哈喽,大家好,我是Leven, 在上一篇数据仓库(一):概述和大家普及了一些数据仓库中的基本概念,那么这篇文章我们详细说一说维度建模。
我们先来聊一个 ER关系图,也就是实体-关系模型,我相信大家对这个都比较清楚,但有时候会存在一个误区,就是将实体-关系等价于范式建模,其实维度建模也是可以使用ER关系图,只是与范式建模的区别在于规范化的程度而已。所以不要将ER模型当成范式建模,它只是我们在建模中具体落实的一种建模方法。维度建模的过程中也是需要梳理实体与实体间的关系,请注意这一点。这个观点在Kimball《数据仓库工具箱——维度建模权威指南》也是有表达:
The industry sometimes refers to 3NF models as entity-relationship (ER) models. Entity-relationship diagrams (ER diagrams or ERDs) are drawings that communicate the relationships between tables. Both 3NF and dimensional models can be represented in ERDs because both consist of joined relational tables; the key difference between 3NF and dimensional models is the degree of normalization. Because both model types can be presented as ERDs, we refrain from referring to 3NF models as ER models; instead, we call them normalized models to minimize confusion
注:这里有需要数据仓库工具箱英文版PDF和阿里大数据实践之路的PDF可以随时私信我领取
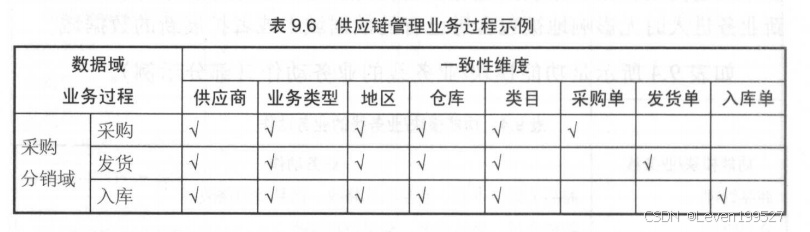
1 总线矩阵
总线矩阵是一个二维表格,其中:
- 行(横轴) 表示企业中的业务过程(Business Process)。
- 列(纵轴) 表示数据仓库中的共享维度(Shared Dimensions)。
- 矩阵的交叉点表示某个业务过程是否使用某个共享维度。
它提供了一个高层次的视图,展示了哪些业务过程需要哪些共享维度,帮助确保不同业务过程可以一致地使用同一维度。
下图是《阿里大数据实践之路》给到的一个总线矩阵示例:
2 事实表
2.1 基本概念
2.1.1 粒度
在Kimball 数据仓库工具箱有这样的一句话:
The idea that a measurement event in the physical world has a one-to-one relationship to a single row in the corresponding fact table is a bedrock principle for dimensional modeling. Everything else builds from this foundation.
这句话充分说明了事实表是对现实世界某个事件的描述,这个事件所表达业务细节的程度称之为粒度。
2.1.2 业务过程
数据仓库工具箱对于业务过程的描述:
Business processes are the operational activities performed by your organization, such as taking an order, processing an insurance claim, registering students for a class, or snapshotting every account each month. Business process events generate or capture performance metrics that translate into facts in a fact table. Most fact tables focus on the results of a single business process. Choosing the process is important because it defi nes a specifi c design target and allows the grain, dimensions, and facts to be declared. Each business process corresponds to a row in the enterprise data warehouse bus matrix.
其实是晦涩难懂的。但其实其本质表达的意思也是事件,因为事实表的每一行就是对一个事件描述。同时我们再看阿里大数据实践之路对于业务过程的描述:
业务过程可以概括为一个个不可拆分的行为事件,如下单、支付、退款等
也是表达了同样的观点。
2.3 事实表类型
事实表主要分为三种类型:
1. 事务型事实表(Transactional Fact Table)
事务型事实表存储的是针对某个特定业务事件或操作的详细数据。这些表的粒度通常是单个事务或事务行。
-
特点:
- 存储的是最细粒度的数据,通常与单个交易或事件对应。
- 每一行代表一个具体的业务事件(如一次订单、一次交易、一次访问等)。
- 主要包含度量数据(如金额、数量)和外键(指向维度表)。
-
示例:
- 订单事实表:每一行表示一个订单项,包含订单编号、产品ID、客户ID、时间ID、数量、金额等度量。
订单ID 产品ID 客户ID 销售日期 数量 金额 1001 200 301 2025-01-01 2 50 1002 201 302 2025-01-02 1 25
2. 周期型事实表(Periodic Snapshot Fact Table)
周期型事实表记录的是在某一时间点或时间区间内的数据快照。这些表的粒度通常是周期性地反映某个业务的状态,通常是按天、周、月或季度存储数据。
-
特点:
- 存储的是某一时间点或时间段的汇总数据。
- 每一行代表某一业务过程在某一时间点的快照(例如每日账户余额、每月库存水平等)。
- 适合记录类似账户余额、库存水平等的度量,通常不涉及单个交易。
-
示例:
- 账户余额事实表:每一行记录某一时点的账户余额。
客户ID 日期 账户余额 301 2025-01-01 1000 302 2025-01-02 1500
3. 累积型事实表(Cumulative Snapshot Fact Table)
累积型事实表记录的是一个业务过程从开始到结束的累计数据。这类表通常用于描述一个实体的整个生命周期,例如订单从创建到完成的所有状态变化。
-
特点:
- 存储的是某个过程的累积信息,记录过程的多种状态变化。
- 例如,订单生命周期中的不同状态:从订单创建、发货、付款到订单完成等。
- 适合记录订单的各个阶段或产品生命周期的各个阶段。
-
示例:
- 订单进度事实表:记录一个订单从创建到发货、到收货等不同阶段的累计状态。
订单ID 创建日期 发货日期 收货日期 订单状态 累计销售额 1001 2025-01-01 2025-01-02 2025-01-05 完成 200 1002 2025-01-03 2025-01-04 处理中 100
2.4 事实表设计原则
在《阿里大数据实践之路》中,事实表的设计包含以下8个原则:
原则 1:尽量涵盖所有与业务过程相关的事实
在设计事实表时,应尽可能地包含所有能够体现业务过程的事实数据。全面的事实数据有助于在后期的查询和分析中提供更为丰富的视角。
原则 2:只选择与业务过程紧密相关的事实
在选择事实时,必须确保其与具体的业务过程密切相关。避免将无关的或不重要的数据引入事实表,这样可以保持事实表的简洁性和聚焦度。
原则 3:分解不可加的事实为可加的组件
对于一些不可直接聚合(不可加)的事实,应将其拆分为可加的组件。这样能够提高数据的分析和汇总能力,避免因复杂的聚合逻辑影响查询性能。
原则 4:在选择维度和事实之前,首先明确粒度
粒度是事实表设计的核心,必须先明确粒度的定义。粒度决定了事实表中每一行记录代表的具体业务事件或事务的详细程度,进而影响数据的存储、查询和分析。
原则 5:同一事实表中不能混合不同粒度的事实
为了保证查询的一致性和高效性,同一个事实表中不应包含多个粒度的事实。如果粒度不同,建议将其拆分为多个事实表,避免混淆和复杂的查询逻辑。
原则 6:确保事实单位的一致性
事实表中的度量数据应该采用统一的度量单位。无论是数量、金额还是其他度量,保持一致性可以避免后续分析中的混乱,并确保计算的准确性。
原则 7:妥善处理事实表中的 NULL 值
在事实表中出现 NULL 值时,需要做好处理。NULL 值可能代表缺失的数据、未发生的事件或无法获取的值,适当的处理方式能提高数据质量,避免影响后续的数据分析。
原则 8:使用退化维度提高事实表的可用性
在Kimball维度建模中,通常按照星形模型的方式来设计,对于 维度的获取采用的是通过事实表的外键关联专门的维表的方式,谨慎使 用退化维度。而在大数据领域的事实表设计中,则大量采用退化维度的 方式,在事实表中存储各种类型的常用维度信息。这样设计的目的主要 是为了减少下游用户使用时关联多个表的操作,直接通过退化维度实现 对事实表的过滤查询、控制聚合层次、排序数据以及定义主从关系等。 通过增加冗余存储的方式减少计算开销,提高使用效率。
Kimball 在《数据仓库工具箱中》中对于退化维度的定义:
Sometimes a dimension is defined that has no content except for its primary key. For example, when an invoice has multiple line items, the line item fact rows inherit all the descriptive dimension foreign keys of the invoice, and the invoice is left with no unique content. But the invoice number remains a valid dimension key for fact tables at the line item level. This degenerate dimension is placed in the fact table with the explicit acknowledgment that there is no associated dimension table. Degenerate dimensions are most common with transaction and accumulating snapshot fact tables.
2.5 事实表设计方法
在《阿里大数据实践之路》的事实表设计方法中,相比于Kimball在《数据仓库工具箱》中提出的设计步骤,阿里的方法增加了一步冗余维度的操作。
- 选择业务过程并确定事实表类型:首先需要选择代表业务操作的过程,并根据不同业务需求确定事实表的类型。
- 声明粒度:粒度是事实表的核心,明确数据的粒度对于设计高效的表结构至关重要。
- 确定维度:根据业务需求选择与事实表关联的维度,例如时间、地点、产品等。
- 确定事实:明确事实表中的事实数据,如销售额、数量、金额等。
- 冗余维度:在确保数据一致性的前提下,增加冗余维度,以提升查询效率和处理性能。
3 维度表
3.1 基本概念
3.1.1 代理键和自然键
在数据仓库设计中,"代理键"(Surrogate Key)和"自然键"(Natural Key)是指用来唯一标识维度表中每一行记录的两种不同的方式。
自然键(Natural Key):自然键是指在业务系统中已经存在的、可以直接用来唯一标识一条记录的字段。它通常是业务上具有实际意义的字段,如客户的身份证号、产品的SKU编号等。自然键本身在业务系统中就有唯一性,且有业务含义。
代理键(Surrogate Key):代理键是数据仓库中为每一条记录生成的人工定义的唯一标识符。代理键通常是一个没有任何业务含义的、在数据库中自动生成的数字或字符串。它是数据仓库中用来代替自然键进行引用的键。
代理键与自然键的关系
-
数据仓库设计中常用代理键:在实际的维度建模中,通常使用代理键来作为维度表的主键。这是因为自然键的变化性和复杂性可能导致数据仓库维护的困难,而代理键解决了这些问题。
-
如何使用代理键:当数据仓库中的事实表引用维度表时,事实表会使用代理键,而不是自然键。这使得事实表的查询更加高效,并且避免了自然键变更时所带来的影响。
| 特点 | 自然键 | 代理键 |
|---|---|---|
| 含义 | 与业务相关,通常在业务系统中已存在且有意义。 | 没有业务含义,仅在数据仓库中作为唯一标识符使用。 |
| 变化性 | 可能会发生变化(例如,客户的姓名地址发生变动)。 | 不会变化,一旦创建,始终不变。 |
| 性能 | 可能较长且复杂,影响性能。 | 通常为短整数,性能较好。 |
| 存储需求 | 存储多个字段(例如,复合键),可能增加存储成本。 | 只需要一个字段(通常是整型),存储成本较低。 |
| 维护复杂度 | 随着业务变化可能需要进行更新,维护复杂度高。 | 无需关注业务变化,维护简单。 |
3.1.2 退化维度
退化维度(Degenerate Dimension) 是在数据仓库设计中常见的一种特殊类型的维度。它与普通的维度表不同,不会有独立的维度表,而是直接存在于事实表中。退化维度是指在事实表中作为一个单独字段存在的维度键,但并没有其对应的维度表。它通常代表业务过程中的某个标识符(例如订单号、发票号、票据号等),这些标识符本身是具有业务意义的,但在数据仓库中没有附加的详细属性(即没有专门的维度表来描述这些标识符)。
为什么使用退化维度:
- 简化设计:退化维度将不需要的维度属性(如详细的订单信息、客户信息等)简化处理,减少了表的数量。它可以避免创建额外的维度表来存储这些不需要详细描述的标识符。
- 提高查询效率:退化维度通常是单一的、简单的标识符,因此查询时不需要连接维度表,而是可以直接在事实表中使用,从而提高了查询的性能。
- 适用于某些业务场景:例如订单号、发票号等,在事实表中直接使用这些字段,可以快速进行事务的跟踪和分析。
退化维度的例子:
- 订单号:在零售行业,订单号是一个常见的退化维度。订单号本身不需要额外的维度表来存储详细信息,因为订单号在事实表中就足以标识一个交易。
- 事实表字段:
order_id(订单号) - 没有额外的订单维度表,所有与订单相关的事实(如购买数量、销售额等)都会包含在事实表中。
- 事实表字段:
- 发票号:在财务处理中,发票号也是一个典型的退化维度,发票号在交易中具有唯一标识作用,但通常不需要关联到详细的维度表。
- 事实表字段:
invoice_number(发票号) - 发票号可以作为一个维度直接在事实表中使用,而无需额外的维度表来存储相关信息。
- 事实表字段:
- 票据号:在银行、保险等行业,票据号也是一个退化维度,通常用来标识某一交易或业务事件,但不需要创建额外的维度表来详细描述。
什么时候使用退化维度:
- 当某个标识符在事实表中有唯一的意义,并且它本身不需要额外的维度表来存储其属性时,可以考虑使用退化维度。
- 当你需要避免创建大量的维度表,并希望事实表更简洁时,可以使用退化维度。
- 对于某些业务过程中的标识符,创建独立的维度表可能会增加复杂度和维护成本,这时候退化维度是一个不错的选择。
3.1.3 多层次维度
多层次维度(Hierarchical Dimensions) 是数据仓库中的一个重要概念,指的是在同一个维度中,存在多个层级(或层次)的数据结构,层级间有明确的父子关系。每个层级代表一个不同的粒度,能够对数据进行分层和分类,使得分析更加灵活,支持从不同的角度来进行汇总、细化和切片。
常见的多层次维度示例:
-
时间维度:时间维度通常具有多层次的结构,可以从年到季节、季度、月份、周、日、小时等。示例:年 → 季度 → 月 → 周 → 日 → 小时 → 分钟
-
地理维度:地理维度可以有不同的层次,从国家到省、城市、街道等。示例:国家 → 省 → 城市 → 区域 → 街道
-
产品维度:产品维度通常包含多个层次,例如从产品线到产品类别、产品型号等。示例:产品线 → 类别 → 型号 → 品牌
-
组织维度:组织维度描述了一个企业或机构内部的层次结构,包括部门、团队等。示例:公司 → 部门 → 团队 → 员工
层次结构的设计方法:在设计多层次维度时,通常会采用“父-子”结构,父层级包含了子层级的聚合数据。设计多层次维度时应注意以下几个要点:
- 层次关系清晰:层级之间的关系必须明确,确保从上层到下层的汇总关系。
- 粒度一致:每个层级代表一个固定的粒度,不同层级之间的数据应该可以互相聚合。
- 灵活性:不同的查询需求可能需要从不同的层级开始,因此需要确保查询灵活性。
3.1.4 杂项维度
杂项维度(Junk Dimension) 是数据仓库设计中常见的一个维度,它主要用于存储一组无法归类到其他维度的属性数据。通常,这些数据是小而不常用的,可能是二元标记、状态标识或一些临时标记,往往没有固定的结构或逻辑。杂项维度将这些无关紧要的或零散的字段收集到一起,使得事实表和其他维度表保持清晰和简洁。
使用场景:
- 无关或低频的标志:数据可能包含一些无关的标志,比如是否启用了某项功能、用户是否已经验证、是否过期等。
- 数据值不稳定的字段:可能存在一些字段,它们的取值变化很少且与核心业务无关,如某个订单的配送方式、包装类型等。
- 标识符:包含多个二进制字段(如是/否标志)的数据,它们通常不与其他业务维度关联,适合存储在杂项维度中。
杂项维度的设计思路:
-
合并小维度表:当有多个小型维度表,但每个表中的数据量都非常小,并且这些数据没有明显的业务逻辑关系时,可以将它们合并成一个杂项维度。这种方式避免了大量小型维度表的创建,提高了查询效率。
-
避免重复和冗余:这些字段本来可能分散在多个维度中,但通过建立杂项维度表,可以避免在事实表中重复存储不重要的字段,减少冗余数据。
-
提高模型可维护性:将一些不常用的属性集中到一个单独的维度表中,不仅能保持事实表的简洁性,还能够提高维度表的可维护性,避免了过多的“死数据”占用存储空间。
杂项维度的优点:
- 减少冗余:通过将多个不相关的小维度合并,避免了在事实表中存储大量的无关字段。
- 提高性能:减少了对单独维度表的引用,减少了连接操作,能提高查询的性能。
- 增强查询灵活性:通过杂项维度,将零散的信息集中存储,使得业务查询时更容易提取需要的信息。
- 简化数据模型:保持事实表和其他维度表的简洁,避免过多无关字段的干扰,简化了数据模型的设计。
杂项维度的缺点:
- 数据不容易理解:杂项维度表的内容比较杂乱无章,可能会增加理解和维护的难度,尤其是当业务变化时,杂项维度的字段可能需要调整或拆分。
- 查询复杂性增加:虽然它能减少事实表和维度表的冗余,但在查询时,如果不清楚具体字段的含义,可能会增加理解和使用的复杂度。
- 需要时常维护:由于杂项维度包含了各种零散的信息,可能会随着业务需求的变化而频繁更新,增加了数据维护的成本。
杂项维度的设计示例:
假设我们有一个销售事实表(sales_fact),其中包括了一个“配送方式”字段、一个“客户忠诚度标识”字段和一个“促销活动标识”字段,这些字段虽然有其存在的必要性,但它们本身并不属于某个具体的业务维度。为了避免将这些字段散布在多个维度表或事实表中,我们可以将它们合并成一个“杂项维度”(junk_dimension)表。
1. 杂项维度表设计:
| JunkID | 配送方式 | 客户忠诚度标识 | 促销活动标识 |
|---|---|---|---|
| 1 | 快递 | 是 | 促销1 |
| 2 | 自提 | 否 | 促销2 |
| 3 | 快递 | 是 | 无促销 |
2. 销售事实表设计:
| SalesID | ProductID | Quantity | SalesAmount | JunkID |
|---|---|---|---|---|
| 1001 | P001 | 2 | 200 | 1 |
| 1002 | P002 | 1 | 100 | 3 |
在上述设计中,JunkID 是连接事实表和杂项维度表的外键。通过使用杂项维度,所有不重要或低频的标志信息都集中存储在一个表中,避免了在多个事实表中重复存储这些信息。
实现方式:
-
合并多个小维度表:对于包含低频或无关字段的小维度表,可以将它们的字段合并到一个杂项维度表中。
-
在 ETL 过程中合并数据:在数据加载的ETL过程中,可以先将多个小维度的字段合并成一个杂项维度,再将其加入到事实表或数据模型中。
3.2 维度表设计方法
维度的设计过程实际上就是确定维度属性的过程。如何生成维度属性,以及这些属性的优劣,直接决定了维度的使用方便性,也成为数据仓库易用性的关键。正如Kimball所言,数据仓库的能力与维度属性的质量和深度是成正比的。
第一步:选择维度或新建维度。
确定哪些业务领域需要独立的维度,或者从现有的维度中提取新的维度。
第二步:确定主维表。
主维表是用于存储核心维度信息的表格,它通常包含维度的基本属性。
第三步:确定相关维表。
根据主维表,选择那些与主维表有关联的维度表,通常是为了补充更详细的维度信息。
第四步:确定维度属性。
这一步是维度设计的关键,主要包括两个阶段:
- 从主维表中选择维度属性或生成新的维度属性。
- 从相关维表中选择维度属性或生成新的维度属性。
确定维度属性的几点提示:
-
尽可能生成丰富的维度属性:淘宝商品维度可能会包含近百个维度属性,这些丰富的属性为下游的数据统计、分析和探索提供了坚实的基础。
-
尽可能多地给出富有意义的文字描述:属性不应仅仅是编码,而应尽量使用文字描述。在阿里巴巴的维度建模中,编码和文字描述通常同时存在。例如,商品维度中包含商品ID和商品标题、类目ID和类目名称等。ID通常用于表之间的关联,而名称则用于报表标签,帮助用户更好地理解数据。
-
区分数值型属性和事实:数值型字段是作为事实还是维度属性,通常可以通过字段的用途来判断。如果字段通常用于查询约束条件或分组统计,它是维度属性;如果用于度量的计算,则作为事实。例如,商品价格可以用于查询约束条件或统计价格区间的商品数量时,作为维度属性;但若用于统计某一类目下商品的平均价格时,则是事实属性。另外,离散值的数值型字段更可能是维度属性,而连续值的数值型字段更可能是事实属性,但也需要考虑具体用途。
-
尽量沉淀出通用的维度属性:有些维度属性需要复杂的逻辑处理,可能需要通过多表关联、单表字段混合处理,或解析字段得到。此时,应该尽可能地将通用的维度属性进行沉淀。这样既能提高下游使用的方便性,减少复杂度,又能避免因各自不同的解析逻辑导致口径不一致的问题。
3.3 缓慢变化维的处理方法
缓慢变化维度(Slowly Changing Dimensions, SCD) 是数据仓库中经常遇到的一类维度,它指的是那些随着时间变化而发生改变的维度数据。与快速变化维度(如交易事实)不同,缓慢变化维度的变化通常是渐进的,发生频率较低。例如,客户的地址、员工的职位、产品的类别等,可能会随着时间的推移而发生变化。
缓慢变化维度常见的处理方法有三种:类型 1(Type 1)、类型 2(Type 2) 和 类型 3(Type 3)。每种方法处理维度变化的方式不同,适用于不同的业务需求。
类型 1:覆盖旧值(Overwrite the old value)
类型1的处理方式是直接覆盖旧的维度数据。当维度属性发生变化时,直接更新原有记录,不保存历史数据。这种方式非常简单,不会增加额外的数据存储,但丧失了历史信息。
特点:
- 更新方式:直接覆盖。
- 存储历史:不存储历史数据,当前的值会替代之前的值。
- 适用场景:当历史数据不重要,或者业务中不需要追溯历史数据时适用。例如,员工的家庭住址可能发生变化,但只关心当前地址,不需要记录历史地址。
示例:假设员工的职位发生变化,在类型1方法下,原来的职位数据将被新职位覆盖。
| 员工ID | 姓名 | 职位 |
|---|---|---|
| 001 | 张三 | 数据分析师 |
| 002 | 李四 | 开发工程师 |
如果张三的职位变更为“技术经理”,那么更新后的数据表将如下:
| 员工ID | 姓名 | 职位 |
|---|---|---|
| 001 | 张三 | 技术经理 |
| 002 | 李四 | 开发工程师 |
类型 2:添加新记录(Add new records with versioning)
类型2的处理方式是当维度发生变化时,不更新原记录,而是插入一条新记录,并保留旧记录。新记录包含一个有效时间区间(如有效开始和结束日期)。这种方法可以保留历史数据,适合需要保留完整历史数据的场景。
特点:
- 更新方式:插入新记录,保留旧记录。
- 存储历史:会保存历史数据,可以查询历史变化。
- 适用场景:当需要追溯历史变化,如客户地址的变化,产品类别变动等。适用于需要完整历史记录的场景。
示例:假设张三的职位从“数据分析师”变更为“技术经理”,在类型2方法下,表中会添加新记录并保留旧记录:
| 员工ID | 姓名 | 职位 | 有效开始日期 | 有效结束日期 |
|---|---|---|---|---|
| 001 | 张三 | 数据分析师 | 2020-01-01 | 2021-01-01 |
| 001 | 张三 | 技术经理 | 2021-01-02 | NULL |
| 002 | 李四 | 开发工程师 | 2020-01-01 | NULL |
在这里,张三的职位从2021年1月1日起变更为“技术经理”,原“数据分析师”记录的有效期是到2021年1月1日。
类型 3:保留有限历史数据(Store limited history)
类型3的处理方式是为维度属性的变化保留有限的历史数据,通常只保留最近的N个版本。例如,保留员工的当前职位和之前的职位(最多一个历史记录)。当维度变化时,会更新历史字段,并在表中增加新的字段来存储历史数据。
特点:
- 更新方式:更新历史字段,增加额外的字段来存储历史数据。
- 存储历史:保留有限的历史数据,通常只保留最近一两个版本的变化。
- 适用场景:当只关心有限的历史数据,或者业务上只需要追踪某些最近的变化时适用。例如,产品的上一版本和当前版本。
示例:假设张三的职位从“数据分析师”变更为“技术经理”,在类型3方法下,原表的设计可能会增加“上一个职位”字段来存储历史职位:
| 员工ID | 姓名 | 当前职位 | 上一个职位 |
|---|---|---|---|
| 001 | 张三 | 技术经理 | 数据分析师 |
| 002 | 李四 | 开发工程师 | NULL |
在这里,张三的“当前职位”被更新为“技术经理”,并且“上一个职位”保留为“数据分析师”。
在我目前所在的团队以及之前的团队中,我们并未采用传统的三种慢变化维度处理方法,而是采用了快照维表的方式,这一方法在《阿里的大数据实践之路》中有详细描述:
快照维表:数据仓库的计算周期通常为每天一次,基于这一周期,我们的维度变化处理方法是每天保留一份全量的快照数据。例如,商品维度每天都会保存一份全量的商品快照数据。无论是查询某一天的事实数据,还是查询最新的商品信息,只需通过限定日期并使用自然键进行关联即可。这种方式既有优点,也有一些弊端。
优点:
- 简单有效:开发和维护成本较低,操作过程直接。
- 使用便捷:数据使用方只需限定日期,即可获取当日的快照数据。任意一天的事实数据与维度快照通过自然键关联,操作起来直观易懂。
弊端:
- 存储浪费:若某一维度的变化量很小,甚至在极端情况下完全没有变化,那么每天保存全量快照会导致存储浪费非常严重。
- 牺牲存储换取效率:虽然此方法简化了逻辑处理,提高了查询效率,但也造成了存储资源的大量浪费。因此,必须要避免过度使用该方法,并且要有相应的数据生命周期管理制度,以定期清理不再需要的历史数据。
综合来看,考虑到存储成本相较于 CPU、内存等硬件资源成本较低,快照维表的方法在实际应用中弊大于利。
4 模型实施
这里也是引用《阿里大数据实践之路》中的内容,整个互联网行业也基本采用这套方法论进行数仓建设
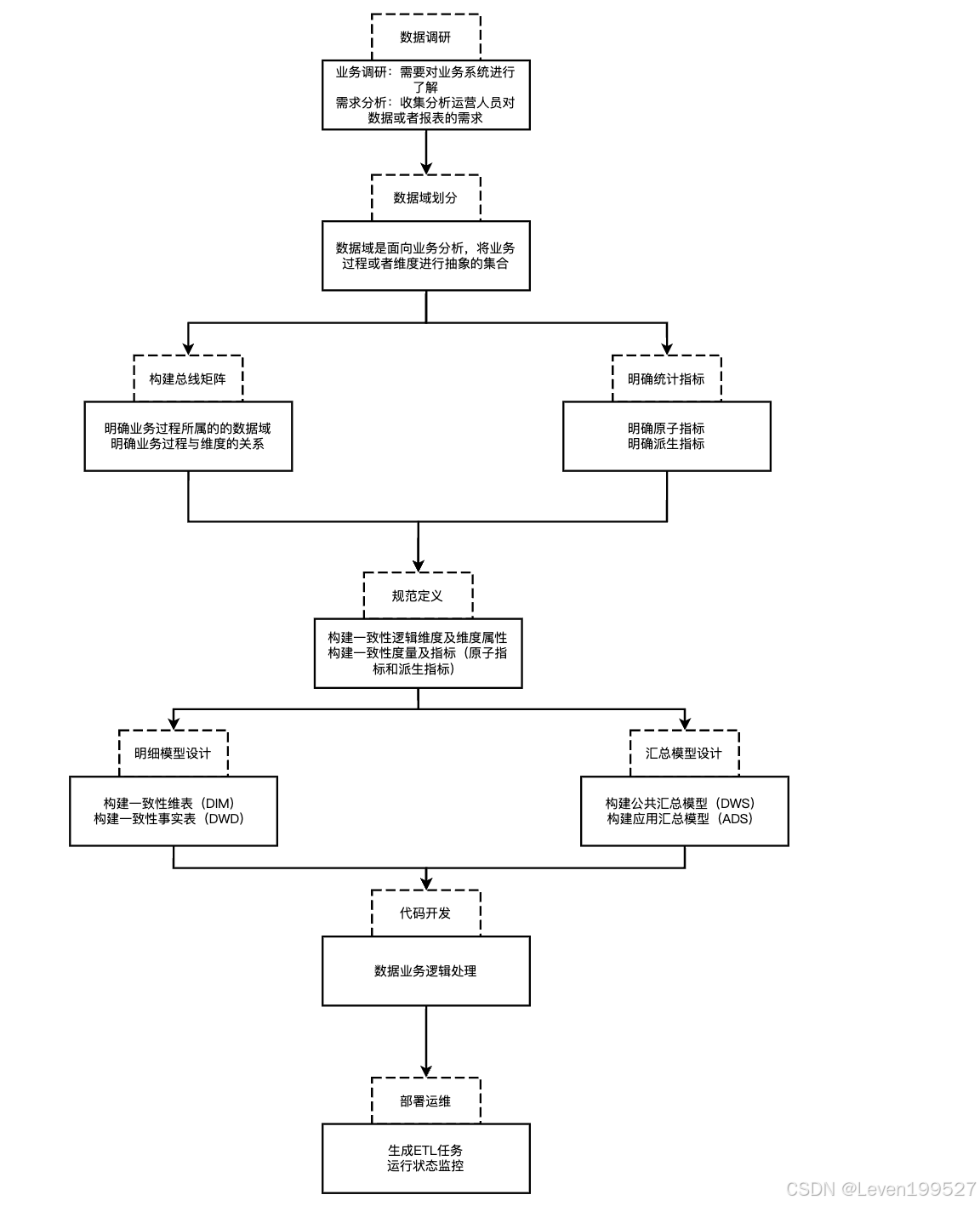
第一步:数据调研
数据调研阶段包括业务调研和需求调研两个方面。首先,通过与业务部门的深入沟通,全面了解业务流程、核心指标和决策需求。其次,通过需求调研,识别系统的功能需求、数据要求以及各方用户的期望,为后续的架构设计和数据建模奠定基础。
第二步:架构设计
架构设计阶段重点是数据域的划分和总线矩阵的构建。在数据域划分过程中,根据业务特点和数据的使用场景,将数据划分为不同的领域,确保数据存储和访问的高效性。与此同时,构建总线矩阵,为数据仓库的集成提供一个清晰的视图,明确各个业务过程、维度和事实之间的关系,为后续的数据建模工作提供基础。
第三步:规范设计
在规范设计阶段,确定数据建模、数据质量、数据安全等方面的标准与规范。这包括但不限于数据命名规范、数据格式规范、数据存储标准等,以确保数据的高质量和一致性。此外,还需制定数据治理的相关政策和流程,以确保数据在整个生命周期中的可控性和合规性。
第四步:模型设计
模型设计阶段主要包括维度模型和事实模型的设计。根据前期的数据调研和架构设计,选择适合的建模方法(如星型模型或雪花模型),设计出高效、易用的分析模型。此阶段需要确保模型能够有效支持业务需求和分析场景,并具备较高的查询性能。
第五步:模型部署、运行与监控
在模型部署阶段,将设计好的数据模型进行实际部署,确保其能够与数据源和业务系统无缝对接,支持实时或批量数据的加载和处理。运行阶段则包括对模型的运行进行监控,确保数据的更新和查询高效、准确,并及时处理可能出现的问题。同时,持续监控和优化模型的性能,确保其能够应对不断变化的业务需求。
5 参考文献
- 《数据仓库工具箱——维度建模权威指南》
- 《大数据之路:阿里巴巴大数据实践》