📢📢📢📣📣📣
作者:IT邦德
中国DBA联盟(ACDU)成员,10余年DBA工作经验
Oracle、PostgreSQL ACE
CSDN博客专家及B站知名UP主,全网粉丝10万+
擅长主流Oracle、MySQL、PG、高斯及Greenplum备份恢复,
安装迁移,性能优化、故障应急处理
本次的故障案例是发生在Oracle 10G的数据库上,在上午的10点,整个应用处于卡顿的状态,数据库完全是夯住了!这套库之前给客户做过巡检就提出替换存储的建议,这不这次故障存储的问题就暴露出来了,详细的分析过程如下
1.异常等待分析
通过AWR分析看出来,log file sync占比64.2%,属于提交类异常等待
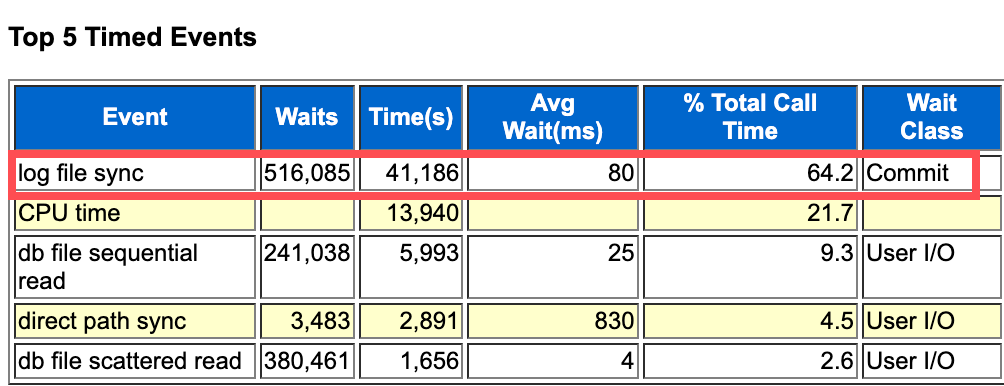
那么到底log file sync是什么呢?
官方的解释为:当用户会话提交时,该会话事务生成的所有重做记录都需要从内存中刷新到重做日志文件中,以确保该事务对数据库所做的更改是永久性的。
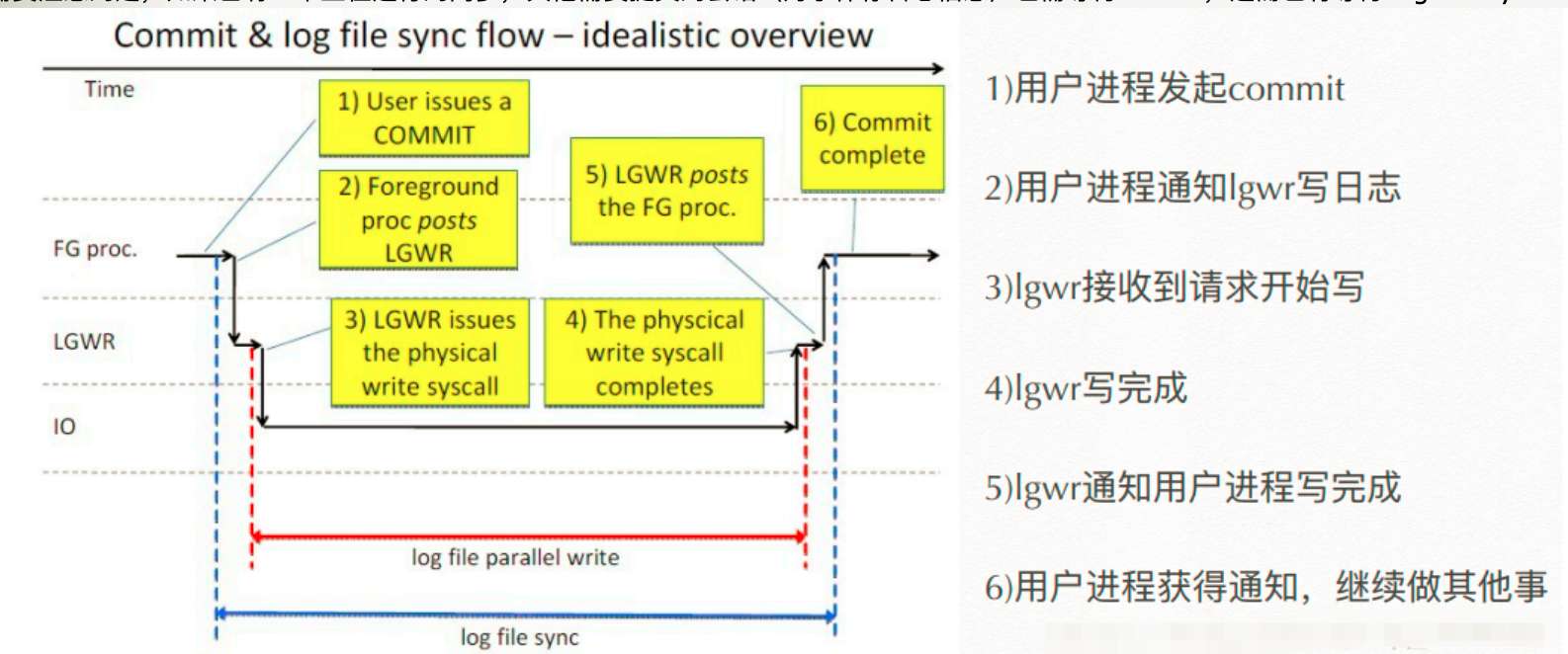
2.查找根因
什么原因会造成了很高的log file sync等待呢?
其中的最常见的原因有2个
1.影响 LGWR 的 I/O 性能问题
2.过多的应用程序 commit
2.1 分析程序提交
比较 user commit/rollback 同 user calls 比值的平均值确认提交是否异常

user calls/(user commits+user rollbacks) 本次平均值为60.85= 60.85/(0.98+0.02) ,平均每60.85 次 user calls 就会有一次 commit,提交不是很频繁。

然后在确认LGWR switch是否异常
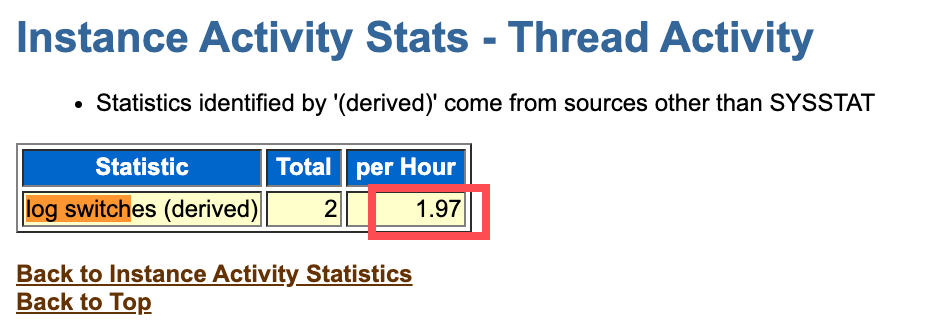
oracle的推荐值是每15-20分钟切换一次,也就是每小时切换3-4次。如果per Hour大于3-4次,则说明日志文件过小。
2.2 分析IO性能问题
比较’log file sync’和’log file parallel write’的平均等待时间。
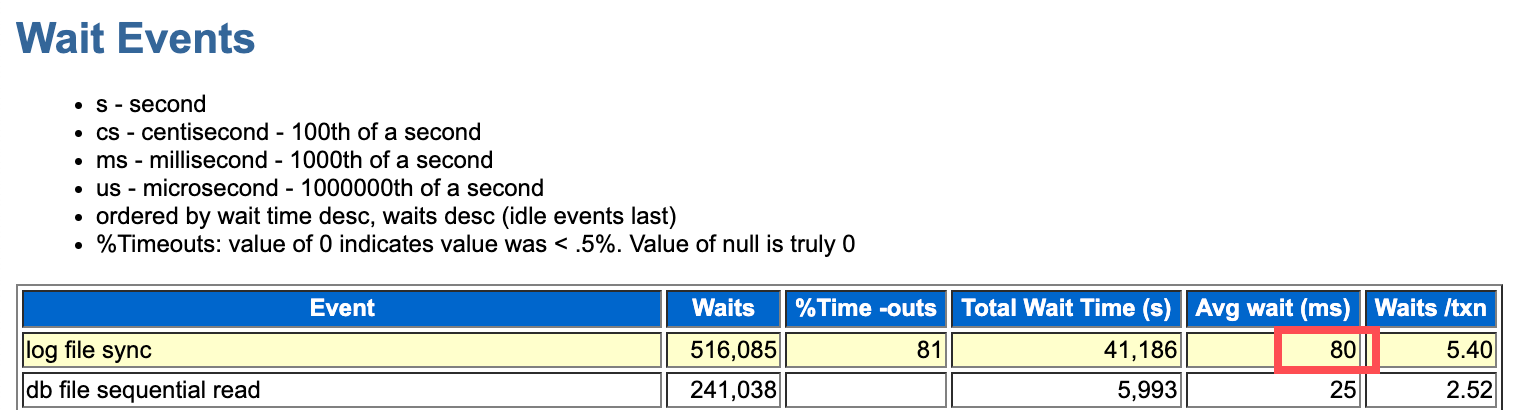

很明显log file sync的时间消耗在log file parallel write上的比例高,那么大部分的等待时间是由于 IO(等待 redo 写入)
根据经验,“日志文件并行写入”的平均时间超过5-10毫秒,甚至可能更低,这表明IO子系统存在问题。
同时根据异常等待阻塞事务发现也是大量的log file parallel write阻塞了log file sync,初步判断磁盘的I/O出现了问题。
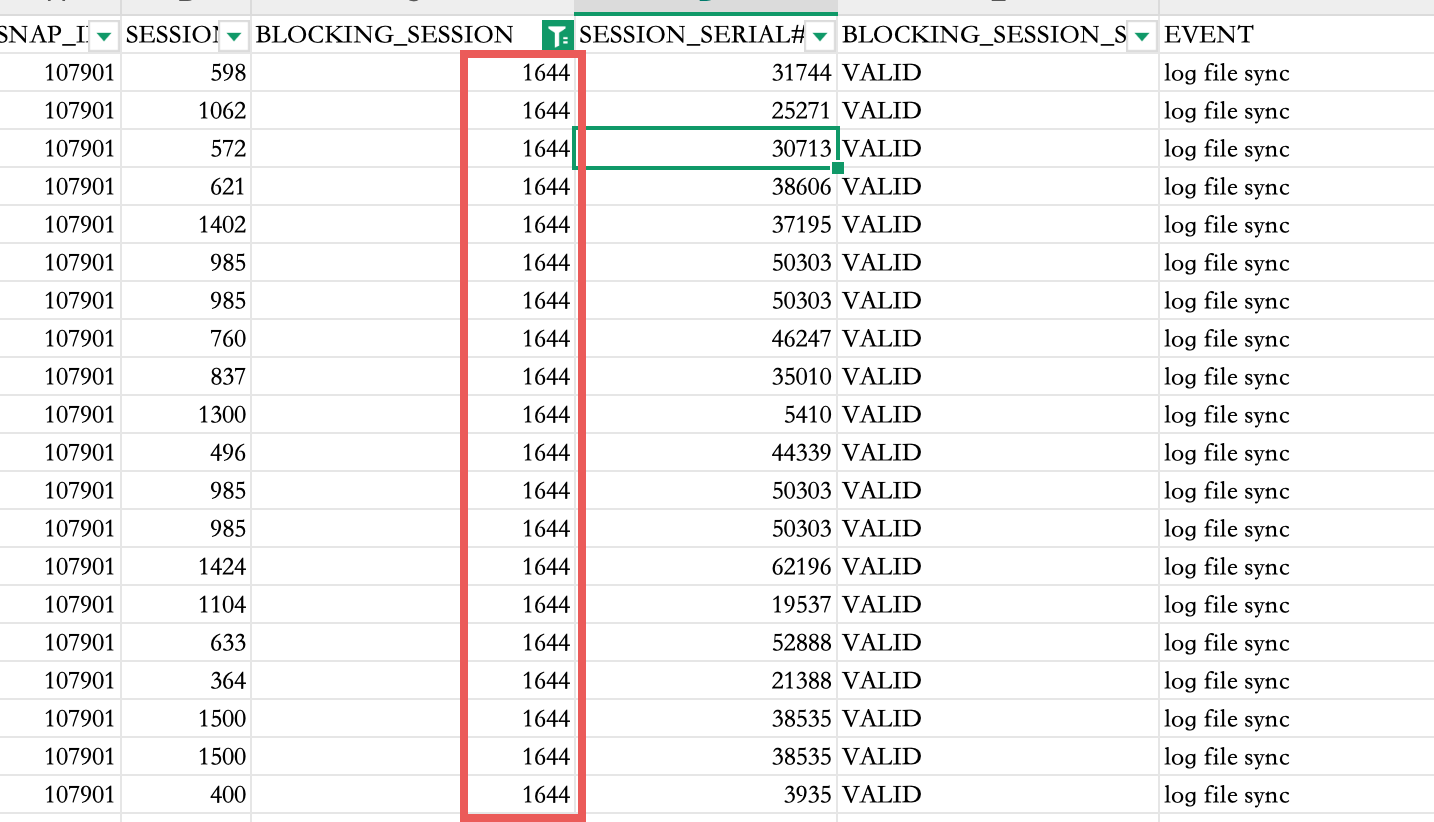
后来客户反馈,该时间段存储设备为机械盘,出了点问题,导致存储IO性能严重下降。
3.alert日志排查
alert.log日志报了如下的错误,再次证明了以上的判断无误!
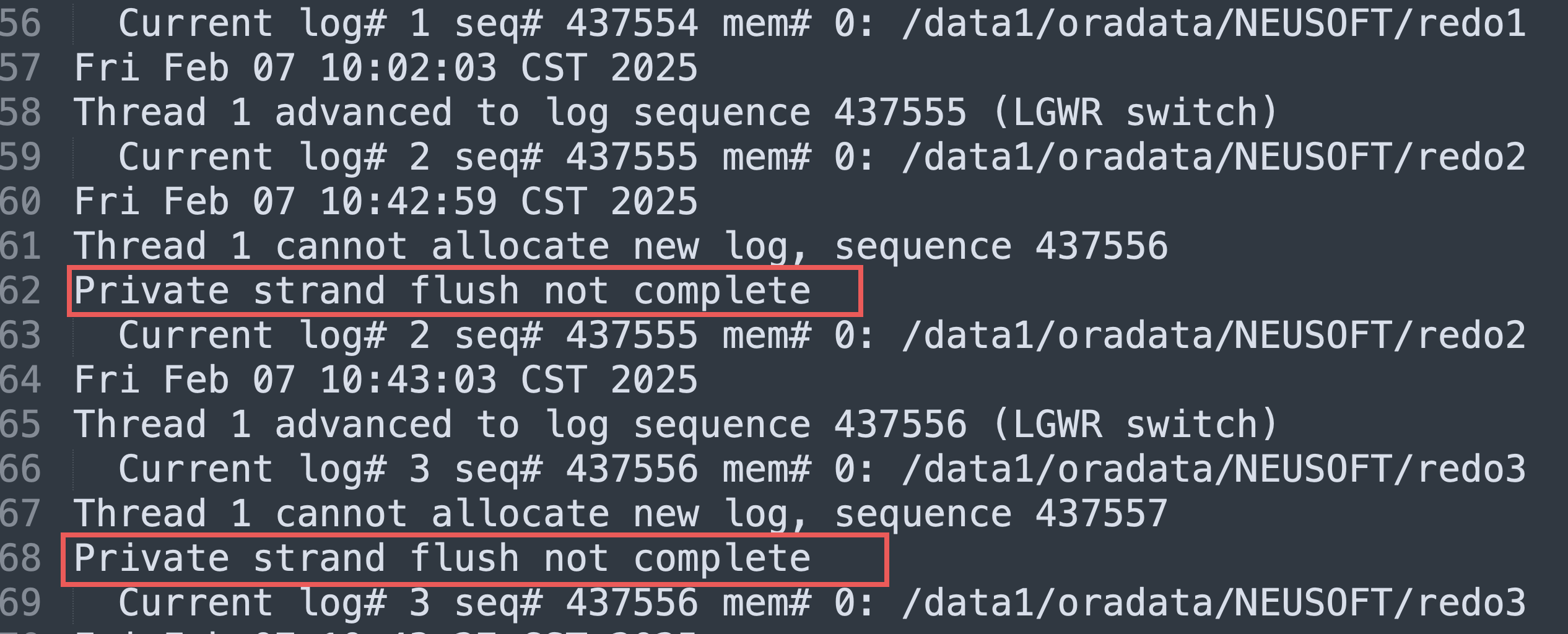
当数据库切换日志时,所有private strand都必须刷新到当前日志,然后才能继续,此信息表示我们在尝试切换时,还没有完全将所有 redo信息写入到日志中。
Private Strands是10gR2才有的,它用于处理redo的latch(redo allocation latch),是一种允许进程利用多个allocation latch更高效地将redo写入redo buffer cache的机制。
4.总结
不要把重做日志放在上一代或者较老的机械磁盘上,虽然通常情况下,可能会遇到写峰值,从而导致大量的严重’log file sync’等待并引发数据库性能不稳定或者hung住。
监控其他可能需要写到相同路径的进程,确保该磁盘具有足够的带宽,足以应付所要求的容量。
确保 LOG_BUFFER 不要太大,一个非常大的 log_buffer 的不利影响就是刷新需要更长的等待时间。