3.1、 CUDA执行模型概述
3.1.1 GPU架构概述
GPU架构主要围绕流式多处理器(SM)进行的搭建。如下图所示。

SM中有多个CUDA执行核心,支持数百个线程的并发执行。
当启动一个grid时,其中的block被划分到SM上进行执行,block不会跨SM进行执行。一个SM中可执行多个block,block之间根据SM资源的可用性进行调度(主要由Warp Scheduler负责)。
SM会将block再次进行划分,划分为线程束wrap(每个wrap有32个线程),然后再调度执行,wrap是SM调度运行的最小单位。此外由于block分了wrap,同一线程块中的线程可能会以不同的速度进行前进。
CUDA采用SIMT架构管理和执行线程。每32个线程为一组,称为线程束wrap。线程束中的线程执行相同的指令,但是不同线程拥有自己的指令地址计数器、寄存器状态,利用自身的数据对当前指令进行执行。
SIMT(单指令多线程)和SIMD(单指令多数据)
相同:二者都是将相同指令广播给多个执行单元进行执行
区别:
SIMD要求同一个向量中的所有元素要在一个统一的同步组中一起执行,SIMT允许同一线程束中的线程独立执行。
SIMD是一个线程,在一个核心上。SIMT是多个线程,多个核心上运行的线程。
SIMT是真正的并行,各个线程的逻辑都可以有一定的区别;SIMD仅仅能进行简单的加减乘除运算而已。
3.1.2 Fermi架构

架构图如上所示。Fermi架构是第一个完整的GPU计算架构,共有16个SM,一个SM有32个CUDA执行核心,一个执行核心中又有一个全流水线的ALU和FPU(浮点运算),有点套娃了。
整个Fermi架构还包括:
一个二级缓存(768KB,16个SM共享);
6个DRAM存储接口(提供大容量的全局内存 );
Giga Thread引擎(全局调度器),调度线程块到SM的wrap scheduler上面。
往下再套一波,每个SM中,32个CUDA执行核心;16个LD/SD单元(允许一个时钟周期内16个线程计算源地址、目的地址);4个SFU(特殊功能计算,比如正余弦等);
两个wrap scheduler和Dispatch Unit,双Warp调度器同时调度和分派来自两个独立Warp的指令。如图1所示,两个组,每组16个CUDA核心。
Fermi架构,可以在每个SM中同时处理48个线程束(16+16+16(LD/SD))。
Fermi也支持同时并发执行内核。并发执行内核允许执行一些小的内核程序来充分利用GPU,如图:

3.1.3 Kepler架构
Kelper架构框主要有三个比较大的提升:全新的SM、动态并行、Hyper-Q技术。架构图如下所示:
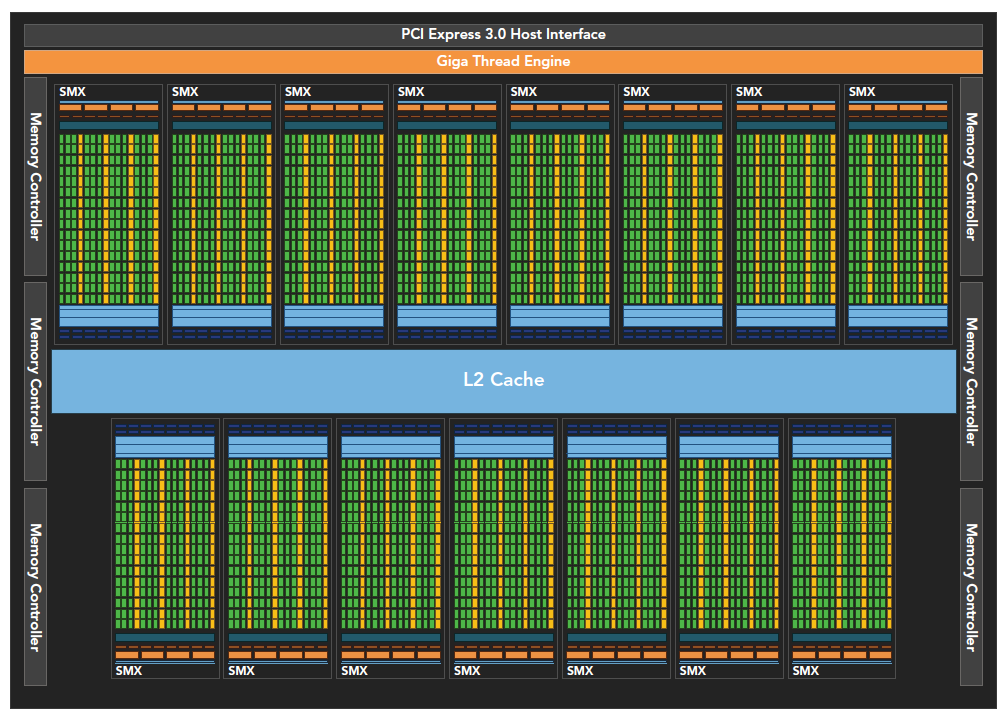
主要部件:
15个SM
6个64位内存控制器
(1) 全新的SM:

192个单精度CUDA核心
64个双精度单元
32个SFU
32个LD/ST
64KB的共享内存/L1 Cache
4个Wrap Scheduler、8个Dispatch Unit(确保在一个SM上同时发送和执行4个wrap)
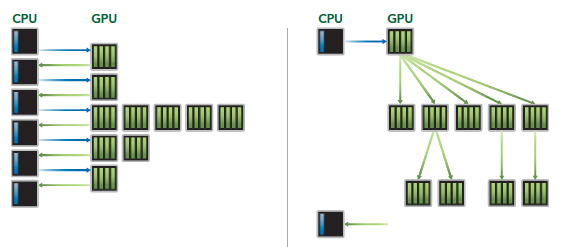
(2) 动态并行:
允许GPU动态启动新的网格,内核可以启动其他内核。这样一来便于创建和优化递归以及数据相关,同时也减少了CPU与GPU之间的通信,如下图所示。
(3) Hyper-Q技术:
增加了更多的CPU和GPU之间的同步硬件连接,使得CPU可以在GPU上同时运行更多任务,防止因队列阻塞而导致的速度下降,如下图所示。

3.1.4 使用Profile工具进行优化
简而言之:想优化速度,首先用性能分析工具分析(年轻人,得练 ):
- nvvp
- nvprof
限制内核性能的主要包括但不限于以下因素:
- 存储带宽
- 计算资源
- 指令和内存延迟