哈喽,大家好,我是Leven, 今天我们花点时间初步了解大数据计算引擎Spark ,也是我们从事数据工作中肯定会用到计算引擎。文章中有书写错误的内容,辛苦评论指正,感谢🙏
1. Spark 简介
Apache Spark 是一个开源的大数据处理引擎,设计用于快速处理大规模的数据集。Spark 提供了比传统的 Hadoop MapReduce 更高效的计算能力,支持批处理、流处理、交互式查询和机器学习等多种大数据处理任务。它广泛应用于大数据分析和处理领域。
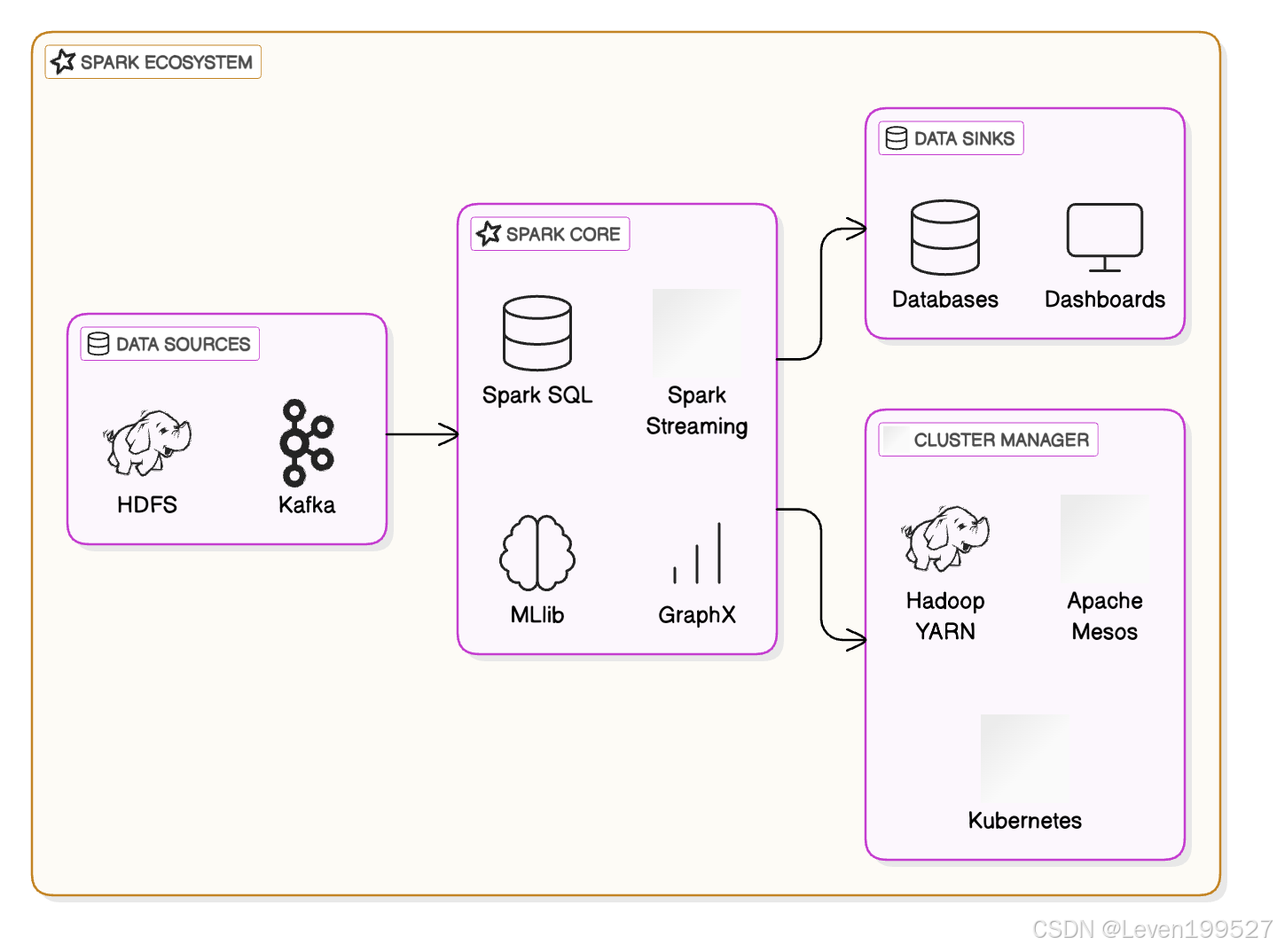
2. Spark 特点
-
内存计算(In-Memory Computation):Spark 通过将中间计算结果存储在内存中,而不是像 Hadoop 那样将数据频繁地写入磁盘,显著提高了计算速度。
-
统一的大数据处理引擎:Spark 支持批处理(Batch Processing)和流处理(Stream Processing)两种计算模型。Spark Streaming 是其扩展模块,可以处理实时数据流。
-
高层 API:Spark 提供了多种 API,支持 Python(PySpark)、Java、Scala 和 R 编程语言,方便用户根据自己的需求选择适合的开发语言。
-
强大的计算引擎:Spark 的核心是一个分布式计算引擎,能够处理大规模数据集并支持诸如 SQL 查询、机器学习(MLlib)、图形计算(GraphX)等高级功能。
-
容错性:Spark 内置了数据的容错机制,通过数据副本(RDD:Resilient Distributed Datasets)来确保在节点失败时不会丢失数据。
3. Spark 发展历史
1. 起源与早期开发(2009 - 2010)
- 2009年:Spark由Matei Zaharia在加州大学伯克利分校的AMPLab发起,最初的目的是为了解决Hadoop MapReduce在某些工作负载(特别是机器学习、图计算和交互式查询)上的性能瓶颈。
- 2010年:Spark的第一个版本正式发布,支持内存计算,显著提升了在迭代计算(例如机器学习算法)中的性能。Spark相较于传统的MapReduce框架,可以将中间结果保存在内存中,而不是写入磁盘,减少了I/O操作的开销。
2. Apache Incubator与开源(2010 - 2014)
- 2010年:Spark项目加入Apache软件基金会的孵化器(Apache Incubator)。这一阶段,Spark逐渐从一个实验性项目转向一个稳定的开源框架,并开始获得越来越多的贡献。
- 2012年:Spark逐渐成熟,开始支持更多的数据处理功能,比如数据流(Streaming)和图计算(GraphX)。在这一年,Spark的第一个稳定版本(1.0)发布。
- 2013年:Apache Spark成为一个顶级项目(Top-level Project),这标志着它从Apache孵化器正式毕业,成为Apache Software Foundation的一个正式项目,开始获得更广泛的社区支持和企业采用。
3. 扩展与功能增强(2014 - 2017)
-
2014年:
- Spark SQL被引入,允许Spark通过结构化数据进行SQL查询。这是Spark发展的一大突破,标志着它不仅限于传统的MapReduce计算,还能够支持结构化数据分析。
- MLlib和GraphX的功能进一步得到完善,机器学习库和图计算库被广泛应用。
-
2015年:Spark 1.4发布,增加了对JSON数据格式的支持,进一步增强了其在大数据处理中的通用性。同时,Spark Streaming也不断得到优化,使得Spark在实时数据处理中的能力更加完善。
-
2016年:
- Spark 2.0发布,带来了几项重要的新特性,包括:
- Dataset API:提供了结构化数据的高级抽象,可以在类型安全和性能上提供更好的优化。
- Spark SQL优化器(Catalyst Optimizer):引入了一个新的查询优化器,能够显著提高SQL查询的性能。
- 统一的批处理和流处理:Spark 2.0中的Structured Streaming引入了流处理的统一API,使得流式处理和批处理之间的区别变得模糊。
- Spark 2.0发布,带来了几项重要的新特性,包括:
-
2017年:Spark 2.2和2.3版本进一步增强了性能和对数据源的支持,特别是在运行时优化、扩展性和易用性方面。
4. Spark生态系统的成熟与企业采用(2018 - 至今)
-
2018年:Spark持续成熟,成为大数据和机器学习领域的核心技术之一。它被广泛应用于企业的数据处理、机器学习和数据分析任务。
-
2019年:Apache Spark 3.0发布,包含以下几个重要更新:
- Adaptive Query Execution (AQE):引入了适应性查询执行,进一步提升了Spark SQL的性能。
- 支持更多的云计算平台和存储系统:提升了对云平台(如AWS、Azure、Google Cloud)的集成支持,方便用户在云环境中进行大规模数据处理。
- Python API增强:对PySpark(Spark的Python接口)进行了许多增强,提升了Python用户的体验。
-
2020年:
- Spark 3.x继续扩展,增加了对新型数据源和计算模型的支持,同时提升了与其他数据处理框架(如TensorFlow、Hadoop)的集成性。
- 由于其强大的数据处理能力和良好的易用性,Spark在许多云平台(如Databricks)中成为默认的大数据处理引擎。
5. Spark的未来(2021 - 至今)
- 持续创新:Spark继续优化性能和扩展功能,如在机器学习、图计算、实时流处理等领域增强其能力。随着人工智能和大数据分析需求的增长,Spark的生态系统越来越丰富,支持更多的AI/ML框架与工具。
- 云原生化:随着容器化和云计算的普及,Spark越来越多地与云原生架构兼容,成为现代数据处理平台的重要组成部分。
4. Spark 架构
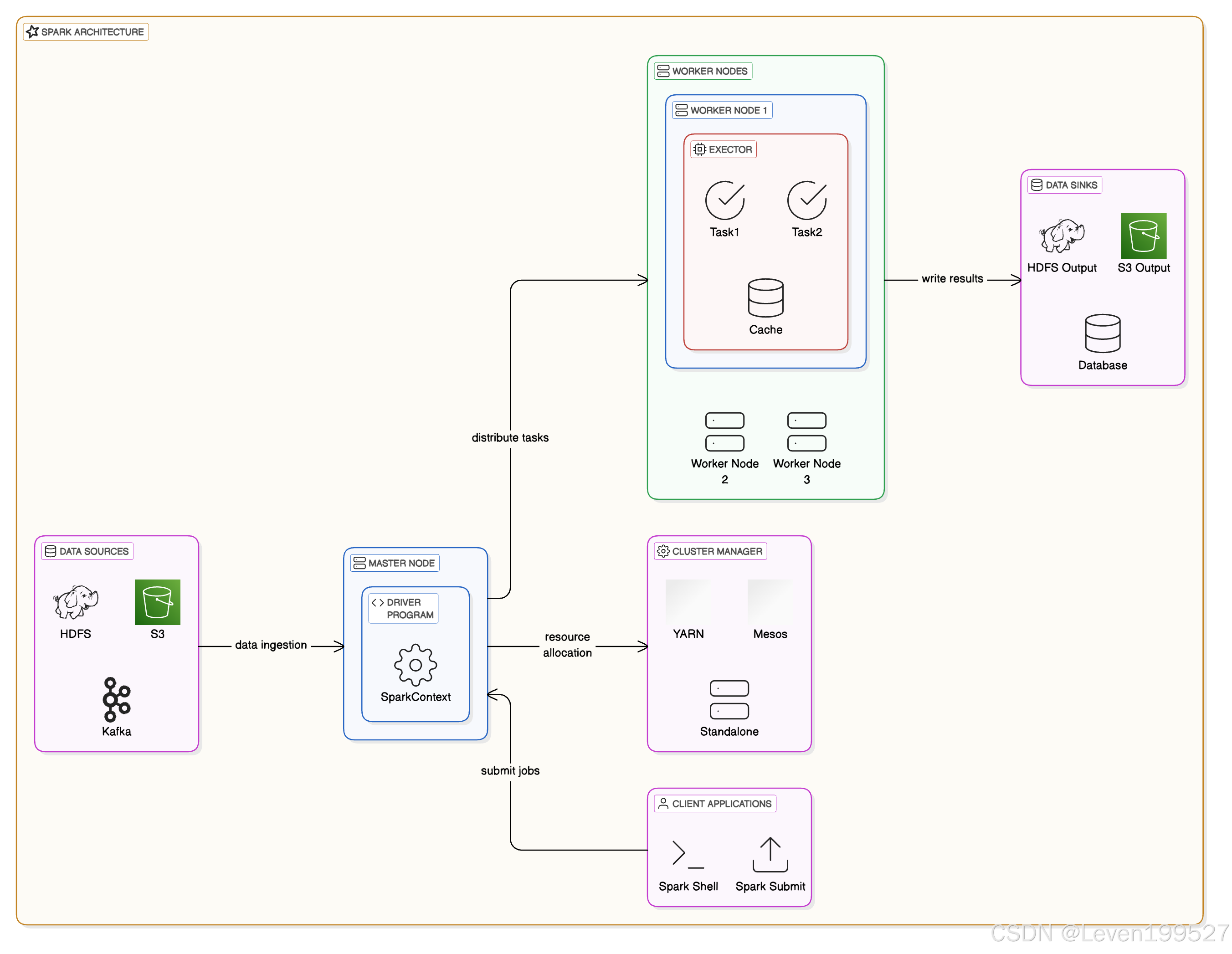
-
Driver (驱动程序)
- 角色:Driver 是 Spark 程序的控制器,负责协调 Spark 作业的执行。
- 功能:它将应用程序的所有任务分配给集群中的各个 Executor,并负责执行 Spark 程序的逻辑。Driver 还负责维护 Spark 应用程序的元数据,包括RDD和DataFrame等。
- 运行环境:通常是用户提交任务的本地机器或集群的一个节点。
-
Cluster Manager (集群管理器)
- 角色:Cluster Manager 负责管理集群资源的分配和调度任务。它决定哪些节点执行哪些任务,并对集群资源进行动态调度。
- 常见集群管理器:
- Standalone:Spark 自带的集群管理器。
- YARN:Hadoop 的集群资源管理器,适用于 Hadoop 集群中的 Spark 部署。
- Mesos:一个开源的集群资源管理平台,可以管理多种框架(如 Spark、Hadoop、Kafka 等)上的资源。
-
Executor (执行器)
- 角色:Executor 是 Spark 集群中的工作节点,负责运行 Driver 分配的计算任务,并保存该任务的计算结果(例如 RDD 数据)。每个 Executor 运行在单独的工作节点上。
- 功能:负责执行实际的数据处理任务,执行计算并存储中间结果。在任务执行过程中,Executor 会返回计算结果并处理来自 Driver 的请求。
- 生命周期:Executor 在 Spark 应用运行时启动,并在 Spark 应用结束时关闭。
-
Task (任务)
- 角色:Task 是 Spark 中最小的执行单元,每个 Task 负责执行一个数据分区的计算。Spark 作业被分解成多个任务,这些任务被分配到各个 Executor 上执行。
- 任务划分:每个 Stage 都会被分割成多个 Task,通常 Task 是根据 RDD 的分区来分配的。
-
Spark Context (Spark 上下文)
- 角色:SparkContext 是 Spark 应用程序的入口,负责连接到 Spark 集群,并初始化 Executor、Driver 和其他系统组件。所有 Spark 作业都需要通过 SparkContext 来访问。
- 功能:它为应用程序提供了访问 Spark 功能的接口,包括创建 RDD、广播变量、累加器等。
5. Spark vs MapReduce
1. 性能
-
Spark:
Spark 的性能远高于 MapReduce,因为它在内存中处理数据(RAM)。一旦数据被加载到内存中,它可以更快地访问和处理,而不像 MapReduce 每次操作都需要从磁盘读取数据。特别对于需要多次迭代的算法(如机器学习和图处理),Spark 的速度优势更为明显。- 内存计算:Spark 将中间结果缓存到内存中,从而减少磁盘 I/O,提高处理速度。
-
MapReduce:
MapReduce 在处理时采用“从磁盘读取、处理、写回磁盘”的模式。由于高度依赖磁盘 I/O,MapReduce 的速度较慢,尤其是在需要多个处理阶段(例如迭代算法)的情况下。- 磁盘计算:MapReduce 的每个阶段(Map 和 Reduce)都需要将中间数据写入磁盘并读取,这造成了性能瓶颈。
- 较高的开销:由于需要多次进行磁盘 I/O,MapReduce 的作业往往具有更高的开销,尤其是在处理大数据时。
2. 易用性
-
Spark:
Spark 提供了高级 API,支持 Java、Scala、Python 和 R 等语言,编写和维护 Spark 程序变得更加容易。它采用了与常规编程语言中集合操作类似的 函数式编程 模型。- 高级库:Spark 提供了丰富的高级库,如 机器学习 (MLlib)、SQL (Spark SQL)、图处理 (GraphX) 和 流处理 (Spark Streaming)。
- 交互式 API:Spark 支持交互式的 Shell(如 PySpark 用于 Python,SparkShell 用于 Scala),允许实时探索数据和测试命令。
-
MapReduce:
MapReduce 更为底层且冗长。编写 MapReduce 作业通常需要单独编写 Map 和 Reduce 函数,并且管理数据在各阶段的洗牌操作。相对而言,它的开发和调试更为困难。- 有限的库:MapReduce 缺乏像 Spark 这样的机器学习和图处理等高级库,因此编写复杂的应用程序变得更加困难。
- 没有交互性:MapReduce 没有交互式 Shell,无法像 Spark 那样实时测试命令或探索数据。
3. 数据处理模型
-
Spark:
Spark 采用 弹性分布式数据集(RDD) 抽象,RDD 是一种容错的、分布式的数据集合,可以并行处理数据。RDD 可以通过转换操作和动作操作进行处理。- RDDs:RDD 是不可变的,操作(如 map、filter 和 reduce)是惰性计算的,只有在执行动作(如 collect 或 save)时才会触发实际计算。
- DataFrame 和 Dataset:Spark 还提供了 DataFrame 和 Dataset 等更高级的抽象,支持 SQL 类操作并进行优化。
-
MapReduce:
MapReduce 通过两个主要阶段来处理数据:Map 阶段和 Reduce 阶段。Map 阶段读取输入数据并生成键值对,而 Reduce 阶段对这些键值对进行计算并写出输出。- Map 和 Reduce 操作:数据在 Map 阶段进行转换,在 Reduce 阶段进行合并和处理。
- 没有类似 RDD 的内存数据结构:MapReduce 没有像 RDD 那样的抽象来保持中间数据在内存中的状态,导致每次都需要从磁盘读取。
4. 容错性
-
Spark:
Spark 高度容错。如果某个任务失败,Spark 可以通过 RDD 血缘信息(lineage)重新计算丢失的数据。RDD 会记录所有的转换操作,允许系统在数据丢失时通过重新计算来恢复。- RDD lineage:如果某个 RDD 分区丢失,Spark 可以基于原始数据和血缘信息重新计算丢失的部分。
-
MapReduce:
MapReduce 也具有容错机制,通常通过 HDFS(Hadoop 分布式文件系统) 来进行数据复制。如果任务失败,MapReduce 会将任务分配给其他节点并重新处理数据。- 任务重试:MapReduce 任务通常会进行多次重试,以确保任务最终成功执行。
5. 可扩展性
-
Spark:
Spark 能够良好地扩展到多节点,并且能够处理 PB 级的数据。它可以运行在任何 Hadoop 集群中,也可以在独立模式下运行,并且与 YARN 或 Mesos 等资源管理器无缝集成。 -
MapReduce:
MapReduce 也具备高度的可扩展性,能够处理大规模的数据,适用于分布式环境。它在处理批量数据时表现较好,但对于需要低延迟或迭代计算的任务可能表现不佳。
6. 实时数据处理
-
Spark:
Spark 相较于 MapReduce 的一个重要优势是它支持 实时数据处理。通过 Spark Streaming,Spark 可以对实时数据流进行处理,将数据流切分成小批次进行处理,实现近实时的处理。- 低延迟处理:Spark 支持统一的批处理和流处理框架,可以处理流数据和批数据。
-
MapReduce:
MapReduce 不支持实时数据处理。它是面向批量处理的,意味着它处理的是静态的大规模数据。尽管可以借助 Apache Kafka 和 HBase 等其他系统实现某种程度的实时处理,但 MapReduce 本身并不原生支持实时流处理。
7. 生态系统集成
-
Spark:
Spark 拥有丰富的生态系统,能够与其他大数据技术(如 Hadoop HDFS、Hive、HBase、Cassandra、Kafka、S3 等)无缝集成。它还支持多种数据源的连接,包括关系型数据库和 NoSQL 数据库。- 统一平台:Spark 提供了一个统一的处理平台,支持批处理、流处理、机器学习和图处理。
-
MapReduce:
MapReduce 紧密结合 Hadoop 使用,通常依赖 HDFS 来存储数据。它可以与 Hadoop 生态系统中的其他工具(如 Hive、HBase 和 Pig)一起使用,但没有 Spark 那样丰富的集成支持。
8. 成本与资源利用
-
Spark:
由于 Spark 采用内存计算模型,它的硬件要求比 MapReduce 更高,尤其需要更多的内存资源。然而,由于处理速度更快,Spark 通常能在较短时间内完成作业,因此在计算时间上节省成本。 -
MapReduce:
MapReduce 在 CPU 和磁盘使用上通常更节省资源,适用于一些简单任务。然而,由于其较慢的处理速度,长时间运行的作业可能会导致基础设施成本较高。
| 特性 | Spark | MapReduce |
|---|---|---|
| 速度 | 因为内存计算较快 | 由于磁盘计算较慢 |
| 编程模型 | 高级 API 支持 Java、Scala、Python | 低级 Java API |
| 容错性 | 基于 RDD 血缘信息恢复丢失数据 | 任务重试和 HDFS 数据复制 |
| 易用性 | 提供丰富的高级库,易用性更高 | 底层编程,较为困难 |
| 实时处理 | 支持实时数据处理(Spark Streaming) | 不支持原生实时数据处理 |
| 数据处理 | 支持批处理和流处理 | 仅支持批处理 |
| 库支持 | 提供 MLlib、GraphX、Spark SQL 等库 | 缺乏机器学习、图处理等高级库 |
| 可扩展性 | 高度可扩展,支持多个节点 | 可扩展,但对迭代计算和低延迟处理支持差 |