新闻分类,或广义上的文本分类,其核心任务是根据文本内容将相似文本聚合在同一类别中。在新闻领域,这意味着将报道划分为财经、体育、军事等不同主题。人类执行此任务时,通过阅读和理解新闻的主旨来进行归类。然而,作者称计算机并不具备真正理解自然语言的能力(尽管有专家声称计算机能够阅读),实际上机器仅依赖于计算文章间的相似度而非理解语义来执行分类。也就是说,计算机只会“计算”文章,而非“阅读”文章。
为了实现文章相似度的计算:
1)首先需要将自然语言写成的文章转换为数字编码,即使用向量表示一篇新闻。
2)然后选择一种能够量化两篇文章相似度的算法进行计算。
3)最后通过这些具体的相似度数值来实现精准分类。
下面以新闻分类的场景进行讲解。
1. 把一篇新闻稿变成一串数字
1.1 特征向量
由于词汇作为信息的核心承载单元,因此我们可以通过对新闻稿中关键性、高信息量的词汇实施数字编码策略,进而将这一系列编码整合为一组数字串,即特征向量。此特征向量能够作为新闻稿的数值化表征,有效地捕捉并反映文章的主旨内容。这一方法的合理性源于语言使用的统计规律:我们来感性理解下,在特定领域内(如金融领域),文章倾向于共享一套核心词汇体系,如“信贷”、“利率”、“经济”、“股票”等高频词汇,这些词汇的使用频率显著高于其他领域的特定词汇(如食品健康领域的“维生素D”、“氨基酸”、“蛋白质”等词汇)。
因此,我们构建的特征向量不仅体现了文章中关键概念的比例权重,还隐含了文章所属领域的特征模式。通过比较不同文章特征向量中对应关键词汇编码的相似度,我们可以量化评估文章之间的内容接近程度,从而将具有相似主题或归属同一类别的文章聚类分析。
说到这里,还记得我们在【搜索引擎的“道”】这篇读书笔记中提到的TF-IDF吗?它的作用就是给每个词打分,告诉我们这个词在文章里有多重要。所以咱们可以把每个词的TF-IDF值当成是它的“数字身份证”,然后给新闻稿里的每个词都发一张(具体TF-IDF值的计算逻辑,请查看以前的读书笔记)。
1.2 特征向量的示例
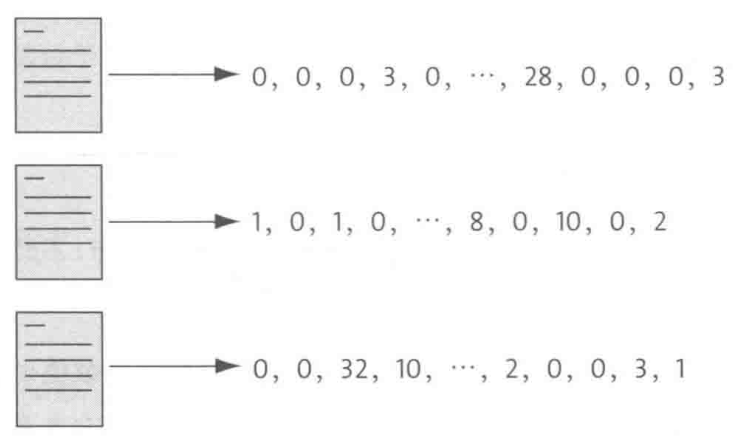
想象一下,我们有个超级大的词汇表,里面有64000个常用汉字和词,它们还都按拼音字母顺序排好了队。

接着,给新闻稿里的每个词都算了TF-IDF分,然后在这个大表里找到它们的位置,把分数填上去。没在新闻稿里露脸的词,就给它们打个0分。

这样一来,新闻稿就变成了一串由TF-IDF分数组成的数字串,就像是我们给新闻稿做的一个“数字画像”,这个就是前面提到的“特征向量”。用这个方法,咱们就能轻松地把一篇篇文字新闻变成一串串数字,让计算机也能“看懂”新闻了。
2. 用余弦定理进行分类
2.1 余弦定理
说实话,中学时候学余弦定理时,我压根没想到它会和新闻稿的分类扯上关系。
现在,咱们手头的新闻稿都化作了特征向量,它们之间的“亲密程度”其实就藏在这些向量的相似度里。而计算这些特征向量的相似度时,余弦定理就派上用场了。数学真奇妙。
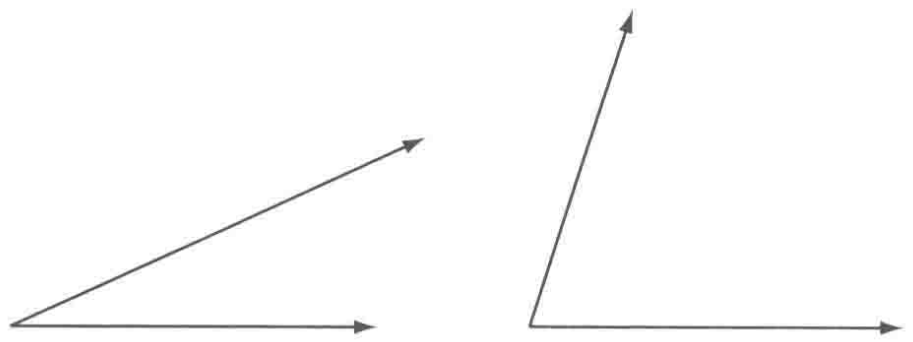
我们先回顾下余弦定理的含义:它描述了三角形中任意一边的平方与另外两边的平方及其夹角余弦值之间的关系。具体来说,对于任意三角形ABC,其中a、b、c分别为三角形的三边,A为边a所对的角,那么余弦定理可以表示为:


如果我们把从角A出发的两条线b和c看做两条向量,那么在向量空间下,余弦定理可以表示为:
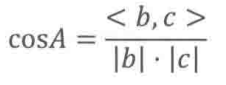
其中 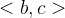

举个例子,如果两篇新闻稿对应的特征向量(对应上面的b和c)分别为:

那么这俩向量的夹角的余弦值为:

2.2 用余弦值来代表相似度
利用余弦定理计算出两个特征向量之间的余弦值后,我们能够直观地评估这两个向量的相似度。
原因在于,余弦值实际上反映了两个向量在方向上的接近程度:当两个向量间的夹角越小,它们的余弦值越接近1,表明这两个向量的方向越趋同。巧的是,在文本分类的语境下,向量的方向往往代表了新闻稿的“内容指向”(即所属类别)。因此,通过比较这些向量间夹角的余弦值,我们能够有效地判断两篇新闻稿在内容上是否倾向于属于同一类别。
这里再提一下,在文本分类的场景下,特征向量里的每个值都是字或词对应的TF-IDF值,又由于TF-IDF的计算方式确保了其值始终为正或零(零值表示该词在文档集中不常见或完全未出现),因此基于TF-IDF构建的特征向量中的每个元素也都是非负的,最终导致余弦值的取值范围就在0到1之间。
-
当余弦值为1时,意味着两个特征向量在方向上完全一致,即它们指向相同的方向。在文本分类的上下文中,这强烈暗示了两篇新闻稿在词汇使用和主题上高度相似,很可能属于同一类别或具有非常接近的主题。
-
相反,当余弦值为0时,表明两个向量完全垂直,即它们在方向上没有任何共同之处。这通常意味着两篇新闻稿在词汇选择、主题表达或信息内容上差异显著,几乎可以断定它们属于不同的类别或讨论完全不相关的主题。
2.3 简化计算量和提高分类质量的方法
2.3.1 向量长度不用重复计算(简化计算量)
在实际应用中,面对成千上万待分类的新闻稿,其对应的特征向量数量庞大,若直接两两计算这些特征向量之间的余弦相似度,将导致计算量急剧增加。为了优化这一过程,一个容易想到的方法就是预先计算并存储每个特征向量的模长(即余弦公式中的分母部分),这样,在后续计算余弦相似度时,可直接调用这些预存模长,避免了重复计算向量长度的开销,从而显著减少总体计算量,提高处理效率。
2.3.2 计算内积只考虑非零元素(简化计算量)
在优化分母部分之后,针对分子部分的计算同样可以进行优化。在文本分类的场景中,由于每篇文章使用的词汇相对于整个词汇表而言非常有限,导致对应的特征向量高度稀疏,即包含大量零值。针对这一特性,我们可以仅计算两个向量中对应两侧均为非零元素的乘积,并求和,以得出内积。这一过程可以通过高效的算法来识别并仅处理非零元素的位置,如利用稀疏矩阵的存储和计算技巧(如压缩稀疏行/列格式等),这样的优化策略能够大幅减少不必要的计算量。
2.3.4 删除一些没意义的虚词(简化计算量&提高分类质量)
在之前的读书笔记中,多次提及诸如【的、地、得、是、和】等虚词,在凸显文章中心思想时其作用微乎其微,甚至可能被视为“噪音”。因此,在构建特征向量时,剔除这些虚词不仅有助于提升文本分类的精度,还能有效减少计算过程中的冗余,从而提高整体效率。
2.3.5 位置的加权(提高分类质量)
通常而言,文章标题、开篇与结尾段落,以及各段落的首句,在表达文章主旨时扮演着更为关键的角色。鉴于此,对于出现在这些关键位置上的词汇,我们可以适当提高其权重,以此强化它们对分类结果的贡献,从而使得最终的分类判断更为准确。
2.4 基于相似度进行分类
当前,我们已经知道了如何计算每两篇新闻稿之间的相似度了。接下来,关于如何进行分类,存在两种情境,可以直观地划分为“有参照分类”与“无参照分类”两种模式。
2.4.1 有参照分类
在“有参照”分类的情形下,核心在于存在一个基准向量,该向量精准捕捉了某一类别新闻(如金融类)的鲜明特征。通过将待分类新闻稿的特征向量与此基准向量进行相似度比对,若相似度超过预设的阈值,则该新闻稿即被归入相应类别。此方法直观且高效,但其关键在于基准向量的精确选择与构建。
书中作者未详述基准向量的构建方法,但经过翻看其他资料,可归纳出几种常见的策略:一是基于专家知识,由领域内专家手动定义基准向量的各维度特征;二是采用聚类算法,从已标记的新闻数据集中自动提取某一类别的中心向量作为基准;三是利用机器学习或深度学习模型,通过训练过程学习并生成能够代表特定类别的基准向量。
2.4.2 无参照分类
在“无参照”分类的情形中,这一过程本质上与机器学习领域的聚类算法相契合。鉴于缺乏预定义的基准向量,系统通过计算所有特征向量之间的相似度,并依据设定的相似度阈值,自动将相互间相似度高的文章聚合成不同的子类别。
这一过程可迭代进行:对于每个生成的子类别,我们可以再次应用相同的聚类方法,构建其对应的代表性特征向量,并基于这些特征向量进一步细分子类别。如此循环往复,直至所有文章均被归入某一类别,或达到预设的停止条件,比如当类别总数减少至预设的阈值(如5个或更少)时,迭代过程终止。这种层次化的聚类方法有助于揭示新闻稿之间的复杂关联与结构。

3. 用奇异值分解进行分类
在利用余弦值进行分类的方法中,尽管其原理直观易懂,但在实际操作中,尤其是在处理大规模数据集且没有预定义基准向量的“无参照”分类场景下,计算复杂度显著上升,对计算资源提出了较高要求。为了应对这一挑战,线性代数中的奇异值分解(Singular Value Decomposition, SVD)技术便显得尤为重要。
3.1 定义
具体来说,对于任意一个 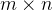
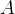

其中 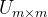
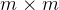
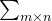

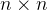
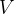
又因为奇异值可作为降维的判断依据,因此可以通过只保留前 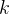

因为 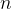

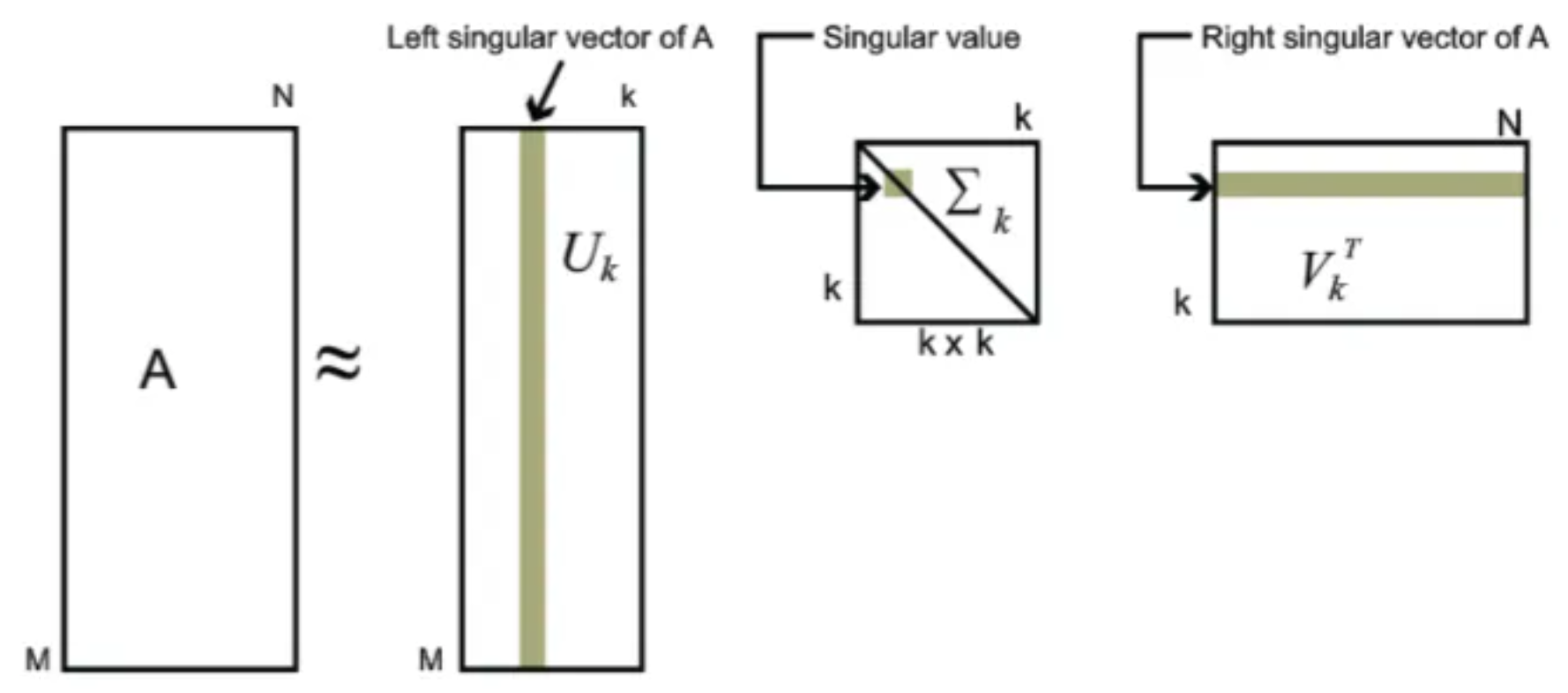
3.2 在文本分类里的作用
如下图所示,在这个矩阵中,每一行对应一篇文章,每一列对应一个词,如果有 

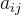

假设上面的
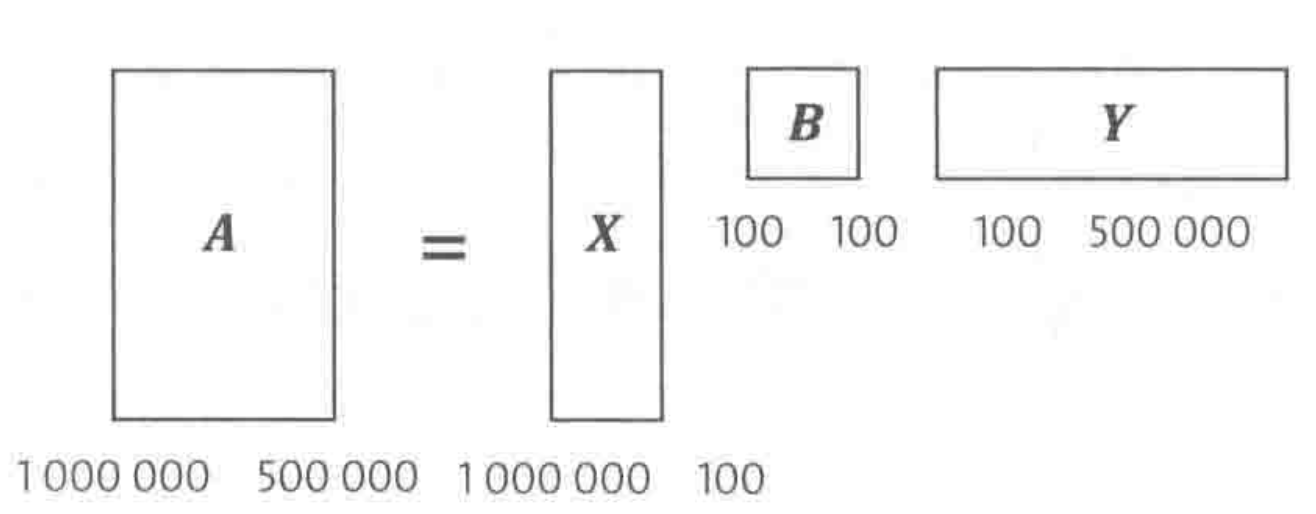
矩阵 
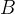
可以看到,只需对矩阵
在分类任务中,当采用余弦定理进行分类时,尤其是无参考分类场景下,往往需经历多轮迭代以优化分类效果,这一过程相对复杂且耗时。相比之下,奇异值分解(SVD)以其单次计算即可完成分解的优势,无需迭代过程,使得其应用更为高效、直接。
4. 余弦定理与奇异值分解的关系
读到这里,面对SVD的高效与直接性,部分同学或许会质疑余弦定理的必要性?然而,需明确的是,SVD虽无需迭代、计算快捷,但其分类精度相对粗略。
作者建议了一种高效策略:首先利用SVD进行初步分类,以快速缩小范围(达到降维的作用);随后,基于这些粗分类结果,采用计算向量余弦的方法进行精细调整,通过少数几轮迭代,实现分类精度的显著提升。这种策略巧妙结合了SVD的速度优势和余弦定理的精度优势,既缩短了整体处理时间,又确保了分类结果的准确性。