采用华为一次比赛的垃圾分类数据集
文章目录
1.数据集简介
首先他有一个分类文件classify_rule.json。
{
"可回收物": [
"充电宝",
"包",
"洗护用品",
"塑料玩具",
"塑料器皿",
"塑料衣架",
"玻璃器皿",
"金属器皿",
"快递纸袋",
"插头电线",
"旧衣服",
"易拉罐",
"枕头",
"毛绒玩具",
"鞋",
"砧板",
"纸盒纸箱",
"调料瓶",
"酒瓶",
"金属食品罐",
"金属厨具",
"锅",
"食用油桶",
"饮料瓶",
"书籍纸张",
"垃圾桶"
],
"厨余垃圾": [
"剩饭剩菜",
"大骨头",
"果皮果肉",
"茶叶渣",
"菜帮菜叶",
"蛋壳",
"鱼骨"
],
"有害垃圾": [
"干电池",
"软膏",
"过期药物"
],
"其他垃圾": [
"一次性快餐盒",
"污损塑料",
"烟蒂",
"牙签",
"花盆",
"陶瓷器皿",
"筷子",
"污损用纸"
]
}
然后文件夹架构长这样
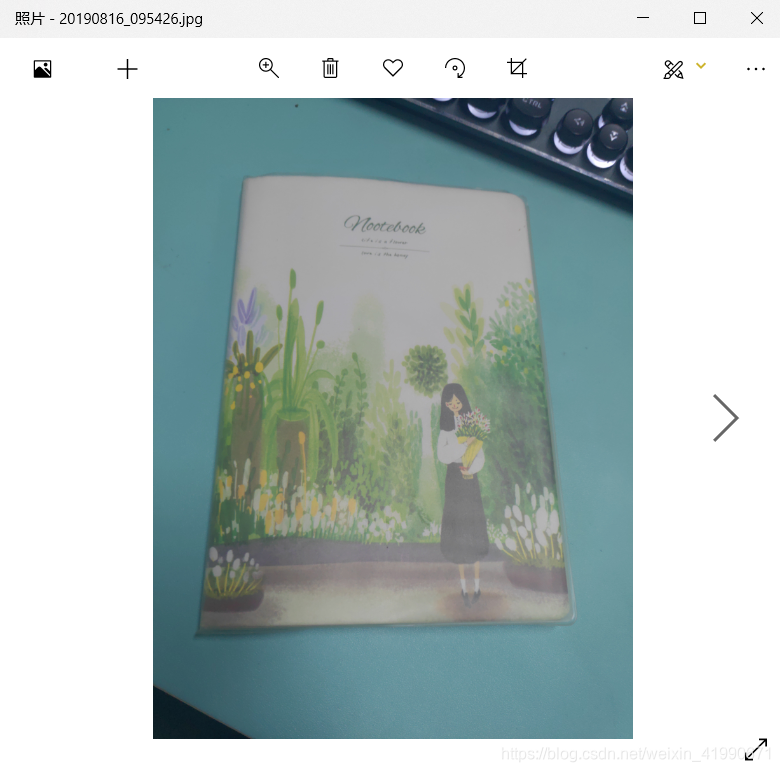
Annotations文件夹里存xml文件,JPEG文件夹里存图片,二者对应文件名相同,举个例子:
20190816_095426.xml

<annotation>
<folder>label</folder>
<filename>20190816_095426.jpg</filename>
<path>C:\Users\hwx594248\Desktop\label\20190816_095426.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>4032</width>
<height>3024</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>书籍纸张</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>447</xmin>
<ymin>328</ymin>
<xmax>3443</xmax>
<ymax>2757</ymax>
</bndbox>
</object>
</annotation>
2.符合yolov5的数据集制作
阅读https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
制定了以下处理步骤:
- 查json文件,对类别编号(从零开始)
- xml->txt
其中xml->txt分以下几步:
- 文件名只需新建一个同名txt即可
- 取总宽总高
- 取所有的object
对于每一个object:
- get name
- name->编号
- get bndbox
- 计算所需的四个数
- 打印到txt中
------------------ 开始------------------
2.1 读json
import json
with open('classify_rule.json', 'r', encoding='utf-8') as fp:
text = json.load(fp)
count = 0
label = {}
for i in text:
for j in text[i]:
label[j] = count
count += 1
print(label)
with open('classes.txt', 'w') as fp:
w_json = json.dump(label, fp)
with open('classes.txt', 'r') as fp:
text = json.load(fp)
print(text['充电宝'])
注意encoding很重要,不加会报错。
得到
{'充电宝': 0, '包': 1, '洗护用品': 2, '塑料玩具': 3, '塑料器皿': 4, '塑料衣架': 5, '玻璃器皿': 6, '金属器皿': 7, '快递纸袋': 8, '插头电线': 9, '旧衣服': 10, '易拉罐': 11, '枕头': 12, '毛绒玩具': 13, '鞋': 14, '砧板': 15, '纸盒纸箱': 16, '调料瓶': 17, '酒瓶': 18, '金属食品罐': 19, '金属厨具': 20, '锅': 21, '食用油桶': 22, '饮料瓶': 23, '书籍纸张': 24, '垃圾桶': 25, '剩饭剩菜': 26, '大骨头': 27, '果皮果肉': 28, '茶叶渣': 29, '菜帮菜叶': 30, '蛋壳': 31, '鱼骨': 32, '干电池': 33, '软膏': 34, '过期药物': 35, '一次性快餐盒': 36, '污损塑料': 37, '烟蒂': 38, '牙签': 39, '花盆': 40, '陶瓷器皿': 41, '筷子': 42, '污损用纸': 43}
0
搞定,共44类。
2.2 xml->txt
文件名只需新建一个同名txt即可
取总宽总高
取所有的object
代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/7/10 20:48
# @Author : Eiya_ming
# @Email : [email protected]
# @File : xml2txt.py
import json
import os
import xml.dom.minidom
xml_folder = 'VOC2007\Annotations'
txt_folder = r'VOC2007\train2020'
with open('classes.txt', 'r') as fp:
classes = json.load(fp)
l = len(classes)
print(l)
# 从文件夹里遍历所有文件
files = os.listdir(xml_folder)
xml_file = files[0]
for xml_file in files:
xml_name = xml_folder + os.sep + xml_file
name = xml_file.split('.')[0]
txt_name = txt_folder + os.sep + name + '.txt'
print(txt_name)
# print(xml_name)
# print(files[0])
# print(len(files))
DOMTree = xml.dom.minidom.parse(xml_name)
root_node = DOMTree.documentElement
# print(root_node.nodeName)
# size = root_node.getElementsByTagName("size")[0]
width = int(root_node.getElementsByTagName("width")[0].childNodes[0].data)
height = int(root_node.getElementsByTagName("height")[0].childNodes[0].data)
# print(width, height)
objs = root_node.getElementsByTagName("object")
contents = ''
for obj in objs:
cls = classes[obj.getElementsByTagName("name")[0].childNodes[0].data]
# print(cls)
xmin = int(obj.getElementsByTagName("xmin")[0].childNodes[0].data)
ymin = int(obj.getElementsByTagName("ymin")[0].childNodes[0].data)
xmax = int(obj.getElementsByTagName("xmax")[0].childNodes[0].data)
ymax = int(obj.getElementsByTagName("ymax")[0].childNodes[0].data)
# print(xmin, type(xmin))
x_center = (xmin + xmax) / width / 2.
y_center = (ymin + ymax) / height / 2.
obj_width = (-xmin + xmax) / width / 1.
obj_height = (-ymin + ymax) / height / 1.
# print(x_center, y_center, obj_width, obj_height)
content = str(cls)+' '+str(x_center)+' '+str(y_center)+' '+str(obj_width)+' '+str(obj_height)+' '+'\n'
print(content)
contents = contents+content
with open(txt_name,'w')as f:
f.write(contents)
搞定
2.3 文件结构整理
官方给出的文件架构长这样,我也弄成这样
3.训练
3.1 修改相关文件
junk2020.yaml
# Dataset should be placed next to yolov5 folder:
# /parent_folder
# /junk
# /yolov5
# train and val datasets (image directory or *.txt file with image paths)
train: ../junk/images/train2020/
val: ../junk/images/train2020/
# number of classes
nc: 44
# class names
names: ['充电宝', '包', '洗护用品', '塑料玩具', '塑料器皿', '塑料衣架', '玻璃器皿', '金属器皿', '快递纸袋',
'插头电线', '旧衣服', '易拉罐', '枕头', '毛绒玩具', '鞋', '砧板', '纸盒纸箱', '调料瓶', '酒瓶',
'金属食品罐', '金属厨具', '锅', '食用油桶', '饮料瓶', '书籍纸张', '垃圾桶', '剩饭剩菜', '大骨头',
'果皮果肉', '茶叶渣', '菜帮菜叶', '蛋壳', '鱼骨', '干电池', '软膏', '过期药物', '一次性快餐盒',
'污损塑料', '烟蒂', '牙签', '花盆', '陶瓷器皿', '筷子', '污损用纸']
将models/yolov5s.yaml中的nc修改为自己的类别数(44)。
3.2 尝试训练
命令:
python .\train.py --batch 128 --epoch 5 --data .\data\junk2020.yaml --cfg .\models\yolov5s.yaml
报错1 编码问题
Traceback (most recent call last):
File ".\train.py", line 404, in <module>
train(hyp)
File ".\train.py", line 68, in train
data_dict = yaml.load(f, Loader=yaml.FullLoader) # model dict
File "C:\Users\15518\AppData\Local\Programs\Python\Python37\lib\site-packages\yaml\__init__.py", line 112, in load
loader = Loader(stream)
File "C:\Users\15518\AppData\Local\Programs\Python\Python37\lib\site-packages\yaml\loader.py", line 24, in __init__
Reader.__init__(self, stream)
File "C:\Users\15518\AppData\Local\Programs\Python\Python37\lib\site-packages\yaml\reader.py", line 85, in __init__
self.determine_encoding()
File "C:\Users\15518\AppData\Local\Programs\Python\Python37\lib\site-packages\yaml\reader.py", line 124, in determine_encoding
self.update_raw()
File "C:\Users\15518\AppData\Local\Programs\Python\Python37\lib\site-packages\yaml\reader.py", line 178, in update_raw
data = self.stream.read(size)
UnicodeDecodeError: 'gbk' codec can't decode byte 0x9d in position 309: illegal multibyte sequence
读取yaml出问题,在出错位置增加encoding="utf-8"即可。
test.py也要改哦!!!!!
报错2 windows文件路径格式问题
Traceback (most recent call last):
File ".\train.py", line 402, in <module>
tb_writer = SummaryWriter(log_dir=increment_dir('runs/exp', opt.name))
File "D:\ForSpeed\junk_yolov5\yolov5\utils\utils.py", line 911, in increment_dir
n = int(d[:d.find('_')] if '_' in d else d) + 1 # increment
ValueError: invalid literal for int() with base 10: 'runs\\exp0'
这里报错为字符串转int出问题,经过一系列打印测试得知是在将runs\exp0
中的runs\exp替换成空字符出了问题,因为代码中写的是runs/exp所以没有做替换操作,在train.py中改一下就好了。
报错3 txt出问题
Traceback (most recent call last):
File ".\train.py", line 404, in <module>
train(hyp)
File ".\train.py", line 165, in train
hyp=hyp, augment=True, cache=opt.cache_images, rect=opt.rect)
File "D:\ForSpeed\junk_yolov5\yolov5\utils\datasets.py", line 57, in create_dataloader
pad=pad)
File "D:\ForSpeed\junk_yolov5\yolov5\utils\datasets.py", line 371, in __init__
assert (l[:, 1:] <= 1).all(), 'non-normalized or out of bounds coordinate labels: %s' % file
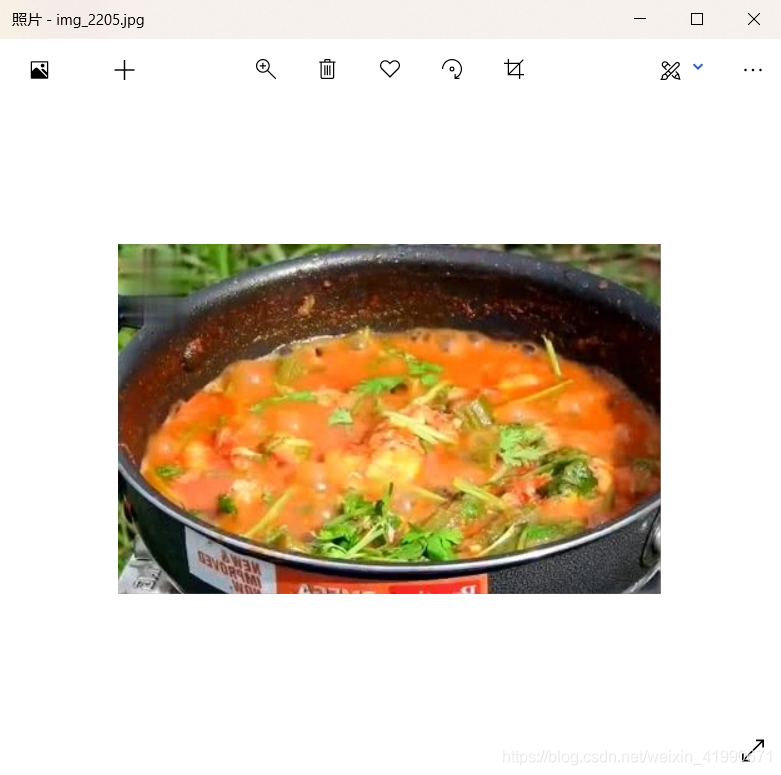
AssertionError: non-normalized or out of bounds coordinate labels: ..\junk\labels\train2020\img_2205.txt
查看这个txt,是有数超过1了
26 0.5184331797235023 0.5732142857142857 0.9585253456221198 0.6892857142857143
21 0.4988479262672811 0.5 0.9976958525345622 0.9928571428571429
26 1.6244239631336406 1.0892857142857142 1.0 1.0
查看xml
<annotation>
<folder>6</folder>
<filename>img_2205.jpg</filename>
<path>D:\resize\6\img_2205.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>434</width>
<height>280</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>剩饭剩菜</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>17</xmin>
<ymin>64</ymin>
<xmax>433</xmax>
<ymax>257</ymax>
</bndbox>
</object>
<object>
<name>锅</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>0</xmin>
<ymin>1</ymin>
<xmax>433</xmax>
<ymax>279</ymax>
</bndbox>
</object>
<object>
<name>剩饭剩菜</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>488</xmin>
<ymin>165</ymin>
<xmax>922</xmax>
<ymax>445</ymax>
</bndbox>
</object>
</annotation>
最后这个框确实过分了,看来原始数据集有误,修改一下转txt的代码,有超过1的都不要了。
报错4 RuntimeError
batch给128有点多了,换成16(咱这破电脑过了这个数就不行了)
警告5
Seems like optimizer.step() has been overridden after learning rate scheduler initialization. Please, make sure to call optimizer.step() before lr_scheduler.step().
初步结果
Optimizer stripped from runs\exp7\weights\last.pt, 14.9MB
Optimizer stripped from runs\exp7\weights\best.pt, 14.9MB
2 epochs completed in 0.703 hours.
时间很长,而且没事就停很尴尬。
修复cmd暂停问题
https://zhidao.baidu.com/question/497445865190918364.html
结果显示"???"问题
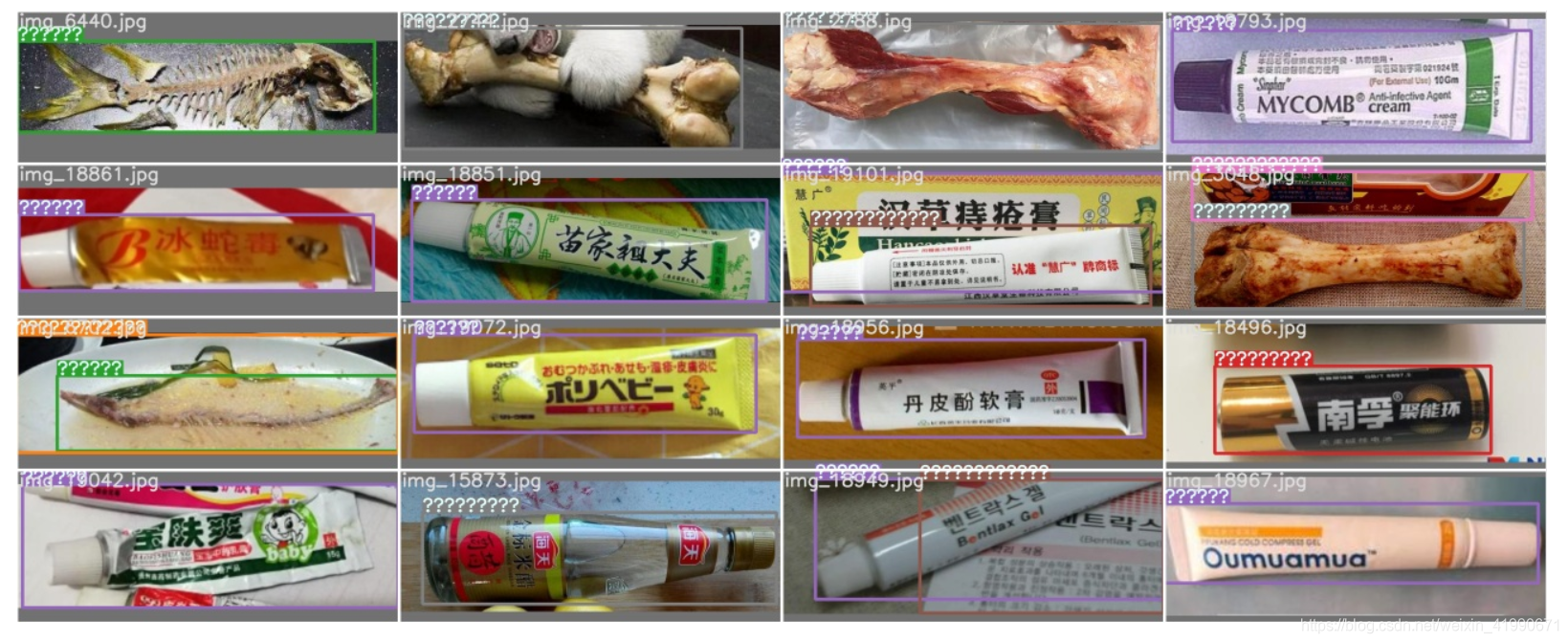
改成英文再训练两轮(之前已经跑了50个epoch)。
python train.py --batch 16 --epoch 52 --data .\data\junk2020.yaml --cfg .\models\yolov5s.yaml --weight runs\exp10\weights\last.pt
训练前把原图删了,不然还是"???"。

下一步:读懂相关参数意义,半夜就训练去呗。。。
python train.py --batch 16 --epoch 3 --data .\data\junk2020.yaml --cfg .\models\yolov5s.yaml --weight best1.pt