_{\mathrm{HTV}}+\frac{\mu}{2}\left\|\mathbf{X}-\mathbf{L}^{(k+1)}+\frac{\Lambda_{2}^{(k)}}{\mu}\right\|_{F}^{2} \end{aligned} X(k+1)===Xargminℓ(L(k+1),X,S(k),Λ1(k),Λ2(k))Xargminτ∥X∥HTV+⟨Λ2(k),X−L(k+1)⟩+2μ∥∥∥X−L(k+1)∥∥∥F2argXminτ∥X∥HTV+2μ∥∥∥∥∥X−L(k+1)+μΛ2(k)∥∥∥∥∥F2
我们定义 Q = L ( k + 1 ) − ( Λ 2 ( k ) / μ ) Q=\mathbf{L}^{(k+1)}-\left(\Lambda_{2}^{(k)} / \mu\right) Q=L(k+1)−(Λ2(k)/μ)以及 Q = [ Q 1 , Q 2 , … , Q p ] ∈ R M N × p Q=\left[Q_{1}, Q_{2}, \ldots, Q_{p}\right] \in\mathbb{R}^{M N \times p} Q=[Q1,Q2,…,Qp]∈RMN×p,上述优化可以分成 p p p个子问题,每个子问题都要解决( H X j \mathbf{H} \mathbf{X}_{j} HXj是什么?) X j ( k + 1 ) = arg min X j τ μ ∥ H X j ∥ T V + 1 2 ∥ X j − Q j ∥ 2 \mathbf{X}_{j}^{(k+1)}=\underset{\mathbf{X}_{j}}{\arg \min } \frac{\tau}{\mu}\left\|\mathbf{H} \mathbf{X}_{j}\right\|_{\mathrm{TV}}+\frac{1}{2}\left\|\mathbf{X}_{j}-Q_{j}\right\|^{2} Xj(k+1)=Xjargminμτ∥HXj∥TV+21∥Xj−Qj∥2
在本文中,我们使用快速基于梯度的算法(Ref:Fast gradient-based algorithms for constrained total variation image denoising and deblurring problems)来求解上式。对于子问题 ( c ) (c) (c),有 S ( k + 1 ) = arg min S ℓ ( L ( k + 1 ) , X ( k + 1 ) , S , Λ 1 ( k ) , Λ 2 ( k ) ) = arg min S λ ∥ S ∥ 1 + ⟨ Λ 1 ( k ) , Y − L ( k + 1 ) − S ⟩ + μ 2 ∥ Y − L ( k + 1 ) − S ∥ F 2 = arg min S λ ∥ S ∥ 1 + μ 2 ∥ S − ( Y − L ( k + 1 ) + Λ 1 ( k ) μ ) ∥ 2 ( 4 ) \begin{aligned} \mathbf{S}^{(k+1)}=& \underset{\mathbf{S}}{\arg \min } \ell\left(\mathbf{L}^{(k+1)}, \mathbf{X}^{(k+1)}, \mathbf{S}, \Lambda_{1}^{(k)}, \Lambda_{2}^{(k)}\right) \\ =& \underset{\mathbf{S}}{\arg \min } \lambda\|\mathbf{S}\|_{1}+\left\langle\Lambda_{1}^{(k)}, \mathbf{Y}-\mathbf{L}^{(k+1)}-\mathbf{S}\right\rangle \\ &+\frac{\mu}{2}\left\|\mathbf{Y}-\mathbf{L}^{(k+1)}-\mathbf{S}\right\|_{F}^{2} \\ =& \underset{\mathbf{S}}{\arg \min } \lambda\|\mathbf{S}\|_{1}+\frac{\mu}{2}\left\|\mathbf{S}-\left(\mathbf{Y}-\mathbf{L}^{(k+1)}+\frac{\Lambda_{1}^{(k)}}{\mu}\right)\right\|^{2}\quad(4) \end{aligned} S(k+1)===Sargminℓ(L(k+1),X(k+1),S,Λ1(k),Λ2(k))Sargminλ∥S∥1+⟨Λ1(k),Y−L(k+1)−S⟩+2μ∥∥∥Y−L(k+1)−S∥∥∥F2Sargminλ∥S∥1+2μ∥∥∥∥∥S−(Y−L(k+1)+μΛ1(k))∥∥∥∥∥2(4)
通过引入下面的软阈值(收缩)算子 ℜ Δ ( x ) = { x − Δ , if x > Δ x + Δ , if x < − Δ 0 , otherwise \Re_{\Delta}(x)=\left\{\begin{array}{ll} x-\Delta, & \text { if } x>\Delta \\ x+\Delta, & \text { if } x<-\Delta \\ 0, & \text { otherwise } \end{array}\right. ℜΔ(x)=⎩⎨⎧x−Δ,x+Δ,0, if x>Δ if x<−Δ otherwise
其中 x ∈ R , Δ > 0 x\in\mathbb{R}, \Delta>0 x∈R,Δ>0,(4)的优化可以表示如下 S ( k + 1 ) = ℜ λ μ ( Y − L ( k + 1 ) + Λ 1 ( k ) μ ) \mathbf{S}^{(k+1)}=\Re_{\frac{\lambda}{\mu}}\left(\mathbf{Y}-\mathbf{L}^{(k+1)}+\frac{\Lambda_{1}^{(k)}}{\mu}\right) S(k+1)=ℜμλ(Y−L(k+1)+μΛ1(k))
总结前面的描述,我们得到了一个增广拉格朗日交替方向法来求解LRTV模型,算法如下:
(22)即为(a)…(e)那里。

Robust recovery of subspace structures by low-rank representation
Constrained Optimization and Lagrange Multiplier Methods
Parameter Determination
λ = 1 / M N \lambda=1/\sqrt{MN} λ=1/MN, ε 1 = ε 2 = 1 0 − 8 \varepsilon_1=\varepsilon_2=10^{-8} ε1=ε2=10−8,借助于[Ref:Hyperspectral subspace identification]提出的称为HySime的HSI子空间识别方法来估计端元的数量 r r r, τ = 0.01 \tau=0.01 τ=0.01.
实验
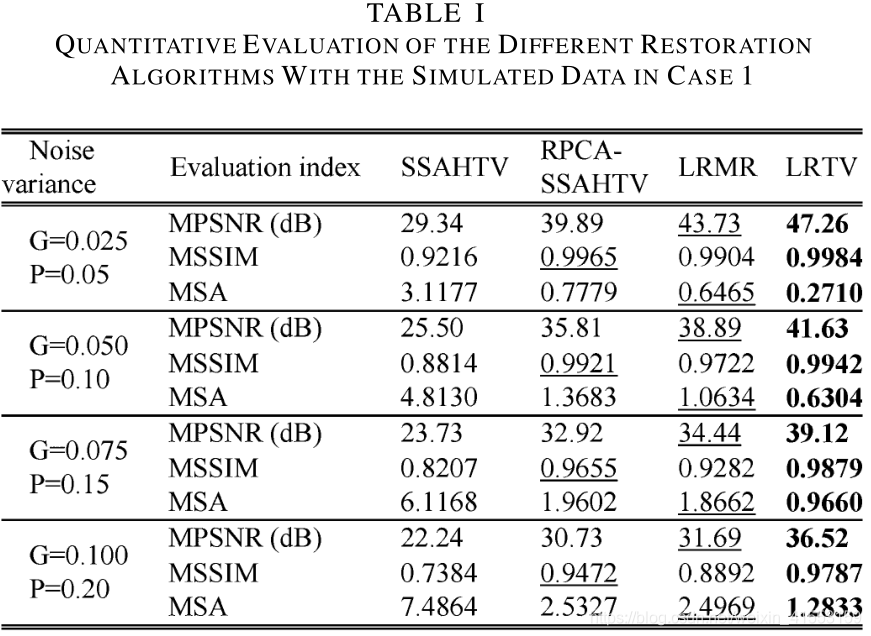
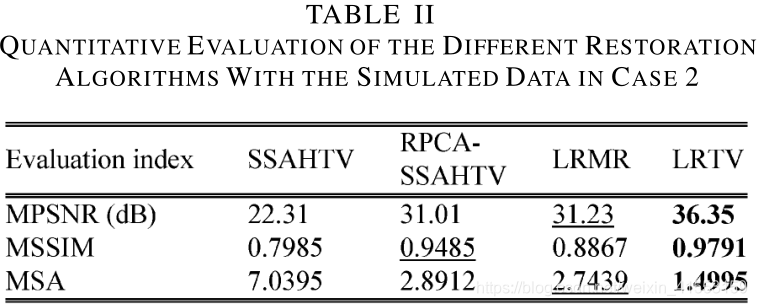
对比:SSAHTV,LRMR
模拟实验:Indian Pines(GT,145×145×224)
https://engineering.purdue.edu/~biehl/MultiSpec/hyperspectral.html
http://speclab.cr.usgs.gov/spectral.lib
真实实验:
- HYDICE urban data set, http://www.tec.army.mil/hypercube, 200×200×210
- Indian Pines data set, 145×145×220
- EO-1 Hyperion data set, http://www.gscloud.cn/, 200×200×166
改进之处:尽管LRTV性能良好,但它仍有进一步改进的空间。在实验中,我们将相同的参数值添加到HSI的所有波段。然而,正如SSAHTV中所介绍的,不同波段的噪声强度应该是不同的。也就是说,结合低秩约束的噪声调整TV正则化将在未来被研究。
源代码
1