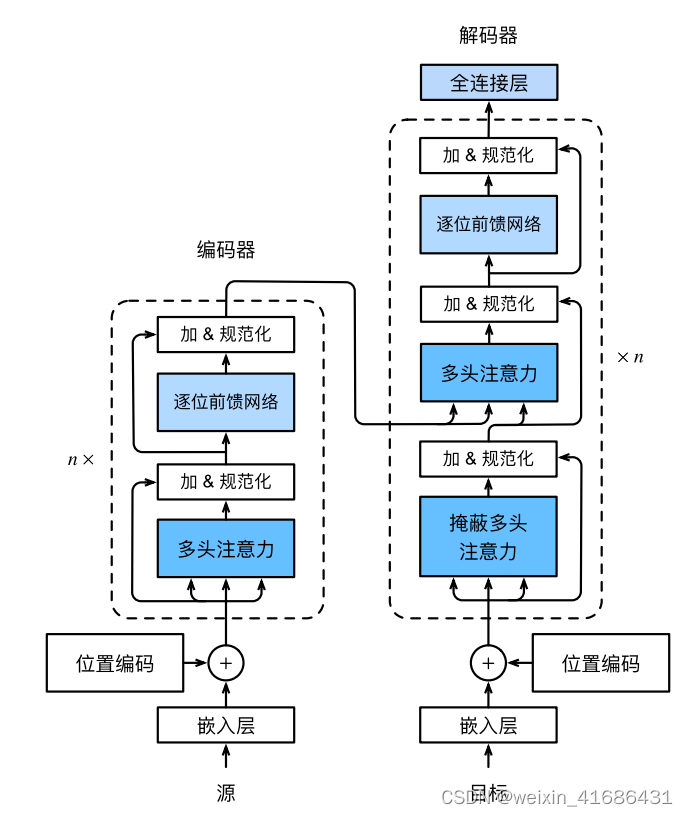
一,Transformer架构介绍:
Transformer的编码器-解码器是基于自注意力的模块叠加而成的,源序列(Input)和目标序列(Target)的嵌入(Embedding)表示将加上位置编码(Positional encoding),再分别输入到编码器和解码器中。从宏观角度来看,Transformer的编码器是由多个相同的层叠加而 成的,每个层都有两个子层(子层表示为sublayer)。第一个子层是多头自注意力(multi‐head self‐attention)
二,嵌入层和位置编码的作用:
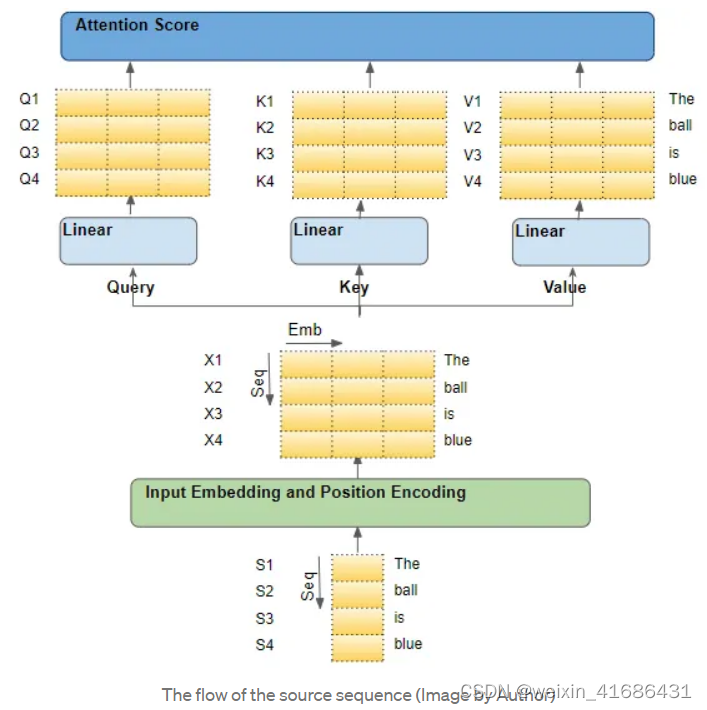
举个例子,假设我们正在处理一个英语到西班牙语的翻译问题,其中一个样本的源序列是 "The ball is blue",目标序列是 "La bola es azul"。
源序列首先通过 Embedding 和 Position Encoding 层,为序列中的每个单词生成嵌入。随后嵌入被传递到编码器,到达 Attention module.
Attention module 中,嵌入的序列通过三个线性层(Linear layers),产生三个独立的矩阵--Query、Key、Value。这三个矩阵被用来计算注意力得分。这些矩阵的每一 "行 "对应于源序列中的一个词。
位置编码的简单图示:

三,多头自注意力网络(MultiHead Self-Attention):

多头点积注意力:
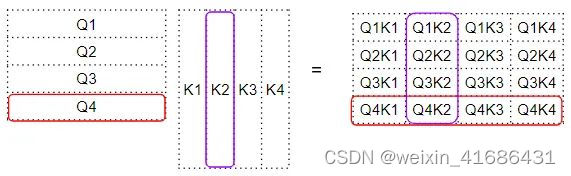
Query 与 Key 的转置进行点积,产生一个中间矩阵,即所谓“因子矩阵”。因子矩阵的每个单元都是两个词向量之间的矩阵乘法。

如下所示,因子矩阵第 4 行的每一列都对应于 Q4 向量与每个 K 向量之间的点积;因子矩阵的第 2 列对应与每个 Q 向量与 K2 向量之间的点积,这个“因子矩阵”就是注意力分数(Attention Score)
因子矩阵再经过Softmax函数生成一组概率分布也就是注意力权重(Attention Weights)再和 V 矩阵之间进行矩阵相乘,产生注意力池化(Attention Pooling)输出。可以看到,输出矩阵中第 4 行对应的是 Q4 矩阵与所有其他对应的 K 和 V 相乘:

可以将注意力得分理解成一个词的“编码值”。这个编码值是由“因子矩阵”对 Value 矩阵中的词加权而来。而“因子矩阵”中对应的权值则是该特定单词的 Query 向量与 Key 向量的点积。再啰嗦一遍:
1-一个词的注意力得分可以理解为该词的"编码值",它是注意力机制最终为每个词赋予的表示向量。
2-这个"编码值"是由"值矩阵"(Value矩阵)中每个词的值向量加权求和得到的。
3-加权的权重就是"因子矩阵"中对应的注意力权重。
4-"因子矩阵"中的注意力权重是通过该词的查询向量(Query)与所有词的键向量(Key)做点积计算得到的。
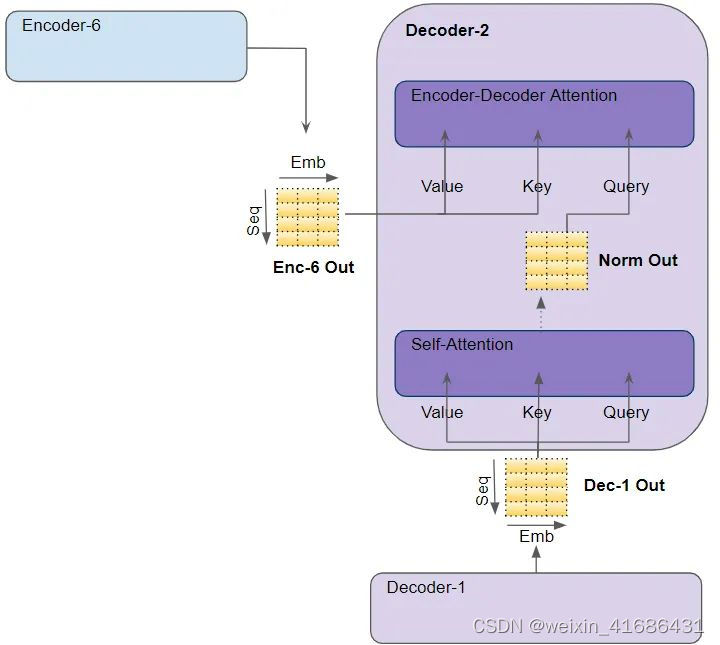
四,Transformer的Encoder与Decoder键值传递:

在 "Encoder-Decoder Attention "中,Query 来自Traget序列,而Key-Value来自Input序列。
五,Transformer的实战代码:
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt
# 1.1, 搭建多头注意力
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens, value=-1e6)
return nn.functional.softmax(X.reshape(shape), dim=-1)
class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries的形状:(batch_size,查询的个数,d)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[2]
scores = torch.bmm(queries, keys.transpose(1, 2))/math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
def transpose_qkv(tensor, num_heads):
"""为了多注意力头的并行计算而变换形状"""
# 输入tensor的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
# 输出tensor的形状:(batch_size,查询或者“键-值”对的个数,num_heads,
# num_hiddens/num_heads)
tensor = tensor.reshape(tensor.shape[0], tensor.shape[1], num_heads, -1)
# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
tensor = tensor.permute(0, 2, 1, 3)
# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
return tensor.reshape(-1, tensor.shape[2], tensor.shape[3])
def transpose_output(tensor, num_heads):
"""逆转transpose_qkv函数的操作"""
tensor = tensor.reshape(-1, num_heads, tensor.shape[1], tensor.shape[2])
tensor = tensor.permute(0, 2, 1, 3)
return tensor.reshape(tensor.shape[0], tensor.shape[1], -1)
class MultiHeadAttention(nn.Module):
def __init__(self, key_size, query_size, value_size, num_hiddens, num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
print('MultiHeadAttention __init__:', file=log)
self.num_heads = num_heads
self.attention = DotProductAttention(dropout)
self.weight_query = nn.Linear(query_size, num_hiddens, bias=bias)
self.weight_key = nn.Linear(key_size, num_hiddens, bias=bias)
self.weight_value = nn.Linear(value_size, num_hiddens, bias=bias)
self.weight_output = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# queries, keys, values的形状:
# (batch_size, 查询或者“键-值”对的个数,num_hiddens)
# valid_lens 的形状:
# (batch_size, )或(batch_size, 查询的个数)
# 经过变换后,输出的queries, keys, values的形状
# (batch_size*num_heads, 查询或者“键-值”对的个数)
# num_hiddens/num_heads
queries = transpose_qkv(self.weight_query(queries), self.num_heads)
# print('queries:', file=log)
# print(queries.shape, file=log)
# print(queries, file=log)
keys = transpose_qkv(self.weight_key(keys), self.num_heads)
# print('keys:', file=log)
# print(keys.shape, file=log)
# print(keys, file=log)
values = transpose_qkv(self.weight_value(values), self.num_heads)
# print('values:', file=log)
# print(values.shape, file=log)
# print(values, file=log)
if valid_lens is not None:
# 在轴0,将第一项(标量或者矢量)复制num_heads次,
# 然后如此复制第二项,然后诸如此类。
valid_lens = torch.repeat_interleave(valid_lens, repeats=self.num_heads, dim=0)
# print('valid_lens:', file=log)
# print(valid_lens.shape, file=log)
# print(valid_lens, file=log)
# output的形状:(batch_size*num_heads,查询的个数,num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# print('output:', file=log)
# print(output.shape, file=log)
# print(output, file=log)
# output_concat的形状:(batch_size,查询的个数,num_hiddens)
output_concat = transpose_output(output, self.num_heads)
# print('output_concat:', file=log)
# print(output_concat.shape, file=log)
# print(output_concat, file=log)
return self.weight_output(output_concat)
# 2.1, 基于位置的前馈网络
class PositionWiseFFN(nn.Module):
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs, **kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
print('PositionWiseFFN __init__:', file=log)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
"""
FFN = PositionWiseFFN(4, 4, 8)
FFN.eval()
print(FFN(torch.ones((2, 3, 4))).shape)
print(FFN(torch.ones((2, 3, 4))))
"""
# 3.1, 残差连接和层规范化
ln = torch.nn.LayerNorm(2)
bn = torch.nn.BatchNorm1d(2)
X = torch.tensor([[1, 2], [3, 4]], dtype=torch.float32)
# 在训练模式下计算x的均值和方差
print('layer norm:', ln(X), '\nbatch norm:', bn(X))
# 3.2, 使用残差连接和层规范化来实现AddNorm类,暂退法也被作为正则化方法使用。
class AddNorm(nn.Module):
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
print('AddNorm __init__:', file=log)
self.dropout = torch.nn.Dropout(dropout)
self.ln = torch.nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
# 3.3 残差连接要求两个输入的形状相同,以便加法操作后输出张量的形状相同。
"""
add_norm = AddNorm([3, 4], 0.5)
add_norm.eval()
tensor1 = add_norm(torch.ones((2, 3, 4)), torch.ones((2, 3, 4)))
print(tensor1.shape)
print(tensor1)
"""
# 4.1, 位置编码
class PositionalEncoding(nn.Module):
"""位置编码"""
def __init__(self, num_hiddens, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
# 创建一个足够长的P
self.P = torch.zeros((1, max_len, num_hiddens))
print('PositionalEncoding:', file=log)
print(self.P.shape, file=log)
X = torch.arange(0, max_len, step=1, dtype=torch.float32).reshape(-1, 1)
print('X1:', file=log)
print(X.shape, file=log)
Y = torch.pow(10000, torch.arange(0, num_hiddens, step=2, dtype=torch.float32) / num_hiddens)
print('Y:', file=log)
print(Y.shape, file=log)
print(Y, file=log)
X = X/Y
print('X3:', file=log)
print(X.shape, file=log)
print(X, file=log)
self.P[:, :, 0:num_hiddens:2] = torch.sin(X)
self.P[:, :, 1:num_hiddens:2] = torch.cos(X)
print(self.P.shape, file=log)
print(self.P, file=log)
def forward(self, X):
X = X + self.P[:, :X.shape[1], :].to(X.device)
print('self.P:', file=log)
print(self.P[:, :X.shape[1], :].to(X.device), file=log)
print('X4:', file=log)
print(X.shape, file=log)
print(X, file=log)
return self.dropout(X)
# 4.2, 位置编码测试
"""
encoding_dim, num_steps = 32, 60
pos_encoding = PositionalEncoding(encoding_dim, 0)
pos_encoding.eval()
tensor_pos = torch.zeros((1, num_steps, encoding_dim))
print('tensor_pos:')
print(tensor_pos.shape)
print(tensor_pos)
X = pos_encoding(tensor_pos)
print('X4:')
print(X.shape)
print(X)
P = pos_encoding.P[:, :X.shape[1], :]
d2l.plot(torch.arange(num_steps), P[0, :, 6:10].T, xlabel='Row(position)', figsize=(6, 2.5), legend=["Col %d" % d for d in torch.arange(6, 10)])
plt.show()
"""
# 5.1, 实现编码器中的一个层,EncoderBlock类包含两个子层:多头自注意力和基于位置的前馈网络,
# 这两个子层都使用了残差连接和紧随的层规范化。
class EncoderBlock(nn.Module):
def __init__(self, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
print('EncoderBlock __init__:', file=log)
self.attention = MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout, use_bias)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
def forward(self, X, valid_lens):
print('EncoderBlock forward:', file=log)
atten = self.attention(X, X, X, valid_lens)
print('atten:', file=log)
print(atten.shape, file=log)
print(atten, file=log)
Y = self.addnorm1(X, atten)
print('Y:', file=log)
print(Y.shape, file=log)
print(Y, file=log)
ff = self.ffn(Y)
print('ff:', file=log)
print(ff.shape, file=log)
print(ff, file=log)
return self.addnorm2(Y, ff)
"""
log = open('transformer1.txt', mode='a', encoding='utf-8')
# X = torch.ones((2, 100, 24))
valid_lens = torch.tensor([3, 2])
encoder_blk = EncoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5)
encoder_blk.eval()
# encoder_blk(X, valid_lens).shape
"""
# 5.2, 实现Transformer编码器,堆叠num_layers个EncoderBlock类的实例。
class TransformerEncoder(d2l.Encoder):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
print('EncoderBlock instance index:', file=log)
print(i, file=log)
self.blks.add_module("block"+str(i), EncoderBlock(key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, dropout, use_bias))
def forward(self, X, valid_lens, *args):
# 因为位置编码值在-1和1之间,
# 因此嵌入值乘以嵌入维度的平方根进行缩放,
# 然后再与位置编码相加。
X = self.embedding(X) * math.sqrt(self.num_hiddens)
print('TransformerEncoder:', file=log)
print(X.shape, file=log)
print(X, file=log)
X = self.pos_encoding(X)
print('TransformerEncoder:', file=log)
print(X.shape, file=log)
print(X, file=log)
self.attention_weights = [None]*len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[i] = blk.attention.attention.attention_weights
return X
# 6.1, 指定超参数创建两层的Transformer编码器,Transformer编码器输出的形状是(批量大小,时间步数目,num_hiddens)
"""
encoder = TransformerEncoder(200, 24, 24, 24, 24, [100, 24], 24, 48, 8, 2, 0.5)
encoder.eval()
valid_lens = torch.tensor([3,2])
encoder(torch.ones((2, 100), dtype=torch.long), valid_lens).shape
"""
# 7.1, 解码器包含了三个子层:解码器自注意力、“编码器-解码器”注意力和基于位置的前馈网络。
class DecoderBlock(nn.Module):
"""解码器中第i个块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, i, **kwargs):
super(DecoderBlock, self).__init__(**kwargs)
print('DecoderBlock __init__:', file=log)
self.i = i
self.attention1 = MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.attention2 = MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm2 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm3 = AddNorm(norm_shape, dropout)
def forward(self, X, state):
enc_outputs, enc_valid_lens = state[0], state[1]
# 训练阶段,输出序列的所有词元都在同一时间处理,
# 因此state[2][self.i]初始化为None。
# 预测阶段,输出序列是通过词元一个接着一个解码的,
# 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示
print('DecoderBlock forward:', file=log)
if state[2][self.i] is None:
key_values = X
else:
key_values = torch.cat((state[2][self.i], X), axis=1)
state[2][self.i] = key_values
if self.training:
batch_size, num_steps, _ = X.shape
# dec_valid_lens的开头:(batch_size,num_steps),
# 其中每一行是[1,2,...,num_steps]
dec_valid_lens = torch.arange(1, num_steps + 1, device=X.device).repeat(batch_size, 1)
else:
dec_valid_lens = None
# 自注意力
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X, X2)
# 编码器-解码器注意力。
# enc_outputs的开头:(batch_size,num_steps,num_hiddens)
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
Z = self.addnorm2(Y, Y2)
return self.addnorm3(Z, self.ffn(Z)), state
class TransformerDecoder(d2l.AttentionDecoder):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block" + str(i),
DecoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, i))
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
return [enc_outputs, enc_valid_lens, [None] * self.num_layers]
def forward(self, X, state):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self._attention_weights = [[None] * len(self.blks) for _ in range(2)]
for i, blk in enumerate(self.blks):
X, state = blk(X, state)
# 解码器自注意力权重
self._attention_weights[0][i] = blk.attention1.attention.attention_weights
# “编码器-解码器”自注意力权重
self._attention_weights[1][i] = blk.attention2.attention.attention_weights
return self.dense(X), state
@property
def attention_weights(self):
return self._attention_weights
# 8.1, 训练
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
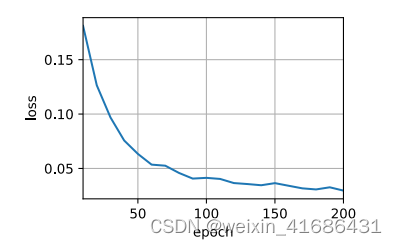
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]
log = open('transformer1.txt', mode='a', encoding='utf-8')
# 8.2, 加载数据集
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = TransformerEncoder(len(src_vocab), key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout)
decoder = TransformerDecoder(len(tgt_vocab), key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
plt.show()