周末大概看了一下最近的vos领域的发展,简单地介绍一下发表于cvpr2022 的这篇工作。
BackGround
VOT和VOS其实是非常相像的,只是target一个是bbox,一个是mask;这篇文章是半监督的VOS,主要是在其他帧中跟踪某一帧的mask。可以简单概括一下半监督vos的几种主流方法:
- Online fine-tuning based methods
顾名思义,先学习一个通用的分割特征,然后在测试阶段将网络在目标视频上进行微调,这是online的方法,后面两种都是offline的方法
- Propagation based methods
以反馈的方式不断微调所得到的mask,从而获取高质量的segmentation mask
- Matching based methods
将一些帧编码为embeddings,将这些embeddings存储到memory bank中,对当前帧进行分割;同时这也是vos的最主流的方向,我猜大概是因为vos的视频片段都很简短吧:)
Motivation
基于Matching based方法会有如下的几个缺点:
- 随着视频帧数的增加,硬件负担不起不断增长的内存需求
- 存储大量的数据不可避免会带来大量的噪声,这并不利于读取重要的信息
Method
在STM 中,image和mask分别被encode到两个embedding spaces中,分别是key和value,将以前所有帧都做这样的处理后concat到一起,输入到Space-time Memory Read中,当前帧通过encoder编码为Query embedding,和之前得到的embedding进行交互,将输出结果送入到Decoder中和Image共同进行分割得到最后的分割结果
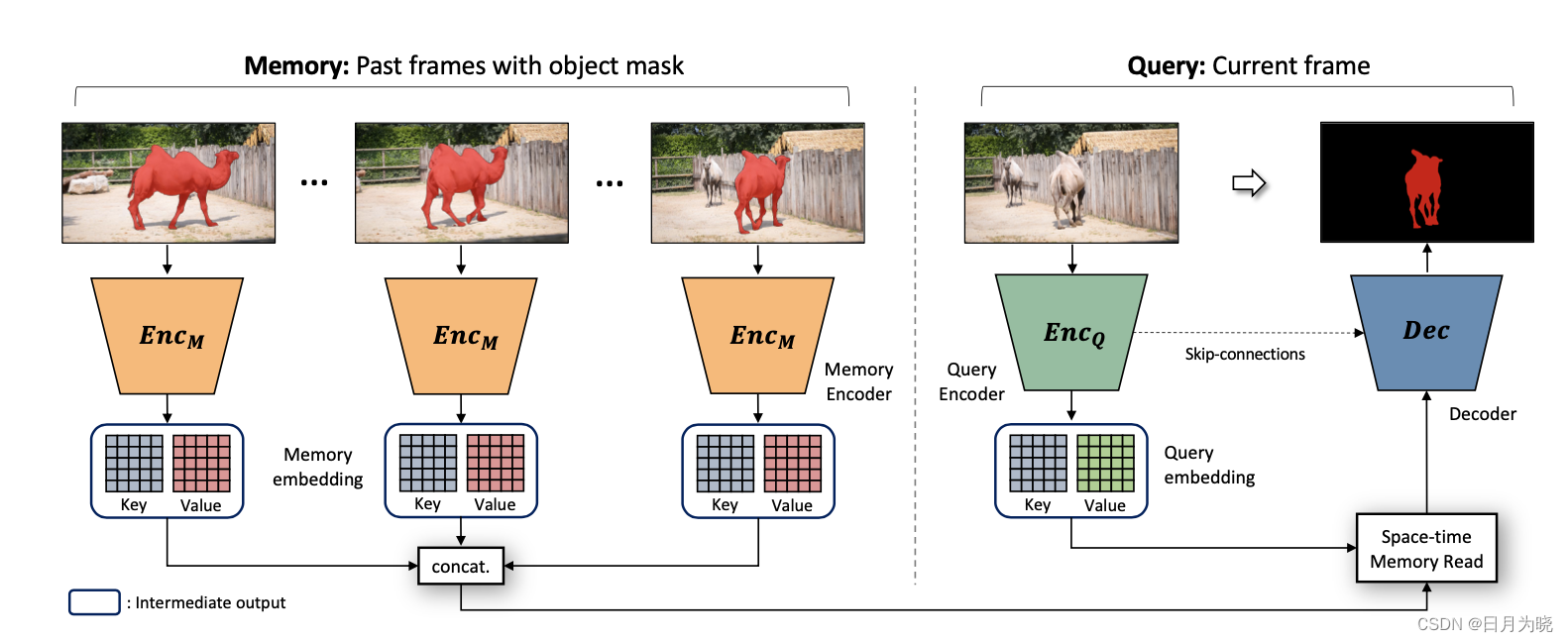
Space-time Memory Read
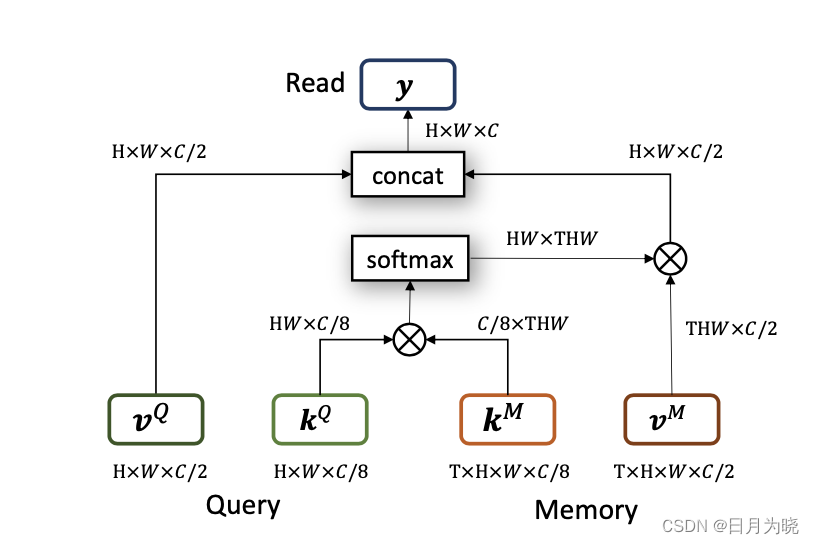
该结构中,将
k
Q
k^Q
kQ 和
k
M
k^M
kM 进行矩阵乘法,经过softmax后和
v
M
v^M
vM进行矩阵乘法,和
v
Q
v^Q
vQ concat到一起后作为输出。这一块应该是采用了attention的结构,具体的大家可以去看《attention is all you need》
接下来便是这篇论文的核心方法:
Encoders:
模型有两个encoder,一个是Image encoder,一个是mask encoder,都用的是ResNet-50的backbone,最后会简单的将输出映射为两个embeddings,分别得到了两个embedding分别是 k ∈ R C k × H 16 × W 16 \mathbf{k} \in \mathbb{R}^{C_{k} \times \frac{H}{16} \times \frac{W}{16}} k∈RCk×16H×16W 和 v ∈ R C v × H 16 × W 16 \mathbf{v} \in \mathbb{R}^{C_{v} \times \frac{H}{16} \times \frac{W}{16}} v∈RCv×16H×16W,其中 C k C_k Ck=64, C v C_v Cv = 512,这里的结构和STM中一致
Memory Reading and Decoder:
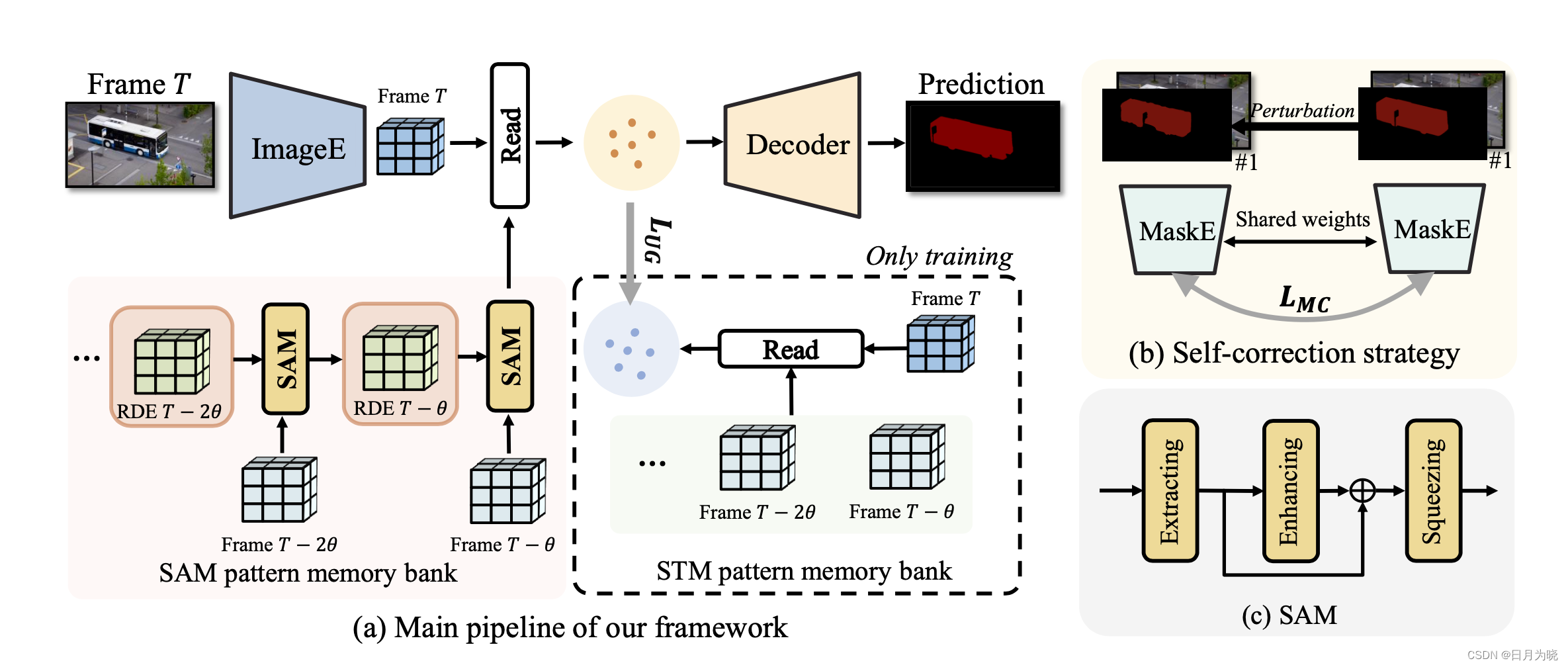
其中包含几个重要的模块,分别是ImageEncoder、Decoder,MaskEncoder,Spatio-temporal Aggregation Module、Spatio-time Memory
ImageEncoder
用于提取图像特征
Decoder
在训练过程中将SAM的输出和Image Encoder的输出以及STM的输出concat到一起输入到Decoder中获取分割mask;在inference过程中去掉STM模块,只保留SAM模块,同训练一样将ImageEncoder的输出和SAM concat到一起输入Decoder获取分割mask
SAM
SAM全称为Spatial-temporal Aggregation Module,这是为了生成以及迭代RDE这个feature的,总共包含三个部分:extracting,enhancing,squeezing,如上述图©
extracting 部分是负责将previous
RDE
{
k
t
−
θ
R
D
E
,
v
t
−
θ
,
i
R
D
E
}
\operatorname{RDE}\left\{\mathbf{k}_{t-\theta}^{R D E}, \mathbf{v}_{t-\theta, i}^{R D E}\right\}
RDE{kt−θRDE,vt−θ,iRDE}和当前帧到embeddings
{
k
t
−
θ
R
D
E
,
v
t
−
θ
,
i
R
D
E
}
\left\{\mathbf{k}_{t-\theta}^{R D E}, \mathbf{v}_{t-\theta, i}^{R D E}\right\}
{kt−θRDE,vt−θ,iRDE}的时空关系组织起来,如下是将
k
R
D
E
k^{RDE}
kRDE和
k
L
k^L
kL在时间维度上连接起来得到特征x
x
=
Cat
(
k
t
−
θ
R
D
E
,
k
t
L
)
,
x
∈
R
C
k
×
2
×
H
16
×
W
16
\mathbf{x}=\operatorname{Cat}\left(\mathbf{k}_{t-\theta}^{R D E}, \mathbf{k}_{t}^{L}\right), \mathbf{x} \in \mathbb{R}^{C_{k} \times 2 \times \frac{H}{16} \times \frac{W}{16}}
x=Cat(kt−θRDE,ktL),x∈RCk×2×16H×16W
接着聚合特征,这篇文章借鉴了attention的结构,先将特征归一化,再使用
w
,
w,
w,
ϕ
\phi
ϕ,
g
g
g,1x1x1的卷积聚合特征,有点像注意力机制,maybe这里是实验为导向的创新,其中
x
↓
\mathbf{x} \downarrow
x↓表示对
x
\mathbf{x}
x进行max-pooling,能够降低计算复杂度
x
a
g
g
=
1
C
(
x
)
ω
(
x
)
T
ϕ
(
x
↓
)
g
(
x
↓
)
\mathbf{x}_{a g g}=\frac{1}{C(\mathbf{x})} \omega(\mathbf{x})^{\mathrm{T}} \phi(\mathbf{x} \downarrow) g(\mathbf{x} \downarrow)
xagg=C(x)1ω(x)Tϕ(x↓)g(x↓)
enhancing部分以残差的方式采用了ASPP的模块对特征
x
a
g
g
x_{agg}
xagg进行了增强,ASPP全称是atrous spatial pyramid pooling,一般也是常用于FPN的最小分辨率层,用以增强特征,这也是一个常用的trick
squeeze部分是将增强后的特征使用2x3x3卷积进行压缩,并维持previous RDE的特征维度
k
t
R
D
E
=
Squeeze
(
x
a
g
g
+
A
S
P
P
(
x
a
g
g
)
)
\mathbf{k}_{t}^{R D E}=\text { Squeeze }\left(\mathbf{x}_{a g g}+A S P P\left(\mathbf{x}_{a g g}\right)\right)
ktRDE= Squeeze (xagg+ASPP(xagg))
Results
在DAVIS2017验证集上的实验结果
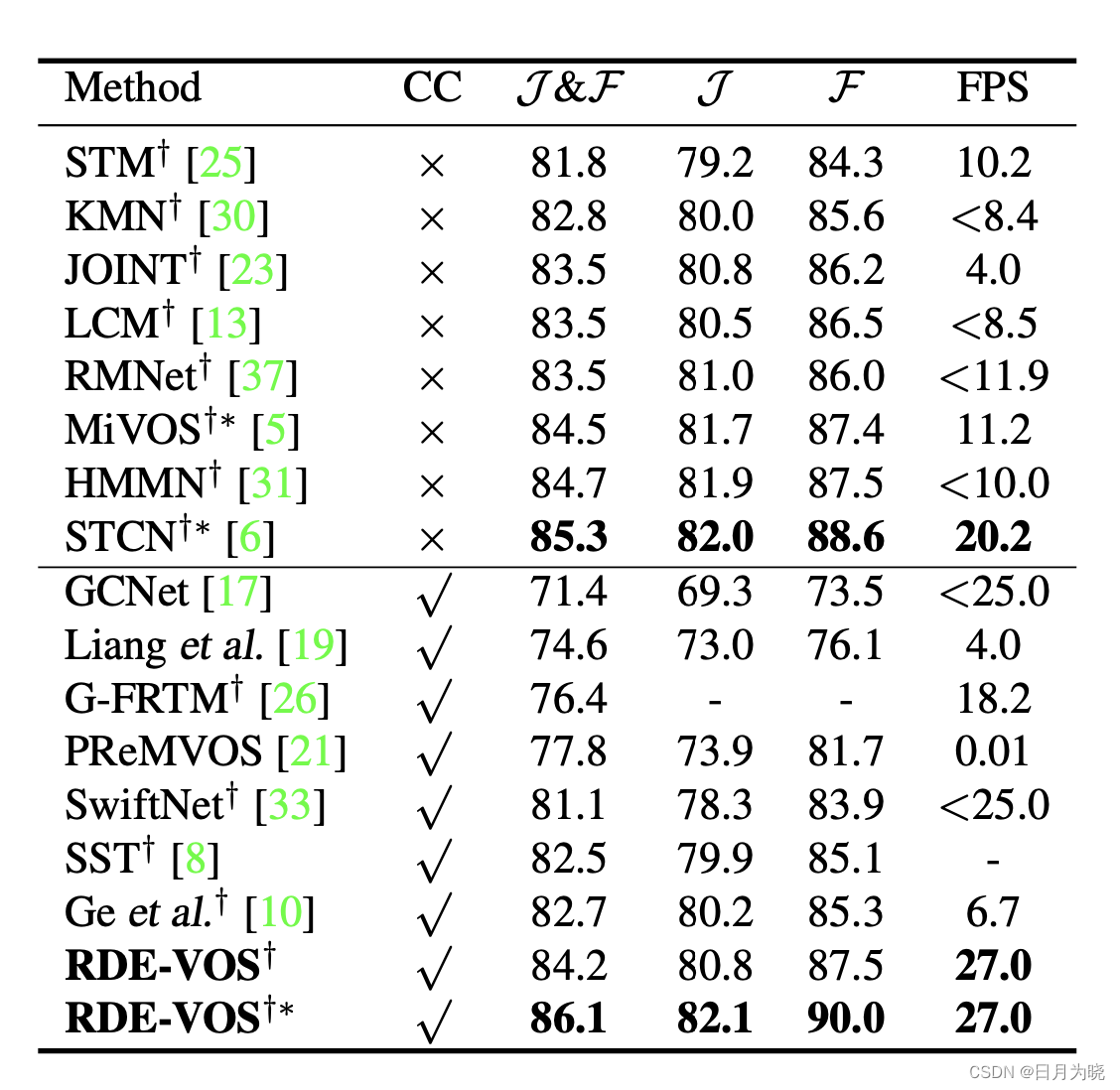
在DAVIS2016验证集上的实验结果
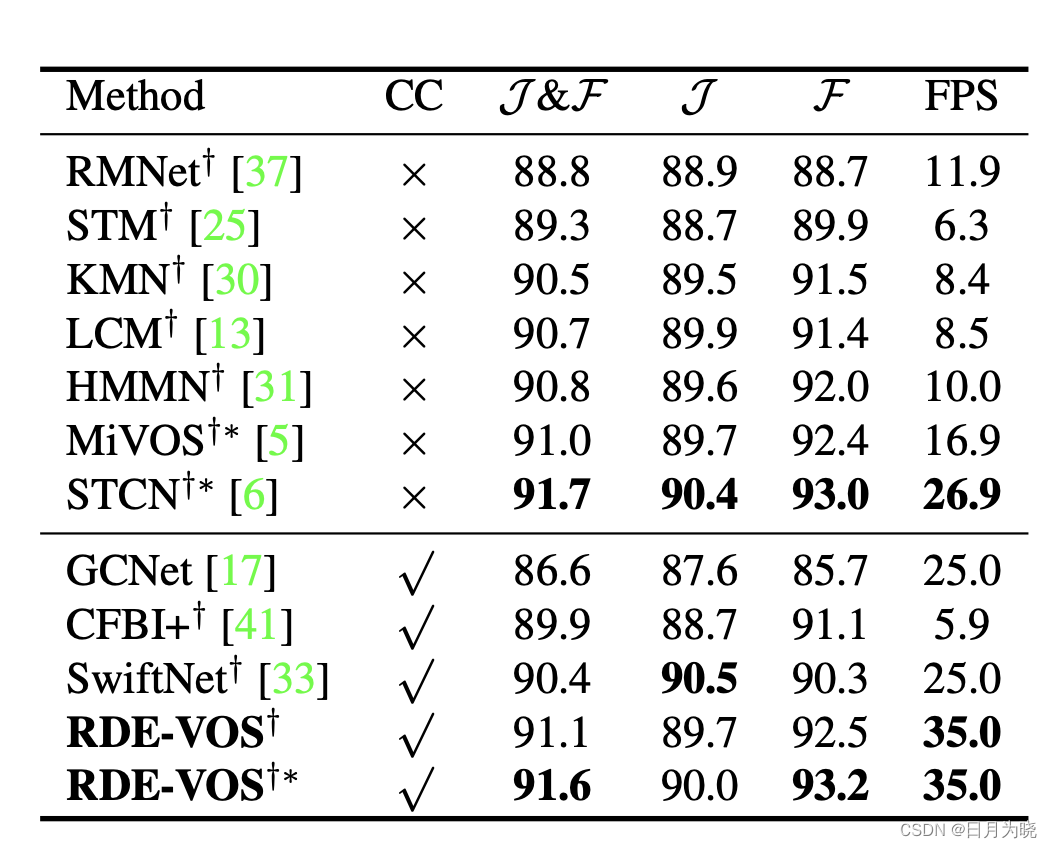
可以看到FPS显著增加,在inference中只保留SAM能够明显加快推理速度,并且其不随着视频序列的长度增加降低速度
Visible Images

Reference
- Li, Mingxing, et al. "Recurrent Dynamic Embedding for Video Object Segmentation."Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
- Oh, Seoung Wug, et al. "Video object segmentation using space-time memory networks."Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
- Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).