决策树的ID3算法
模式识别课程第二组课题是熟悉和掌握决策树的分类原理、实质和过程,掌握决策树典型算法(ID3、C4.5、CART)的核心思想和实现过程。
我的主要任务是对决策树的ID3算法的部分进行PPT制作以及算法讲解,主要介绍ID3算法的简介,算法原理,案例分析。
-
- ID3算法的简介
ID3算法核心是“信息熵”,在创建决策树的过程中,依次查询样本集合中的每个属性,选取出具有最大信息增益值的属性,将该属性作为测试属性与划分标准。通过该标准将原始数据集合划分成多个更纯的子集,并在每个子集中重复这个过程,直到分支子集中的所有样本无法继续分割,即样例属性属于同一类别,此时一棵决策树便创建完成。
-
- ID3算法的原理
1信息熵
信息熵又叫香农熵,是1948年美国数学家香农把热力学的熵引入到信息论。信息熵代表的是属性类别的不纯性度量,熵值越高属性的纯度越低。
信息熵的定义式如下
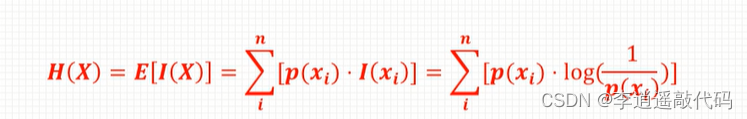
决策树算法中log使用以2为低,对于随机变量X,以一定的概率p(xi)取值为xi,当计算随机变量X的自发信息量时,由于不知道X的具体取值,要考虑到所有X取到每一个xi的情况,而对于每一个xi的自信息量是可以计算的。
2条件熵
条件熵描述在随机变量X的值已知的前提下,随机变量Y的不确定程度,表示为H(Y|X)。若H(Y|X=x)表示变量Y在变量X取特定值x条件下的熵,那么H(Y|X)就是X在取所有的x后取平均的结果。即:
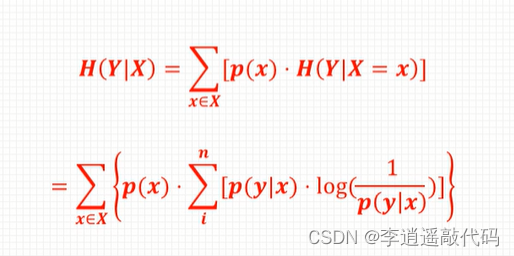
条件熵可以描述在某个随机变量确定的情况下,另一个随机变量的不确定程度。
3信息增益
信息增益:通过信息熵相减求得,它反映了该属性特征在总体数据集中的重要程度,用Gain(Y,X) 表示。指在随机变量X确定条件下,随机变量Y的熵值较没有任何条件确定时减少了多少。计算公式如下:

ID3算法是一个从模糊到清晰,不确定程度越来越小的过程。在决策树构造中呢,最重要的步骤就是决策树节点属性的选择,在决策树的结点划分之前,先计算每一个属性所带来的信息增益,选择最大信息增益的属性来划分,因为信息增益越大,区分样本的能力就越强,越具有代表性,这就是ID3算法的核心。
1.3 ID3算法优缺点
ID3算法是一种采用自顶向下,贪婪策略的算法。
1优点:
(1)自顶向下的搜索方式降 低了搜索次数,提升了分类速度;
(2)ID3算法原理清晰,算法思路简单易懂,易于实现;
(3)由于决策树在创建的过程中都使用目前的训练样本